文章目录
- 1、什么是HTTP协议
- 2、HTTP协议格式
- <1>HTTP请求方法
- <2>HTTP的状态码
- 3、HTTP是不保存状态的协议
- <1>使用Cookie的状态管理
- 3、HTTPS
- <1>加密方式
- <2>理解HTTPS加密过程
1、什么是HTTP协议
HTTP协议常被称为超文本传输协议,HTTP协议和TCP/IP协议族内的其他众多协议相同,用于客户端个服务端之间的通信。
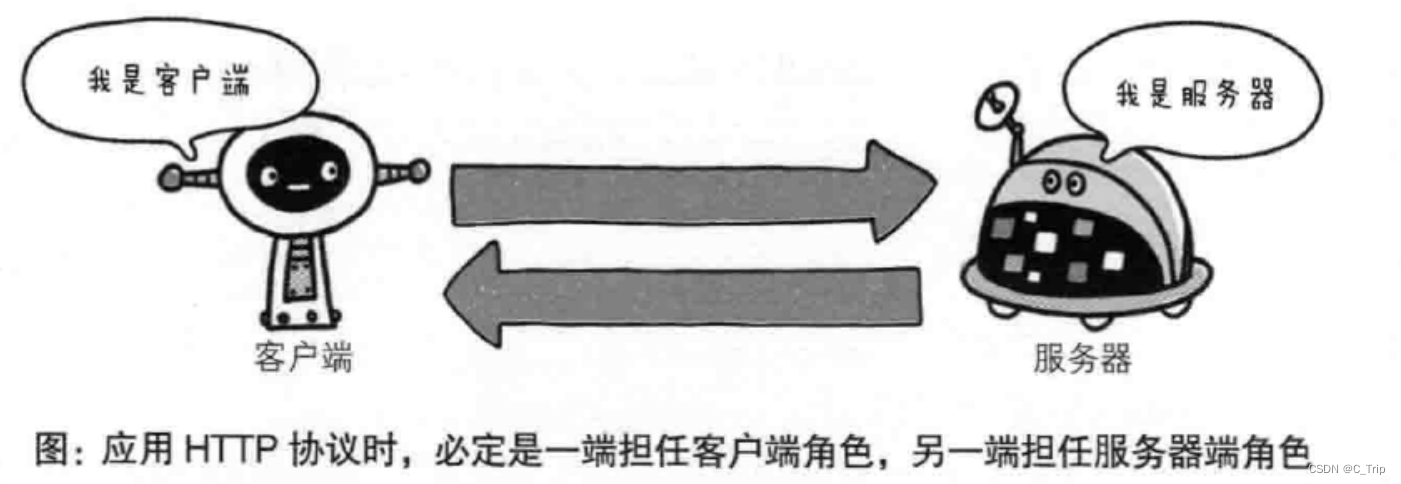
在两台计算机之间使用HTTP协议通信时,在一条通信线路上必定有一端是客户端,另一端则是服务端。HTTP协议能够明确区分那端是客户端,哪端是服务端。请求必定由客户端发出,而服务端回复响应。换句话说肯定是先从客户端开始建立通信的,服务器端在没有收到请求之前不会发送响应。
