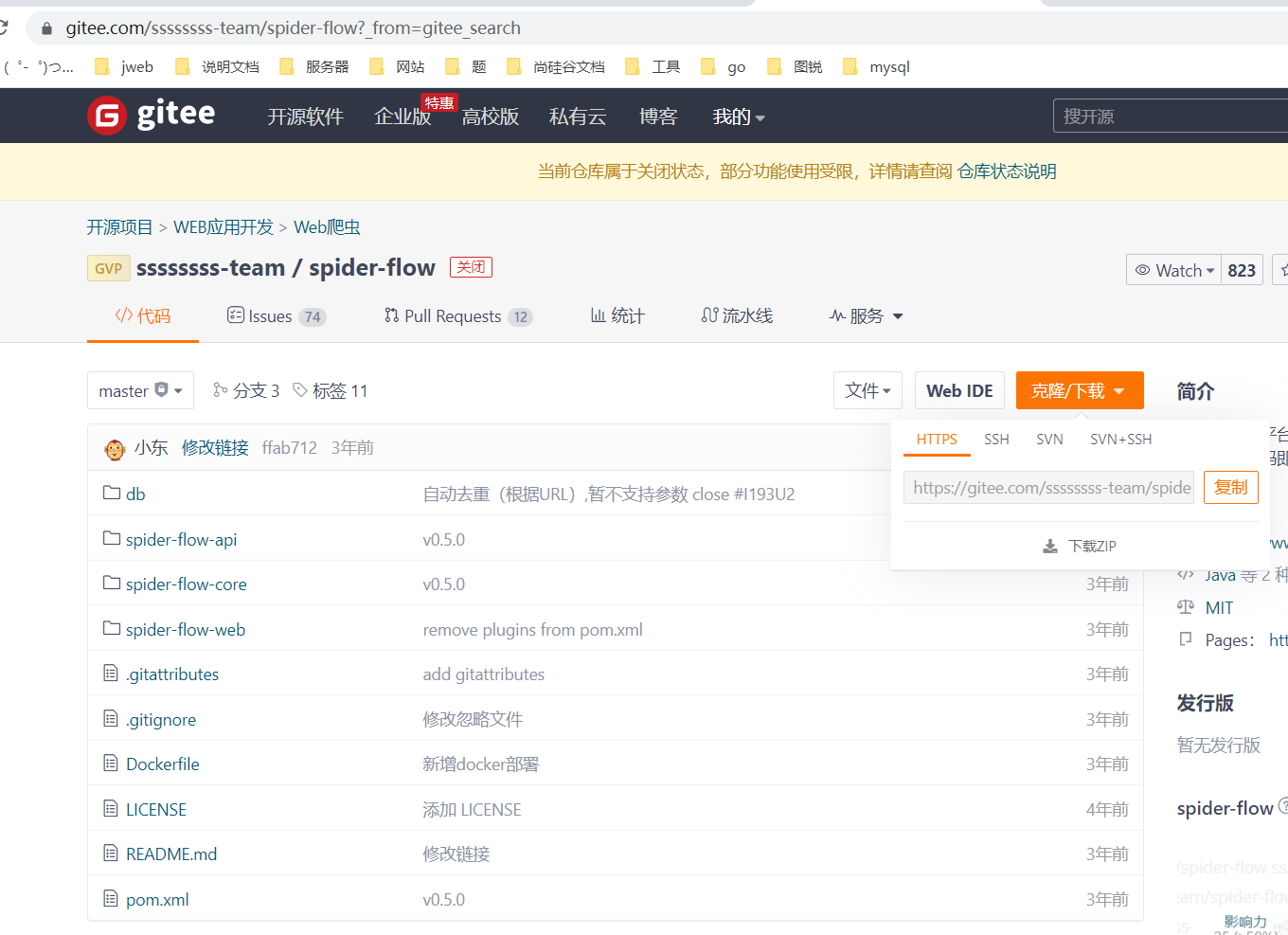
1、简介spider-flow 是一个爬虫平台,以图形化方式定义爬虫流程,无需代码即可实现一个爬虫 官网地址:https://www.spiderflow.org/ 2、spiderflow的初步使用2.1拉取,配置和启动从gitee上拉取
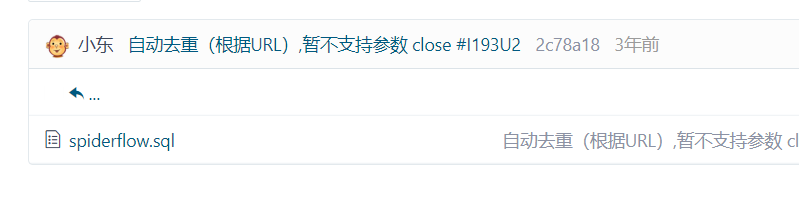
执行db里面的sql
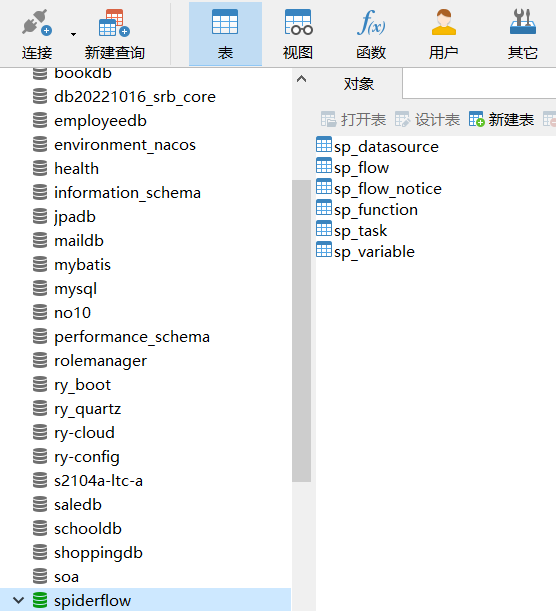
里面会有6张表
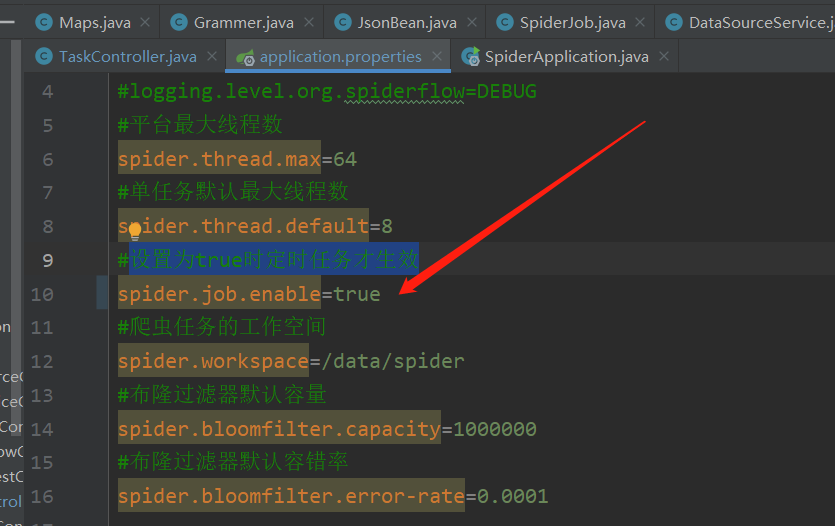
修改配置文件里面的数据库连接的账号密码和地址 修改配置文件里面的开启定时任务,设置为true时定时任务才生效 spider.job.enable=true
直接启动,访问端口号即可,启动成功
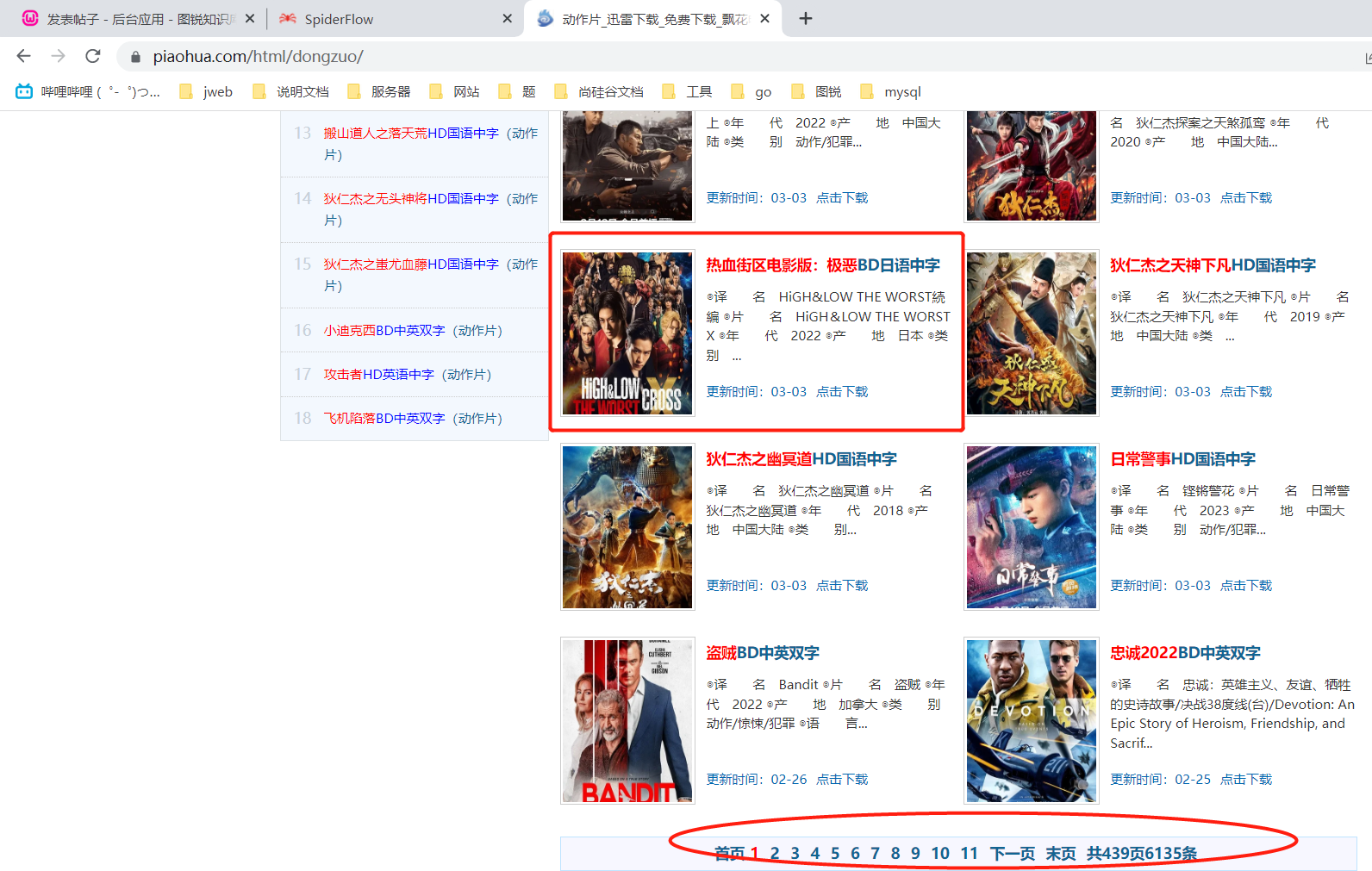
