1. 计算并指定索引长度
阿里开发手册:
强制】在 varchar 字段上建立索引时,必须指定索引长度,没必要对全字段建立索引,根据实际文本区分度决定索引长度。
说明:索引的长度与区分度是一对矛盾体,一般对字符串类型数据,长度为 20 的索引,区分度会高达 90%以上,可以使用 count(distinct left(列名,索引长度)) / count(*) 的区分度来确定。
测试:
-- address长度为10,当截取到5的时候查询区分度高达0.9572(dept表是随机数据 根据自己的情况判断)
SELECT COUNT(DISTINCT LEFT(address,5)) / COUNT(*) FROM dept;
-- 创建address列的索引并指定长度为5(address可以为空 varchar类型,字节数为:5*3+3 = 18)
ALTER TABLE dept ADD INDEX idx_address(address(5));
-- 可以看到address使用的索引长度为18
EXPLAIN SELECT * FROM dept WHERE address IS NULL;2. 实现并优化8个SQL
#删除两个表的所有索引
#1、列出自己的掌门比自己年龄小的人员
EXPLAIN SELECT * FROM t_emp c
INNER JOIN (SELECT a.id, a.deptName, b.age FROM t_dept a INNER JOIN t_emp b ON a.CEO=b.id) v ON c.deptId=v.id
WHERE c.age > v.age;
EXPLAIN SELECT SQL_NO_CACHE * FROM dept a
INNER JOIN t_emp b ON a.CEO=b.id
INNER JOIN t_emp c ON c.deptId=a.id
WHERE c.age > b.age;
create index idx_deptId on t_emp(deptId);
#2、列出所有年龄低于自己门派平均年龄的人员
EXPLAIN select SQL_NO_CACHE * from emp c
LEFT JOIN (select b.deptId,AVG(b.age) avgage from emp b GROUP BY b.deptId
) v on c.deptId=v.deptId
where c.age < v.avgage;
EXPLAIN select * from (select b.deptId, AVG(b.age) avgage from emp b GROUP BY b.deptId) v
LEFT JOIN emp c on c.deptId=v.deptId
where c.age < v.avgage;
CREATE INDEX idx_deptId on emp(deptId);
#3、列出至少有2个年龄大于40岁的成员的门派
explain select SQL_NO_CACHE a.deptId, b.deptName, count(*) cou
from t_emp a
INNER JOIN t_dept b on a.deptId=b.id
where a.age>40
GROUP BY a.deptId
HAVING cou >= 2;
# 使用数据量少的表的字段分组
explain select SQL_NO_CACHE b.id, b.deptName, count(*) cou
from t_dept b
STRAIGHT_JOIN t_emp a on a.deptId=b.id
where a.age>40
GROUP BY b.id
HAVING cou >= 2;
create INDEX idx_dept on t_emp(deptId, age);
#4、至少有2位非掌门人成员的门派
EXPLAIN select SQL_NO_CACHE a.deptId,b.deptName,count(*) cou
from t_emp a
INNER JOIN t_dept b on a.deptId=b.id
where a.id!=b.CEO
GROUP BY a.deptId
HAVING cou >= 2;
explain select a.deptId,c.deptName,count(*) cou from t_emp a LEFT JOIN t_dept b on a.id=b.ceo INNER JOIN t_dept c on a.deptId=c.id
where b.ceo is null
GROUP BY a.deptId
HAVING cou>=2
CREATE INDEX idx_deptId on t_emp(deptId);
CREATE INDEX idx_ceo on t_dept(ceo);
#5、列出全部人员,并增加一列备注“是否为掌门”,如果是掌门人显示是,不是掌门人显示否
select a.id, a.`name`, CASE WHEN b.CEO IS NULL THEN '是' ELSE '否' END '是否掌门人'
from t_emp a LEFT JOIN t_dept b on a.id=b.CEO;
#6、列出全部门派,并增加一列备注“老鸟or菜鸟”,若门派的平均值年龄>50显示“老鸟”,否则显示“菜鸟”
select a.id,a.deptName,AVG(b.age),IF(AVG(b.age)>50, '老鸟', '菜鸟') '老鸟or菜鸟'
from t_dept a INNER JOIN t_emp b on a.id=b.deptId GROUP BY a.id;
#7、显示每个门派年龄最大的人
CREATE INDEX idx_deptId on t_emp(deptId);
CREATE INDEX idx_age on t_emp(age);
#8、显示每个门派年龄第二大的人·
