MySQL为什么有了redolog还需要double write buffer?
问题
我们知道MySQL InnoDB引擎使用redolog作为异常容灾恢复的机制,当MySQL进程发生异常退出、机器断电等,在重新启动时,使用redolog恢复。
OK,redolog是被MySQL设计为异常崩溃恢复的,double write buffer同样是为了保证数据完整性,那么既然已经有了redolog,为什么还需要double write buffer(双写缓冲区)呢?
double write buffer
InnoDB用double write buffer(双写缓冲区)来避免页没写完整所导致的数据损坏。当一个磁盘写操作不能完整地完成时,不完整的页写入就可能发生,16KB的页可能只有一部分被写到磁盘上。有多种多样的原因(崩溃、Bug,等等)可能导致页没有写完整。double write buffer在这种情况发生时可以保证数据完整性。
MySQL的buffer一页的大小是16K,但是底层文件系统一页的大小是4K,换句话说,MySQL将一页buffer数据刷入磁盘,需要写4个文件系统里的页。
假如MySQL内page=1的页准备刷入磁盘,才刷了2个(p1和p2)到文件系统里的页,这个时候停电或者机器宕机,当机器恢复后,buffer的一页数据完整性已经遭到破坏,这时MySQL通过double write buffer来解决数据损坏。
double write buffer是表空间一个特殊的保留区域,在一些连续的块中足够保存100个页。本质上是一个最近写回的页面的备份拷贝。当InnoDB从缓冲池刷新页面到磁盘时,首先把它们写(或者刷新)到double write buffer,然后再把它们写到其所属的数据区域中。这可以保证每个页面的写人都是原子并且持久化的。
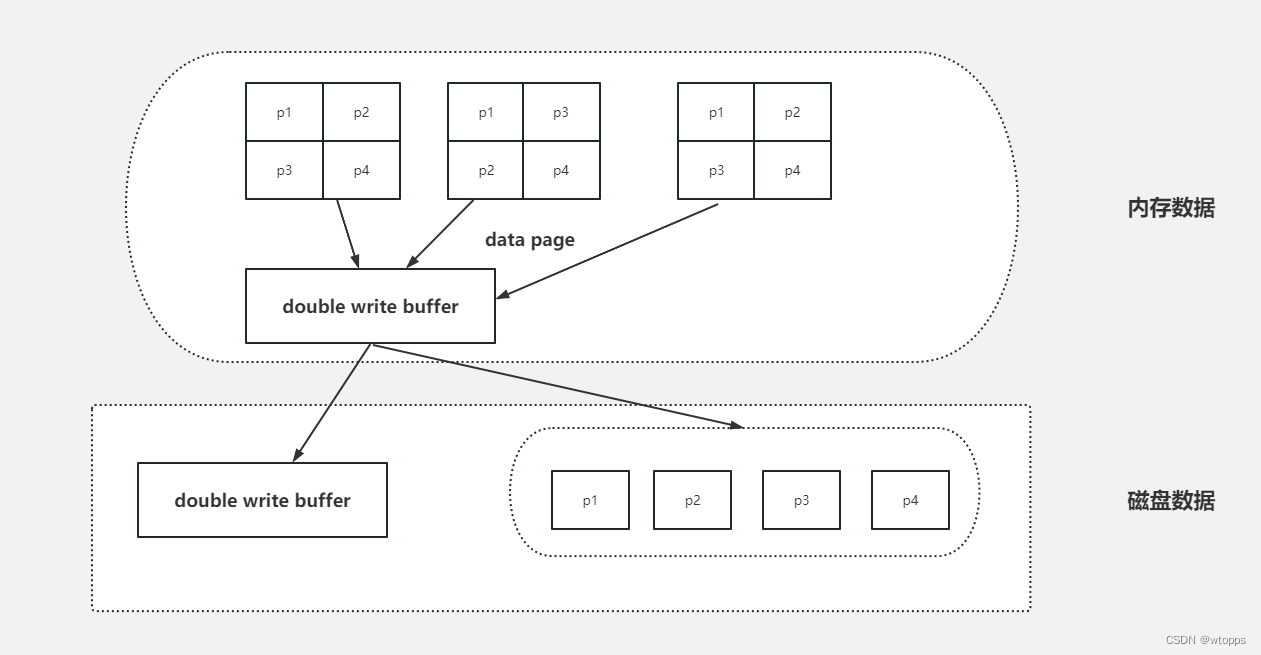
如果有一个不完整的页写到了double write buffer,原始的页依然会在磁盘上它的真实位置。当InnoDB恢复时,它将用原始页面替换掉双写缓冲中的损坏页面。
然而,如果double write buffer成功写人,但写到页的真实位置失败了,InnoDB在恢复时将使用双写缓冲中的拷贝来替换。
InnoDB知道什么时候页面损坏了,因为每个页面在末尾都有校验值(Checksum)。校验值是最后写到页面的东西,所以如果页面的内容跟校验值不匹配,说明这个页面是损坏的。因此,在恢复的时候,InnoDB只需要读取double write buffer中每个页面并且验证校验值。如果一个页面的校验值不对,就从它的原始位置读取这个页面。
我们来梳理一下整个数据页落盘刷新的过程:
- buffer数据页先copy到double write buffer的内存里;
- double write buffer的内存数据刷到double write buffer的磁盘上;
- double write buffer的内存再刷到数据磁盘上;
当MySQL出现异常崩溃时,有如下几种情况发生:
情况一:步骤1前宕机,刷盘未开始,数据在redo log,后期可以恢复
情况二:步骤1后,步骤2前宕机,因为是在内存中,宕机清空内存,和情况1一样
情况三:步骤2后,步骤3前宕机,因为DWB的磁盘有完整的数据,可以修复损坏的页数据
由此我们可以得出结论,double write buffer是针对实际的buffer数据页的原子性保证,就是避免MySQL异常崩溃时,写的那几个data page不会出错,要么都写了,要么什么都没有做。
为什么redolog无法代替double write buffer?
redolog的设计之初,是“账本的作用”,是一种操作日志,用于MySQL异常崩溃恢复使用,是InnoDB引擎特有的日志,本质上是物理日志,记录的是 “ 在某个数据页上做了什么修改 ” ,但如果数据页本身已经发生了损坏,redolog来恢复已经损坏的数据块是无效的,数据块的本身已经损坏,再次重做依然是一个坏块。
所以此时需要一个数据块的副本来还原该损坏的数据块,再利用重做日志进行其他数据块的重做操作,这就是double write buffer的原因作用。
因此,double write buffer与redolog对于容灾场景,缺一不可。
本文参考:
《高性能MySQL第三版》