2.2参照实例写一个爬虫2.2.1爬取站点分析 https://www.piaohua.com/html/dongzuo/ 这是一个电影网站
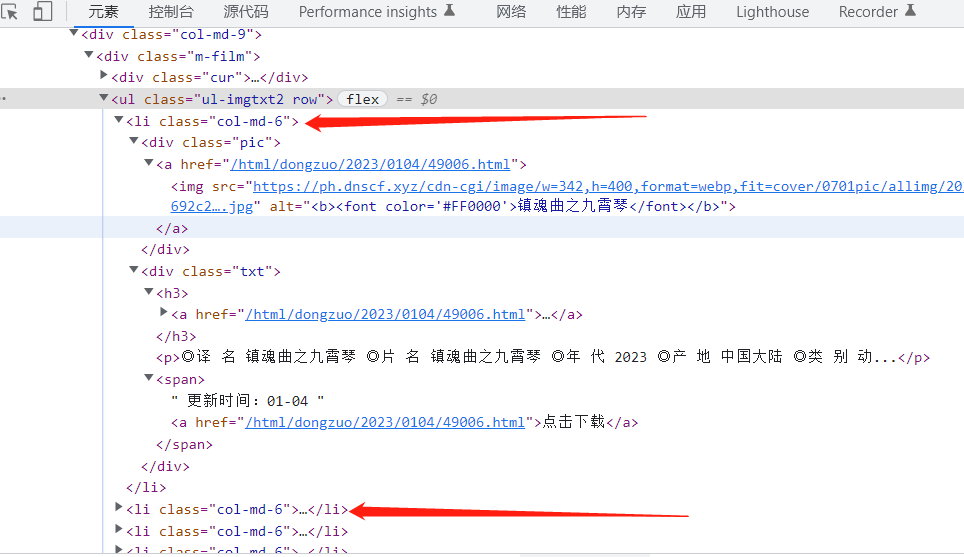
我想爬取的是电影名称,类别,产地等信息 首先查看网页源代码,看获取的信息是否能从网页中拿到,有的是js动态加载的不能直接获取
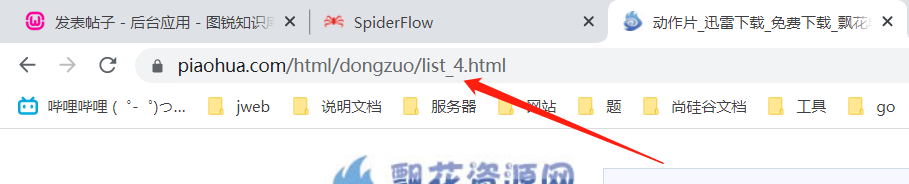
这种可以直接获取 然后试着分析页码,点不同页码的时候连接会发生变化,点第四页,数字就变成了4
然后确定要爬取的信息
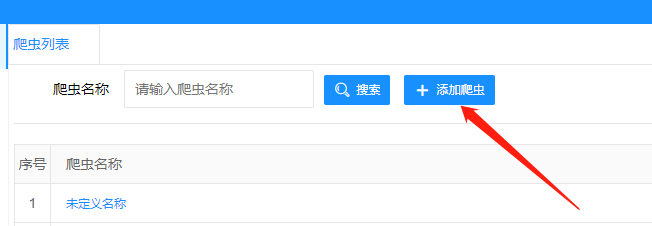
2.2.2开始写爬虫 2.2.2.1新建爬虫
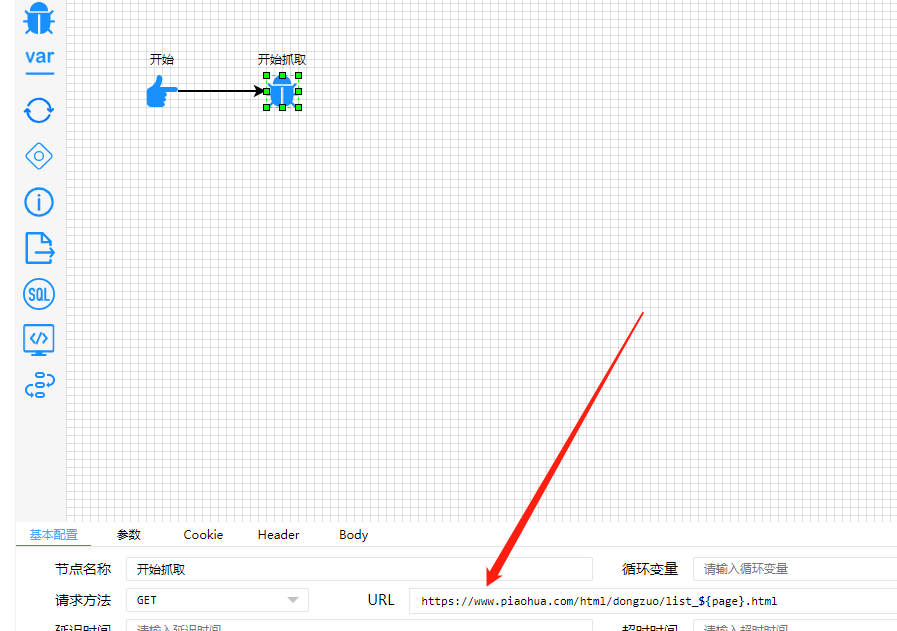
2.2.2.2配置爬虫url 在url中使用${}来放动态参数,类似jquery。(参考官网表达式语法--基本用法--动态拼接url)
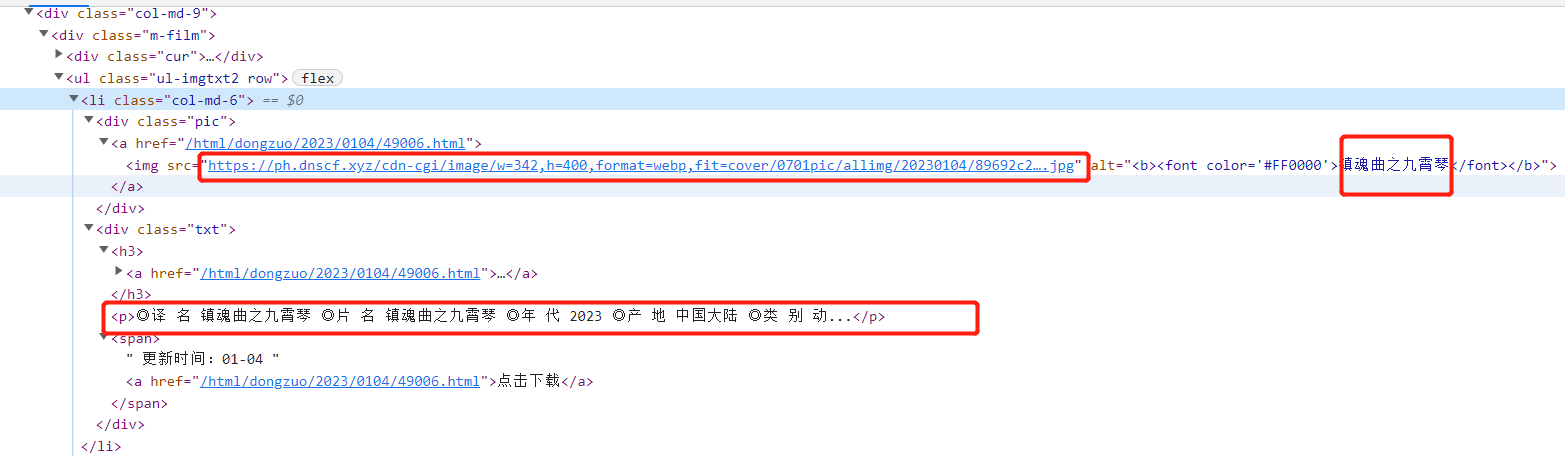
