ERNIE 2.0 提出了一种持续学习的预训练框架:预训练使用了7种任务,而不是一两种简单的任务。不断引入新的预训练任务,让模型可以持续性地学习不同的预训练任务,并且不会遗忘先前学习的知识,以此让模型能够获得更为全面的表征能力。
ERNIE 2.0: A Continual Pre-Training Framework for Language Understanding
1 ERNIE 2.0简介
就像是我们学习一个新语言的时候,我们需要很多之前的知识,在这些知识的基础上,我们可以更快地学习新语言,如此就有了迁移学习的效果。我们的语言模型如果增加多个任务的话,是不是可以获得更好的效果?
事实上,经发现,ERNIE 1.0 加了DLM任务以及其他的模型。如Albert 加了sentence order prediction(SOP)任务、SpanBERT: Improving Pre-training by Representing and Predicting Spans在加上了SBO目标之后 ,模型效果得到了进一步的优化,在预训练的阶段中加入多个下游任务(有监督)进行多任务学习,可以得到state-of-the-art的效果。

2 ERNIE 2.0预训练任务
2-1 Continual Pre-training
ERNIE 2.0提出了一个持续学习的框架,利用这个框架,模型可以持续添加任务但又不降低之前任务的精度,从而能够更好更有效地获得词法lexical,句法syntactic,语义semantic上的表达。
2-1-1 任务构建
百度把语言模型的任务归类为三大类,模型可以持续学习新的任务。
- 字层级的任务(word-aware pretraining task)
- 句结构层级的任务(structure-aware pretraining task)
- 语义层级的任务(semantic-aware pretraining task)
2-1-2 任务难点
持续的多任务学习对于持续的多任务学习,主要需要攻克两个难点:
1.如何保证模型不忘记之前的任务?
常规的持续学习框架采用的是一个任务接一个任务的训练,导致的后果就是模型在最新的任务上得到了好的效果但是在之前的任务上获得很惨的效果(knowledge retention)。
2.模型如何能够有效地训练?
为了解决上一个的问题,有人propose新的方案,我们每次有新的任务进来,我们都从头开始训练一个新的模型不就好了。虽然这种方案可以解决之前任务被忘记的问题,但是这也带来了效率的问题:每次都要从头新训练一个模型,这样子导致效率很低。
2-1-3 解决办法 -sequential multi-task learning
1.序列多任务学习方法
初始化 optimized initialization,当一个阶段加入新的任务时,会使用上一阶段训练好的模型参数进行初始化,并且训练新的任务时,会一起与上个阶段的旧任务进行同步训练。保证模型学习好的参数能够编码前面学到的知识;
2.训练任务安排
对于多个任务,框架将自动的为每个任务在模型训练的不同阶段安排N个训练轮次,即每个任务会按照顺序,一个接着一个,依次训练N步。这样保证了有效率地学习到多任务。如何高效的训练,每个task 都分配有N个训练iteration。
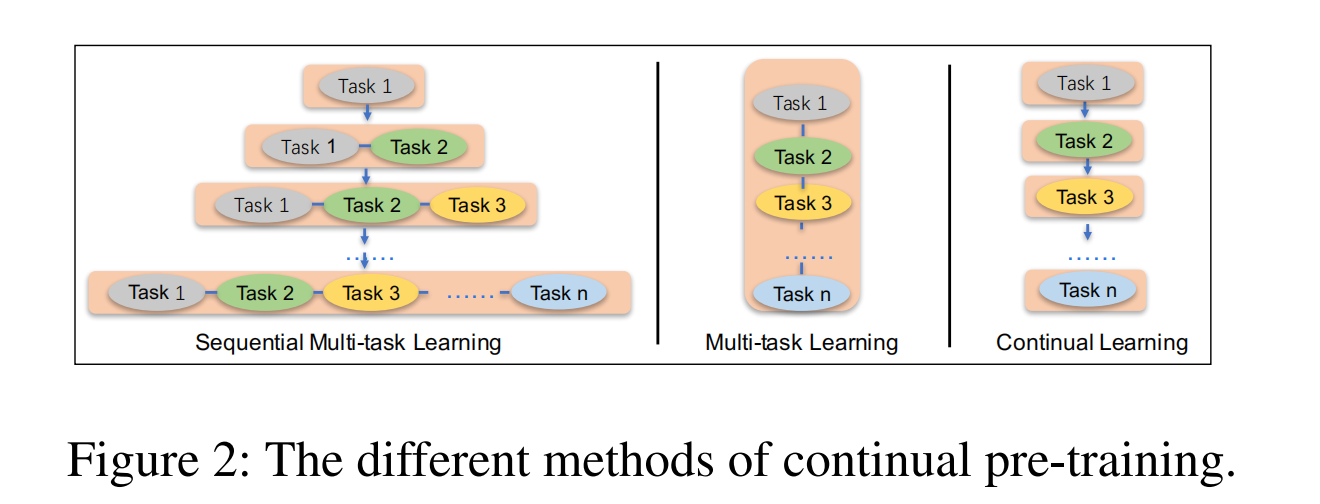
部分任务的语义信息建模适合递进式:比如ERNIE 1.0 突破完形填空ERNIE 2.0 突破选择题,句子排序题等不断递进更新,就好像前面的任务都是打基础,有点boosting的意味。
顺序学习容易导致遗忘模式,所以只适合学习任务之间比较紧密的任务,就好像你今天学了JAVA,明天学了Spring框架,但是如果后天让你学习有机化学,就前后不能够联系起来,之前的知识就忘得快适合递进式的语音建模任务。
2-2 Pre-training Tasks
ERNIE 2.0在训练过程中一共分为三大类,共包含7个预训练任务。
2-2-1 Word-aware Pre-training Tasks(词法层级任务)
1.Knowledge Masking Task
与ERNIE 1.0中的Mask机制相同,这个任务可以帮助模型学习局部和全局上下文的依赖信息,ERNIE 2.0使用这个任务来预训练,得到初始版本的模型;
2.Capitalization Prediction Task(大小写预测)
预测单词是否为大小写。大写的单词相比其他单词,往往有着特别的语义信息。区分大小写的模型对命名实体识别这类任务比较有优势;
3.Token-Document Relation Prediction Task(词频关系)
预测一个词是不是会多次出现在文章中,或者说这个词是不是关键词。根据经验来看,在文档中许多片段都出现的单词往往与主题相关。因此,这个任务可以提升模型捕获关键单词的能力。
2-2-2 Structure-aware Pre-training Tasks(语法层级的任务)
1.Sentence Reordering Task(句子排序)
一个段落被拆分为m个片段并打乱顺序,模型需要预测这m个片段的原始顺序,其实就是一个k分类任务让模型去预测这篇文章是第几种,就是一个多分类的问题。这个问题就能够让模型学到句子之间的顺序关系。就有点类似于Albert的SOP任务的升级版。

