文章目录
- 1. 概述
- 1.1 Apache Flink
- 1.2 特点
- 1.3 Flink VS Spark Streaming
- 2. 安装与部署
- 2. Flink运行时的组件
- 2.1 作业管理器(JobManager)
- 2.2 任务管理器(TaskManager)
- 2.3 资源管理器(ResourceManager)
- 2.4 分发器(Dispatcher)
- 3. 任务提交流程
- 4. Flink API
- 4.1 不用级别的抽象
- 4.2 常用DataStream API
- 4.2.1 Flink针对DataStream提供了大量的已经实现的DataSource (数据源)接口
- 4.2.2 Flink针对DataStream提供了大量的已经实现的算子
- 4.2.2.1 Map
- 4.2.2.2 Flatmap
- 4.2.2.3 Filter
- 4.2.2.4 KeyBy
- 4.2.2.5 Reduce/Aggregations
- 4.2.2.6 union
- 4.2.27 旁路输出
- 4.2.2.8 window/WindowAll
- 4.2.2.8 Window有序消费
- 4.2.2.9 RichAsyncFunction(外部数据访问的异步 I/O)
1. 概述
1.1 Apache Flink
Apache Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行状态计算。
1.2 特点
- 支持事件时间(event-time)和处理时间(processing-time)语义
- 精确一次(exactly-once)的状态一致性保证
- 低延迟,每秒处理数百万个事件,毫秒级延迟
- 与众多常用存储系统的连接
- 高可用,动态扩展,实现7*24小时全天候运行
1.3 Flink VS Spark Streaming
- 数据模型
- spark采用RDD模型,spark streaming 的 DStream 实际上也就是一组组小批数据RDD的集合
- flink基态数据模型是数据流,以及事件(Event)序列
- 运行时架构
- spark 是批计算,将DAG划分为不同的stage,一个完成后才可以计算下一个
- flink是标准的流执行模式,一个事件在一个节点处理完后可以直接发往下一个节点进行处理
2. 安装与部署
2. Flink运行时的组件
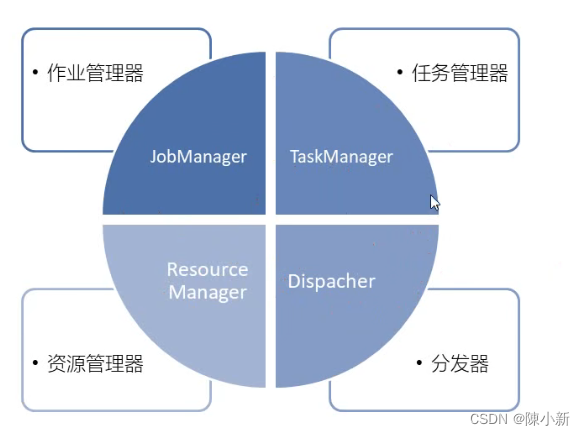
2.1 作业管理器(JobManager)
- 控制一个应用程序执行的主进程,也就是说,每个应用程序都会被一个不同的JobManager所控制执行
- JobManager会先接收要执行的应用程序,这个应用程序会包括:作业图(JopGraph)、逻辑数据流图(Logical dataflow graph)和打包了所有类、库和其他资源的JAR包
- JobManager会把JopGraph转换成一个物理层面的数据流图,这个图被叫做"执行图"(ExecutionGraph),包含了所有可以并发执行的任务
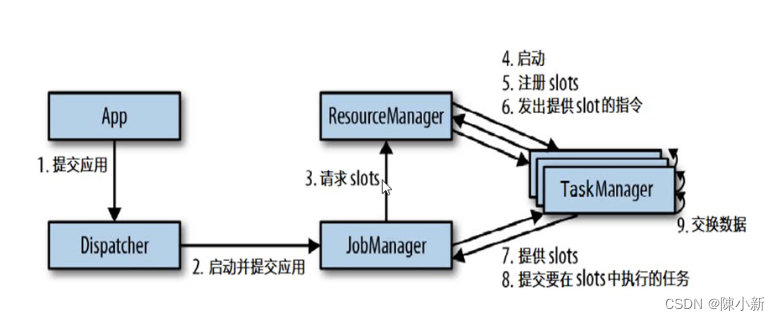
- JobManager会向资源管理器(ResourceManager)请求执行任务必要的资源,也就是任务管理器(TaskManager)上的插槽(slot)。一旦它获取到了足够的资源,就会将执行图分发到真正运行它们的TaskManager上。而在运行过程中,JobManager会负责所有需要中央协调的操作,比如说检查点(checkpoints)的协调.