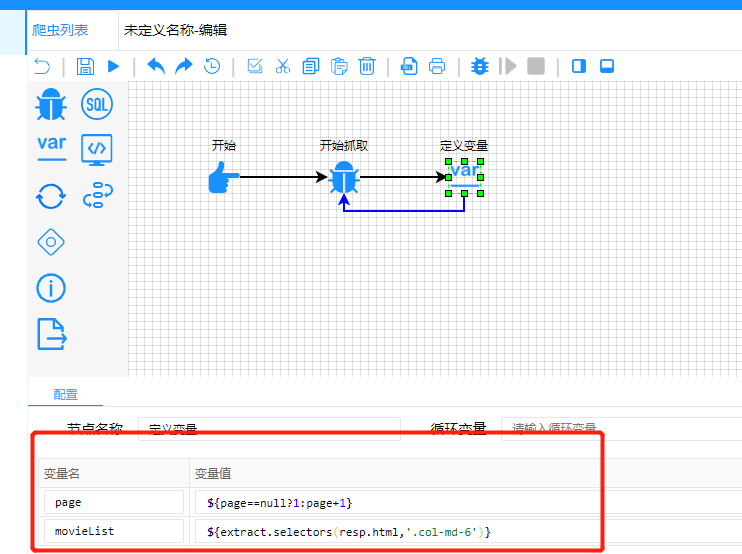
2.2.2.3配置页码和拉取信息 三元运算符和java中的一样(参考官网表达式语法--三元运算符) 获取页面内容 获取页面中class='col-md-6'的所有内容(参考官网 函数说明--抽取函数--selectors)
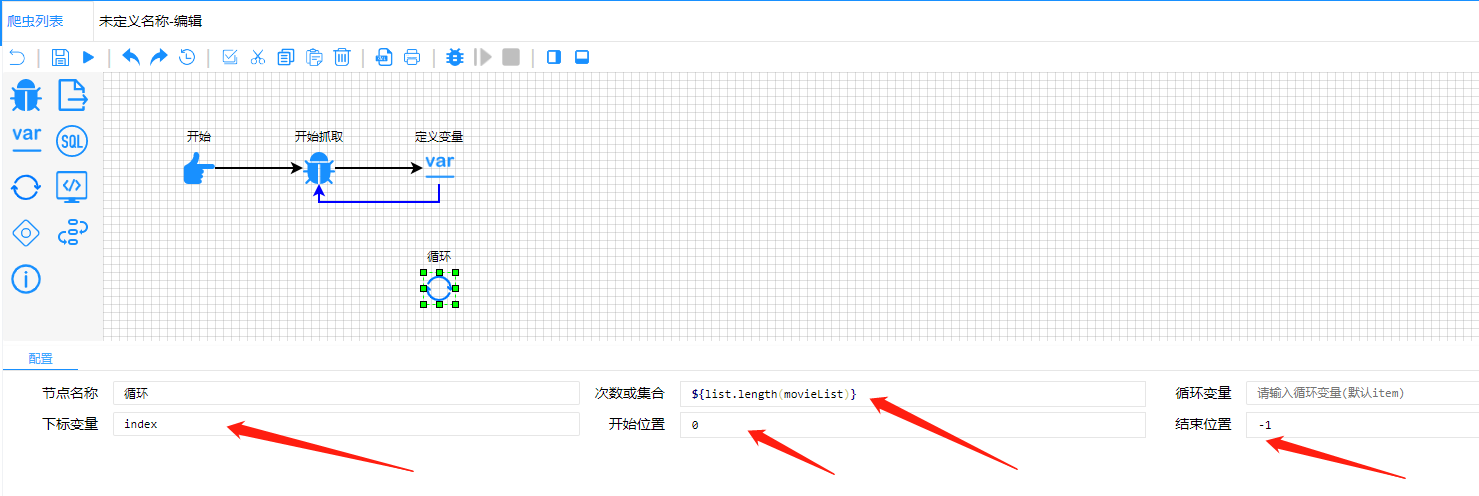
2.2.2.4 遍历 上面的movieList是一个集合,遍历这个集合
参考官网(快速入门--循环节点),list.length是获取集合的长度,参考官网(函数说明--list--length)
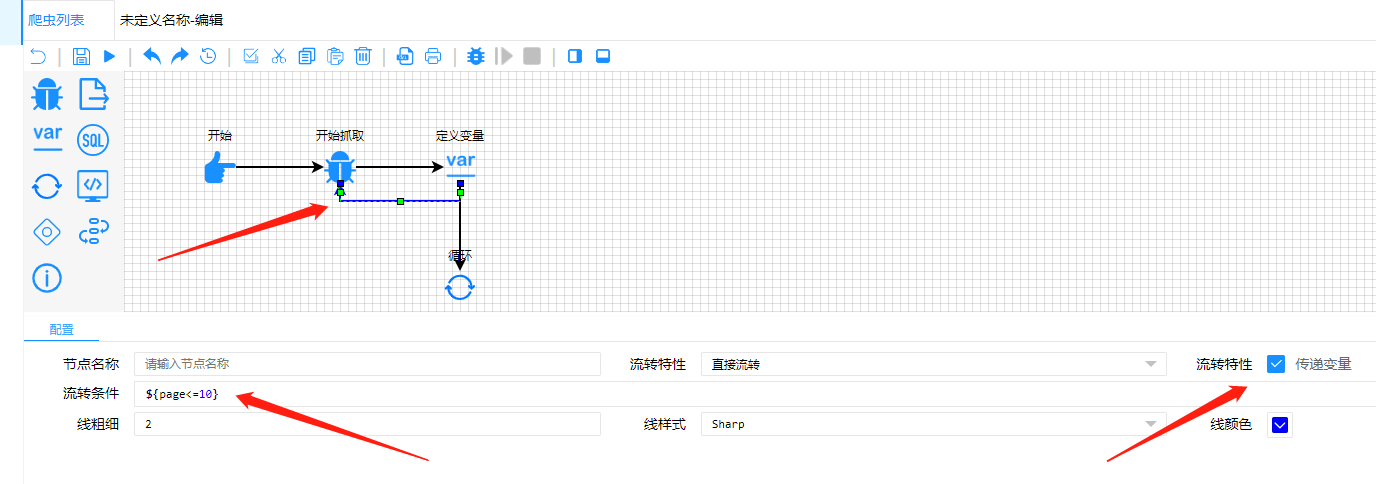
2.2.2.5设置翻页条件 当页码<=10的时候继续爬取 流转条件:当表达式返回
参考官网(快速入门--连接线)
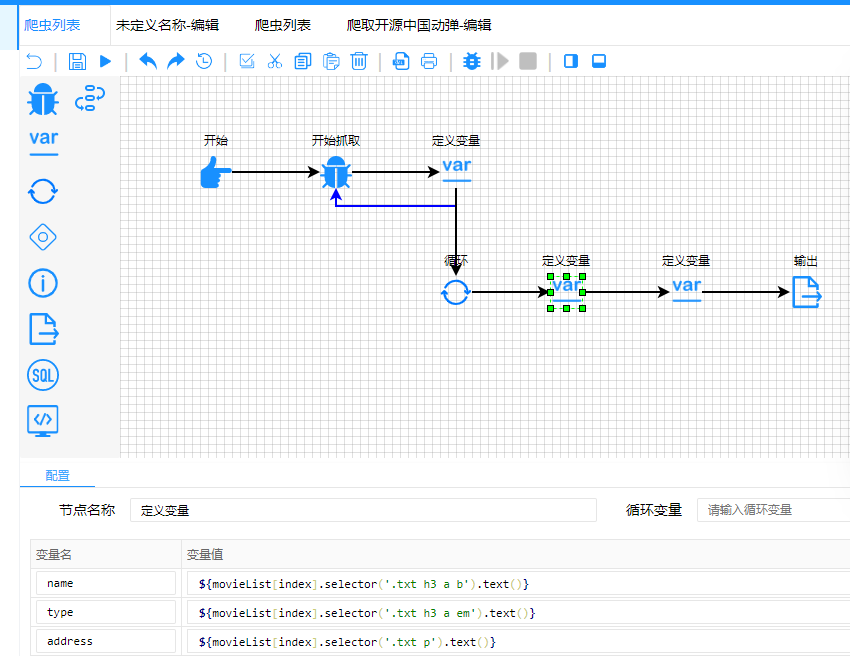
2.2.2.6 定义变量