SET @last_deptid=0;
SELECT a.id,a.deptid,a.name,a.age,a.rk
FROM(
SELECT t.*,
IF(@last_deptid=deptid,@rank:=@rank+1,@rank:=1) AS rk,
@last_deptid:=deptid AS last_deptid
FROM t_emp t
ORDER BY deptid,age DESC
)a WHERE a.rk=2;
UPDATE t_emp SET age=100 WHERE id = 2
SET @rank=0;
SET @last_deptid=0;
SET @last_age=0;
SELECT t.*,
IF(@last_deptid=deptid, IF(@last_age = age, @rank, @rank:=@rank+1),@rank:=1) AS rk,
@last_deptid:=deptid AS last_deptid,
@last_age :=age AS last_age
FROM t_emp t
ORDER BY deptid,age DESC
CALL proc_drop_index('mydb', 't_emp');
CALL proc_drop_index('mydb', 't_dept');
CALL proc_drop_index('mydb', 'emp');
CALL proc_drop_index('mydb', 'dept');3. 时间日期处理(了解)
SELECT DATE_FORMAT(NOW() , '%Y年%m月%d日 %H时%i分%s秒');
SELECT NOW();
SELECT * FROM ucenter_member WHERE DATE(gmt_create) = '2019-01-02';
SELECT * FROM ucenter_member WHERE DATE_FORMAT(gmt_create , '%Y-%m-%d') = '2019-01-02';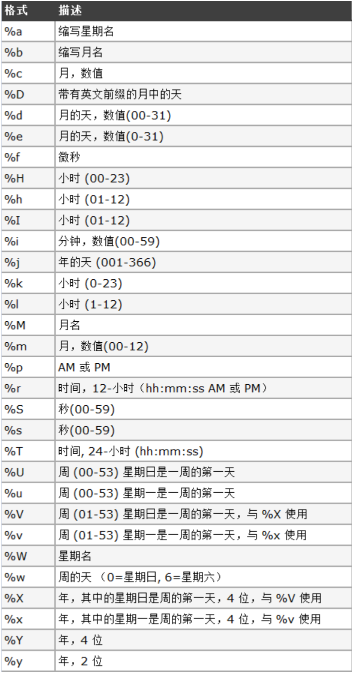
4. 行转列
测试表:
CREATE TABLE t_score(
id INT(11) NOT NULL auto_increment,
stuid VARCHAR(20) NOT NULL COMMENT 'id',
subject VARCHAR(20) COMMENT '科目',
score DOUBLE COMMENT '成绩',
PRIMARY KEY(id)
)测试数据:
INSERT INTO t_score(stuid,subject,score) VALUES ('001','Java基础',90);
INSERT INTO t_score(stuid,subject,score) VALUES ('001','mysql',92);
INSERT INTO t_score(stuid,subject,score) VALUES ('001','Javaweb',80);
INSERT INTO t_score(stuid,subject,score) VALUES ('002','Java基础',88);
INSERT INTO t_score(stuid,subject,score) VALUES ('002','mysql',90);
INSERT INTO t_score(stuid,subject,score) VALUES ('002','Javaweb',75.5);
INSERT INTO t_score(stuid,subject,score) VALUES ('002','ssm',100);
INSERT INTO t_score(stuid,subject,score) VALUES ('003','Java基础',70);
INSERT INTO t_score(stuid,subject,score) VALUES ('003','mysql',85);
INSERT INTO t_score(stuid,subject,score) VALUES ('003','Javaweb',90);
INSERT INTO t_score(stuid,subject,score) VALUES ('003','ssm',82);SELECT * FROM t_score; 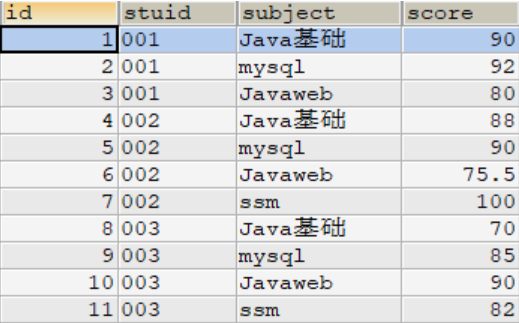
需求:行转列显示学生直观显示学生各科成绩
SELECT stuid ,
SUM(IF(SUBJECT = 'Java基础' , score , NULL)) 'Java基础',
SUM(IF(SUBJECT = 'mysql' , score , NULL)) 'mysql',
SUM(IF(SUBJECT = 'Javaweb' , score , NULL)) 'Javaweb',
SUM(IF(SUBJECT = 'ssm' , score , NULL)) 'ssm'
FROM t_score
GROUP BY stuid; 
5. 删除重复行
插入重复数据:
INSERT INTO t_score(stuid,SUBJECT,score) VALUES ('001','Java基础',5);
INSERT INTO t_score(stuid,SUBJECT,score) VALUES ('001','mysql',90);
INSERT INTO t_score(stuid,SUBJECT,score) VALUES ('001','Javaweb',1);
INSERT INTO t_score(stuid,SUBJECT,score) VALUES ('002','Java基础',22);
INSERT INTO t_score(stuid,SUBJECT,score) VALUES ('002','mysql',55);
