第二章:信息的表示和处理
历史上因程序bug导致重大事故的情况很多是由数字溢出,缓冲区溢出导致的。
本章主要讲的是基本数据类型的(IEEE)表示,大小端,以及二进制位运算的骚操作案例。
第三章:程序的机器级表示
本章主要讲 C语言代码翻译成的汇编语言代码。通过对比,理解程序如何在汇编级上运行的。
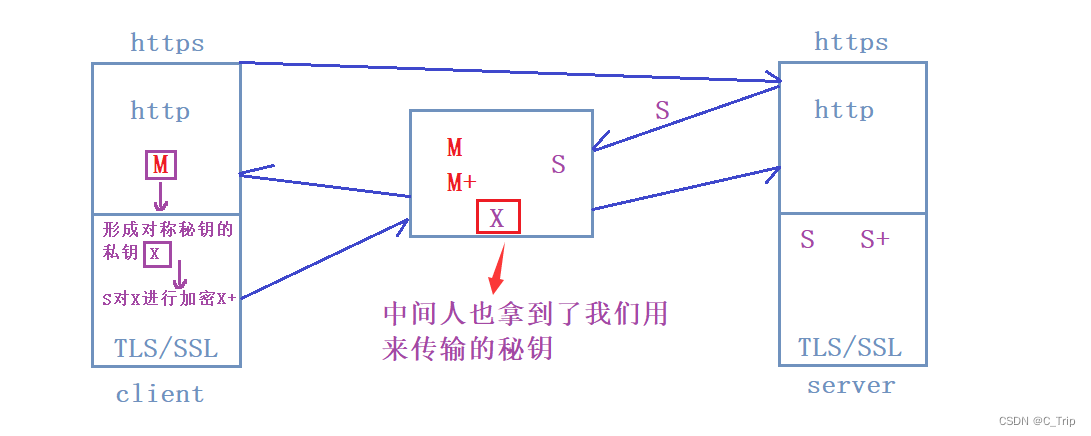
涉及各种数据操作指令,PC和16个寄存器。
3.7 节重点讲了函数调用的汇编实现。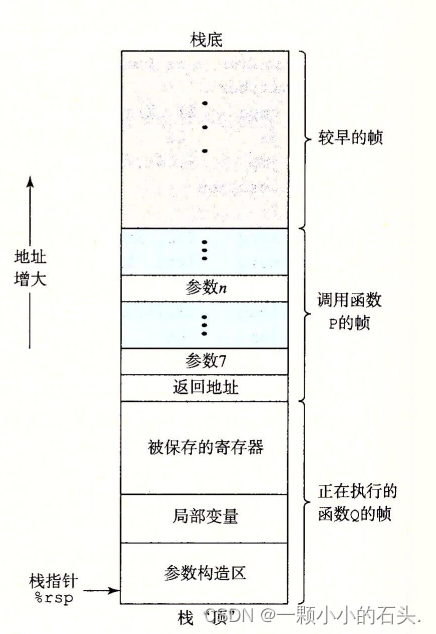
如果函数Q执行的过程中出现缓冲区溢出或者内存越界访问,那么可能导致上面被保存的寄存器被错改,甚至返回地址被修改,导致调用者拿到的返回地址是一段恶意攻击代码的地址。
os 提供了栈地址随机化,栈破坏检测[插入金丝雀数据] 等对抗的方法。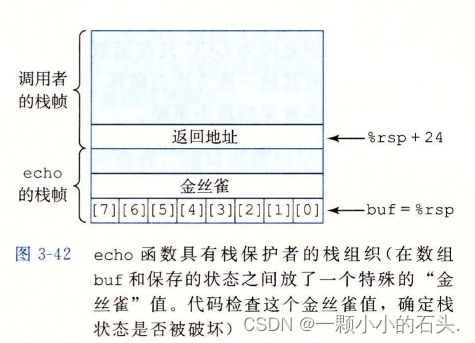
第四章: 处理器体系结构
讲 cpu 的计算机组成原理课,跳过
第五章: 优化程序性能
编译器优化
gcc 可选择编译优化的程度,通过 -O1 O2 这样的命令参数。
考虑交换函数:
void func(long *x1, long *x2){
*x1 += *x2;
*x1 += *x1;
}
编译器不能将其优化成:
void swap1(long *x1, long *x2){
*x1 += 2 * *x2;
}
因为在 x1 和 x2 地址相同时前者是4倍加法。
同理对于函数调用也是:
long f();
long fun1(){
return f() + f();
}
long fun2(){
return 2 * f()
}
因为 f() 中可能包含对全局变量的修改。
另外,对于swap 函数不用临时变量的写法,编译器同样没法优化。
void swap(long *x1, long *x2){
*x1 = *x1 + *x2;
*x2 = *x1 - *x2;
*x1 = *x1 - *x2;
}
针对 for 循环的优化:
void sum1(long x1[], long s[], int n){
long i ;
s[0] = x1[0] ;
for(i = 1; i < n; i++){
s[i] = s[i-1] + x1[i];
}
}
循环了 n 次, 可以优化成 n/2 次:
void sum2(long x1[], long s[], int n){
long i ;
s[0] = x1[0] ;
for(i = 1; i < n-1; i+=2){
long mid_val = s[i-1] + x1[i];
s[i] = mid_val;
s1[i+1] = s[i] + x1[i+1];
}
if(i < n){
s[i] = s[i-1] + x1[i];
}
}
sum2 函数是 sum1 性能的 1.5 倍左右
以上被称为"循环展开": 例如下面3种



类似的可以采用 k * k 展开。 但当k过大时会导致寄存器溢出,16个寄存器不够存储那么多展开时的临时变量,导致只能在栈上分配额外空间进行读写,反而降低了性能。
另外,从CPU指令角度和业务代码角度提高程序并行性,可大幅提高性能。


![[附源码]计算机毕业设计人体健康管理appSpringboot程序](https://img-blog.csdnimg.cn/ac5fad3e96844184a2ef4186c86dd463.png)



![MyBatis-Plus之ActiveRecord[基础增删改查操作]](https://img-blog.csdnimg.cn/6682f916db1a40e387760a77f762e8ba.png)