文章目录
- 基础安全性质
- 保密性(Confidentiality)
- 完整性(Integrity)
- 可用性(Availability)
- 认证(Authentication)
- 不可抵赖性(Non-repudiation)
- 访问控制(Access Control)
- STRIDE 威胁建模
- Spoofing (欺骗)
- Tampering(篡改)
- Repudiation(否认)
- Information Disclosure(信息泄露)
- Denial of Service(服务拒绝)
- Elevation of Privilege(权限提升)
- Attack Tree
基础安全性质
保密性(Confidentiality)
保密性是指信息只被需要或有权查看它的人看到。 如果你的系统可以保持秘密信息的秘密性,那么它在保密性方面就做得很好。
完整性(Integrity)
完整性是指你存储的数据是正确的。完整性的关键在于,确保只有有权修改信息的人才能修改它。这是因为你可能担心攻击者会偷偷更改信息。(如果学生想偷偷在教务系统上修改成绩,那么就是在试图破坏 integrity)
可用性(Availability)
可用性是指一个系统始终可以被访问,并在用户请求时为其提供服务。 常见的攻击方法是拒绝服务攻击,阻止用户从他们应该能够使用的系统中获得服务。(洪水攻击等瘫痪服务器的方式,就破坏了系统的可用性)
认证(Authentication)
认证是 证明你是你所说的人。当你登录任何系统时,你需要提供你自己独有的账户和密码来证明你是你,常见的攻击包括允许未经证明身份的人访问系统,或通过暴力破解密码的方式攻击,一旦某些账号密码被泄露,那么当别人拿着我的密码冒充我的身份,authentication 就被破坏了
不可抵赖性(Non-repudiation)
