前言
在OLAP实践中,在有数据更新的场景中,比如存储订单数据,我们经常会用到ReplaceingMergeTree引擎来去重数据,以获取数据的最新状态。但是ReplaceingMergeTree引擎实现数据的去重合并的操作是异步的,这样在实际查询的时候,其实是仍然有一部分数据是未进行合并的。为了保证统计数据的准确性,比如订单金额,一个常用的方法是在查询时增加final关键字。那final关键字是如何合并数据的,以及合并的数据范围是怎样的,本文就对此做一个简单的探索。
知识准备
分片:分片就是clickhouse的实例节点,不同的分片就代表不同的节点或机器,分片之间是物理隔离的 分区:分区是一个表中通过指定的规则划分而成的逻辑数据集,比如日期分区,分区是一种逻辑上的,不同的分片上会有相同的分区
探索过程
探索过程比较长,请大家保持耐心,如果不想看过程,可以直接看结论哈,马上开始~
本文基于的clickhouse版本为version 23.3.1.2823
创建表
创建ReplacingMergeTree引擎的表,分布式表union_order_onl_all_test,本地表union_order_onl_local_test,以日期为分区,order_id作为排序键,mid是消息ID,用消息ID作为数据变更的版本号,同时order_id字段作为分片hash字段,不同的订单会被写入到不同的实例上。
CREATE TABLE gbn_onl_mix.union_order_onl_local_test on cluster lf6ckcnts05
(
`order_id` UInt64 COMMENT '订单号',
`after_prefr_amount_1` Float64 COMMENT '订单金额',
`deal_flag` UInt8 COMMENT '成交标识',
`mid` String COMMENT '消息ID',
`update_time` String COMMENT '更新时间',
`ver` UInt64 DEFAULT toUInt64OrZero(mid) COMMENT '版本号',
`dt`Date DEFAULT toDate(update_time) COMMENT '分区'
)
ENGINE = ReplicatedReplacingMergeTree('/clickhouse/lf6ckcnts05/jdob_ha/gbn_onl_mix/lf6ckcnts05/{shard}', '{replica}', ver)
PARTITION BY toYYYYMMDD(dt)
ORDER BY (order_id)
TTL dt + toIntervalDay(7)
SETTINGS storage_policy = 'jdob_ha', index_granularity = 3
CREATE TABLE gbn_onl_mix.union_order_onl_all_test on cluster lf6ckcnts05 as gbn_onl_mix.union_order_onl_local_test
engine=Distributed(lf6ckcnts05, gbn_onl_mix, union_order_onl_local_test, cityHash64(order_id)) ;
数据初始化
初始数据包括2个订单,111和222,初始版本都是0,初始成交状态也都是0,日期是2023-05-28
INSERT into gbn_onl_mix.union_order_onl_all_test (order_id,after_prefr_amount_1,deal_flag,mid,update_time) values ('111',1,0, 0,'2023-05-28'),('222',2,0,0,'2023-05-28');
查询分区信息和数据如下:可以看到数据被写入到了1个分区的2个part中,分区都是20230528,part名都是20230528_0_0_0
知识点详见 https://clickhouse.com/docs/zh/engines/table-engines/mergetree-family/custom-partitioning-key 分区信息有重复是因为lf6ckcnts05集群的配置是有一个副本


验证同分片同分区数据合并
final合并
order_id=111有数据更新,mid变成了1,即插入如下数据
INSERT into gbn_onl_mix.union_order_onl_all_test (order_id,after_prefr_amount_1,deal_flag,mid,update_time) values ('111',1,0, 1,'2023-05-28');
查询分区信息如下,可见增加了一个part,分区为20230528,part名为20230528_1_1_0

查询数据如下,可见order_id=111的订单,版本0和版本1的数据都是存在的
SELECT * FROM gbn_onl_mix.union_order_onl_all_test WHERE dt = '2023-05-28'

查询数据使用final结果如下,可见order_id=111的订单,只查询出最新版本1的数据
SELECT * FROM gbn_onl_mix.union_order_onl_all_test final WHERE dt = '2023-05-28'

再查询一下实际的数据如下,结果order_id=111的2个版本的数据还是都被查询出来了,可见final查询对实际物理数据的存储没有影响
SELECT * FROM gbn_onl_mix.union_order_onl_all_test WHERE dt = '2023-05-28'