认识URL
平时我们俗称的 “网址” 其实就是说的 URL

2、HTTP协议格式
请求报文和响应报文的结构。
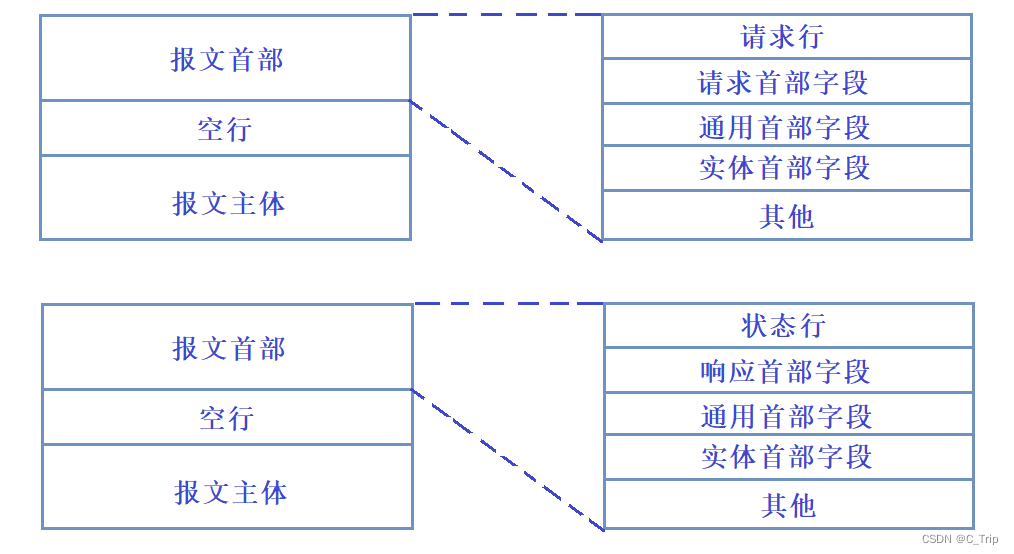
无论请求还是响应,基本上HTTP都是按照行为单位进行构建请求或响应的,且无论是请求还是响应几乎都是由3或4部分组成(有无正文)。
实际请求报文中的内容:
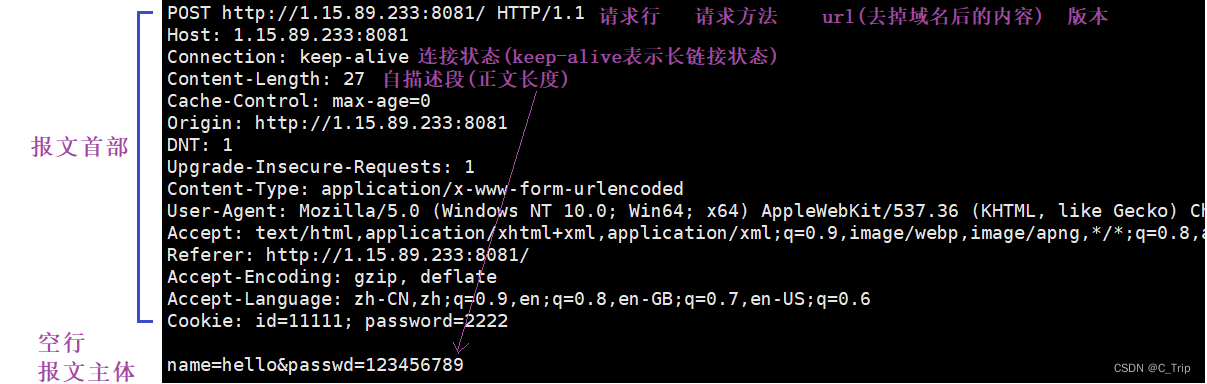
Content-Length若不存在就说明没有下面的正文。
http如何解包,封装,以及分用呢?
解包以及分用是通过特殊字符空行来实现的,分用不是http解决的,是具体应用代码解决,http需要有接口来帮助上层获取参数。
http请求或响应是如何被读取的,请求是如何被发送的?