不可抵赖性是一种比较少见的安全性质,它的含义是事情发生后,涉事者不能否认他们的行为。例如,如果一个人发送了一个消息,然后试图否认他发送了那个消息,不可抵赖性就会防止他这样做。
访问控制(Access Control)
明显的是,要在系统中执行某项操作,你需要有执行它的权限。你不能在系统中随意做你想做的事情。
STRIDE 威胁建模
当我设计我的安全系统时,我应该担心什么类型的威胁?
- 一种方法是去考虑这些不同的安全性质(
safety properties) 在何时不成立。因此,每个properties都给我们提供了一个类别的威胁 (threat),这些威胁是我们可能需要关心的。就像上一节的HAZOP中通过guide words来进行头脑风暴进而得出所有可能的hazards,每一个guide word都提供了一种系统地改变你的系统预期行为(intended behaviors)的方法。 - 类似的,在一个系统中,分别考虑这些
safety properties如何失败,或者攻击这些safety properties的方法,基本上就给你提供了一种 系统地枚举不同威胁的方法。这就是威胁建模方法,它是专门设计来帮助你进行 创造性的头脑风暴过程,考虑你的系统可能面临的不同类型的威胁或安全风险。

现在,我们深入了解 STRIDE,它是一种威胁模型,代表了:
- Spoofing (欺骗)
- Tampering (篡改)
- Repudiation (否认)
- Information Disclosure (信息泄露)
- Denial of Service (拒绝服务)
- Elevation of Privilege (提升权限)
- 每一个术语都代表了我们的系统可能面临的一种威胁或攻击。关键的是,这些术语也对应着安全性属性的潜在失败。让我们依次看看它们。
