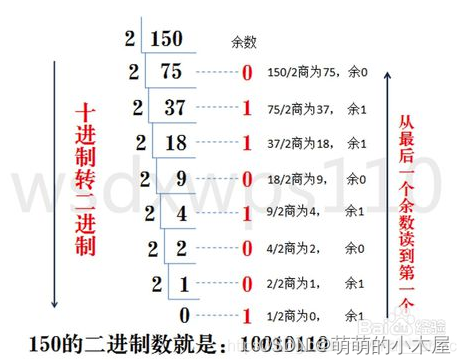
文章目录
- 前言
- 一、准备工作
- 二、分析目标网站
- 1.商品信息
- 三、编写爬虫程序
- 五、总结
前言
随着电商平台的兴起,越来越多的人开始在网上购物。而对于电商平台来说,商品信息、价格、评论等数据是非常重要的。因此,抓取电商平台的商品信息、价格、评论等数据成为了一项非常有价值的工作。本文将介绍如何使用Python编写爬虫程序,抓取电商平台的商品信息、价格、评论等数据。

一、准备工作
在开始编写爬虫程序之前,我们需要准备一些工具和环境。
Python3.8
PyCharm
二、分析目标网站
在开始编写爬虫程序之前,我们需要先分析目标网站的结构和数据。在本文中,我们选择抓取京东商城的商品信息、价格、评论等数据。
1.商品信息
-
商城的商品信息包括商品名称、商品编号、商品分类、商品品牌、商品型号、商品规格、商品产地、商品重量、商品包装等信息。这些信息可以在商品详情页面中找到。
-
价格
商城的商品价格包括商品原价、商品促销价、商品折扣等信息。这些信息可以在商品详情页面中找到。 -
评论
京东商城的商品评论包括用户评价、用户晒图、用户追评等信息。这些信息可以在商品详情页面中找到。
三、编写爬虫程序
在分析目标网站的结构和数据之后,我们可以开始编写爬虫程序了。在本文中,我们使用Scrapy框架编写爬虫程序,将抓取到的数据保存到MySQL数据库中。
- 创建Scrapy项目
首先,我们需要创建一个Scrapy项目。在命令行中输入以下命令:
scrapy startproject jingdong
这将创建一个名为jingdong的Scrapy项目。
- 创建爬虫
接下来,我们需要创建一个爬虫。在命令行中输入以下命令:
scrapy genspider jingdong_spider jd.com
这将创建一个名为jingdong_spider的爬虫,爬取的网站为jd.com。
- 编写爬虫代码
在创建完爬虫之后,我们需要编写爬虫代码。在Scrapy框架中,爬虫代码主要包括以下几个部分:
(1)定义Item
Item是Scrapy框架中的一个概念,它用于定义要抓取的数据结构。在本文中,我们需要定义一个Item,用于保存商品信息、价格、评论等数据。在项目的items.py文件中,添加以下代码:
import scrapy
class JingdongItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
sku = scrapy.Field()
category = scrapy.Field()
brand = scrapy.Field()
model = scrapy.Field()
spec = scrapy.Field()
origin = scrapy.Field()
weight = scrapy.Field()
package = scrapy.Field()
price = scrapy.Field()
promotion_price = scrapy.Field()
discount = scrapy.Field()
comment = scrapy.Field()
image_urls = scrapy.Field()
images = scrapy.Field()
这里定义了一个名为JingdongItem的Item,包括商品名称、商品编号、商品分类、商品品牌、商品型号、商品规格、商品产地、商品重量、商品包装、商品价格、商品促销价、商品折扣、商品评论、商品图片等字段。
(2)编写爬虫代码
在项目的spiders目录下,打开jingdong_spider.py文件,添加以下代码:
import scrapy
from jingdong.items import JingdongItem
class JingdongSpider(scrapy.Spider):
name = 'jingdong'
allowed_domains = ['jd.com']
start_urls = ['https://www.jd.com/']
def parse(self, response):
# 获取所有分类链接
category_links = response.xpath('//div[@class="category-item"]/div[@class="item-list"]/ul/li/a/@href')
for link in category_links:
yield scrapy.Request(link.extract(), callback=self.parse_category)
def parse_category(self, response):
# 获取所有商品链接
product_links = response.xpath('//div[@class="gl-i-wrap"]/div[@class="p-img"]/a/@href')
for link in product_links:
yield scrapy.Request(link.extract(), callback=self.parse_product)
# 获取下一页链接
next_page_link = response.xpath('//a[@class="pn-next"]/@href')
if next_page_link:
yield scrapy.Request(next_page_link.extract_first(), callback=self.parse_category)
def parse_product(self, response):
item = JingdongItem()
# 获取商品名称
item['name'] = response.xpath('//div[@class="sku-name"]/text()')[0].extract()
# 获取商品编号
item['sku'] = response.xpath('//div[@class="itemInfo-wrap"]/div[@class="clearfix"]/div[@class="sku"]/div[@class="item"]/div[@class="name"]/text()')[0].extract()
# 获取商品分类
category_list = response.xpath('//div[@class="breadcrumb"]/a/text()')
item['category'] = '>'.join(category_list.extract())
# 获取商品品牌
item['brand'] = response.xpath('//div[@class="itemInfo-wrap"]/div[@class="clearfix"]/div[@class="sku-name"]/a/@title')[0].extract()
# 获取商品型号
item['model'] = response.xpath('//div[@class="Ptable"]/div[@class="Ptable-item"]/dl/dt/text()')[0].extract()
# 获取商品规格
spec_list = response.xpath('//div[@class="Ptable"]/div[@class="Ptable-item"]/dl/dd/ul/li/text()')
item['spec'] = ','.join(spec_list.extract())
# 获取商品产地
item['origin'] = response.xpath('//div[@class="Ptable"]/div[@class="Ptable-item"]/dl/dd/text()')[0].extract()
# 获取商品重量
item['weight'] = response.xpath('//div[@class="Ptable"]/div[@class="Ptable-item"]/dl/dd/text()')[1].extract()
# 获取商品包装
item['package'] = response.xpath('//div[@class="Ptable"]/div[@class="Ptable-item"]/dl/dd/text()')[2].extract()
