最近在了解 clang/llvm 的时候突然发现一件事:gcc是一个工具集合,包含了或者调用将程序源代码转换成可执行程序文件的所有工具,而不只是简单的编译器。这帮助我对“编译器”有了更深刻的理解,所以写下本文作为记录。
关于“编译器”的原理和机制的更详细内容在另一篇文章里:clang到底是什么?是编译器?gcc和clang有什么区别?(严格说是gcc和llvm/clang的区别)
从源代码转换成可执行程序的完整过程
从源代码转换成可执行程序的完整过程,也就是我们平时所说的“编译过程”,实际如下(圆角矩形表示代码,矩形表示各种处理器):
可以看到从源代码到可执行程序要经过预处理器(preprocessor)、编译器(compiler)、汇编器(assembler)和连接器(linker)或加载器(loader),而编译器只是负责将源代码转换成对应的汇编代码的功能。
接下来,就用gcc来展示上图中的流程。
gcc和配套的cpp、as、ld处理转换程序
上面的几种处理转换程序除了编译器和汇编器,其他三个估计都很很少听到。下面就用最经典的 C 语言和gcc来介绍这个过程,gcc包含的预处理器为cpp,还会调用汇编器as、连接器ld。
我之前以为
as、ld也是包含在gcc中的。但是 GNU 开发组的人告诉我,gcc只包含预处理器和编译器,汇编器和连接器不是 gcc 项目的一部分,而且必须单独提供(很多系统中,是 binutils 项目提供的)(经过验证,Ubuntu 就是这样)
三者的手册界面如下:

再次说明一下,虽然gcc这个命令叫“编译器”,但是包含了预处理器,以及会自动调用了其他的处理程序,所以在表面上看,是gcc自己完成源代码到可执行程序转换。
由于是多个工具组成的,所以你也可以自己决定进行到哪一步,下面你就能看到了。
编译过程演示准备
为了方便读者理解编译过程,将会使用一个实例程序来进行演示。示例程序将会计算12*13*14,并且如果值小于1000就输出值,否则提醒超出了(也就是必定体系)。
本文使用
下面列一下准备工作,一共三个文件和一个空白目录build。
空白目录build是为了方便处理生成文件,不然两次测试可能会搞得乱糟糟。可以使用下面的语句生成:
mkdir build
三个文件为main.c、calc.c和calc.h ,包含的代码如下:
//main.c
#include <stdio.h>
#include "calc.h"
#define MAXNUM 1000
int main()
{
int a = calc(12, 13, 14);
if (a >= MAXNUM)
printf("Over Limit!\n");
else
printf("Result: %d", a);
return 0;
}
//calc.c
#include <stdio.h>
#include "calc.h"
int calc(int a, int b, int c)
{
return a*b*c;
}
//calc.h
int calc(int, int, int);
由于gcc可以指定进行到哪一步,所以我们先用gcc进行演示,再使用cpp、gcc、as和ld进行演示。
使用gcc进行分步演示编译过程
gcc支持在将源代码转换成可执行程序的过程中的某一步停止,也就是限定终点(如果依次手动操作的话,也就是只进行某一步),我们就先用这个机制来展示整个编译过程。
使用gcc演示会简单一些,其次绝大部分程序的使用几乎等价gcc加选项,除了一些小细节。唯一大不同的是连接器。
