✍个人博客:https://blog.csdn.net/Newin2020?spm=1011.2415.3001.5343
📣专栏定位:为学习吴恩达机器学习视频的同学提供的随堂笔记。
📚专栏简介:在这个专栏,我将整理吴恩达机器学习视频的所有内容的笔记,方便大家参考学习。
💡专栏地址:https://blog.csdn.net/Newin2020/article/details/128125806
📝视频地址:吴恩达机器学习系列课程
❤️如果有收获的话,欢迎点赞👍收藏📁,您的支持就是我创作的最大动力💪
十二、降维
1. 目标1:数据压缩
数据压缩有挺多的好处,可以减少数据存储的内存,可以加快算法运行速度等等,让我们先来看看将二维降成一维是如何操作的吧。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bRVKa8Ko-1670200062549)(吴恩达机器学习.assets/image-20211115132037106.png)]](https://img-blog.csdnimg.cn/5d9c8bf27e674f77bc8b7ac639ca68cf.png)
可以看到上面设定了一条绿线,让所有样本都往绿线上投影,然后单独提出来得到一个坐标轴,这时我们就可以通过新的数z来代表每一个样本的位置,实现了二维到一维的降维,接下来再看看三维到二维的过程。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3ibehxdd-1670200062553)(吴恩达机器学习.assets/image-20211115132438029.png)]](https://img-blog.csdnimg.cn/17142ebccd834306ad93595001237d6d.png)
过程和二维到一维的比较相似,只不过我们现在是通过让所有样本投影到一个平面上,这样就可以设置两个新的数z1和z2来表示样本的位置,从而实现了三维到二维的降维。
2. 目标2:可视化
这节课再来将一下降维的第二个应用可视化,假设我们现在有很多数据关于每个国家的信息,每个国家都有50个指标表示即50维,现在我们通过一系列变换将50维降到2维,这可能就很难理解2维是如何表示国家的情况。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SgMcDky6-1670200062556)(吴恩达机器学习.assets/image-20211115133514390.png)]](https://img-blog.csdnimg.cn/e2cad5fb1b3146b285699be0baf33dd6.png)
那我们可以通过图像去理解这些信息,假设横轴代表国家的GDP而纵轴代表人均的GDP,就能很直观的表现出来。
3. 主成分分析问题规划
主成分分析(PCA)问题规划
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gNql79Bt-1670200062557)(吴恩达机器学习.assets/image-20211118092555124.png)]](https://img-blog.csdnimg.cn/5a7d6014f0f14af1a8e3ccc6edf1e08a.png)
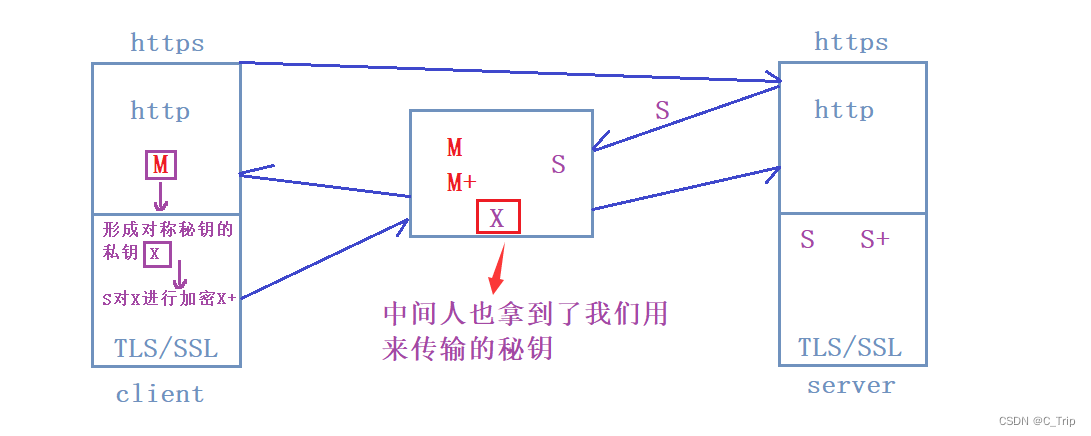
这种算法是最强大的无监督算法之一,其原理是通过将样本通过投影到更低维度上从而找到一个投影误差最小的维度,拿2D到1D距离,PCA就是通过计算所有样本到直线垂直距离即投影误差,找到平方投影误差最小的直线,同理换成3D到2D就是将直线换成了平面。
并且PCA不是线性回归,虽然与线性回归比较相似。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0LhKnUkM-1670200062562)(吴恩达机器学习.assets/image-20211118093226322.png)]](https://img-blog.csdnimg.cn/4ccc32db47814876a0c113aa2cfd3c84.png)
上图左侧代表的是线性回归图像,而右侧则是PCA,可以发现线性回归问题中是找到样本竖直方向与直线的距离的最小误差,而PCA中则是样本与直线的垂直距离。还有一点不同就是,线性回归是要预测y值的,而PCA并没有什么预测的概念,本身作用是用于降维,而特征之间并没有什么特殊关系。
接下来,我们来讲讲PCA算法的详细步骤,但在此之前,我们首先要执行的是均值标准化,这里的流程实际上是和之前有监督学习的数据处理步骤是一样的。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cchxNySw-1670200062565)(吴恩达机器学习.assets/image-20211118101012675.png)]](https://img-blog.csdnimg.cn/fce74fc44854453d8b5c2748421637e4.png)
并且如果特征值相差过大,还需要进行特征缩放。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XgyE1VfF-1670200062566)(吴恩达机器学习.assets/image-20211118094846128.png)]](https://img-blog.csdnimg.cn/998a2490630c4b7d9be56f79f6c8805c.png)
如果你想减少数据即从N维降到K维,首先你要计算协方差矩阵(covariance matrix),要注意的是上面sigma矩阵和求和sigma是完全不一样的,虽然符号十分相似。然后再计算**奇异值分解(svd)**得到U,S,V矩阵,而svd函数可以通过数值库找到对应的代码。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-q3uMKrv6-1670200062568)(吴恩达机器学习.assets/image-20211118095402373.png)]](https://img-blog.csdnimg.cn/5ba5b65d19af435694e4d32159cc2916.png)