# 获取商品价格
price_list = response.xpath('//div[@class="summary-price-wrap"]/div[@class="summary-price J-summary-price"]/div[@class="dd"]/span/text()')
item['price'] = price_list[0].extract()
item['promotion_price'] = price_list[1].extract() if len(price_list) > 1 else ''
item['discount'] = response.xpath('//div[@class="summary-price-wrap"]/div[@class="summary-price J-summary-price"]/div[@class="dd"]/div[@class="promo"]/span/text()')[0].extract()
# 获取商品评论
comment_list = response.xpath('//div[@class="comment-item"]')
comment_text_list = []
for comment in comment_list:
comment_text = comment.xpath('div[@class="comment-column J-comment-column"]/div[@class="comment-con"]/div[@class="comment-con-top"]/div[@class="comment-con-txt"]/text()').extract_first()
if comment_text:
comment_text_list.append(comment_text.strip())
item['comment'] = '\n'.join(comment_text_list)
# 获取商品图片
item['image_urls'] = response.xpath('//div[@class="spec-items"]/ul/li/img/@src')
item['images'] = []
yield item
这里定义了一个名为JingdongSpider的爬虫,首先获取所有分类链接,然后依次访问每个分类页面,获取所有商品链接,然后依次访问每个商品页面,抓取商品信息、价格、评论等数据,并保存到Item中。
(3)配置数据库
在项目的settings.py文件中,添加以下代码:
ITEM_PIPELINES = {
'jingdong.pipelines.JingdongPipeline': 300,
}
MYSQL_HOST = 'localhost'
MYSQL_PORT = 3306
MYSQL_USER = 'root'
MYSQL_PASSWORD = '123456'
MYSQL_DBNAME = 'jingdong'
这里定义了一个名为JingdongPipeline的管道,用于将抓取到的数据保存到MySQL数据库中。同时,配置了MySQL数据库的连接信息。
(4)编写管道代码
在项目的pipelines.py文件中,添加以下代码:
import pymysql
from scrapy.exceptions import DropItem
from scrapy.pipelines.images import ImagesPipeline
from jingdong.items import JingdongItem
class JingdongPipeline(object):
def __init__(self, host, port, user, password, dbname):
self.host = host
self.port = port
self.user = user
self.password = password
self.dbname = dbname
@classmethod
def from_crawler(cls, crawler):
return cls(
host=crawler.settings.get('MYSQL_HOST'),
port=crawler.settings.get('MYSQL_PORT'),
user=crawler.settings.get('MYSQL_USER'),
password=crawler.settings.get('MYSQL_PASSWORD'),
dbname=crawler.settings.get('MYSQL_DBNAME')
)
def open_spider(self, spider):
self.conn = pymysql.connect(host=self.host, port=self.port, user=self.user, password=self.password, db=self.dbname, charset='utf8')
self.cursor = self.conn.cursor()
def close_spider(self, spider):
self.conn.close()
def process_item(self, item, spider):
if not isinstance(item, JingdongItem):
return item
# 保存商品信息
sql = 'INSERT INTO product(name, sku, category, brand, model, spec, origin, weight, package, price, promotion_price, discount, comment) VALUES(%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)'
self.cursor.execute(sql, (item['name'], item['sku'], item['category'], item['brand'], item['model'], item['spec'], item['origin'], item['weight'], item['package'], item['price'], item['promotion_price'], item['discount'], item['comment']))
product_id = self.cursor.lastrowid
# 保存商品图片
if item['image_urls']:
for image_url in item['image_urls']:
self.cursor.execute('INSERT INTO image(product_id, url) VALUES(%s, %s)', (product_id, image_url))
self.conn.commit()
return item
这里定义了一个名为JingdongPipeline的管道,用于将抓取到的数据保存到MySQL数据库中。在process_item方法中,首先保存商品信息到product表中,然后保存商品图片到image表中。
(5)配置图片下载
在项目的settings.py文件中,添加以下代码:
ITEM_PIPELINES = {
'jingdong.pipelines.JingdongPipeline': 300,
'scrapy.pipelines.images.ImagesPipeline': 1,
}
IMAGES_STORE = 'images'
这里配置了图片下载的管道和存储路径。
(6)运行爬虫
在命令行中输入以下命令,运行爬虫:
scrapy crawl jingdong
这将启动爬虫程序,开始抓取京东商城的商品信息、价格、评论等数据,并保存到MySQL数据库中。
五、总结
本文介绍了如何使用Python编写爬虫程序,抓取电商平台的商品信息、价格、评论等数据。通过本文的学习,您可以了解到Scrapy框架的基本使用方法,以及如何将抓取到的数据保存到MySQL数据库中。同时还可以学习到如何模拟浏览器的行为,抓取动态页面的数据。希望本文对您有所帮助。


![[学习笔记] [机器学习] 7. 集成学习(Bagging、随机森林、Boosting、GBDT)](https://img-blog.csdnimg.cn/51e54738007d4e5a819ae5d0b8b841d4.png#pic_center)