请求和响应整体看做一个大的字符串。

HTTP常见Header
- Content-Type: 数据类型(text/html等)
- Content-Length: Body的长度
- Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上;
- User-Agent: 声明用户的操作系统和浏览器版本信息;
- referer: 当前页面是从哪个页面跳转过来的;
- location: 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问;
- Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能;
<1>HTTP请求方法
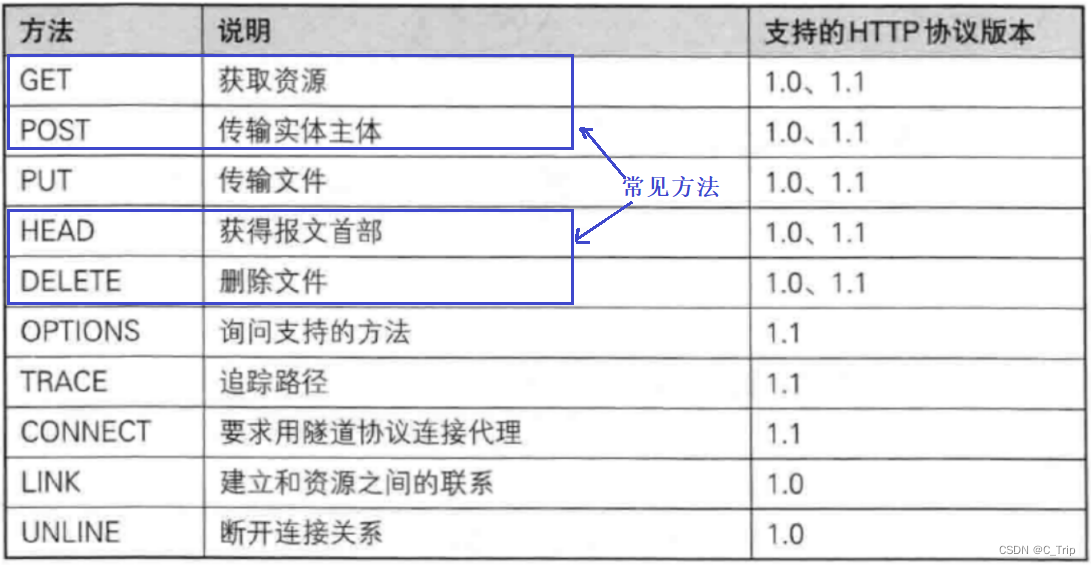
GET和POST方法
-
post方法叫做推送,是提交参数比较长用的方法,参数是通过正文的方式来提交的,如上图,一旦有了参数,就会有Content-Length来表示参数的长度。
-
get方法叫做获取,是最常用的方法,默认一般获取所有的网页都是get方法。get方法可以提交参数,是通过url来进行参数拼接从而交给server端。下面看一下get方法的请求报文。
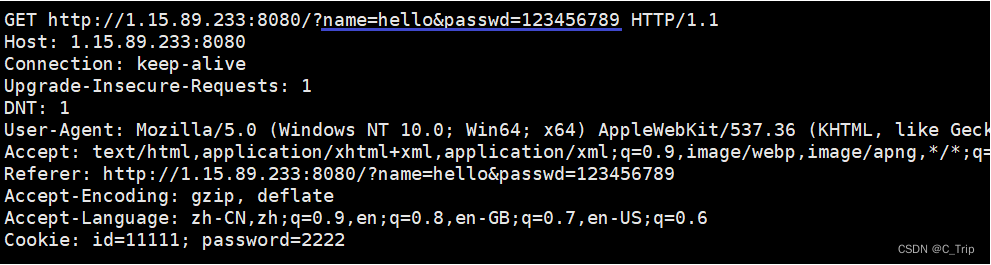
浏览器截图

由上图可见get方法参数是通过url来进行参数拼接从而交给server端的。
GET和POST方法区别