小结:final可以合并同分片同分区的数据,并且final合并数据只是针对当次查询,不会对数据进行物理合并
引擎合并
order_id=111有数据更新,mid变成了2,即插入如下数据
INSERT into gbn_onl_mix.union_order_onl_all_test (order_id,after_prefr_amount_1,deal_flag,mid,update_time) values ('111',1,0, 2,'2023-05-28');
查询分区和数据如下,分区20230528,增加一个part,名为20230528_2_2_0
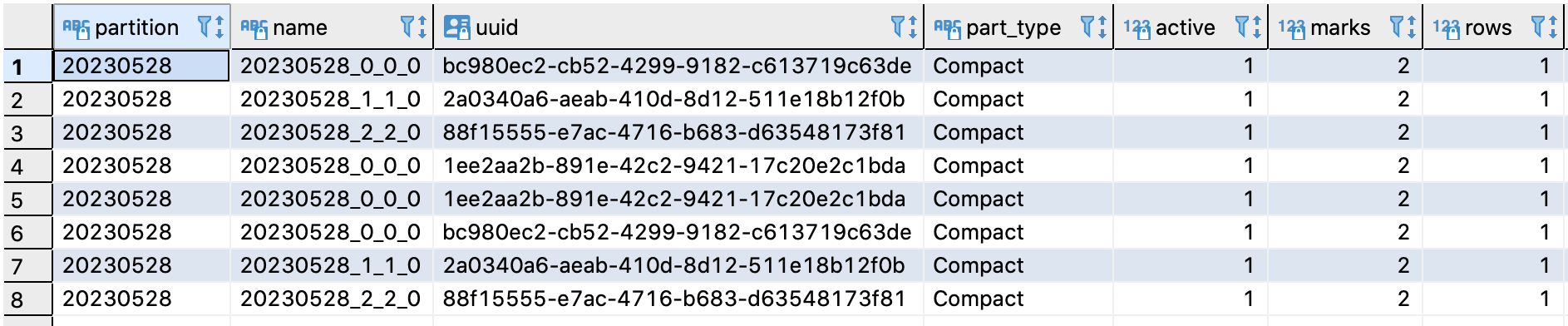

order_id=111有数据更新,mid变成了3,即插入如下数据
INSERT into gbn_onl_mix.union_order_onl_all_test (order_id,after_prefr_amount_1,deal_flag,mid,update_time) values ('111',1,0, 3,'2023-05-28');
分区20230528,增加名为20230528_2_2_0的part
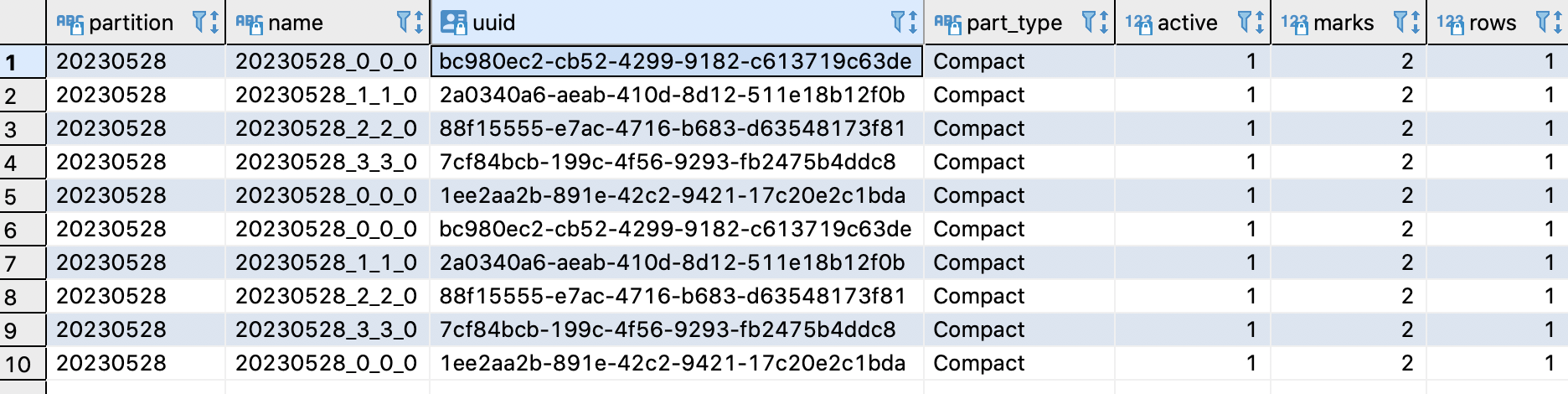
此时数据还没有被引擎合并,先去吃个饭吧~
Later For a Moment ~~~
吃饭回来,查询分区,发现数据已经被引擎合并了,合并后的分区为20230528_0_3_1,但是同分区不同分片的数据没有被合并