- STRIDE让人们 通过图形化的方式来理解系统的威胁模型,这种方法要求从系统的各个组件开始,然后考虑这些组件之间的连接。
信任边界:
- "Trust Boundary"这个概念主要在计算机安全和系统设计中使用。在任何系统中,都存在一些部分我们可以信任,也有一些部分我们无法或者不应该信任。一个"trust boundary"就是这两个区域的分界线。
- 一般来说,我们可以把一个系统分成许多不同的组件,每个组件有自己的责任和功能。 当我们说一个组件是"可信的",就是说我们相信这个组件能够按照我们的预期来执行它的职责,并且不会发生我们不希望发生的事情。而对于"不可信的"组件,我们就无法对它有这样的期待。
- 那么为什么我们需要"trust boundary"呢?主要是因为它有助于我们理解和管理系统的安全性。在设计和评估一个系统的时候,我们需要明确哪些部分是可以信任的,哪些部分是不能信任的,然后在这两个部分之间设置一个明确的"trust boundary"。这样做可以帮助我们更好地管理和控制系统的风险,因为 我们知道所有的风险都可能来自于"trust boundary"的另一边。
- 例如,让我们来看一个简单的网站系统。这个系统的一个组件是处理用户输入的模块。因为用户的输入是不可控制的,所以我们不能信任这个组件,因为用户可能会输入恶意的代码或者数据。所以我们就在用户输入模块和其它部分之间设置一个"trust boundary",并且确保所有来自用户的输入在通过这个"trust boundary"之前都要经过严格的检查和过滤。
总的来说,“trust boundary"是一种非常重要的系统设计和安全管理工具。通过明确地定义和管理"trust boundary”,我们可以更好地理解和控制系统的风险。
Spoofing (欺骗)
欺骗是指攻击者冒充另一个用户或系统的情况。这可能是简单地窃取某人的用户名和密码以获得他们的账户访问权限,也可以是建立一个与合法网站非常相似的网站,以欺骗用户交出他们的个人信息。