- 参数提交位置不同,post方法比较私密(私密 != 安全 ),不会回显到浏览器的url输入框。get方法会将重要信息回显到url输入框中,增加了被盗取的风险。
- get方法通过url传参,而url是有大小限制的(和具体浏览器有关),post方法由正文部分传参,一没有大小限制。
<2>HTTP的状态码
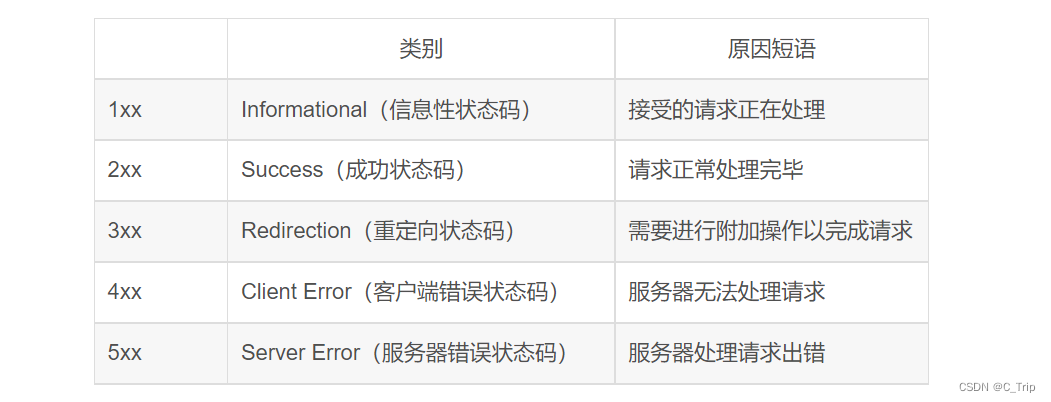
常用的有:
- 200 (OK):请求已正常处理。
- 201 (Created):请求已被接受,等待资源响应。
- 301 (Moved Permanently):永久性重定向,请求的资源已经被分配了新的URI,以后应使用资源现在所指的URI。
- 302 (Found):临时性重定向。和301相似,但302代表的资源不是永久性移动,只是临时性性质的。换句话说,已移动的资源对应的URI将来还有可能发生改变。
- 307 (Temporary Redirect):临时重定向。与302有相同的含义。
- 403 (Forbidden):不允许访问那个资源。该状态码表明对请求资源的访问被服务器拒绝了。
- 404 (Not Found):服务器上没有请求的资源。
- 500 (Internal Server Error):该状态码表明服务器端在执行请求时发生了错误。
- 503 (Service Unavailable):该状态码表明服务器暂时处于超负载或正在停机维护,现在无法处理请求。
临时重定向 VS 永久重定向
临时重定向:如我们平时使用软件要先进行登录操作,此时会跳转到登录界面,输完信息后登录会跳转到开始界面。
永久重定向:如网站搬迁旧网站不用了,此时访问旧网站时会跳到新网站中。