2.2 任务管理器(TaskManager)
- Flink中的工作进程。通常在Flink中会有多个TaskManager运行,每一个TaskManager都包含了一定数量的插槽((slots)。插槽的数量限制了TaskManager能够执行的任务数量。
- 启动之后,TaskManager会向资源管理器注册它的插槽;收到资源管理器的指令后,TaskManager就会将一个或者多个插槽提供给
JobManager调用。JobManager就可以向插槽分配任务(tasks)来执行了。 - 在执行过程中,一个TaskManager可以跟其它运行同一应用程序的
TaskManager交换数据。
2.3 资源管理器(ResourceManager)
- 主要负责管理任务管理器(TaskManager)的插槽(slot),TaskManger插槽是Flink中定义的处理资源单元。
- Flink为不同的环境和资源管理工具提供了不同资源管理器,比如YARN、Mesos、K8s,以及standalone部署。
- 当JobManager申请插槽资源时,ResourceManager会将有空闲插槽的TaskManager分配给JobManager。如果ResourceManager没有足够的插槽来满足JobManager的请求,它还可以向资源提供平台发起会话,以提供启动TaskManager进程的容器。
2.4 分发器(Dispatcher)
- 可以跨作业运行,它为应用提交提供了REST接口。
- 当一个应用被提交执行时,分发器就会启动并将应用移交给一个JobManager。
- Dispatcher也会启动一个Web UI,用来方便地展示和监控作业执行的信息。
- Dispatcher在架构中可能并不是必需的,这取决于应用提交运行的方式。
3. 任务提交流程
4. Flink API
4.1 不用级别的抽象
Flink提供了四种不同层级的API。低级API,核心API,Table API,SQL

-
Flink API 最底层的抽象为有状态实时流处理。其抽象实现是 Process Function,并且 Process Function 被 Flink 框架集成到了 DataStream API 中来为我们使用。自由度最高,从而允许程序可以实现复杂计算。 -
Flink API 第二层抽象是 Core APIs。Core APIs 提供的流式 API(Fluent API)为数据处理提供了通用的模块组件,例如各种形式的用户自定义转换(transformations)、联接(joins)、聚合(aggregations)、窗口(windows)和状态(state)操作等。此层 API 中处理的数据类型在每种编程语言中都有其对应的类。 -
Flink API 第三层抽象是 Table API。Table API 是以表(Table)为中心的声明式编程(DSL)API,例如在流式数据场景下,它可以表示一张正在动态改变的表。
表和 DataStream/DataSet 可以进行无缝切换,Flink 允许用户在编写应用程序时将 Table API 与 DataStream/DataSet API 混合使用。 -
