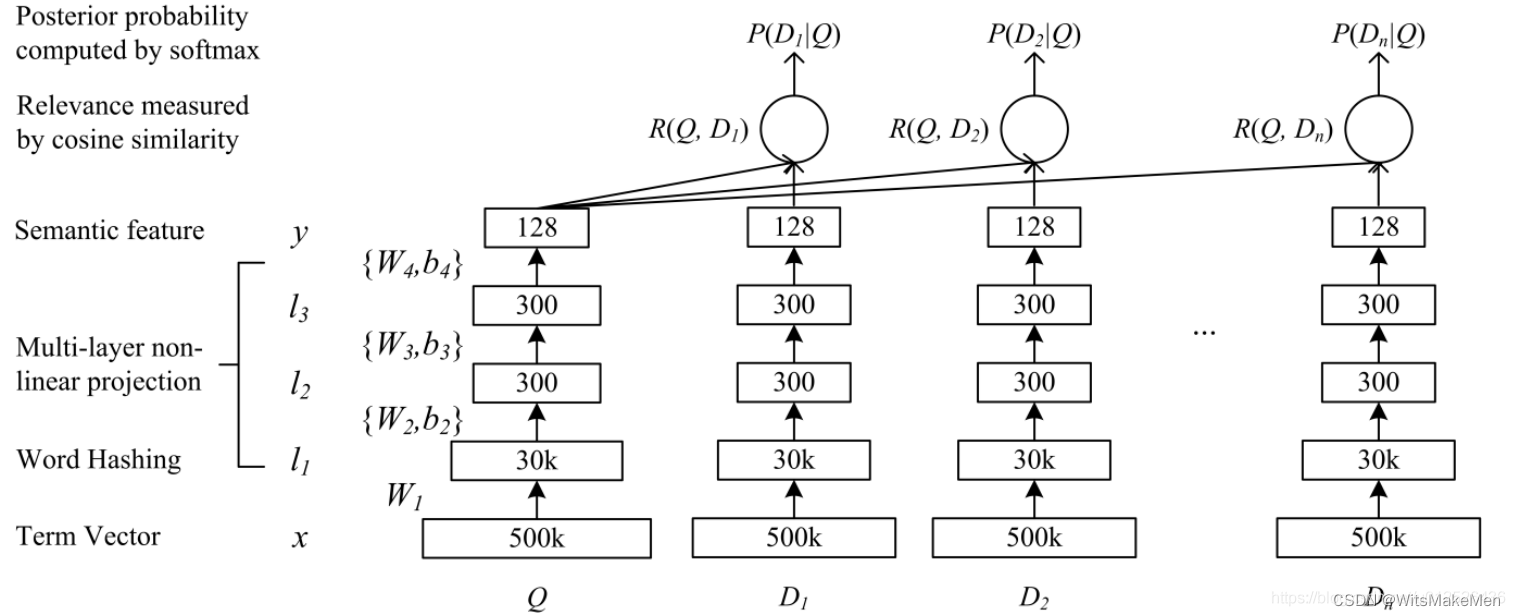
最近在学习向量召回,向量召回不得不用到dssm双塔模型,双塔模型的原理非常简单,就是用两个任务塔,一个是query侧的query任务塔,另一个是doc侧的doc任务塔,任务塔向上抽象形成verctor隐向量后,用cosin相似度度计算两个向量之间的相似程度,进而让query和doc的向量尽量的相近。
模型整体的结构如下所示,线上工程使用的时候,是将doc的隐向量进行离线保存,用faiss类似工具形成线上的向量检索索引,然后线上用户query查询的时候,就可以通过线上部署的query侧任务塔,实时的生成query侧的隐向量,然后通过query隐向量去查询faiss中相似的doc向量结果,达到query语义召回的目的。
代码:模型中的encoder是可以用任何nlp编码模型实现,比如说可以用预训练的bert实现。
class DSSM(nn.Module):
"""
DSSM(Deep Structured Semantic Model) 模型实现, 采用cos值计算向量相似度, 精度稍低, 但计算速度快。
Paper Reference: https://posenhuang.github.io/papers/cikm2013_DSSM_fullversion.pdf
Args:
nn (_type_): _description_
"""
def __init__(self, encoder, dropout=None):
"""
init func.
Args:
encoder (transformers.AutoModel): backbone, 默认使用 ernie 3.0
dropout (float): dropout.