重定向是需要浏览器给我们提供支持的,浏览器必须识别301,302,307状态码。server告诉浏览器,应该在去哪里是通过报头中的location。
3、HTTP是不保存状态的协议
http是一种不保存状态,即无状态协议。http协议自身不对请求和响应之间的通信状态进行保存。也就是说在http这个级别,协议对于发送过的请求或响应都不做持久化处理。无状态优点:由于不必保存状态,自然可减少服务器的CPU及内存资源的消耗。
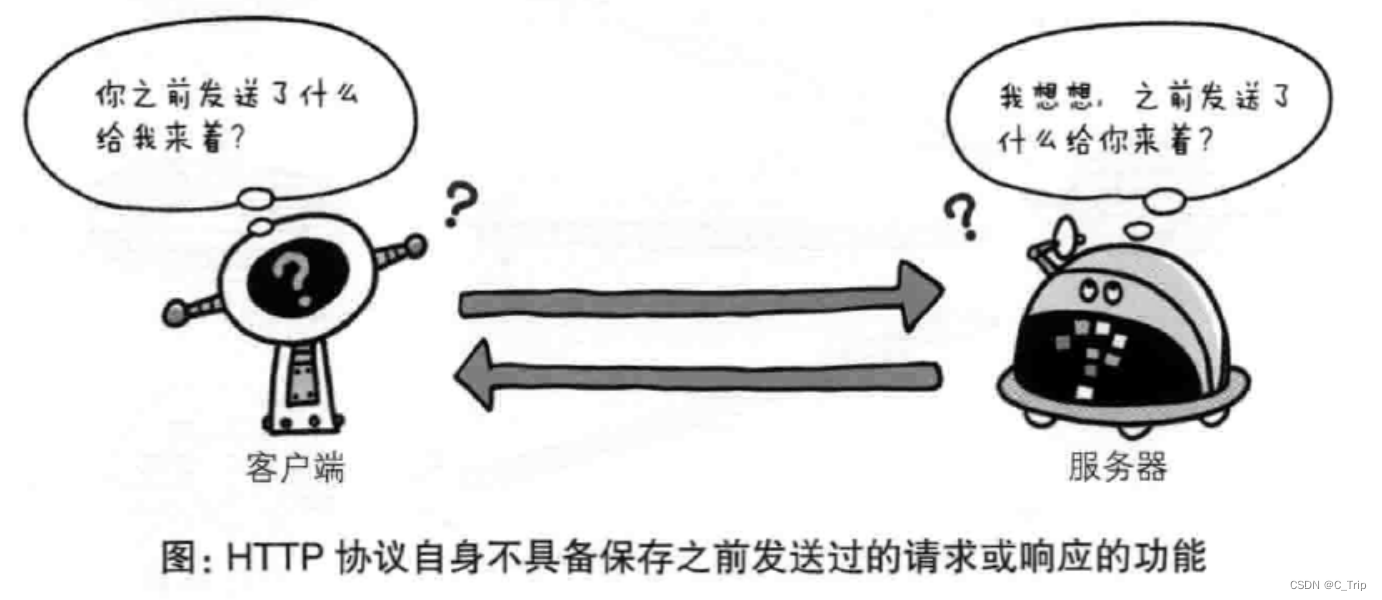
从我们平时生活来看,好像说的不对啊我们平时在网站中进行跳转(http请求)网站照样认识我啊,也不需要重新进行登录,原因是引入了Cookie技术。有了Cookie再用http协议通信,就可以管理状态了。
<1>使用Cookie的状态管理
Cookie技术通过在请求和响应报文中写入Cookie信息来控制客户端状态。Cookie会根据服务端发送响应报文内的一个叫做Set - Cookie的首部字段信息,通知客户端保存Cookie。当下次客户端再往服务器发送请求时,客户端会自动在请求报文中添加Cookie值后发送出去。
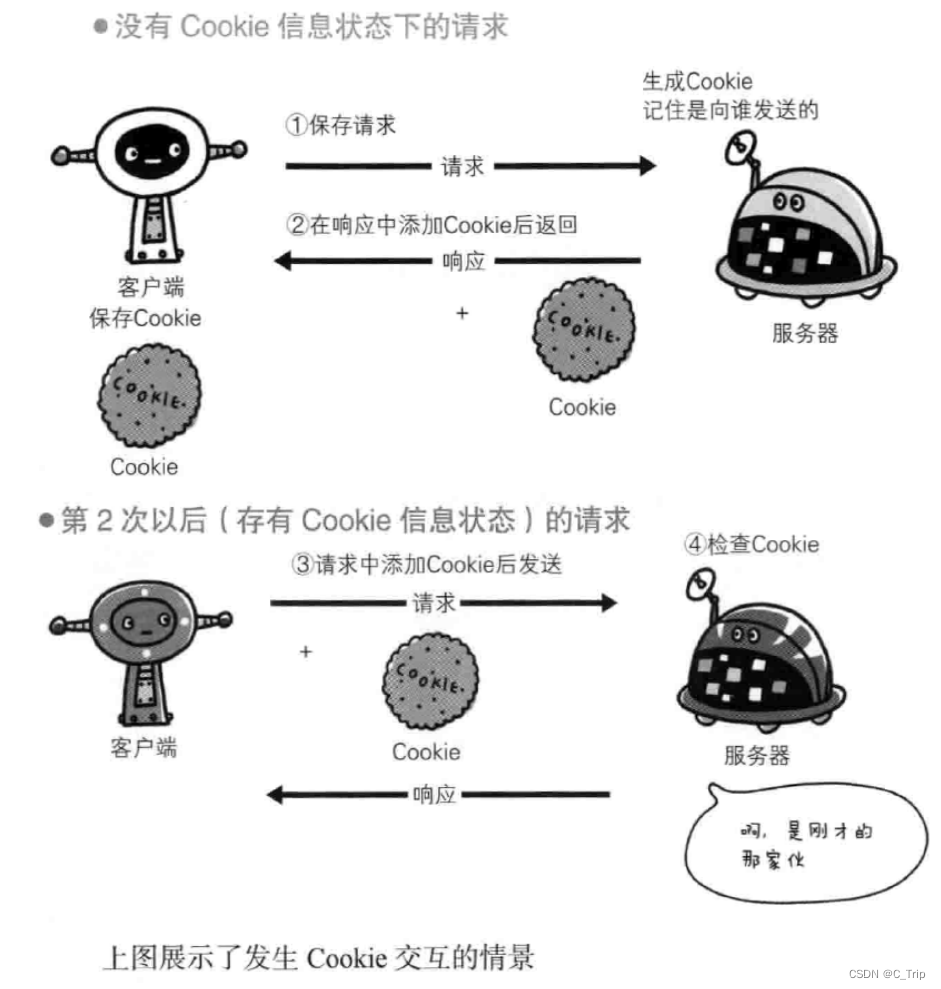
- 浏览器:Cookie其实是一个文件(本地可以找到),该文件里面保存的是我们用户的私密信息。
- http协议:一旦该网站对应有Cookie,在发起任何请求的时候都会在request中携带该Cookie信息。
单纯使用Cookie是有一定安全隐患的
