一、冯·诺伊曼模型
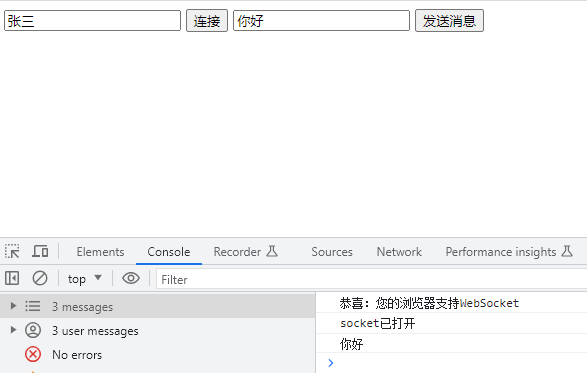
如图:
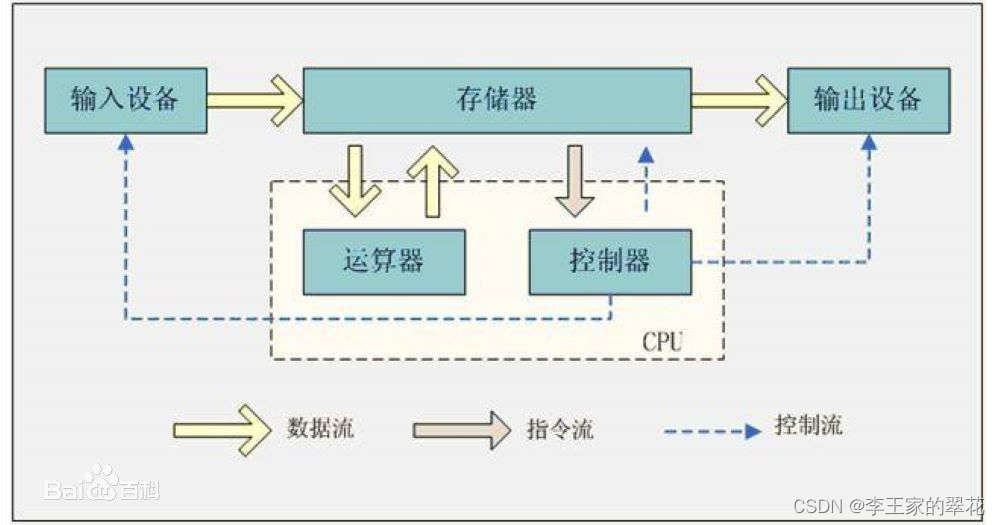
图片来源:百度百科
输入设备向计算机输入数据,输出设备接收计算机输出的数据。
所有的计算机程序,也都可以抽象为从输入设备读取输入信息,通过运算器和控制器来执行存储在存储器里的程序,最终把结果输出到输出设备中。
二、I/O模型解读
I/O 描述了计算机系统与外部设备之间通信的过程。输入与输出。
操作系统里:为了保证操作系统的稳定性和安全性,一个进程的地址空间划分为 用户空间(User space) 和 内核空间(Kernel space ) 。
应用程序都是运行在用户空间,只有内核空间才能进行系统态级别的资源有关的操作。我们想要进行 IO 操作,一定是要依赖内核空间的能力。用户空间的程序不能直接访问内核空间。
从应用程序的视角来看的话,我们的应用程序对操作系统的内核发起 IO 调用(系统调用),操作系统负责的内核执行具体的 IO 操作。也就是说,我们的应用程序实际上只是发起了 IO 操作的调用而已,具体 IO 的执行是由操作系统的内核来完成的。