而得到的USV中的U矩阵尤为关键,它是一个n阶方阵,我们要取其中的前k项从而组成Ureduce矩阵,然后计算其与样本向量的乘机得到z,这里的样本可以用训练集中的也可以用交叉验证集中的。
4. 主成分数量选择
我们在使用PCA的时候还要考虑到k的选择,以下就是我们选择k的标准。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8B4ubBMC-1670200062570)(吴恩达机器学习.assets/image-20211118102142247.png)]](https://img-blog.csdnimg.cn/9a337b212a5d420587e4fac8d19e90d3.png)
你要计算平均平方投影误差与总平方误差,然后使两者相除的数值尽量的小,我们一般想让这个值尽量小于1%,或者我们也可以说尽量有大于99%的方差被保留即大于99%的数据被保留。
所以我们要该如何去选取k呢,下面左侧的方法就比较笨拙,通过不断尝试k值,然后反复计算平均平方投影误差和总平方投影误差,这样每次都会调用一次奇异化分解,导致效率变低。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oWDFyImM-1670200062571)(吴恩达机器学习.assets/image-20211118103233090.png)]](https://img-blog.csdnimg.cn/6e11ec76a1d24610a2c980765bb79d55.png)
所以我们会用上图右侧的方法,利用之前奇异化分解得到的矩阵中的S矩阵,然后将之前的算式改成上图右侧的算式,这样我们就只用计算一次奇异化分解,每次只用计算只用调用S矩阵中的值即可,同样只用尽量让上面算式结果小于0.01,下面就是具体算式。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Au532Rgo-1670200062572)(吴恩达机器学习.assets/image-20211118103945918.png)]](https://img-blog.csdnimg.cn/5a1e9f7b1ae44e46b2ffdb7a22b691b1.png)
5. 压缩重现
我们前面通过投影将高维转化为低维,同样我们也可以通过压缩后的数据将低维重现为高维。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-j6iym39v-1670200062573)(吴恩达机器学习.assets/image-20211118104636862.png)]](https://img-blog.csdnimg.cn/3fd01c4dffa542edab9e3fc96d003da5.png)
重现后的x都在之前映射的直线上,不等于原来的x,但都接近于原来的x,具体步骤通过Ureduce乘以z即可。
6. 应用PCA的建议
我们在进行监督学习时有时候会碰到样本数据量特别大的情况,这时候直接运用逻辑回归、支持向量机等算法可能会运行的比较慢,这时候我们可以通过PCA来降维从而加速监督学习。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gsMInUs5-1670200062575)(吴恩达机器学习.assets/image-20211118133902927.png)]](https://img-blog.csdnimg.cn/3afa03bc2b0e4b6b8464cf16c9b1332f.png)
我们可以从训练集中提取出x特征(注意只能是训练集),然后通过PCA算法将这些特征压缩成z,上面的这个例子是将10000维降到了1000维,实际中可能没这么夸张,可能会降1/5或者1/10之类,并保留大部分的方差。
现在,我们就可以来总结一下PCA的应用了。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-11Nu6Wp5-1670200062576)(吴恩达机器学习.assets/image-20211118134320285.png)]](https://img-blog.csdnimg.cn/b3e1b3ddde8b422ca308c61e9f0d57a6.png)
PCA可以用于数据的压缩,从而减少存储数据的内存或者磁盘,或者加速学习算法。
当然PCA还可以应用于可视化,我们一般运用2D或3D进行可视化。
还有一点要提的是,不要用PCA去防止过拟合情况。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4onumrpE-1670200062577)(吴恩达机器学习.assets/image-20211118134916379.png)]](https://img-blog.csdnimg.cn/3902181da6724003941cd42fcaf86667.png)
也许,你用PCA去防止过拟合得到的效果不错,即使你保留了99%的方差,但仍然有可能会丢失一些有价值的信息,所以这里建议使用正则化去防止过拟合是更好的选择。
还有一个误区就是,很多人会滥用PCA,有些人甚至会在项目计划开始时就使用PCA,这里建议先不使用PCA去尝试训练模型,因为有时候可能不使用PCA也能达到同样的效果,就不用花很多时间在PCA的计算上面了。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dZSHcDoB-1670200062578)(吴恩达机器学习.assets/image-20211118135437524.png)]](https://img-blog.csdnimg.cn/600a3c523d2044dda97f3eb5add18879.png)



![[附源码]计算机毕业设计人体健康管理appSpringboot程序](https://img-blog.csdnimg.cn/ac5fad3e96844184a2ef4186c86dd463.png)



![MyBatis-Plus之ActiveRecord[基础增删改查操作]](https://img-blog.csdnimg.cn/6682f916db1a40e387760a77f762e8ba.png)