小结:ReplaceingMergeTree引擎合并数据,合并的是同分片同分区的数据
验证同分片不同分区数据合并
final合并
order_id=111数据继续更新,mid变成了4,即插入如下数据
INSERT into gbn_onl_mix.union_order_onl_all_test (order_id,after_prefr_amount_1,deal_flag,mid,update_time) values ('111',1,1, 4,'2023-05-29');
查询分区和数据如下,可见增加了一个part,分区是20230529,part名为20230529_0_0_0,order_id=111订单数据版本3和版本4同时存储,数据还未合并


使用final查询数据,结果如下,我们会发现,order_id=111的订单在2个分区2023-05-28和2023-05-29中的数据被合并了
SELECT * FROM gbn_onl_mix.union_order_onl_all_test final

小结:final可以跨分区进行合并
引擎合并
order_id=111数据继续更新,mid变成5、6、7,即插入如下数据
INSERT into gbn_onl_mix.union_order_onl_all_test (order_id,after_prefr_amount_1,deal_flag,mid,update_time) values ('111',1,1, 5,'2023-05-29','111',1,1, 6,'2023-05-29','111',1,1, 7,'2023-05-29');
查询分区和数据如下,可见增加part 20230529_1_1_0,只插入了一条最新消息为7的数据,即插入数据时,数据就已经合并了
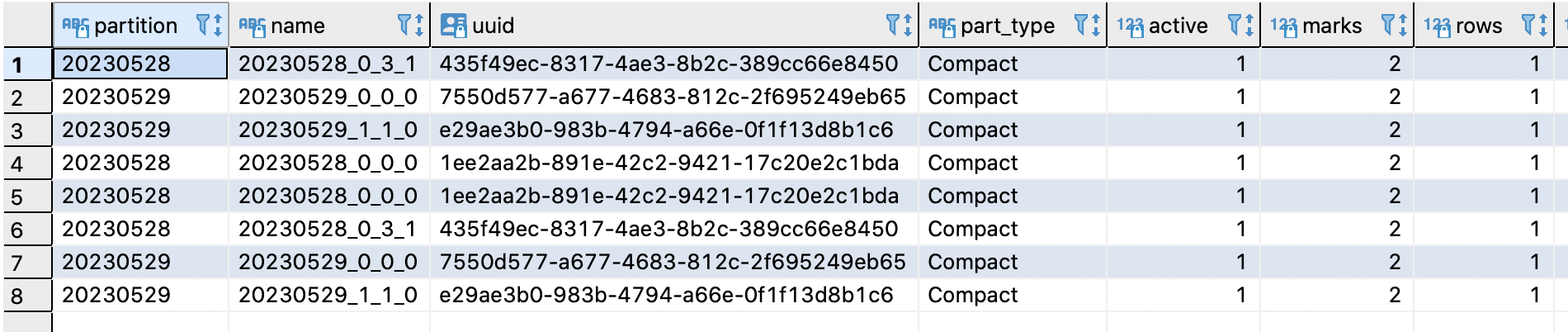