Cookie中存储着我们的私密信息,如果被别人盗取了Cookie文件,那别人就可以以我们的身份信息进行认定访问特定的资源,于是乎有了session。
session核心思路就是:将用户的私密信息,保存在服务端。如图:
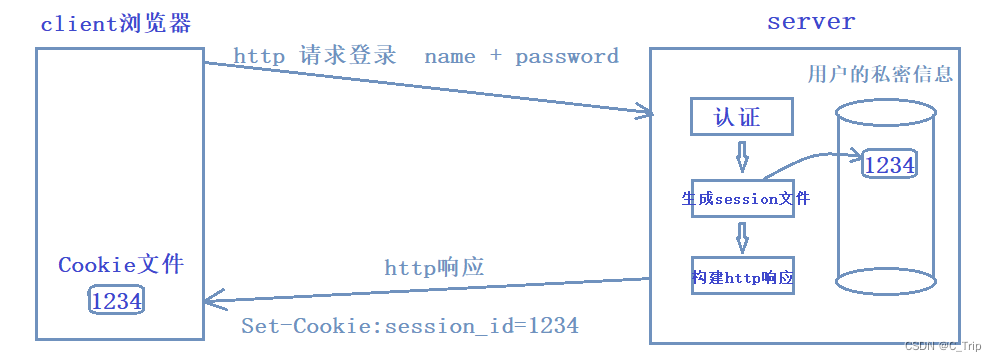
虽然有了session会相对安全一些,但是仍然有被盗取的风险。
3、HTTPS
HTTPS是以安全为目标的 HTTP 通道,在HTTP的基础上通过传输加密和身份认证保证了传输过程的安全性。HTTPS 在HTTP 的基础下加入SSL/TLS,HTTPS 的安全基础是 SSL/TLS,因此加密的详细内容就需要SSL/TLS。
SSL(Secure Socket Layer)安全套接层是Netscape公司率先采用的网络安全协议。它是在传输通信协议(TCP/IP)上实现的一种安全协议,采用公开密钥技术。SSL广泛支持各种类型的网络,同时提供三种基本的安全服务,它们都使用公开密钥技术。
<1>加密方式
对称加密: 只有一个秘钥X,即加密解密都需要用X来完成。
如用X来加密:data ^ x = result;
用X来解密:result ^ x = data;
这里只是举例,真实情况可能并不是这样,加密其实就是算法我们这里用异或来举例。
非对称加密: 有一对秘钥(公钥和私钥)。
可以用公钥来加密,但是只能用私钥来解密。或者用私钥来加密,只能用公钥来解密。
一般而言,公钥是对全世界公开的,私钥是自己私有保存的。
数据加密传到对端解密后我们怎么知道数据对不对是不是我想要的数据呢?
我们先来看这样一个问题。
文本传输如何防止文本中的内容被篡改,以及如何识别文本是否被篡改?