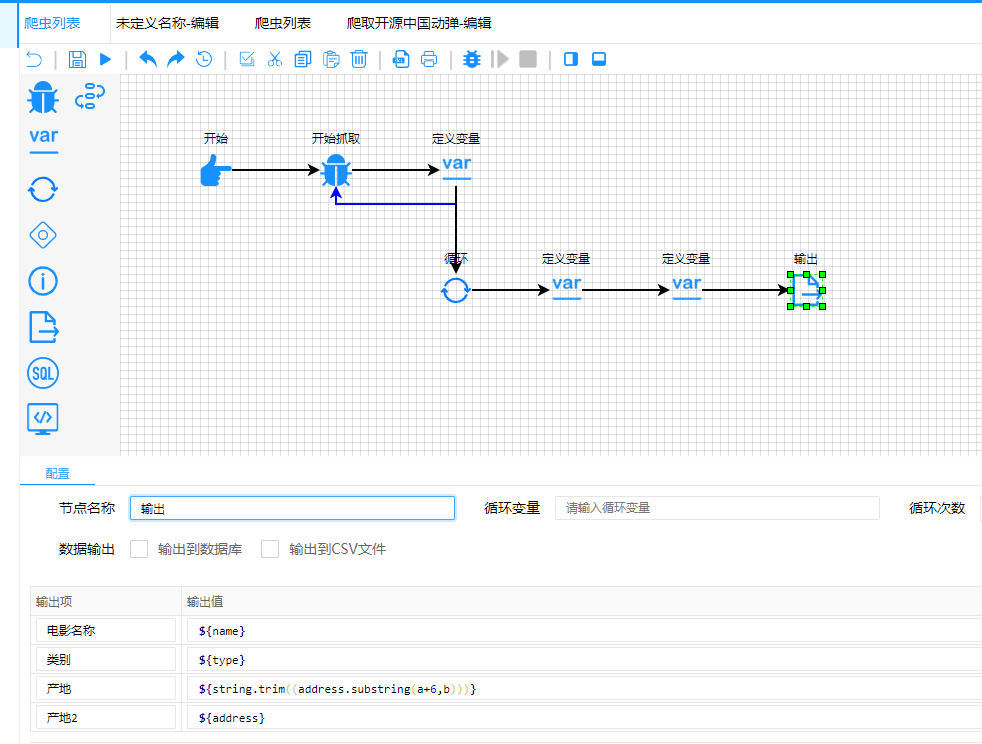
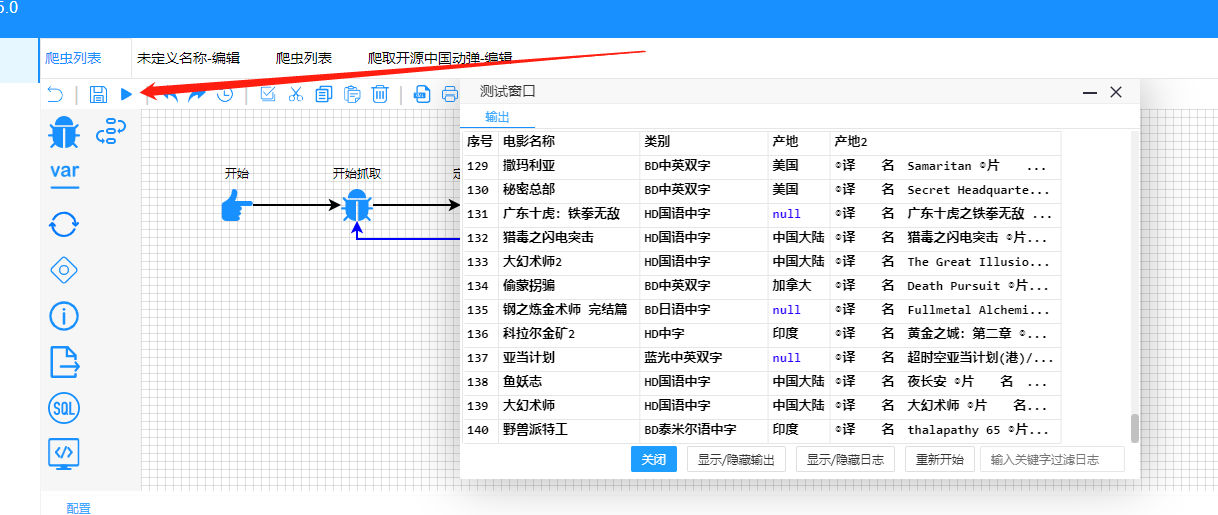
2.2.2.7输出节点
2.2.2.8测试 点击左上角的测试即可看到输出内容
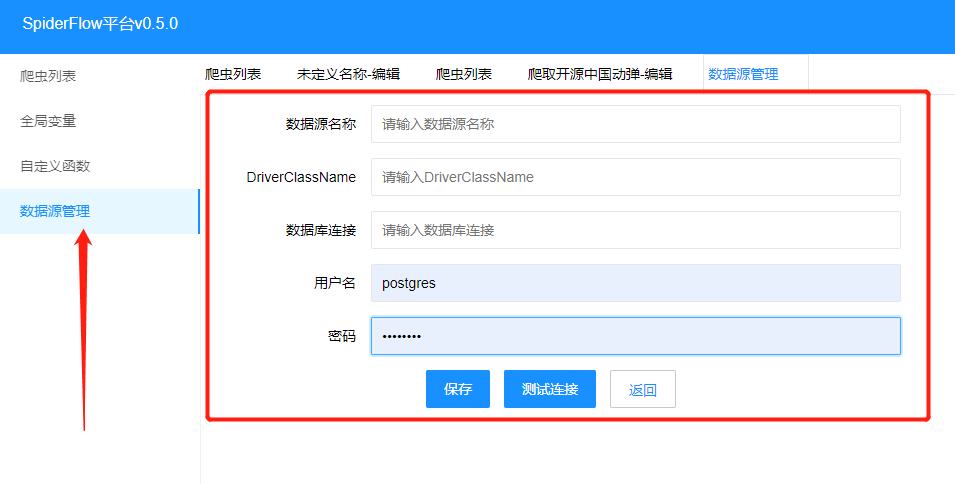
2.2.2.9输出到数据库 1.在输出节点选中输出到数据库 2.添加数据源
3.输出字段和数据库字段保持一致即可 |
spiderflow的初步使用
news2026/2/14 19:54:01



本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/626717.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

为什么说高性能计算工程师越老越吃香?还难以被AI替代?
一般越老越吃香的岗位或者行业,一定是拥有无法或者难以轻易被替代的经验。