order_id=111数据继续更新,mid变成8、9,即插入如下数据
INSERT into gbn_onl_mix.union_order_onl_all_test (order_id,after_prefr_amount_1,deal_flag,mid,update_time) values ('111',1,1, 8,'2023-05-29');
INSERT into gbn_onl_mix.union_order_onl_all_test (order_id,after_prefr_amount_1,deal_flag,mid,update_time) values ('111',1,1, 9,'2023-05-29');
查询分区和数据如下,新增part 20230529_2_2_0和20230529_3_3_0
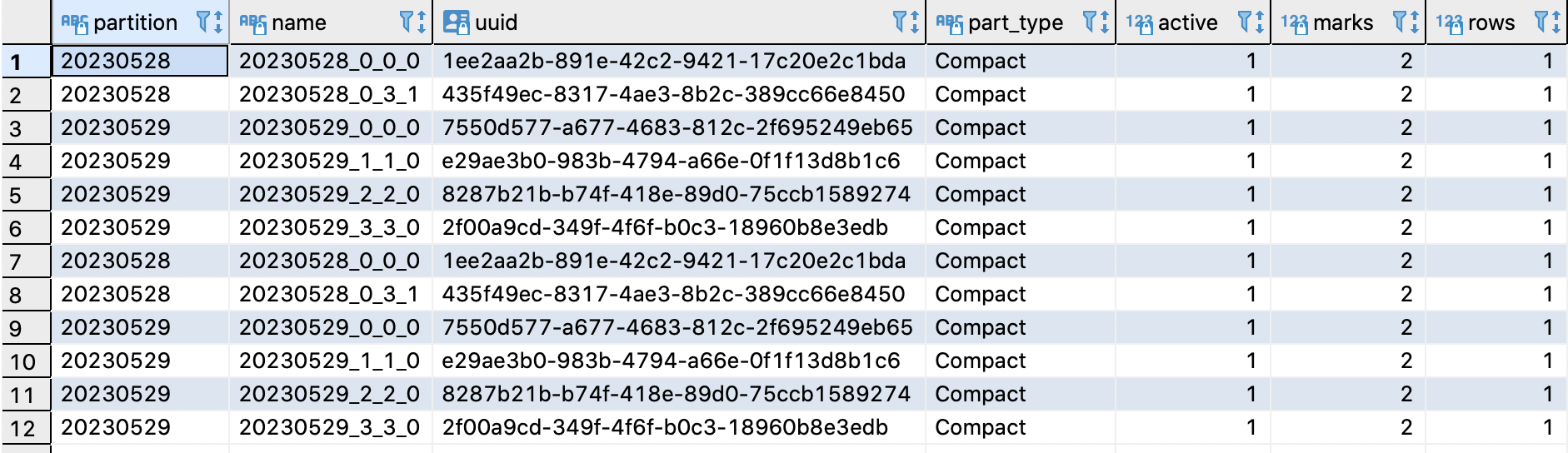

使用final同时查询2个分区数据,以及单独查询单个分区的数据,结果如下,可以看到卡不同的分区,最后合并的结果也不同,(这不是废话嘛~~)
SELECT * FROM gbn_onl_mix.union_order_onl_all_test final

SELECT * FROM gbn_onl_mix.union_order_onl_all_test final WHERE dt = '2023-05-29'

SELECT * FROM gbn_onl_mix.union_order_onl_all_test final WHERE dt = '2023-05-28'