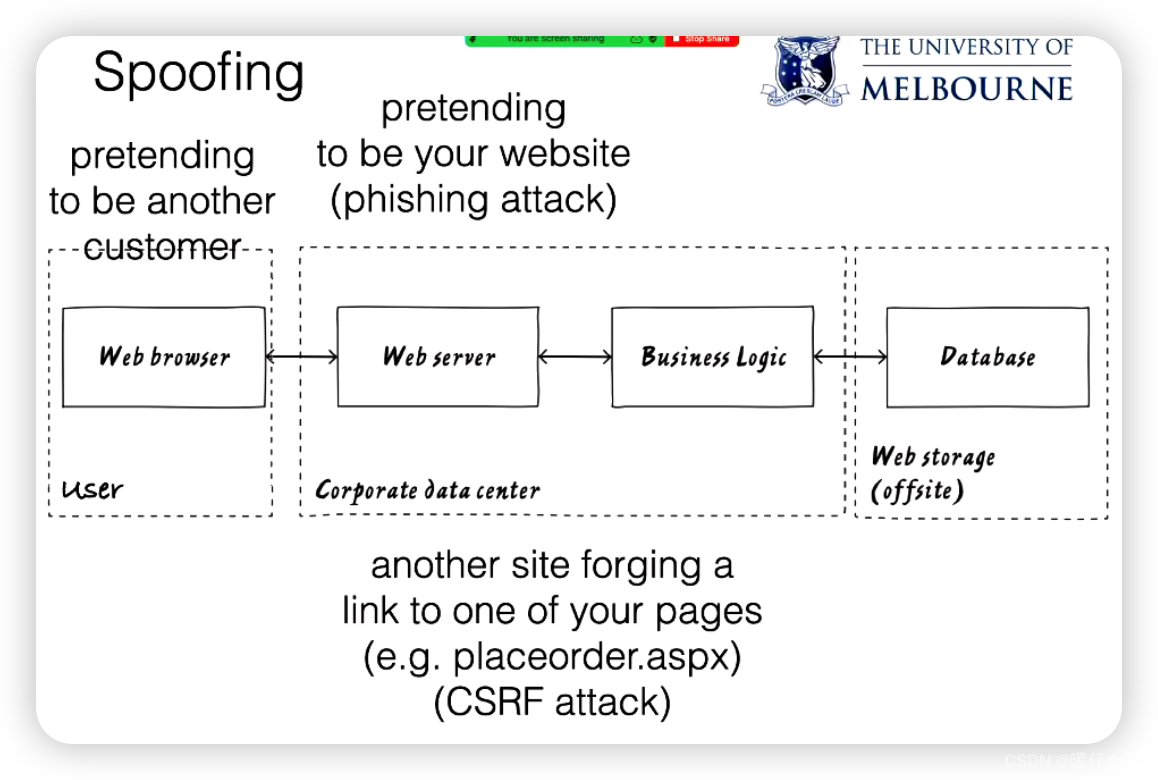
我们的系统可能面临的一些欺骗威胁包括:
- 攻击者冒充网页服务器 webserver,欺骗用户登录一个假网站并窃取他们的凭证(fishing)。
- 用户窃取另一个用户的密码并冒充他们的账户。
- 攻击者建立一个伪装成业务逻辑服务器的服务器,如果没有适当的认证措施,他们可以直接查询数据库。
Tampering(篡改)
篡改则是指未经授权更改数据或系统配置。 这可能涉及用户修改他们的账户信息以获得额外的权限,或者攻击者注入恶意代码到系统中,以破坏其操作。
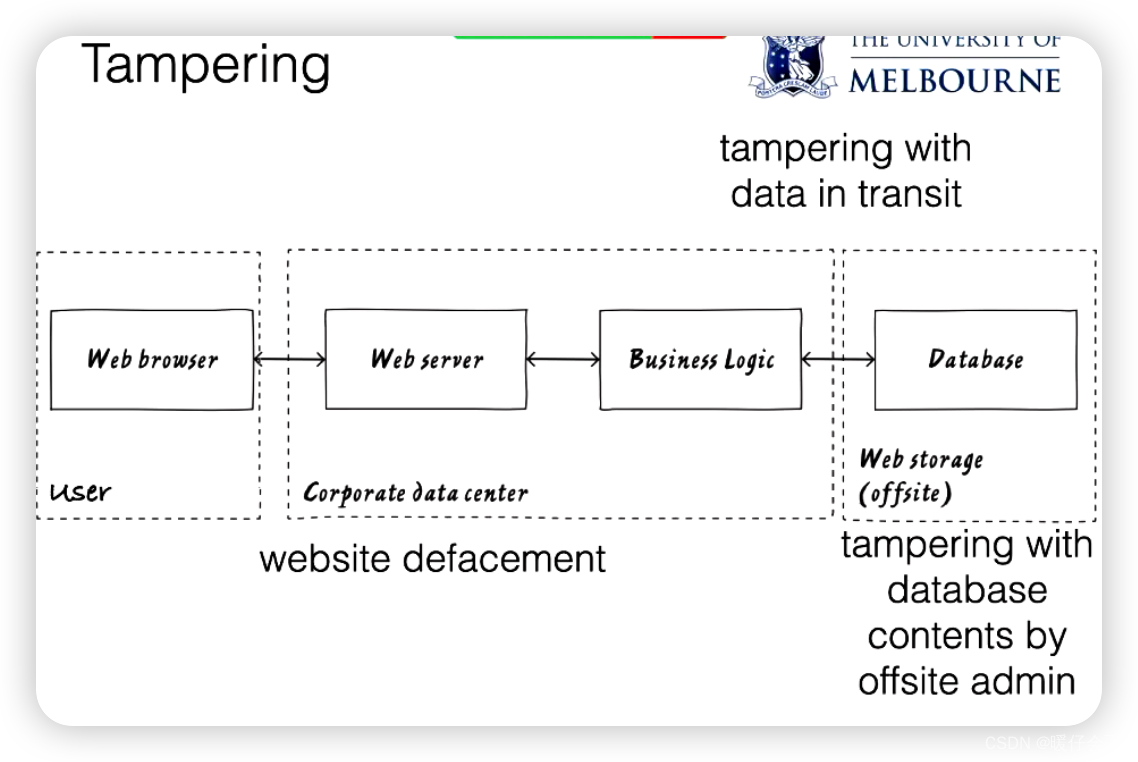
可能的篡改威胁可能包括:
-
攻击者利用糟糕的输入验证,为系统提供意想不到的或恶意的输入。
-
数据库篡改:数据库存储在不同的信任边界内,可能存在篡改的威胁。攻击者可能会获得后端数据库的权限,并且修改数据。例如,一个不满的管理员可能会决定删除数据库的内容,或者后端托管提供商可能遭受到勒索软件攻击,从而修改数据库。SQL注入攻击,攻击者通过操纵对数据库的查询,获得未授权的数据访问权限或破坏系统。
-
数据在传输中的篡改:数据在传输过程中可能会被篡改。攻击者可能会修改正在传输的数据,这是一种明显的篡改威胁。
-
网站篡改(defacement):虽然这种情况现在并不常见,但攻击者可能会利用Web服务器的漏洞来篡改网页内容。
-
日志篡改:日志记录是防止否认(repudiation)威胁的关键,因此它们的完整性很重要。攻击者可能会尝试篡改日志,以否认他们所做的事情。因此,需要确保日志无法被篡改。
Repudiation(否认)
一个用户执行了恶意行为,然后否认曾经执行过,例如,一个用户发送了恶意请求,然后否认曾经发送过。 如果系统没有足够的审计机制,那么这类问题就会很难解决。