所以本节只是为了让你了解流程,每个处理器的详细介绍和扩展见下一节。
预处理阶段
首先是预处理源代码,如果需要在预处理之后停止需要使用选项-E:
$ gcc -E ../calc.c -o calc.i
$ gcc -E ../main.c -o main.i
这里需要使用-o来指定输出文件名称,这是因为gcc调用的预处理器cpp会将处理后的内容输出到标准输出,而不是生成某个文件。预处理之后的文件后缀为.i,所以这里把后缀都换成.i。此时使用ls查看如下:
$ ls
calc.i main.i
编译阶段
接下来是编译阶段。如果你想编译但不进行汇编,那么使用-S选项:
$ gcc -S main.i calc.i
这里会对两个文件进行编译,并生成汇编语言文件,生成文件名是将原文件的.c、.i等后缀替代成.s(因为是从某一步开始,到编译这步停止,不同后缀表示开始的阶段),此时使用ls查看如下:
$ ls
calc.i calc.s main.i main.s
汇编阶段
接下来是汇编阶段。这里使用选项-c,这个选项是进行编译和汇编,但是不进行连接。上文提到过,是根据后缀判断从整个编译流程的哪一步开始,然后进行到汇编之后、连接之前这个阶段。刚才是进行了编译,但是没有汇编,所以这里使用-c相当于只使用了汇编器:
$ gcc -c calc.s main.s
和-S选项一样,它会自动生成对象文件(object file),文件名为用.o替代掉源文件名的.c、.i、.s等后缀,此时使用ls查看如下:
$ ls
calc.i calc.o calc.s main.i main.o main.s
连接阶段
这是最后的连接阶段,使用-o直接输出即可,因为从汇编之后的对象文件到可执行程序和从源代码到可执行程序这个结果是一样的,gcc这些选项只是限定“终点”。这里我们将输出文件名设定为calc:
$ gcc -o calc main.o calc.o
使用ls看到如下内容:
$ ls
calc calc.i calc.o calc.s main.i main.o main.s
这时候我们运行calc看看:
$ ./calc
Over Limit!
运行正常!
单独调用cpp、gcc、as、ld
这部分除了连接器,其他几乎和使用gcc加选项差不多,所以会说很多细节和扩展的内容。
这里是处于演示学习目的,所以从头到尾依次调用。实际上并不会这样使用,只会单独使用个别工具,或者某个阶段特地使用某个工具。
使用预处理器cpp
首先第一步是使用预处理器cpp:
$ cpp ../calc.c -o calc.i
$ cpp ../main.c -o main.i
$ ls
calc.i main.i
直接cpp并不会产生文件,而是直接输出到标准输出了,如果你想保存成文件需要使用选项-o,这里我们必须保存,所以必须使用-o。但是由于这是一对一的,所以需要两条命令。
预处理器会将源代码中引用头文件(#include)、宏(#define)、状态控制(ifdef 等)等内容进行转换,以供后面的步骤使用。由于这一步主要是将宏进行替换,所以预处理器也被称为宏处理器(macro processor)。
这里我说的是供后面步骤使用,而不是供编译器使用,这是因为预处理器可能运行不止一次,或者做其他用途。你甚至可以在汇编代码中加入 C 语言的宏,然后使用预处理器将其处理好,再用汇编器转换成可执行程序(C headers in Asm)。
我们来看看预处理后的内容(main.i),可以看到产生了很多内容(wc统计为 743 行,源文件才 16 行),不过前面那一大堆的部分都是#include <stdio.h>的替换,主要看最后的这一部分:
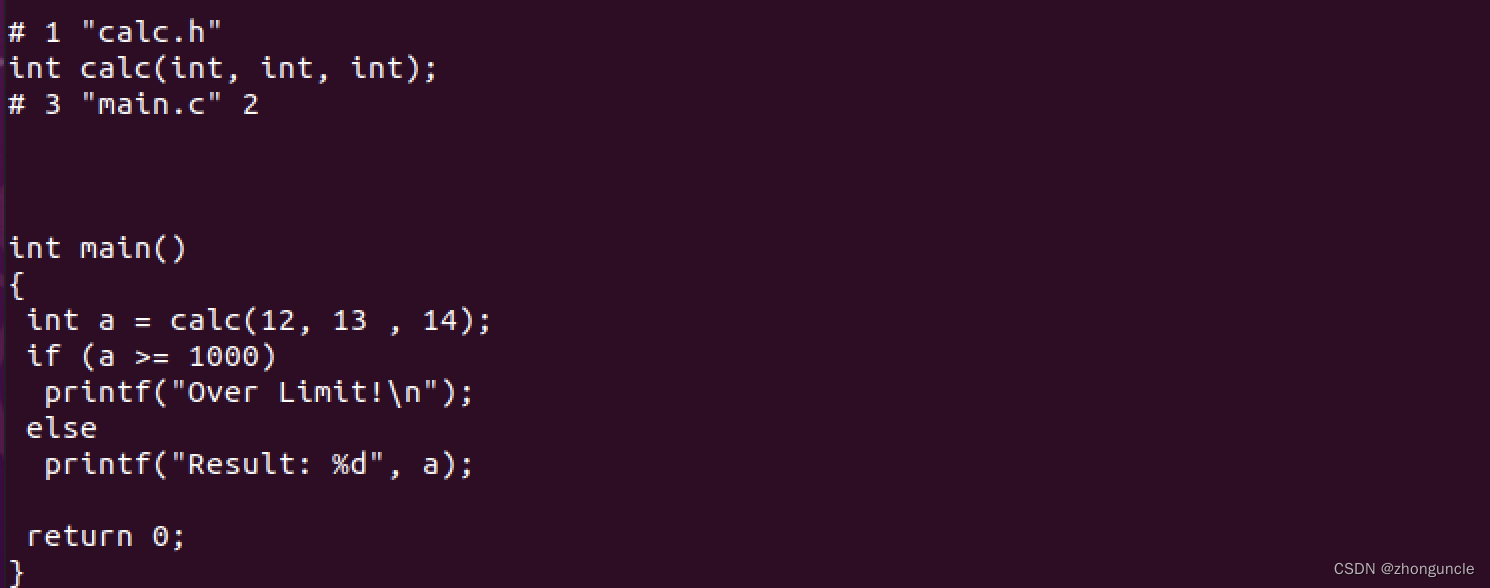
可以看到#include "calc.h"被替换成了头文件中的int calc(int, int, int);,源代码中的宏MAXNUM也被替换成了对应的1000。
使用编译器gcc
接下来要使用编译器将预处理过的文件编程,由于编译器就是gcc,所以我们还是要使用gcc -S来将预处理之后的文件转换成汇编文件:
$ gcc -S main.i calc.i
$ ls
calc.i calc.s main.i main.s
这时候生成的文件就是汇编语言:
.file "calc.c"
.text
.globl calc
.type calc, @function
calc:
.LFB0:
.cfi_startproc
endbr64
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movl %edi, -4(%rbp)
movl %esi, -8(%rbp)
movl %edx, -12(%rbp)
movl -4(%rbp), %eax
imull -8(%rbp), %eax
imull -12(%rbp), %eax
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size calc, .-calc
.ident "GCC: (Ubuntu 11.3.0-1ubuntu1~22.04.1) 11.3.0"
.section .note.GNU-stack,"",@progbits
.section .note.gnu.property,"a"
.align 8
.long 1f - 0f
.long 4f - 1f
.long 5
0:
.string "GNU"
1:
.align 8
.long 0xc0000002
.long 3f - 2f
2:
.long 0x3
3:
.align 8
4:
需要注意一件事,如果你要拿这样生成汇编文件进行学习汇编,那么去看看我的一篇文章:【更新中】苹果自家的as汇编器的特色风格(与微软masm汇编器语言风格的不同),因为我知道很多人对汇编的学习是通过学校或者大学教材,而国内外很多教材都是微软的masm汇编器风格的汇编语言,这与as的语法不一样,有些地方是相反的。苹果虽然是自己写的as,但是与 GNU 的as只是稍有不同,很多语法几乎是一样的,所以可以参考一下。
不过非常不建议使用gcc生成的汇编代码学习汇编,因为多余的东西太多了,后面的连接器ld部分就可以看出来引用了多少库。
使用汇编器as
接下来是将汇编文件转换成对象文件(也就是包含机器语言的文件),这需要as,它会像gcc -c一样自动替换后缀:
$ as calc.s -o calc.o
$ as main.s -o main.o
$ ls
a.out calc.o calc.i calc.s main.i main.o main.s
但是需要注意不能一次处理两个文件,不然会报错:
$ as calc.s main.s
main.s: Assembler messages:
main.s:12: Error: symbol `.LFB0' is already defined
main.s:45: Error: symbol `.LFE0' is already defined