Later For a Moment ~~~
数据合并完成,结果如下,part 20230529_0_0_0、20230529_1_1_0、20230529_2_2_0、20230529_3_3_0变成active=0,合并后part为20230529_0_3_1,但是分区20230508的part 20230528_0_3_1并没有被合并
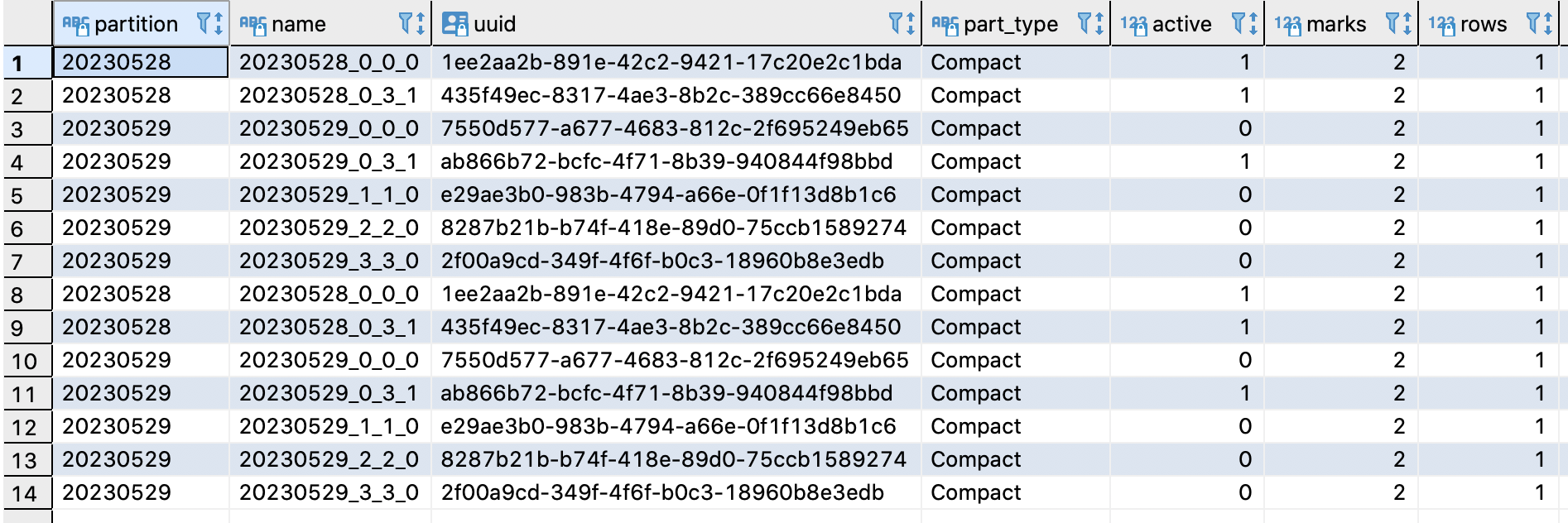
查询分区数据,结果如下
SELECT * FROM gbn_onl_mix.union_order_onl_all_test WHERE dt = '2023-05-28'
SELECT * FROM gbn_onl_mix.union_order_onl_all_test WHERE dt = '2023-05-29'


小结:无论是从分区信息还是从数据结果来看,ReplaceingMergeTree引擎是不会合并同分片不同分区的数据的
验证不同分片数据合并
final合并
考虑order_id=222的订单数据,金额修改成22以做区分,在不同的分片上插入变更数据,本次插入改用向本地表中插入数据,可达到跨分片实例的效果,如下
order_id=222的订单,mid变成1,即插入如下数据
INSERT into gbn_onl_mix.union_order_onl_local_test (order_id,after_prefr_amount_1,deal_flag,mid,update_time) values ('222',22,0,1,'2023-05-28');
查询数据,发现居然和版本0插入到同一个分片上了
SELECT * FROM gbn_onl_mix.union_order_onl_local_test WHERE dt = '2023-05-28'

再来一次,order_id=222的订单,mid变成2,即插入如下数据
INSERT into gbn_onl_mix.union_order_onl_local_test (order_id,after_prefr_amount_1,deal_flag,mid,update_time) values ('222',22,0,2,'2023-05-28');
查询数据,可见这次数据是插入到了不同的分片实例上
SELECT * FROM gbn_onl_mix.union_order_onl_local_test WHERE dt = '2023-05-28'

查看目前分区20230528的数据,如下
SELECT * FROM gbn_onl_mix.union_order_onl_all_test WHERE dt = '2023-05-28'

使用final查询结果如下,可见final查询不能合并跨分片的数据,(order_id=222,ver=1和ver=2是存储在不同分片上的数据)
SELECT * FROM gbn_onl_mix.union_order_onl_all_test final WHERE dt = '2023-05-28'

引擎合并
手动触发引擎合并,如下
optimize table union_order_onl_local_test on cluster lf6ckcnts05 FINAL;
查询数据结果,如下,结果同final查询

小结:无论是final查询还是引擎合并,不同分片上的数据都不会被合并,即使是同分区的也不会被合并
结论
啰哩啰嗦这么多,总结一下吧~~
1.对于不同分片上的数据来说,ReplaceingMergeTree引擎合并和查询时加final的合并,都不会合并不同分片上的数据
2.对于相同分片上的数据来说,ReplaceingMergeTree引擎合并,只合并同分区的数据,不同分区的数据不会合并;查询时加final的合并,会对不同分区的数据进行合并,合并是按照排序键进行合并的,如果想避免不同分区间的合并可以在排序键中增加分区字段
如有问题请指正,欢迎大家沟通交流,感谢~~
作者:京东零售 曹建奇
来源:京东云开发者社区