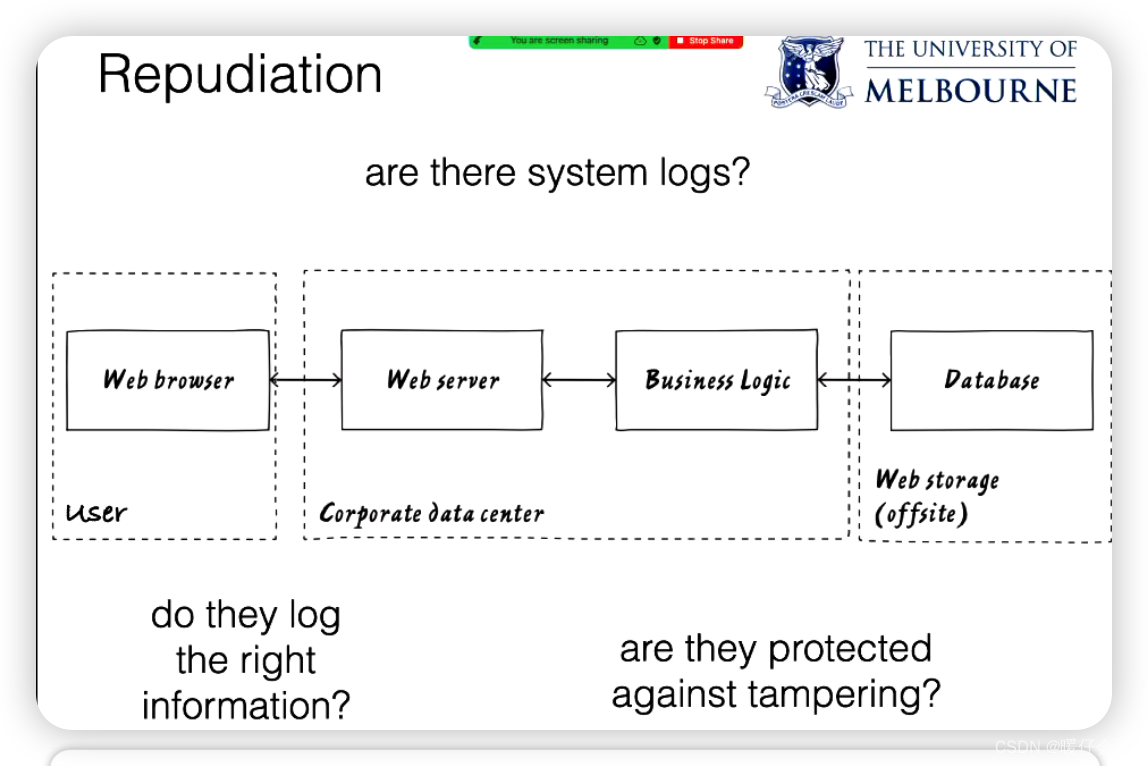
- 因此通过 log 来记录正确的用户操作是非常重要的
- 但日志文件同样有可能被篡改 (tampering)
Information Disclosure(信息泄露)
保密的数据被未经授权的人员获取,例如,通过窃听或者数据库的注入攻击。
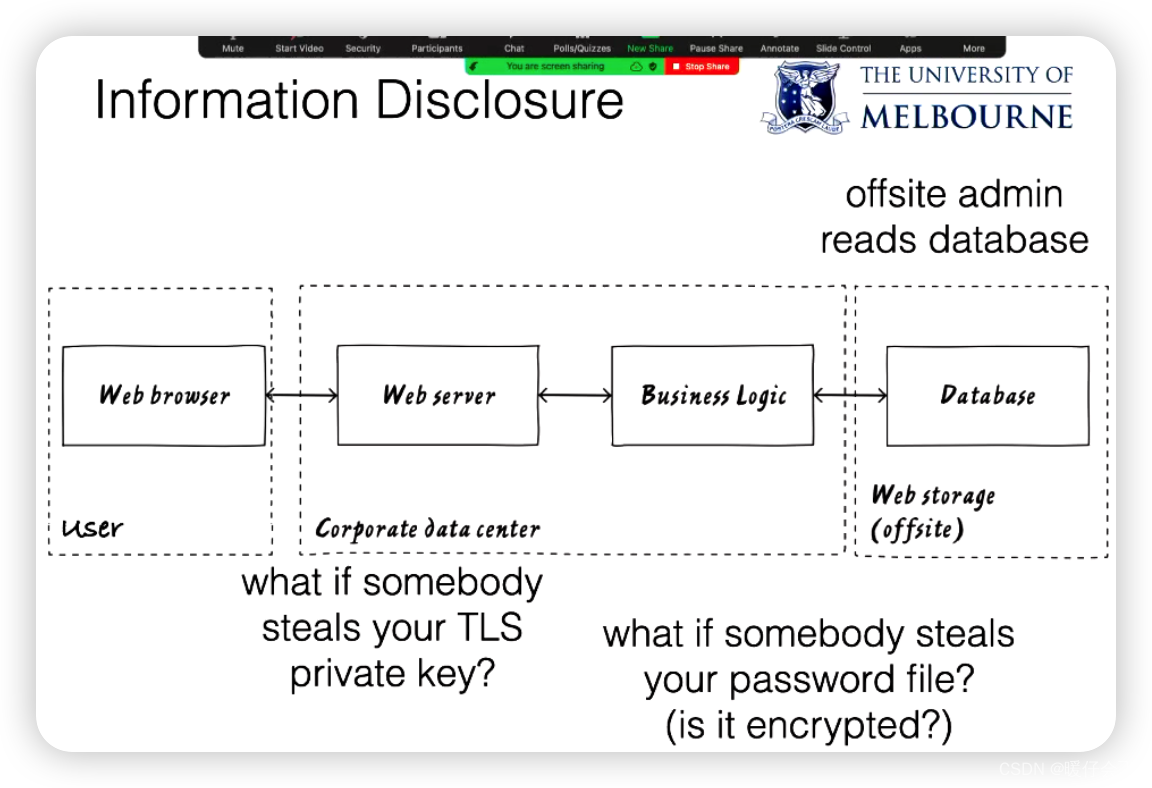
讲者提到了以下几种可能导致信息披露的攻击方式:
-
钓鱼攻击:这种攻击是一种欺诈行为,攻击者通常会通过伪装成可信任的实体来获取用户的敏感信息,例如密码。虽然这也可以被视为一种欺骗攻击,但它最终允许攻击者获取不应披露的信息,从而违反了身份验证。
-
SQL注入:这是一种攻击技术,攻击者试图通过插入恶意SQL代码来读取数据库中的信息。尽管这可能被视为一种篡改攻击,因为它是通过篡改Web服务器预期接收的正常请求内容来完成的,但它在本质上仍然是一种信息披露攻击。
-
TLS私钥盗窃:如果有人窃取了你的TLS私钥,他们就可以冒充Web服务器。虽然这看起来像是一种欺骗攻击,但实际上它可能导致攻击者获取其他敏感信息,因此,窃取服务的私钥实际上是一种信息披露攻击。
- 在互联网通信中,公钥和私钥是用于加密和解密数据的两个关键要素。公钥用于加密数据,私钥则用于解密数据。这两个钥匙构成了一对,通常称为密钥对。
- TLS (Transport Layer Security),是一个用于保护网络通信的协议。它通常用于确保网站和其用户之间的通信是安全的。在TLS中,服务器具有一个公钥和一个私钥。公钥是公开的,任何人都可以获得它,并使用它来加密他们发送到服务器的信息。而私钥是私有的,只有服务器知道它。服务器使用私钥来解密收到的加密信息。