如图:
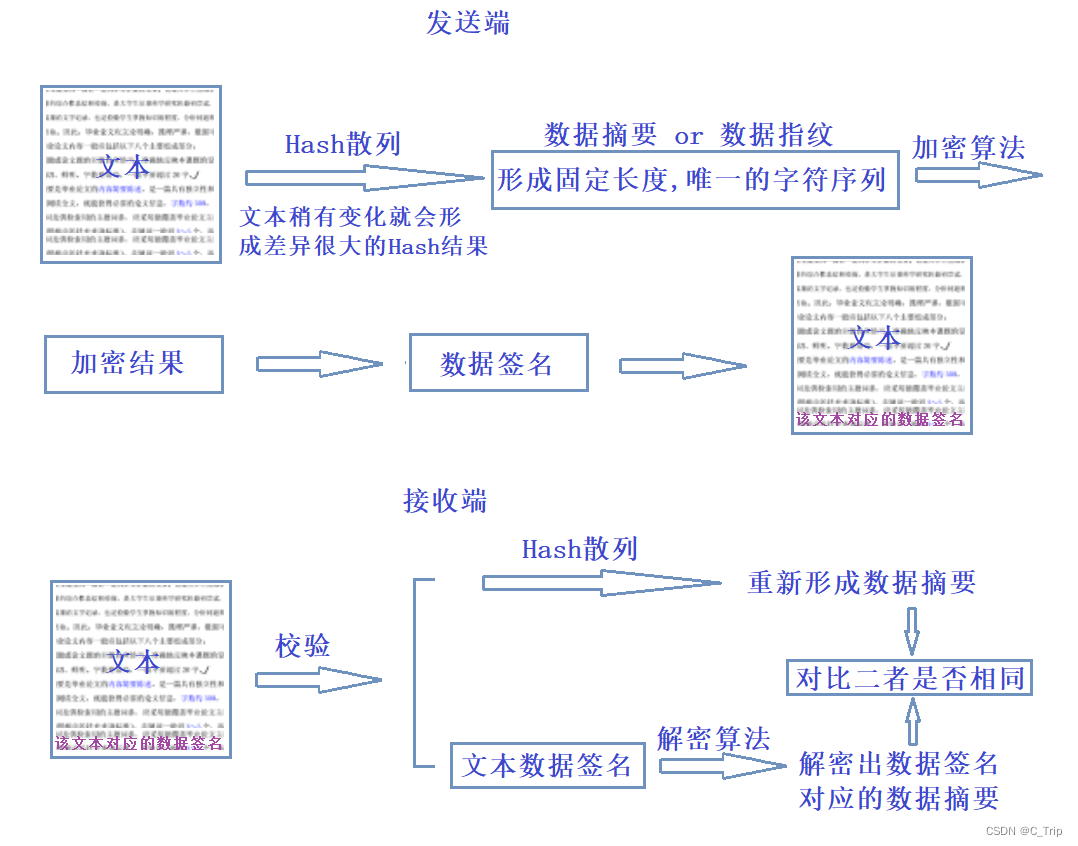
数据传输判断和文本类似。
<2>理解HTTPS加密过程
我们上述说了两种加密方式对称和非对称加密,那么https采用那种加密方式呢?
用对称加密,能不能行?
在双方通信秘钥协商的阶段,很显然秘钥是暴露出来的,因为两把秘钥相同那么不但你自己可以进行数据解密,其他看到你这把秘钥的人也可以对你的数据进行解密,从而看到你的数据。很显然是不行的。
那用非对称加密呢?