这里是因为两个文件都有.LFB0和.LFE0部分,重复了,所以要么单独编译二者,后面连接器会自动处理掉,要么进去手动删一下这部分,就可以生成为一个对象文件。
使用连接器ld
说真的这里只是展示才用ld,哪怕你是直接手写的汇编,也建议使用gcc来进行处理。因为现在 Ubuntu 的引用库非常复杂,ld默认可以访问的路径是空的,需要手动设置,文档和网上说的crt0.o的使用也不顺利。
连接器的工作
为了介绍连接器,这里需要先解释一下程序实际上是如何运行的,详细信息你可以自己看看一些专业书,这里只做简单不严谨的解释:程序本质是存放机器语言的文件,在打开之后会放进内存,不论是 swap 还是快表等任何内存存放机制,它在逻辑上是连续的,有一个程序计数器会记录当前的绝对内存地址,当内存地址到这个程序的空间内的时候,就开始调用这个程序的指令(机器语言)来进行操作。所以不论如何跳转、循环,它实际上都是连续、顺序的。
存放指令的文件就是对象文件,但是这时候可能顺序不对、不包括引用的外部库的指令,或者有其他的问题还不能直接执行。而将这些指令按照源代码设计、顺序摆放到一起,变成一个可以放到内存中的可执行文件,这就是连接器的工作。
此时如果用file查看此时的main.o文件,那么可以看到这是一个“relocatable(可重新分配的)”文件:
$ file main.o
main.o: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), not stripped
如果你去运行它,是无法运行的,会显示“执行格式错误:
$ ./main.o
-bash: ./main.o: cannot execute binary file: Exec format error
连接器会将其和其他对象文件“组合”在一起,为每一部分分配好自己的相对地址,形成一个最终的可执行文件。这样加载入内存的时候,就可以形成绝对地址,然后就可以让程序计数器调用这些地址的指令了。
使用ld完成最后的工作
如果此时你用ld简单地连接两个对象文件,那么会出现以下错误:
$ ld main.o calc.o
ld: warning: cannot find entry symbol _start; defaulting to 0000000000401000
ld: main.o: in function `main':
main.c:(.text+0x37): undefined reference to `puts'
ld: main.c:(.text+0x52): undefined reference to `printf'
这里有两类错误,下面依次解释一下。
第一个错误ld: warning: cannot find entry symbol _start; defaulting to 0000000000401000是因为 Ubuntu 程序的默认入口是_start,而不是经典的main,所以需要修改一下。
第二个错误是因为puts和printf是 C 标准库里的内容,但是ld并不会自动调用连接 C 标准库,需要手动调用。
为了修改这两个错误,简单修改的命令如下(这个命令生成的程序其实有问题):
ld main.o calc.o -o calc -I/lib64/ld-linux-x86-64.so.2 -lc -e main
这时候ld也不会再报错了,但是当你运行生成的可执行程序之后,你会发现虽然输出了Over Limit!,但是会报错Segmentation fault (core dumped)。如下:
$ ./calc
Over Limit!