Flink API 最顶层抽象是 SQL。这层抽象在语义和程序表达式上都类似于 Table API,但是其程序实现都是 SQL 查询表达式。SQL 抽象与 Table API 抽象之间的关联是非常紧密的,并且 SQL 查询语句可以在 Table API 中定义的表上执行。
4.2 常用DataStream API
Flink DataStream的常用API(主要分为三块):DataSource(程序的数据源输入),Transformation(具体的操作),Sink(程序的输出)
4.2.1 Flink针对DataStream提供了大量的已经实现的DataSource (数据源)接口
- 基于文件: readTextFile (path)读取文本文件,文件遵循Text InputFormat逐行读取规则并返回。
- 基于Socket: socketTextStream从Sokcet中读取数据,元素可以通过一个分隔符分开
- 基于集合: fromCollection (Collection)通过Java的Collection集合创建一个数据流,集合中的所有元素必须是相同类型的。
- 自定义输入: addSource可以实现读取第三方数据源的数据。
4.2.2 Flink针对DataStream提供了大量的已经实现的算子
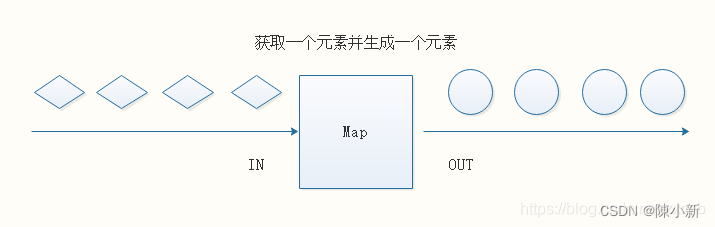
4.2.2.1 Map
DataStream → DataStream
输入一个元素,然后返回一个元素,中间可以进行清洗转换等操作。
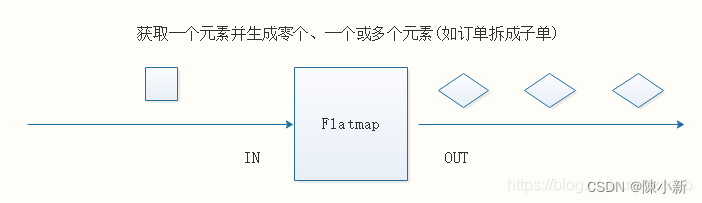
4.2.2.2 Flatmap
DataStream → DataStream
输入一个元素,可以返回零个,一个或者多个元素
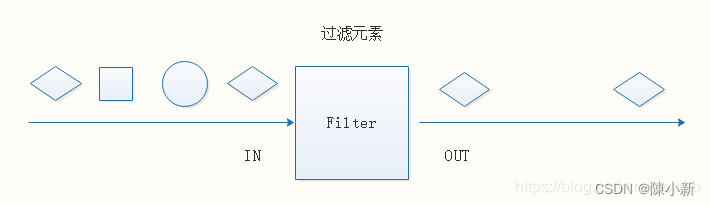
4.2.2.3 Filter
DataStream → DataStream
过滤函数,对传入的数据进行判断,符合条件的数据会被留下。
4.2.2.4 KeyBy
DataStream → DataStream
根据指定的Key进行分组,Key相同的数据会进入同一个分区。

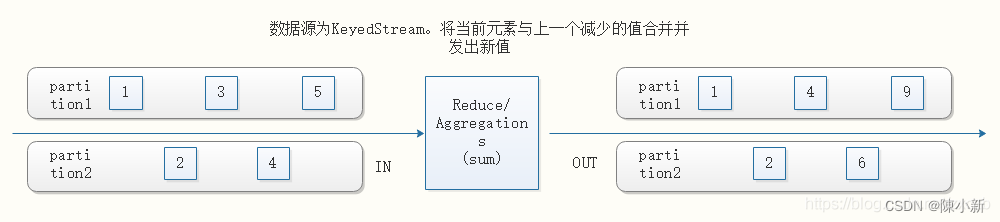
4.2.2.5 Reduce/Aggregations
KeyedStream → DataStream
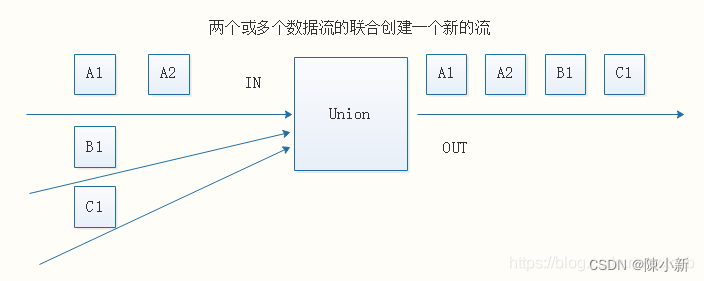
4.2.2.6 union
DataStream → DataStream
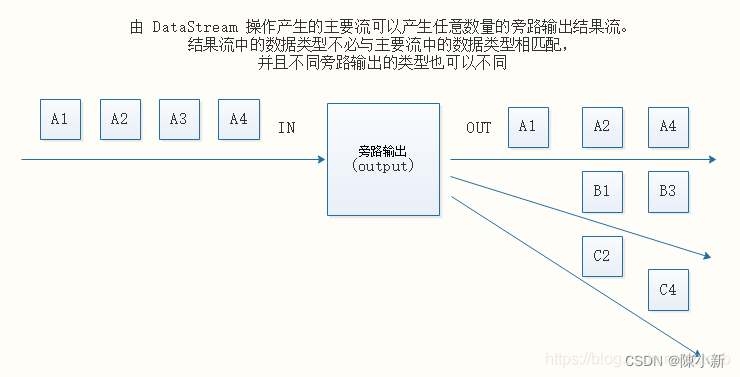
4.2.27 旁路输出
DataStream → DataStream
4.2.2.8 window/WindowAll
-
KeyedStream → WindowedStream
-
DataStream → AllWindowedStream