"""
super().__init__()
self.encoder = encoder
hidden_size = 768
self.dropout = nn.Dropout(dropout if dropout is not None else 0.1)
def forward(
self,
input_ids: torch.tensor,
token_type_ids: torch.tensor,
attention_mask: torch.tensor
) -> torch.tensor:
"""
forward 函数,输入单句子,获得单句子的embedding。
Args:
input_ids (torch.LongTensor): (batch, seq_len)
token_type_ids (torch.LongTensor): (batch, seq_len)
attention_mask (torch.LongTensor): (batch, seq_len)
Returns:
torch.tensor: embedding -> (batch, hidden_size)
"""
embedding = self.encoder(
input_ids=input_ids,
token_type_ids=token_type_ids,
attention_mask=attention_mask
)["pooler_output"] # (batch, hidden_size)
return embedding
def get_similarity(
self,
query_input_ids: torch.tensor,
query_token_type_ids: torch.tensor,
query_attention_mask: torch.tensor,
doc_input_ids: torch.tensor,
doc_token_type_ids: torch.tensor,
doc_attention_mask: torch.tensor
) -> torch.tensor:
"""
输入query和doc的向量,返回query和doc两个向量的余弦相似度。
Args:
query_input_ids (torch.LongTensor): (batch, seq_len)
query_token_type_ids (torch.LongTensor): (batch, seq_len)
query_attention_mask (torch.LongTensor): (batch, seq_len)
doc_input_ids (torch.LongTensor): (batch, seq_len)
doc_token_type_ids (torch.LongTensor): (batch, seq_len)
doc_attention_mask (torch.LongTensor): (batch, seq_len)
Returns:
torch.tensor: (batch, 1)
"""
print('query_input_ids=', query_input_ids, query_input_ids.shape)
# print('query_token_type_ids=', query_token_type_ids)
# print('query_attention_mask=', query_attention_mask)
query_embedding = self.encoder(
input_ids=query_input_ids,
token_type_ids=query_token_type_ids,
attention_mask=query_attention_mask
)["pooler_output"] # (batch, hidden_size)
print('query_embedding=', query_embedding, query_embedding.shape)
query_embedding = self.dropout(query_embedding)
doc_embedding = self.encoder(
input_ids=doc_input_ids,
token_type_ids=doc_token_type_ids,
attention_mask=doc_attention_mask
)["pooler_output"] # (batch, hidden_size)
doc_embedding = self.dropout(doc_embedding)
similarity = nn.functional.cosine_similarity(query_embedding, doc_embedding)
return similarity
train代码:
# !/usr/bin/env python3
import os
import time
import argparse
from functools import partial
import torch
from torch.utils.data import DataLoader
import evaluate
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModel, default_data_collator, get_scheduler
from model import DSSM
from utils import convert_dssm_example
from iTrainingLogger import iSummaryWriter
parser = argparse.ArgumentParser()
parser.add_argument("--model", default='bert-base-chinese', type=str, help="backbone of encoder.")
parser.add_argument("--train_path", default='./data/dssm_data/train.csv', type=str, help="The path of train set.")
parser.add_argument("--dev_path", default='./data/dssm_data/train.csv', type=str, help="The path of dev set.")
parser.add_argument("--save_dir", default="./checkpoints", type=str, required=False, help="The output directory where the model predictions and checkpoints will be written.")
parser.add_argument("--max_seq_len", default=512, type=int,help="The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded.", )
parser.add_argument("--batch_size", default=16, type=int, help="Batch size per GPU/CPU for training.", )
parser.add_argument("--learning_rate", default=1e-5, type=float, help="The initial learning rate for Adam.")
parser.add_argument("--weight_decay", default=0.0, type=float, help="Weight decay if we apply some.")
parser.add_argument("--num_train_epochs", default=10, type=int, help="Total number of training epochs to perform.")
parser.add_argument("--warmup_ratio", default=0.06, type=float, help="Linear warmup over warmup_ratio * total_steps.")
parser.add_argument("--valid_steps", default=200, type=int, required=False, help="evaluate frequecny.")
parser.add_argument("--logging_steps", default=10, type=int, help="log interval.")
parser.add_argument('--device', default="cpu", help="Select which device to train model, defaults to gpu.")
parser.add_argument("--img_log_dir", default='logs', type=str, help="Logging image path.")
parser.add_argument("--img_log_name", default='Model Performance', type=str, help="Logging image file name.")