- 当你访问一个使用TLS的网站时,你的浏览器会获取该网站的公钥并验证它的有效性。这通常是通过检查由受信任的证书颁发机构(CA)签发的数字证书来完成的。如果证书有效,浏览器就会用公钥加密它要发送的信息。
- 如果有人窃取了服务器的私钥,他们就可以冒充服务器。这是因为他们可以使用私钥解密发送到服务器的信息,并使用公钥加密他们发送出去的信息。这样,他们就可以阅读、修改、甚至冒充服务器发送的所有通信。这就是为什么保护私钥的安全是如此重要的原因。如果私钥被窃取,那么所有使用该密钥的通信都可能被攻击者读取或篡改。
-
管理员读取数据库:如果一个不值得信任的数据库管理员选择复制数据库的内容,而不是删除它,那么这就可能会成为一种信息披露攻击。
-
密码文件被窃取:如果某人窃取了你的密码文件,那么这也会是一种信息披露攻击。这种攻击中,攻击者可能获取系统中所有用户的密码。
Denial of Service(服务拒绝)
攻击者使系统无法对正常的请求做出响应,例如,通过发送大量的请求来使服务器崩溃。
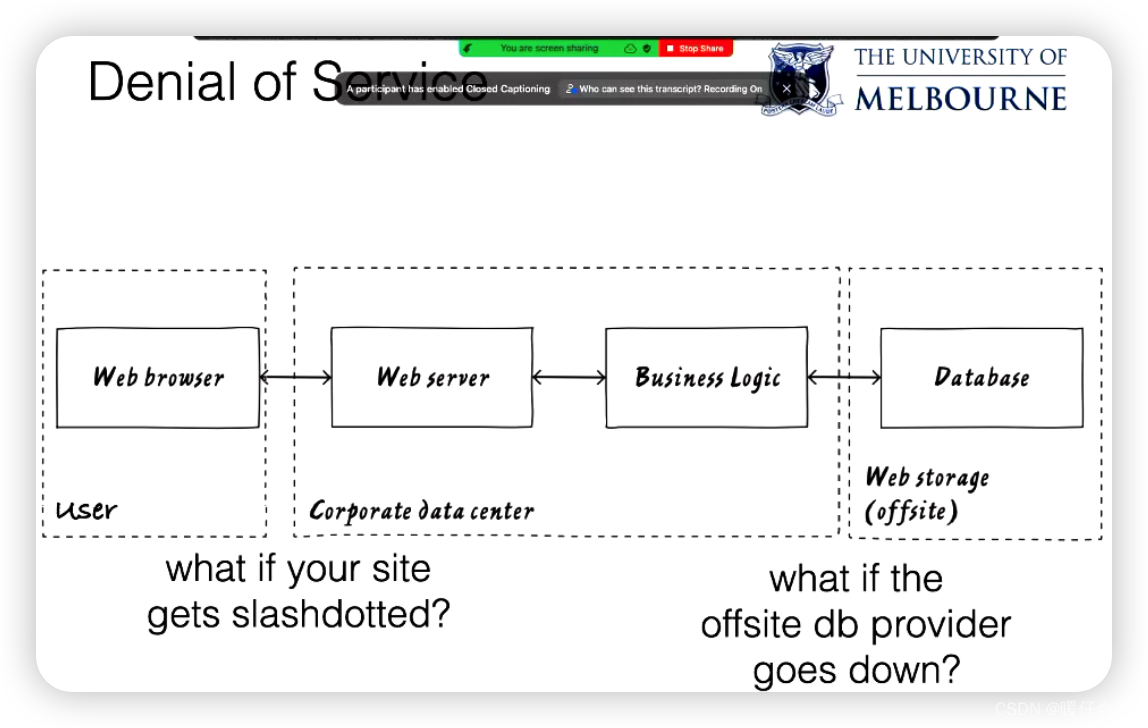
对于拒绝服务攻击(Denial of Service, DoS),主要讨论集中在以下几种可能的攻击类型:
-
数据库故障:数据库,无论是本地还是远程,都是Web应用程序的关键组成部分。如果数据库停止运行或变得不可访问,那么这将导致对Web应用程序的服务中断,构成了拒绝服务攻击。
-
分布式拒绝服务攻击(Distributed Denial of Service, DDoS):这是一种攻击方式,攻击者通过从不同的来源发起大量的请求来试图使一个网站或服务瘫痪。一种可能的情况是攻击者租用一群被危害的机器(称为僵尸网络),并指示这些机器同时访问目标网站,从而导致服务器过载无法处理合法用户的请求。
-