2.Sentence Distance Task(句子距离预测)
三分类任务:“0”代表两个句子属于同个文档并且是相邻的,“1”代表两个句子属于同个文档但不是相邻的,“2”则代表两个句子来自不同文档。
这个任务可以让模型通过文档级别的信息,学习句子之间的距离。
2-2-3 Semantic-aware Pre-training Tasks(语义层级的任务)
1.篇章句间关系任务(Discourse Relation Task)
判断句子的语义关系例如logical relationship( is a, has a, contract etc.),预测两个句子的语义或者修饰(rhetorical)关系。数据集出自论文:Mining discourse markers for unsupervised sentence representation learning。
2.信息检索关系任务(IR Relevance Task)
三分类任务,预测query和网页标题的关系。查询文本为第一个句子,标题为第二个句子,模型需要预测这两个句子的关系。
- “0”代表强关联,用户输入可该查询文本并且点击了这个标题。
- “1”代表弱关联,用户输入了该查询,并且这个标题出现在了搜索结果中,但用户并未点击。
- “2”则代表查询文本和标题在语义信息上是随机的,完全不相关的。这个任务可以让模型学习信息检索中的短文本之间的关联。
2-3 Task Embedding
模型加入了一个新的嵌入 Task Embedding,用来表征不同任务的特征,即每一个预训练任务对应着一个id,从0到N。微调阶段,可以使用任意一个任务的id来加载模型。

2-4 训练结构
Encoder可以使用循环神经网络或者Transformer,ERNIE用了Transformer。Encoder参数对于所有任务都是共享的,每个任务都可以更新参数。
其中存在两种损失函数,一种是句子级别的loss,一种的token级别的loss(与BERT类似)。每个预训练任务拥有自己的损失函数。
Token level loss:给每个token一个label。
Sentence level loss:例如句子重排任务,判断[CLS]的输出是那一类别。

在 ERNIE 2.0 中,新构建的预训练任务类型可以无缝的加入训练框架,持续的进行语义理解学习。通过新增的实体预测、句子因果关系判断、文章句子结构重建等语义任务,ERNIE 2.0 语义理解预训练模型从训练数据中获取了词法、句法、语义等多个维度的自然语言信息,极大地增强了通用语义表示能力。
Reference:
1.百度安全验证
2.BERT模型系列大全解读_我就算饿死也不做程序员的博客-CSDN博客