这些经验一般是靠时间、靠思维、靠试错不断积累起来的。然而AIGC来了,好像宣布AI会取代所有人一样,如经验丰富的律师、医生、教师等等,尤其是贡献了AIGC…
java ssm贸易平台-物流管理系统myeclipse开发mysql数据库springMVC模式java编程计算机网页设计
一、源码特点 java ssm贸易平台-物流管理系统是一套完善的web设计系统(系统采用SSM框架进行设计开发,springspringMVCmybatis),对理解JSP java编程开发语言有帮助,系统具有完整的源代码和数据库,系统主…
【运维知识进阶篇】用阿里云部署kod可道云网盘(DNS解析+CDN缓存+Web应用防火墙+弹性伸缩)
本篇文章依托kod可道云项目继续介绍阿里云产品,介绍DNS解析,CDN缓存,Web应用防火墙,弹性伸缩。
DNS解析 这里我将二级域名设为kod,一般都是设为www和,带表示可以不加二级域名,直接访问。也可以…

基于html+css的图展示117
准备项目
项目开发工具
Visual Studio Code 1.44.2 版本: 1.44.2 提交: ff915844119ce9485abfe8aa9076ec76b5300ddd 日期: 2020-04-16T16:36:23.138Z Electron: 7.1.11 Chrome: 78.0.3904.130 Node.js: 12.8.1 V8: 7.8.279.23-electron.0 OS: Windows_NT x64 10.0.19044
项目…

Java 八股文-集合框架篇
Java 集合框架
一、常见集合
1.说说有哪些常见集合?
集合相关类和接口都在java.util中,主要分为3种:List(列表)、Map(映射)、Set(集)。
其中Collection是集合List、Set的父接口,…
AI热度降温?揭秘加德纳技术成熟度曲线与AI发展阶段
一文解决你所有对 AI 的焦虑
近期,我们发现ChatGPT的热度似乎不如前几个月。许多人尝试了这个技术,觉得它非常强大,但似乎与自己的日常生活和工作关系不大,因此逐渐失去了兴趣。
然而,这实际上是技术发展的正常周期&…

学术界用ChatGPT写论文,真的靠谱吗?