意外的流量浪潮:例如,如果网站被列入热门新闻聚合站点(如Hacker News或过去的Slashdot),那么可能会引发大量的流量涌入,使网站无法为所有访问者提供服务。这是一种更温和的拒绝服务情况,但其结果仍会导致合法用户无法访问网站。
-
数据库提供商停止运行:如果使用的是远程数据库,并且数据库提供商遇到问题导致服务中断,那么这也将阻止应用程序能够提供服务。
总的来说,拒绝服务攻击的目的是阻止合法用户访问和使用一个网络服务或应用程序。这些攻击可以以许多形式出现,并可能针对各种系统的各个部分,包括数据库、Web服务器等。
Elevation of Privilege(权限提升)
攻击者提升他们的权限,从而能够执行他们原本无法执行的操作,例如,通过利用系统的漏洞来获取管理员权限。
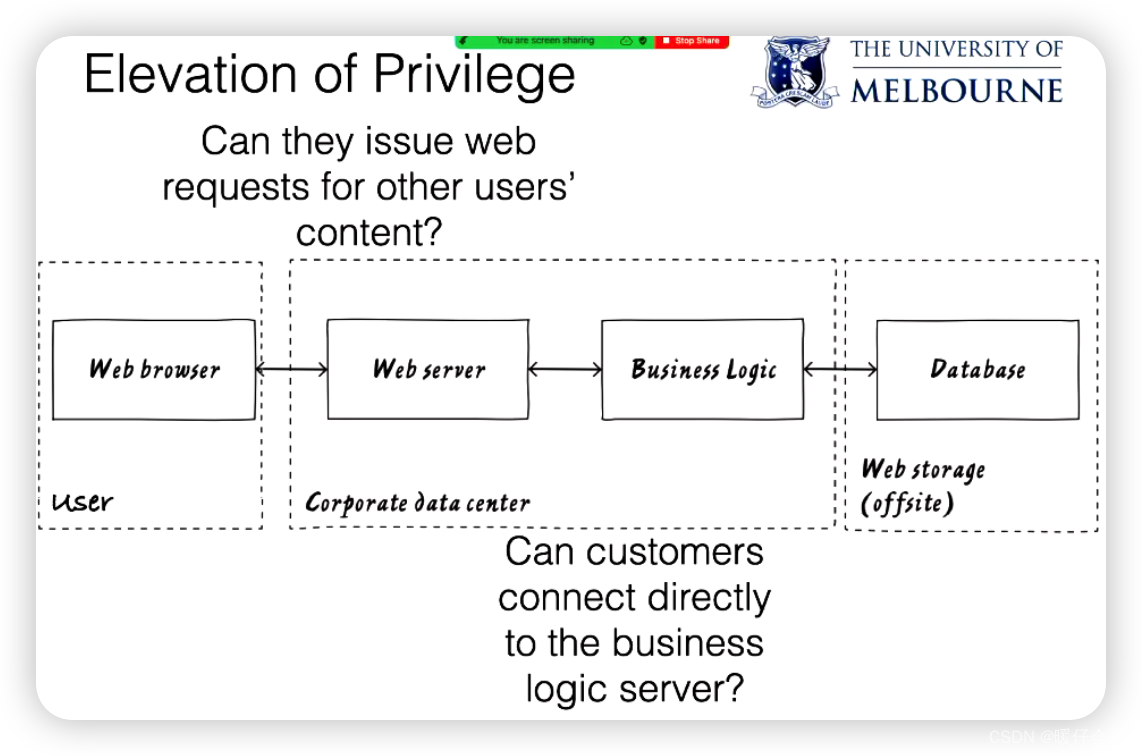
-
缓冲区溢出攻击:一个用户可能执行像缓冲区溢出这样的攻击来破坏程序(如Web服务器)的内存。例如,Web服务器可能在内存中有一个标志,表明当前登录用户是否为管理员。攻击者可以通过执行缓冲区溢出攻击或其他内存破坏攻击来覆盖该标志的内容,并使Web服务器误认为攻击者是管理员。这样的低级别攻击(如缓冲区溢出等)是进行权限升级的有效方法。
-
路径访问攻击:Web浏览器可能会以某种方式获得对应该仅管理员能访问的特定网站路径的访问权限。例如,如果Web服务器配置不当,攻击者可能通过输入特殊的URL来让网站访问服务器上不应该显示给用户的文件。这样可能使用户获得对他们不应该访问的内容的访问权,例如只有管理员应该能够访问的内容。
-
直接连接到业务逻辑服务器:虽然这个例子不如前两个强,但它提到了Web服务器可能存在一个漏洞,允许用户的Web浏览器直接与业务逻辑服务器进行通信,这在某种程度上也可视为权限提升。
-