args = parser.parse_args()
writer = iSummaryWriter(log_path=args.img_log_dir, log_name=args.img_log_name)
def evaluate_model(model, metric, data_loader, global_step):
"""
在测试集上评估当前模型的训练效果。
Args:
model: 当前模型
metric: 评估指标类(metric)
data_loader: 测试集的dataloader
global_step: 当前训练步数
"""
model.eval()
with torch.no_grad():
for step, batch in enumerate(data_loader):
logits = model.get_similarity(query_input_ids=batch['query_input_ids'].to(args.device),
query_token_type_ids=batch['query_token_type_ids'].to(args.device),
query_attention_mask=batch['query_attention_mask'].to(args.device),
doc_input_ids=batch['doc_input_ids'].to(args.device),
doc_token_type_ids=batch['doc_token_type_ids'].to(args.device),
doc_attention_mask=batch['doc_attention_mask'].to(args.device))
logits[logits>=0.5] = 1
logits[logits<0.5] = 0
metric.add_batch(predictions=logits.to(torch.int), references=batch["labels"])
eval_metric = metric.compute()
model.train()
return eval_metric['accuracy'], eval_metric['precision'], eval_metric['recall'], eval_metric['f1']
def train():
encoder = AutoModel.from_pretrained(args.model)
model = DSSM(encoder)
tokenizer = AutoTokenizer.from_pretrained(args.model)
dataset = load_dataset('text', data_files={'train': args.train_path,
'dev': args.dev_path})
print(dataset)
convert_func = partial(convert_dssm_example, tokenizer=tokenizer, max_seq_len=args.max_seq_len)
dataset = dataset.map(convert_func, batched=True)
train_dataset = dataset["train"]
eval_dataset = dataset["dev"]
train_dataloader = DataLoader(train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=args.batch_size)
eval_dataloader = DataLoader(eval_dataset, collate_fn=default_data_collator, batch_size=args.batch_size)
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": args.weight_decay,
},
{
"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
},
]
optimizer = torch.optim.AdamW(optimizer_grouped_parameters, lr=5e-5)
model.to(args.device)
# 根据训练轮数计算最大训练步数,以便于scheduler动态调整lr
num_update_steps_per_epoch = len(train_dataloader)
max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
warm_steps = int(args.warmup_ratio * max_train_steps)
lr_scheduler = get_scheduler(
name='linear',
optimizer=optimizer,
num_warmup_steps=warm_steps,
num_training_steps=max_train_steps,
)
loss_list = []
metric = evaluate.combine(["accuracy", "f1", "precision", "recall"])
criterion = torch.nn.MSELoss()
tic_train = time.time()
global_step, best_f1 = 0, 0
for epoch in range(1, args.num_train_epochs+1):
for batch in train_dataloader:
logits = model.get_similarity(query_input_ids=batch['query_input_ids'].to(args.device),
query_token_type_ids=batch['query_token_type_ids'].to(args.device),
query_attention_mask=batch['query_attention_mask'].to(args.device),
doc_input_ids=batch['doc_input_ids'].to(args.device),
doc_token_type_ids=batch['doc_token_type_ids'].to(args.device),
doc_attention_mask=batch['doc_attention_mask'].to(args.device))
labels = batch['labels'].to(torch.float).to(args.device)
loss = criterion(logits, labels)
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
loss_list.append(float(loss.cpu().detach()))
if global_step % args.logging_steps == 0:
time_diff = time.time() - tic_train
loss_avg = sum(loss_list) / len(loss_list)
writer.add_scalar('train/train_loss', loss_avg, global_step)
print("global step %d, epoch: %d, loss: %.5f, speed: %.2f step/s"
% (global_step, epoch, loss_avg, args.logging_steps / time_diff))
tic_train = time.time()
if global_step % args.valid_steps == 0:
cur_save_dir = os.path.join(args.save_dir, "model_%d" % global_step)
if not os.path.exists(cur_save_dir):
os.makedirs(cur_save_dir)
torch.save(model, os.path.join(cur_save_dir, 'model.pt'))
tokenizer.save_pretrained(cur_save_dir)
acc, precision, recall, f1 = evaluate_model(model, metric, eval_dataloader, global_step)
writer.add_scalar('eval/accuracy', acc, global_step)
writer.add_scalar('eval/precision', precision, global_step)
writer.add_scalar('eval/recall', recall, global_step)
writer.add_scalar('eval/f1', f1, global_step)
writer.record()
print("Evaluation precision: %.5f, recall: %.5f, F1: %.5f" % (precision, recall, f1))
if f1 > best_f1:
print(
f"best F1 performence has been updated: {best_f1:.5f} --> {f1:.5f}"
)
best_f1 = f1
cur_save_dir = os.path.join(args.save_dir, "model_best")
if not os.path.exists(cur_save_dir):
os.makedirs(cur_save_dir)
torch.save(model, os.path.join(cur_save_dir, 'model.pt'))
tokenizer.save_pretrained(cur_save_dir)
tic_train = time.time()
global_step += 1
if __name__ == '__main__':
train()