INSERT INTO t_score(stuid,SUBJECT,score) VALUES ('002','Javaweb',1.5);
INSERT INTO t_score(stuid,SUBJECT,score) VALUES ('002','ssm',2);SELECT * FROM t_score ORDER BY stuid,SUBJECT; 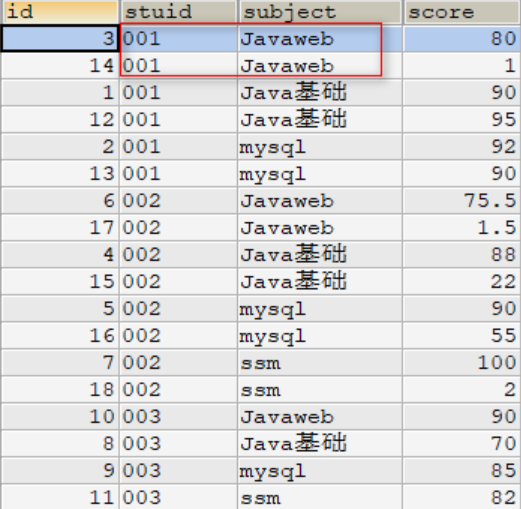
需求:每个学生同一学科有多个成绩的,保留分数高的
DELETE FROM t_score WHERE id NOT IN(
SELECT tmp.id FROM
(SELECT id FROM t_score t1 JOIN (
SELECT stuid , SUBJECT , MAX(score) m_score
FROM t_score
GROUP BY stuid , SUBJECT) t2
ON t1.`stuid` = t2.stuid
AND t1.`subject` = t2.subject
AND t1.`score` = t2.m_score)tmp
);SET @stuid:=0;
SET @subject:='';
SET @rank:= 1;
DELETE FROM t_score WHERE id IN(
SELECT id
FROM(
SELECT * , IF(@stuid = stuid , IF(@subject = SUBJECT , @rank:=@rank+1 ,@rank:=1) , @rank:=1) 'rank',
@stuid:=stuid , @subject:=SUBJECT
FROM t_score
ORDER BY stuid , SUBJECT ,score DESC) tmp
WHERE tmp.rank !=1);6. 窗口函数
窗口函数和普通聚合函数很容易混淆,二者区别如下:
Ø 聚合函数是将多条记录聚合为一条
Ø 窗口函数是每条记录都会执行,有几条记录执行完还是几条
按照功能划分,可以把MySQL支持的窗口函数分为如下几类:
# 序号函数:没有参数
row_number()/rank()/dense_rank()
# 分布函数:没有参数
percent_rank():所在行数/总行数的百分比
cume_dist():累积分布值
# 前后函数:参数有3个(expr:列名;n:偏移量;default_value:超出记录窗口的默认值)
lag(): 从当前行开始往前获取第N行,缺失则使用默认值
lead():从当前行开始往后获取第N行,缺失则使用默认值
# 头尾函数: 参数1个(expr:列名)
first_value():返回分组内截止当前行的第一个值
last_value():返回分组内截止当前行的最后一个值
# 其他函数:
-- 参数有2个(expr:列名;n:偏移量)
nth_value():返回分组内截止当前行的第N行
-- 参数有1个(expr:列名;)
ntile():返回当前行在分组内的分桶号
/*
语法结构:
window_function ( expr ) OVER (
PARTITION BY ...
ORDER BY ...
)
其中,window_function 是窗口函数的名称;
expr 是参数,有些函数不需要参数;OVER子句包含三个选项:
1、分区(PARTITION BY)
PARTITION BY选项用于将数据行拆分成多个分区(组),它的作用类似于GROUP BY分组。如果省略了 PARTITION BY,所有的数据作为一个组进行计算
2、排序(ORDER BY)
OVER 子句中的ORDER BY选项用于指定分区内的排序方式,与 ORDER BY 子句的作用类似
OVER后面括号中的内容可以抽取:
WINDOW w AS (
PARTITION BY ...
ORDER BY ...
)
*/测试窗口函数的使用:
-- 1、查询员工信息和他部门年龄升序排列前一名员工的年龄
SELECT * , lead(age , 1,-1) over(
PARTITION BY deptId
) last_emp_age
FROM t_emp;
-- 2、查询每个员工在自己部门由大到小的年龄排名
select * ,
row_number() over(PARTITION BY deptid ORDER BY age DESC) as row_num,
from t_emp;
# 或者
SELECT * ,
row_number() over w AS row_num # w代表使用的
FROM t_emp
WINDOW w AS(PARTITION BY deptid ORDER BY age DESC);接下来,我们来实现这么一个需求:查询员工表中每个部门的的年龄前两名
-- 查询每个员工所在部门的其他员工 如果年龄大于等于自己的小于等于两个,则保留自己的数据
SELECT * FROM t_emp t1
WHERE (SELECT COUNT(1) FROM t_emp t2 WHERE t2.`deptId`=t1.`deptId` AND t2.age>=t1.`age`)<=2
ORDER BY t1.`deptId` DESC, t1.age DESC;上面的SQL是不是不好理解,接下来我们采用窗口函数看看如何优雅的实现同样的功能
select * from(
select row_number() over(partition by deptid order by age desc) as row_num,
id,name,sal,deptid
from t_emp
) t where row_num <= 2








![JavaSE-06 [面向对象+封装]](https://img-blog.csdnimg.cn/fae25c221d65480086de5dad9760715a.png)