Segmentation fault (core dumped)
出现Segmentation fault (core dumped)错误是因为连接的时候设置错误(库不对或者不够,设置出错),进而导致连接错误,最后生成的可执行程序会去访问不该访问的内存空间。
那么为了解决这个问题,完整的命令会很长。
如果是 Ubuntu 20.04,那么是:
ld -o calc -I /usr/lib/gcc/x86_64-linux-gnu/9/collect2 -plugin /usr/lib/gcc/x86_64-linux-gnu/9/liblto_plugin.so -plugin-opt=/usr/lib/gcc/x86_64-linux-gnu/9/lto-wrapper -plugin-opt=-fresolution=/tmp/ccywuOTu.res -plugin-opt=-pass-through=-lgcc -plugin-opt=-pass-through=-lgcc_s -plugin-opt=-pass-through=-lc -plugin-opt=-pass-through=-lgcc -plugin-opt=-pass-through=-lgcc_s --build-id --eh-frame-hdr -m elf_x86_64 --hash-style=gnu --as-needed -dynamic-linker /lib64/ld-linux-x86-64.so.2 -pie -z now -z relro -o main /usr/lib/gcc/x86_64-linux-gnu/9/../../../x86_64-linux-gnu/Scrt1.o /usr/lib/gcc/x86_64-linux-gnu/9/../../../x86_64-linux-gnu/crti.o /usr/lib/gcc/x86_64-linux-gnu/9/crtbeginS.o -L/usr/lib/gcc/x86_64-linux-gnu/9 -L/usr/lib/gcc/x86_64-linux-gnu/9/../../../x86_64-linux-gnu -L/usr/lib/gcc/x86_64-linux-gnu/9/../../../../lib -L/lib/x86_64-linux-gnu -L/lib/../lib -L/usr/lib/x86_64-linux-gnu -L/usr/lib/../lib -L/usr/lib/gcc/x86_64-linux-gnu/9/../../.. calc.o main.o -lgcc --push-state --as-needed -lgcc_s --pop-state -lc -lgcc --push-state --as-needed -lgcc_s --pop-state /usr/lib/gcc/x86_64-linux-gnu/9/crtendS.o /usr/lib/gcc/x86_64-linux-gnu/9/../../../x86_64-linux-gnu/crtn.o
如果是 Ubuntu(WSL),那么是:
$ ld -o calc -I /usr/lib/gcc/x86_64-linux-gnu/11/collect2 -plugin /usr/lib/gcc/x86_64-linux-gnu/11/liblto_plugin.so -plugin-opt=/usr/lib/gcc/x86_64-linux-gnu/11/lto-wrapper -plugin-opt=-fresolution=/tmp/cc4YfMoM.res -plugin-opt=-pass-through=-lgcc -plugin-opt=-pass-through=-lgcc_s -plugin-opt=-pass-through=-lc -plugin-opt=-pass-through=-lgcc -plugin-opt=-pass-through=-lgcc_s --build-id --eh-frame-hdr -m elf_x86_64 --hash-style=gnu --as-needed -dynamic-linker /lib64/ld-linux-x86-64.so.2 -pie -z now -z relro -o calc /usr/lib/gcc/x86_64-linux-gnu/11/../../../x86_64-linux-gnu/Scrt1.o /usr/lib/gcc/x86_64-linux-gnu/11/../../../x86_64-linux-gnu/crti.o /usr/lib/gcc/x86_64-linux-gnu/11/crtbeginS.o -L/usr/lib/gcc/x86_64-linux-gnu/11 -L/usr/lib/gcc/x86_64-linux-gnu/11/../../../x86_64-linux-gnu -L/usr/lib/gcc/x86_64-linux-gnu/11/../../../../lib -L/lib/x86_64-linux-gnu -L/lib/../lib -L/usr/lib/x86_64-linux-gnu -L/usr/lib/../lib -L/usr/lib/gcc/x86_64-linux-gnu/11/../../.. main.o calc.o -lgcc --push-state --as-needed -lgcc_s --pop-state -lc -lgcc --push-state --as-needed -lgcc_s --pop-state /usr/lib/gcc/x86_64-linux-gnu/11/crtendS.o /usr/lib/gcc/x86_64-linux-gnu/11/../../../x86_64-linux-gnu/crtn.o
这个命令有多长你可以复制下来看看。所以gcc生成的时候,就是调用ld的时候就是使用这样的命令,所以实际工作中需要连接的时候,还是直接使用gcc就可以了。
这样生成的可执行程序就工作很完美了,如下:
$ ./calc
Over Limit!
写这篇文章的过程中我学到了很多,也希望能帮到有需要的人~