Sliding Windows滑动窗口(time/count):
- 每次滑动window slide的距离, 并获取window size范围内的数据进行处理
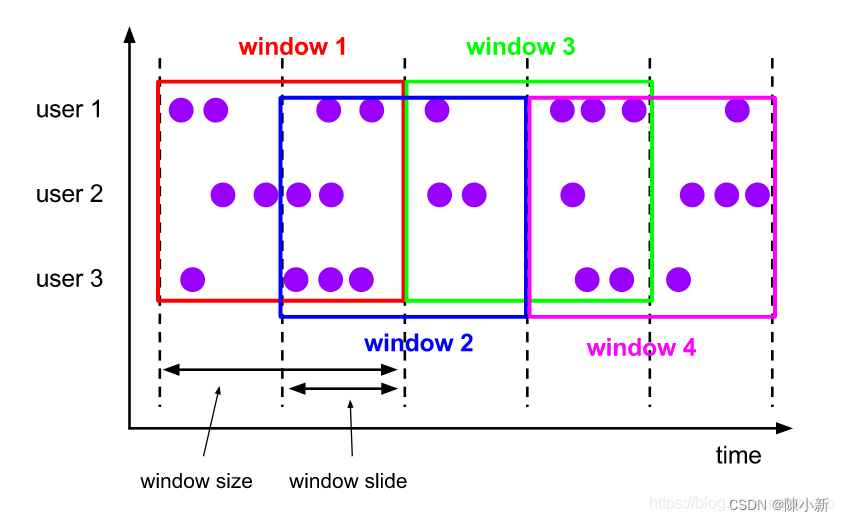
Tumbling Windows滚动窗口(time/count): (滚动窗口是window size = widow slide的滑动窗口)
- 每次获取window size范围内的数据进行处理
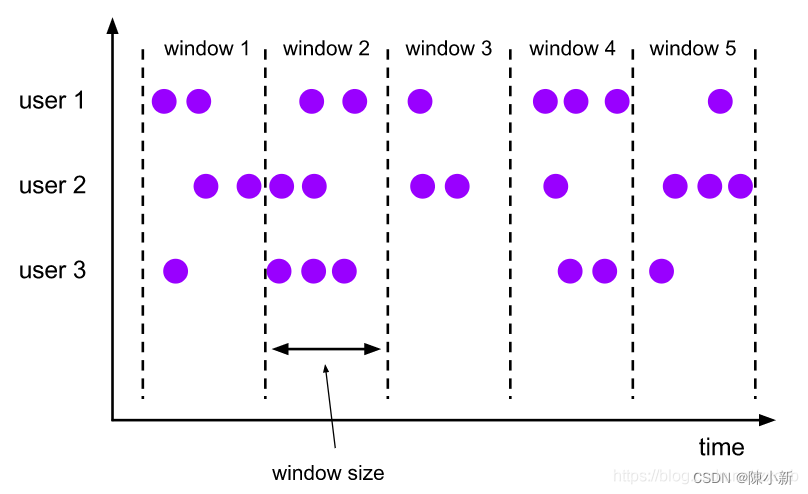
4.2.2.8 Window有序消费
-
场景: Window基于 EventTime 统计, 需要既实时统计, 又需要保障数据准确性
-
问题: Window基于 EventTime 而不是 OperateTime 计算时, Flink会丢弃延时数据
Watermark(水印):
-
缺点: 降低吞吐量(缓存历史窗口数据), 仅能处理允许延时范围内的数据, 迟到严重数据依然会被丢弃
-
窗口按 EventTime 计算后, 划分每个窗口开始,结束时间点; 按读取到消息被标记上的Watermark判断是否超过结束时间点触发统计
-
Watermark 标记规则: 例: 窗口结束时间-2秒 -> 允许消息延迟2秒
Allowed Lateness(允许迟到机制):
- 将延迟过于严重的数据输出到侧输出流, 侧输出流存储或进行特殊处理
4.2.2.9 RichAsyncFunction(外部数据访问的异步 I/O)
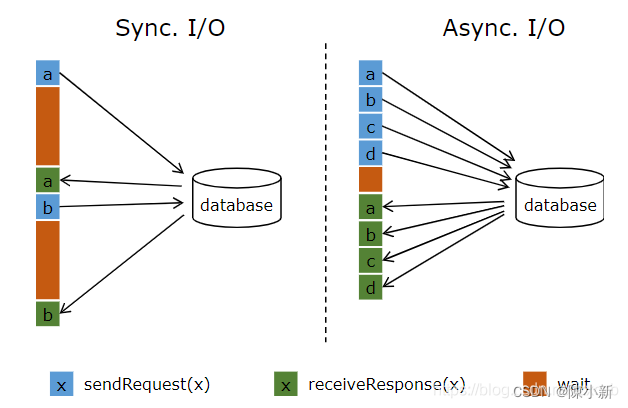
实现数据库(或键/值存储)的异步 I/O 交互需要支持异步请求的数据库客户端。许多主流数据库都提供了这样的客户端。
如果没有这样的客户端,可以通过创建多个客户端并使用线程池处理同步调用的方法,将同步客户端转换为有限并发的客户端。
然而,这种方法通常比正规的异步客户端效率低。
![[附源码]JAVA毕业设计旅游景点展示平台的设计与实现(系统+LW)](https://img-blog.csdnimg.cn/8590f7252ccd43f8a212d47caa611678.png)



![[论文精读|顶刊论文]Relational Triple Extraction: One Step is Enough](https://img-blog.csdnimg.cn/29ba7e6e860f4adfa34373f329c91930.png#pic_center)
![[附源码]Python计算机毕业设计Django区域医疗服务监管可视化系统](https://img-blog.csdnimg.cn/b6b0628d0f444cfba87a144e0bc69b30.png)







![[附源码]计算机毕业设计校友社交系统Springboot程序](https://img-blog.csdnimg.cn/5d3f9627b05d4b83b221f582c7b955be.png)