请求其他用户的内容:例如,如果内容分发网络 (CDN)没有正确地将一个用户的内容与另一个用户的内容隔离开来,那么一个用户可能会访问到另一个用户的内容。尽管这个例子也可以被视为信息披露攻击,但其本质是一种权限提升攻击,因为用户能够访问他们本不应该能够访问的内容。
Attack Tree
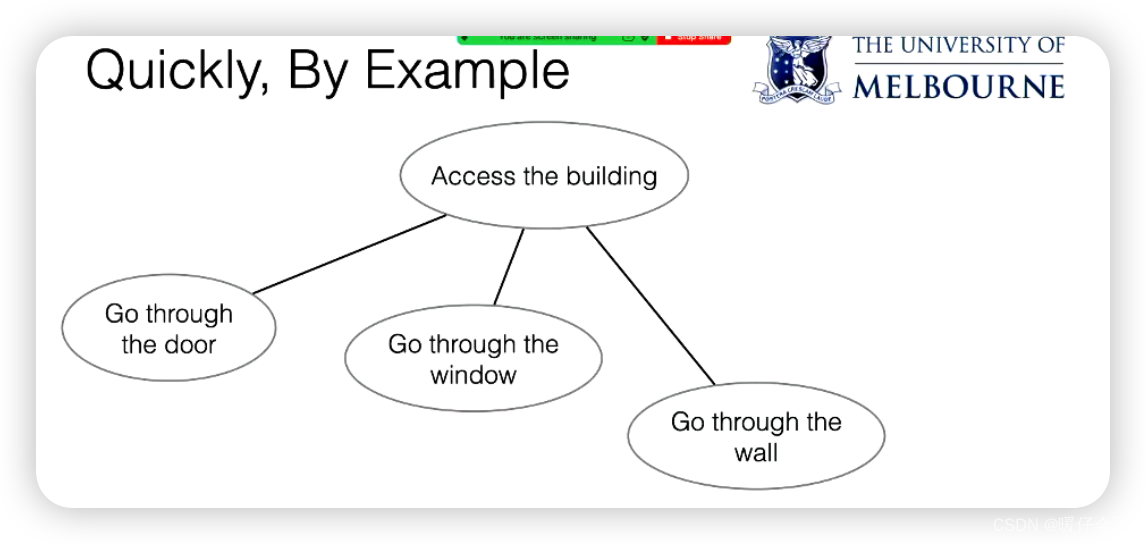
教授通过一个例子详细解释了攻击树(attack tree)的概念和构建方法。攻击树是一种安全工程工具,它将攻击(例如,黑客入侵)的各种可能途径可视化,从而帮助我们更好地理解和防御这些攻击。
-
之前学过 fault tree,fault tree是一个分析系统中可能的故障方式的图形工具,通常包含“与门”和“或门”。与门表示两个或两个以上的事件都需要发生才会导致最终的故障,而或门表示任一事件发生就会导致故障。然而,在这个讲座中,教授提到的 attack tree 仅使用了“或门”,这使得其比故障树简单。
-
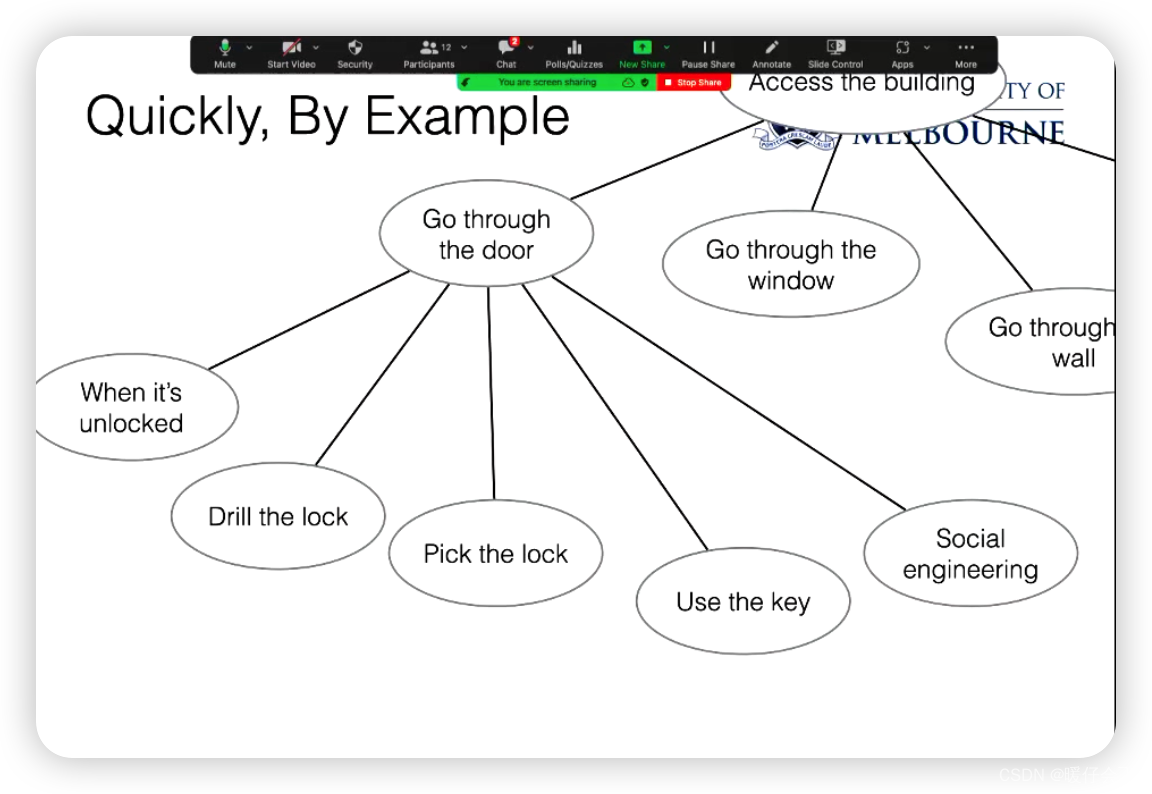
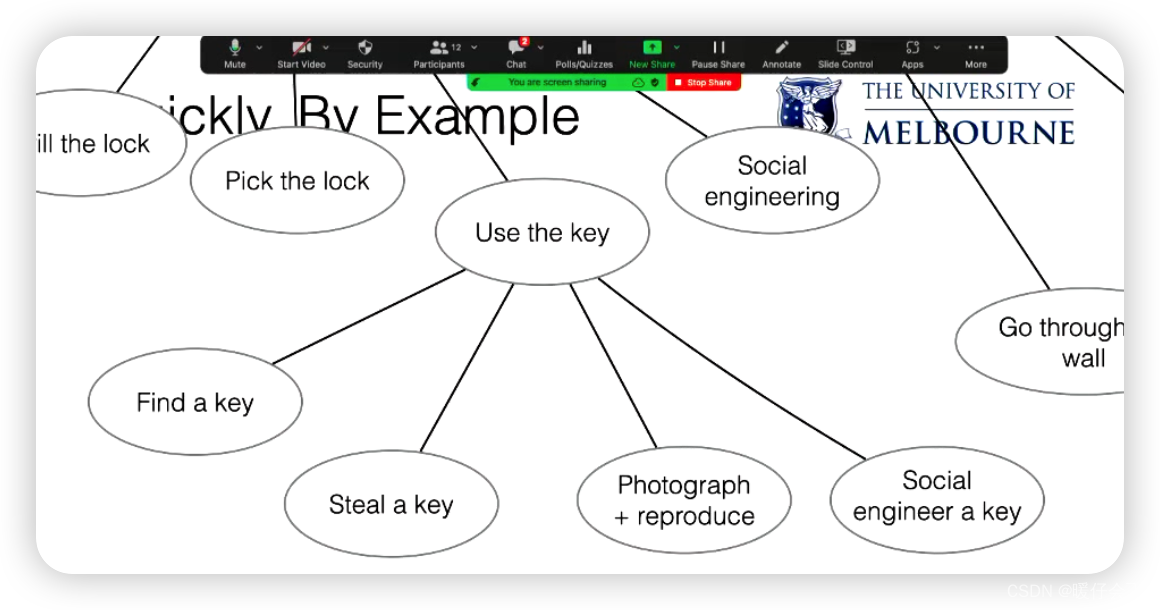
一个简单的物理安全例子(如何进入一栋大楼)来示范如何构建攻击树。从最初的攻击目标(进入大楼)开始,然后倒推回去,思考达成该目标所需的最直接的步骤或事件。这些可能包括通过门、窗或墙等进入。然后,再为这些事件中的一个(例如,通过门进入)制作更详细的攻击树,考虑可以通过哪些方式实现(例如,门未上锁、钻锁、撬锁、使用钥匙、社会工程等)。
-
讲解中也提到了社会工程攻击,这是一种通过欺骗别人来获取他们不应提供的信息的攻击方式。此外,教授还强调,分析的粒度取决于我们自己,最重要的是始终关注最直接的原因。
-
最后,虽然这次讲解的例子较为简单,但在处理更复杂的例子时,我们可能会需要像 fault tree 那样使用“与门”和“或门”,并考虑每种事件发生的概率,以更准确地估计攻击成功的整体概率。