文章目录
一、回表操作
二、主键索引
三、非主键索引
四、低版本操作
五、高版本操作
六、总结
一、回表操作
对于数据库来说,只要涉及到索引,必然绕不过去回表操作。当然这也是我们今天所讲的内容的前提基础。说到回表,我们需要从索引开始说起。这里我们以Innodb存储引擎作为讲解对象。
二、主键索引
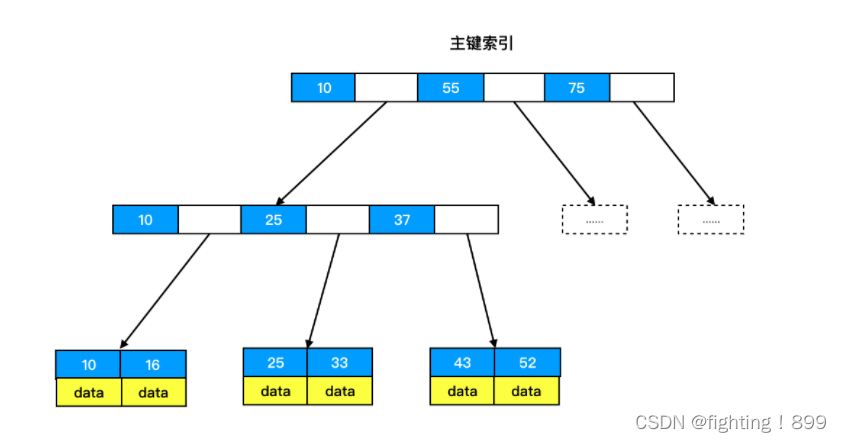
主键索引在底层的数据存储是通过B+树来实现的。除了叶子节点之外的其他节点存储的是主键值,而叶子节点上存储的是一整行的数据。主键索引实际上就是聚簇索引,即将数据按照主键值进行排序,并存储在B+ 树中的过程。
大体结构如下图所示
三、非主键索引
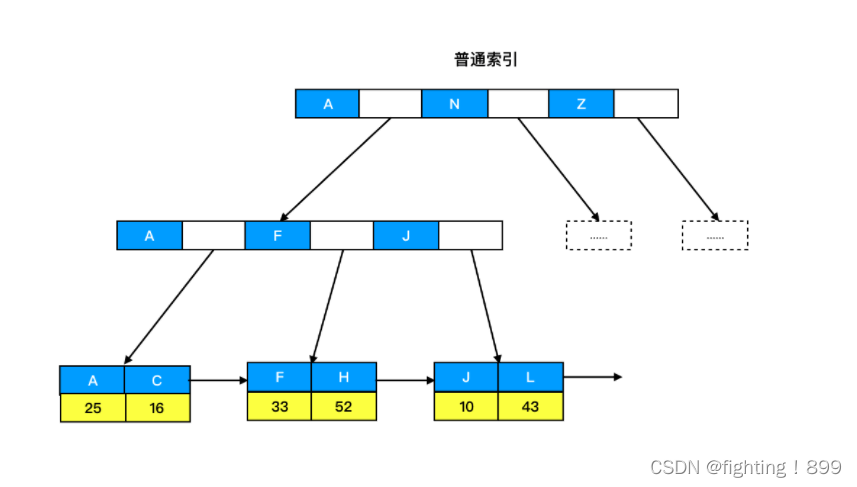
除了主键索引外,其它的索引都被称为非主键索引(非聚簇索引)。与主键索引不同的是,非主键索引的叶子节点存储的是指向对应行的主键值,而非完整的行数据,因此在使用非主键索引时需要先查找到对应行的主键值,再通过主键值查找到完整的行数据。
那让我们再回到开始的问题,什么是回表操作?
当我们在非主键索引上查找一行数据的时候,此时的查找方式是先搜索非主键索引树,拿到对应的主键值,再到主键索引树上查找对应的行数据。这种操作就叫作回表操作。
好了,这里你应该了解了什么是回表操作了。简单来讲,就是在非主键索引树上拿到对应的主键值,然后回到主键索引上找到对应的行数据。
这样做的前提条件是,所要查找的字段不存在于非主键索引树上。
四、低版本操作
讲完了回表操作,让我们继续回到这篇文章的主题——索引下推。
其实在 Mysql 5.6 版本之前是没有索引下推这个功能的,从 5.6 版本后才加上了这个优化项。所以在引出索引下推前还是先回顾下没有这个功能时是怎样一种处理方式。
我们以一个真实例子来进行讲解。
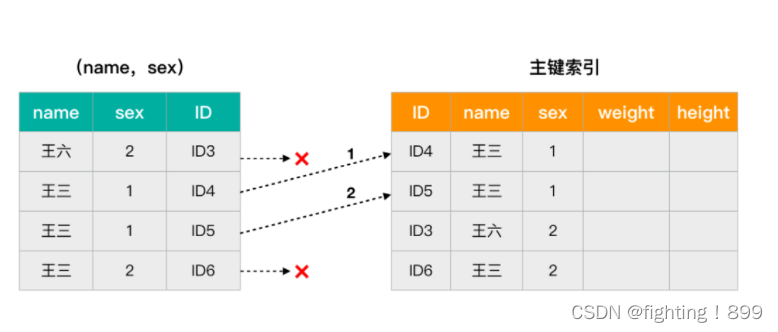
在这里有张用户表 user,记录着用户的姓名,性别,身高,年龄等信息。表中 id 是自增主键,(name,sex) 是联合索引。在这里用 1 表示男,2 表示女。现在需要查找所有姓王的男性信息。
SQL 实现起来很简单:

但是它的实现原理是什么呢?
根据联合索引最左前缀原则,我们在非主键索引树上找到第一个满足条件的值时,通过叶子节点记录的主键值再回到主键索引树上查找到对应的行数据,再对比是否为当前所要查找的性别。
整个原理可以用下边的图进行表示。
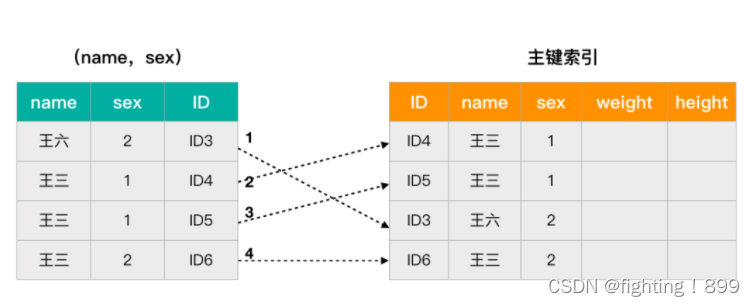
看到了吧,低版本中需要每条数据都进行回表,增加了树的搜索次数。如果遇到所要查找的数据量很大的话,性能必然有所缺失。
五、高版本操作
讲完了低版本操作,让我们继续回到这篇文章的主题——索引下推。
知道了痛点,那么怎么解决。很简单,只有符合条件了再进行回表。结合我们的例子来说就是当满足了性别 sex = 1 了,再回表查找。这样原本可能需要进行回表查找 4 次,现在可能只需要 2 次就可以了。
所以本质来说,索引下推就是只有符合条件再进行回表,对索引中包含的字段先进行判断,不符合条件的跳过。减少了不必要的回表操作。
六、总结
回表操作
-
当所要查找的字段不在非主键索引树上时,需要通过叶子节点的主键值去主键索引上获取对应的行数据,这个过程称为回表操作。
索引下推
-
索引下推主要是减少了不必要的回表操作。对于查找出来的数据,先过滤掉不符合条件的,其余的再去主键索引树上查找。