写论文时,赵铭用ChatGPT查询了国内外云计算技术的研究进展,并请它一一详细介绍。他用搜索引擎简单核实了真实性,润色后就放进了论文中,“我感觉它说的东西都是一些现状,也没什么好调整的,就直接用了&#x…
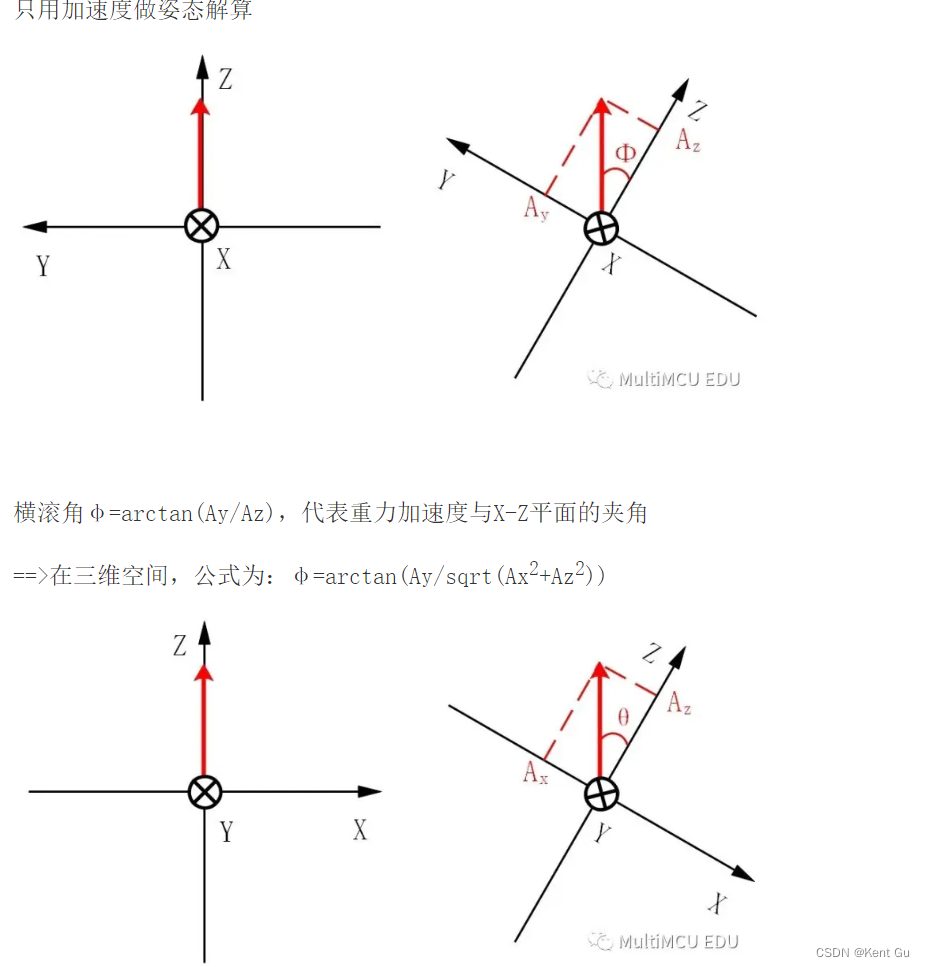

vue安裝及配置 nodejs安装配置
vue安装及配置
vue安装步骤
nodejs安装
安装nodejs环境:https://nodejs.org/en/ 查看node版本:node-v vue3.0需要使用node 8版本以上
npm镜像配置 npm是nodejs内置的资源管理器 npm两个镜像: 淘宝镜像:https://registry.npm.…
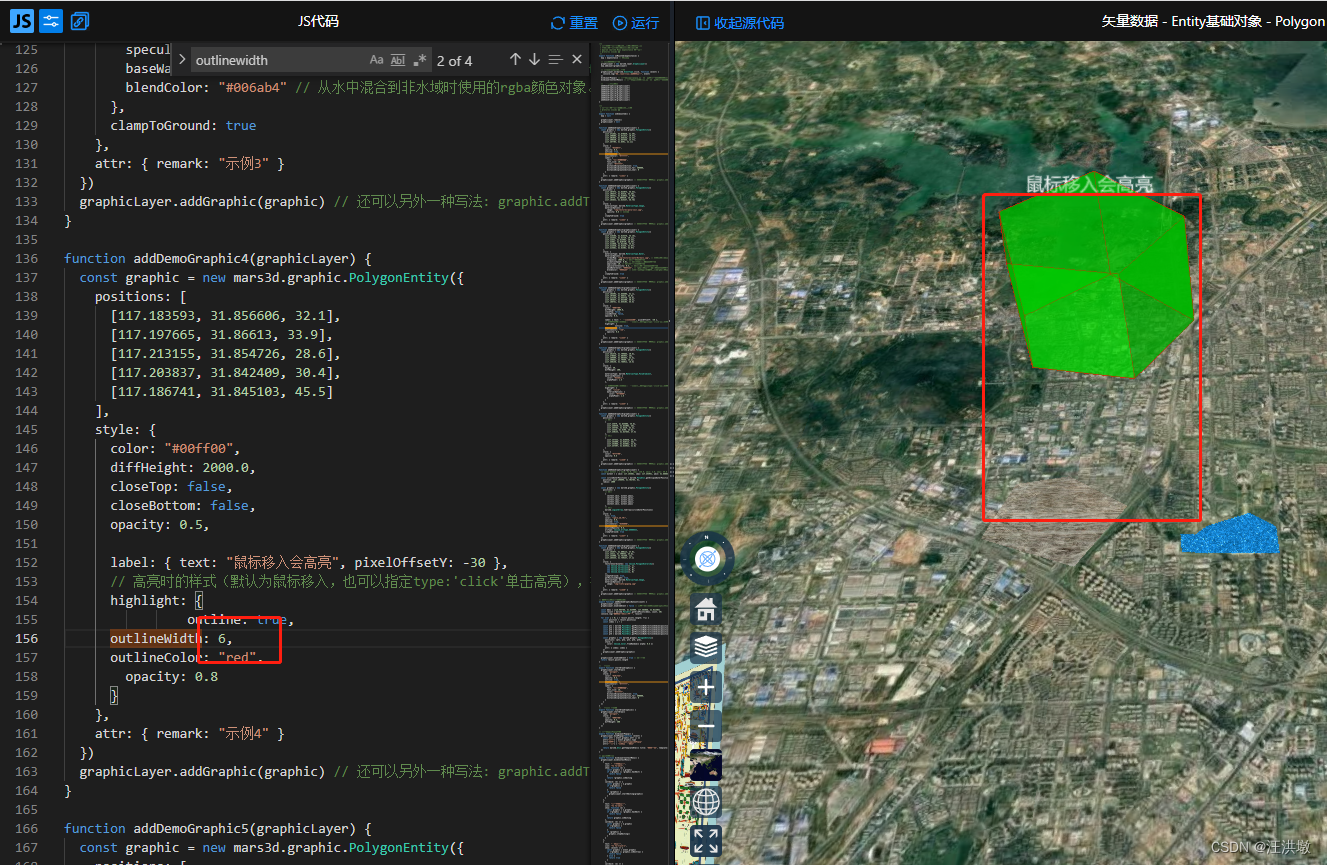
Mars3d的PolygonEntity的边框宽度outlineWidth只能是1
1.Mars3d的PolygonEntity的边框宽度只能是1
2.问题来源:
尝试在Mars3d官网的面的示例中修改高亮样式是,发现修改边框宽度为3或者是10,效果一致
function addDemoGraphic4(graphicLayer) { const graphic new mars3d.graphic.PolygonEntit…

车载以太网网络管理之UDPNM
前言
首先,请问大家几个小小问题,你清楚:
你知道UdpNm模块的主要作用是什么吗?UdpNm模块与其他AUTOSAR基础软件模块交互关系;UdpNm模块的网络管理算法,状态机如何运转?UdpNm模块的PNC功能如何…

TLE4250-2G-ASEMI代理英飞凌汽车芯片TLE4250-2G
编辑:ll
TLE4250-2G-ASEMI代理英飞凌汽车芯片TLE4250-2G
型号:TLE4250-2G
品牌:Infineon(英飞凌)
封装:SCT-595-5
特性:驱动芯片、汽车芯片
温度范围-40C~150C
最大输入电压:-42 V~45 V
TLE4250-2G…
跨境电商app系统开发
近年来,随着跨境电商行业的发展,越来越多的企业开始关注跨境电商app系统的开发。这些系统可以帮助企业更加高效地管理跨境电商业务,提高产品销售的效率,并且为消费者提供更加方便快捷的购物体验。
跨境电商app系统的开发需要考虑…

品牌618如何宣传,才能为业绩加油助力?