非对称加密,在秘钥协商阶段虽然别人可以看到传输的公钥,但是却不知到你的私钥信息故无法对你的数据进行解密。不足的是,客户端和服务端一人只有一把公钥和一把私钥,无法进行双向加密传输。
通过上面分析那用两对非对称秘钥不就可以保证数据双向传输安全了吗。理论上确实可以,不过非对称加密算法非常浪费时间,而对称加密是比较节省时间的。故实际采用 对称 + 非对称方案。
如图:
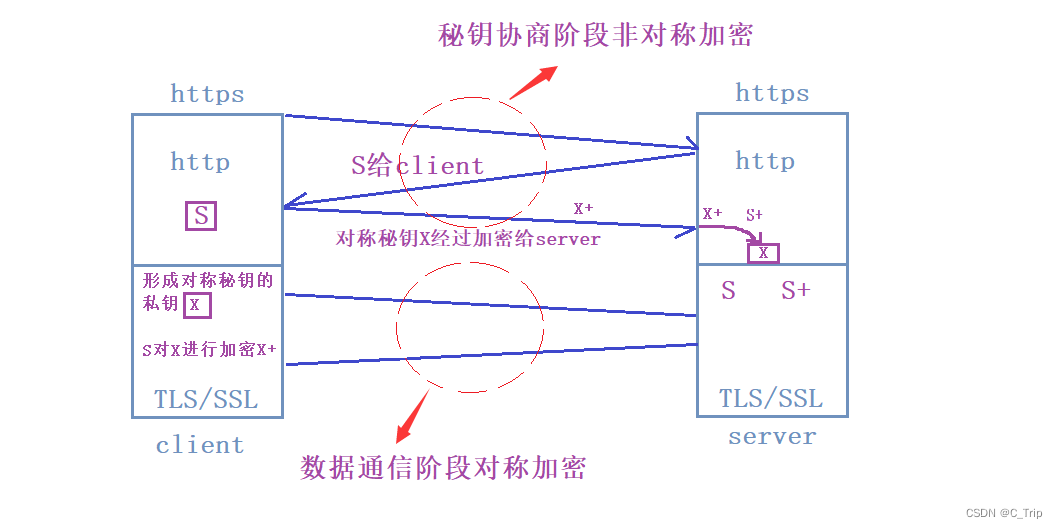
上述过程虽然成功完成了加密传输,但是有一定风险。在网络环节中随时都有可能存在中间人来,偷窥、修改我们的数据。如果在上述中间环节我们传给client的公钥S被中间人用自己的秘钥替换了的话(狸猫换太子),那么最终形成的传输给server端的X+就是用中间人的秘钥形成的,中间人就可以知道我们的传输对称的秘钥,我们的数据也就被中间人看到了。如图:
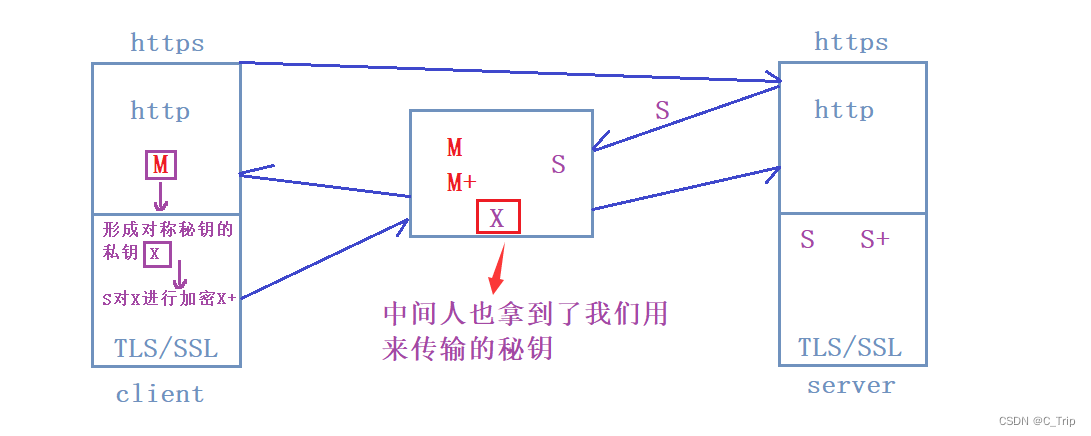
本质问题是client端无法判断发来的秘钥协商报文是不是从合法的服务方发来的。
故就有了CA证书机构(经过权威机构认证,是合法的),有自己的公钥和私钥。此时中间人若是想来偷换数据也需要向CA机构申请证书,此时发送给client端的时候client端就能判断出是不是合法的服务方发过来的。




![[附源码]计算机毕业设计时间管理软件appSpringboot程序](https://img-blog.csdnimg.cn/e9015a84b3044aa298d5156ff04147e2.png)



![[附源码]计算机毕业设计基于Springboot景区直通车服务系统](https://img-blog.csdnimg.cn/1d6cd546f4e8410a9e719d0d6972f46c.png)