三、BIO
同步阻塞 IO 模型中,应用程序发起 read 调用后,会一直阻塞,直到内核把数据拷贝到用户空间。
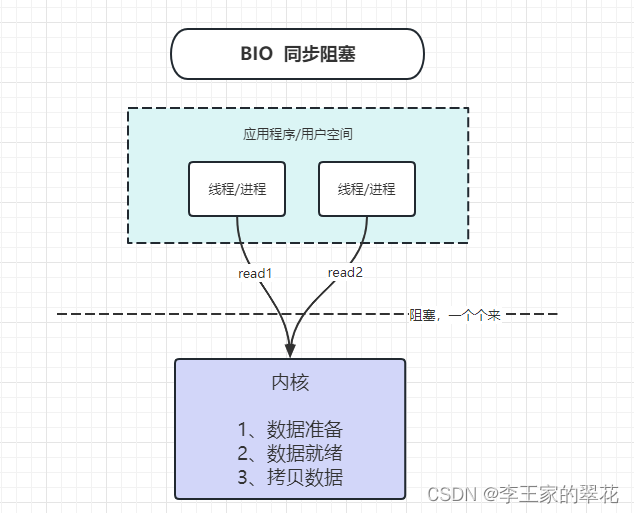
这就有个问题,一旦并发数过多,排队的时间就够呛。所以有了NIO。
四、NIO
1、同步非阻塞IO

同步非阻塞 IO 模型中,应用程序会一直发起 read 调用,等待数据从内核空间拷贝到用户空间的这段时间里,线程依然是阻塞的,直到在内核把数据拷贝到用户空间。
但是有个问题:应用程序不断进行 I/O 系统调用轮询数据是否已经准备好的过程是十分消耗 CPU 资源的,比如轮询了1000次read,会有极大的成本问题。就有了多路复用IO。
2、多路复用IO

线程首先发起 select 调用(1000个文件描述符一次性发送给内核,把用户轮询的事情放在内核中完成,减少无效调用),询问内核数据是否准备就绪,等内核把数据准备好了,用户线程再发起 read 调用。read 调用的过程(数据从内核空间 -> 用户空间)还是阻塞的。
多路复用模型,通过减少无效的系统调用,减少了对 CPU 资源的消耗。
select 调用:内核提供的系统调用,它支持一次查询多个系统调用的可用状态。几乎所有的操作系统都支持。
epoll 调用:linux 2.6 内核,属于 select 调用的增强版本,优化了 IO 的执行效率。
3、带有共享空间的NIO
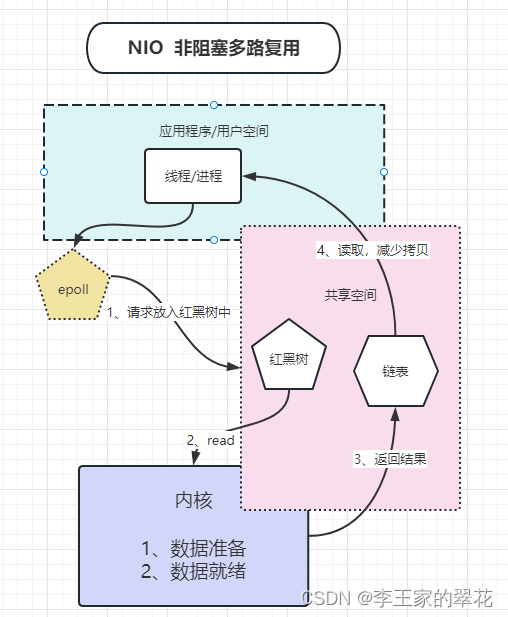
epoll启动共享空间(mmap),把1000次连接(请求)放到红黑树内,把就绪的数据放到链表中,线程之间可以读取到。减少了IO,也减少了拷贝的阻塞。大大提升了效率。Redis的底层就是这么使用的。
还能延伸到零拷贝、kafka,这里不作过多的深入了。
五、AIO
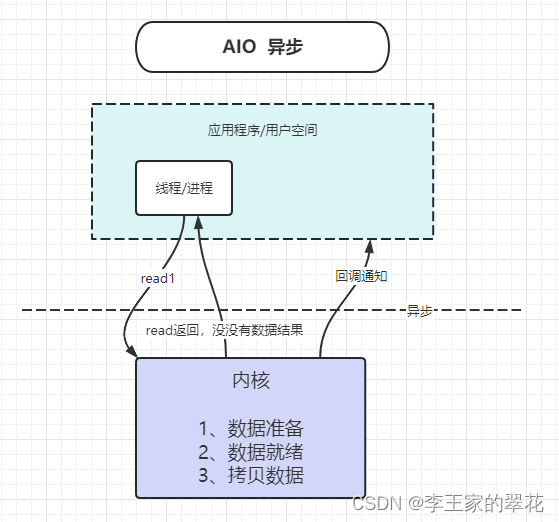
异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。