传媒如春雨,润物细无声,大家好,我是51媒体 胡老师。
随着618年中消费季的临近,许多企业和品牌都已经卯足了马力,争取在年终狂欢中多多增加公司业绩,现在的618 不仅仅涉及我们的吃穿用行,而且各…
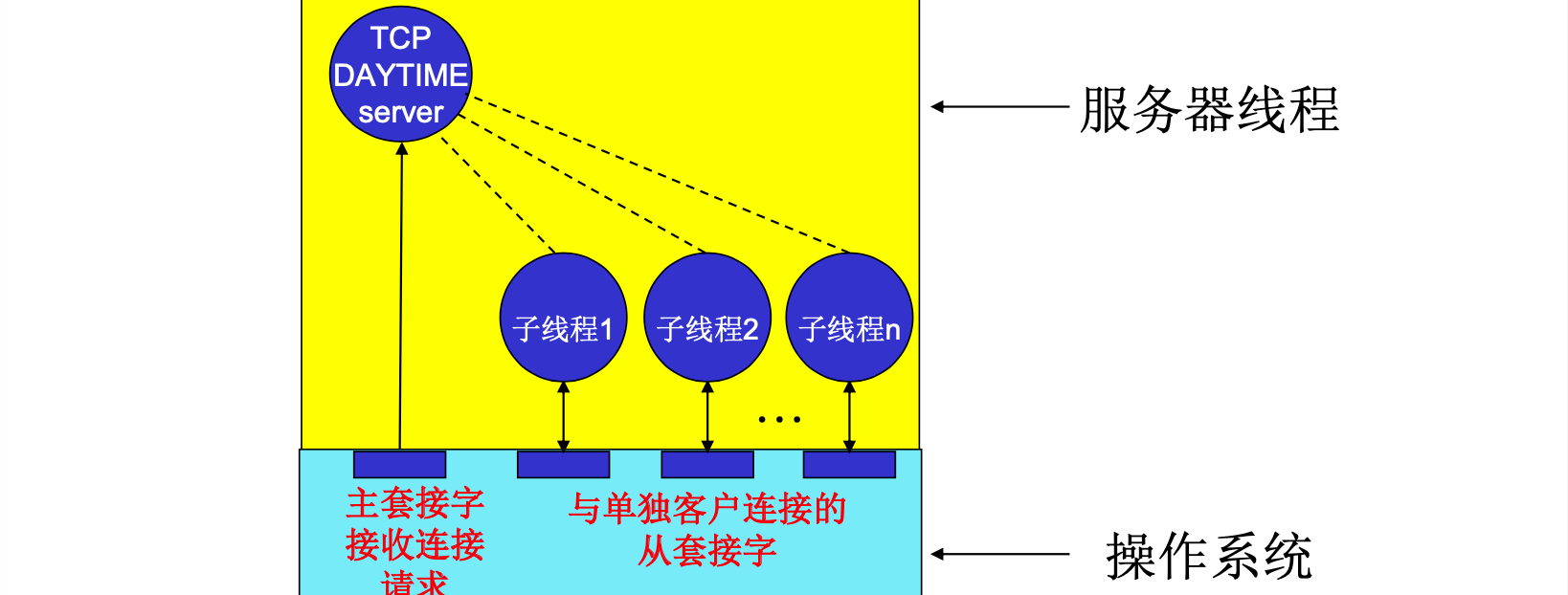
计算机网络开荒2.2-Socket编程
文章目录 一、Socket概述二、Socket API 概述三、WinSock常用API3.1 常用API3.1.1 WSAStartUP3.1.2 WSACleanup3.1.3 Socket3.1.4 Closesocket3.1.5 bind3.1.6 listen3.1.7 connect3.1.8 accept3.1.9 send, sendto3.1.10 recv, recvfrom3.1.11 etsockopt, getsockopt 3.2 网络字…
H3C 交换机的VXLAN二层转发配置
H3C 交换机的VXLAN二层转发配置
本篇介绍H3C交换机的VXLAN二层转发配置。
基本概念:
首先了解VXLAN(Virtual eXtensible LAN,可扩展虚拟局域网络)的基本概念。VXLAN是基于IP网络、采用“MAC in UDP”封装形式的二层VPN技术。VXLAN可以基于…

Vue.js 中的 v-bind 指令详解
Vue.js 中的 v-bind 指令
介绍
Vue.js中的v-bind指令是一种将组件的属性绑定到Vue实例的数据的方式。v-bind指令可以用于将任何组件属性绑定到Vue实例的数据上,例如class、style、属性等。v-bind指令允许我们动态地设置组件的属性,从而使组件更加灵活和…

案例精述丨Fortinet SASE 护航跨国公司中国区网络安全升级
在全球数字化转型大潮下,跨国公司的机构、设施、人员等全球分布式特性,不但带来了广域网建设的网络复杂性,也带来了更加严峻的安全挑战。某全球知名跨国公司,在中国区进行网络安全升级改造的过程中,采用国内某IDC运营商…

阿里巴巴序列模型梳理
SIM:基于搜索的用户终身行为序列建模
论文:《Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction》 下载地址:https://arxiv.org/abs/2006.05639
1、用户行为序列建模回顾
1…
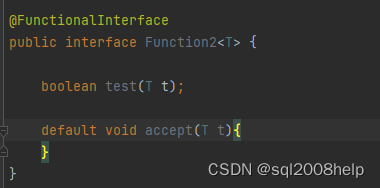
JDK8-1-Lambda表达式(3)-函数式接口
JDK8-1-Lambda表达式(3)-函数式接口
有且仅有一个抽象方法的接口称为函数式接口,上文 中 java.util.function.Predicate 接口就是一个函数式接口,Java 8中引入的函数式接口定义在 java.util.function 包下
java.util.function.P…