动态内存分配
我们通常在C里面动态分配内存,会写出下面这样的代码:
struct header {
size_t len;
unsigned char *data;
};随后为data malloc一段内存出来,那么还有其他办法吗?
那便是弹性数组!在阐述本节之前,先了解一下这两种写法:
struct header {
size_t len;
unsigned char data[1];
};
struct header {
size_t len;
unsigned char data[];
};在实际项目中,会看到这两种写法,下面来重点聊聊它们吧。
方法1:
struct header {
size_t len;
unsigned char data[1];
};这种写法使用了一个长度为1的数组来表示数据部分。这是一种古老的技巧,通常称为"结构体尾部数组"或"伪动态数组"。在早期的C语言标准中,它被广泛用于实现变长结构体。在这种情况下,实际分配给结构体的内存会比sizeof(struct header)大,以容纳更多的数据。通过动态内存分配,可以为data成员分配更多的空间,并根据需要修改len字段的值。这样,结构体实际上可以扩展以容纳变长数据。
方法2:
struct header {
size_t len;
unsigned char data[];
};这种写法使用了一个长度为空的数组。这是C99标准中引入的"弹性数组成员"特性。与前一个例子相比,这种写法更加简洁和直观。它允许在结构体中声明一个可变长度的数组,而无需显式指定长度。使用这种灵活数组成员,可以根据需要为data成员动态分配内存,并根据len字段的值来管理数据的长度。
历史原因是,在早期的C语言标准中,动态分配内存的技术并不像现代的C语言那样成熟。因此,人们使用了一些技巧来实现变长数据的结构体。第一个结构体定义是其中一种技巧的结果。然而,随着C语言的发展和C99标准的引入,灵活数组成员提供了更加方便和安全的方式来处理变长数据。因此,第二个结构体定义更符合现代C语言的实践。
实际项目中的使用这几种方式都会涉及,例如:著名的postgresql数据库,分别使用如下:
1.使用data[1]方式
union pgresult_data
{
PGresult_data *next; /* link to next block, or NULL */
char space[1]; /* dummy for accessing block as bytes */
};2.使用data[]方式
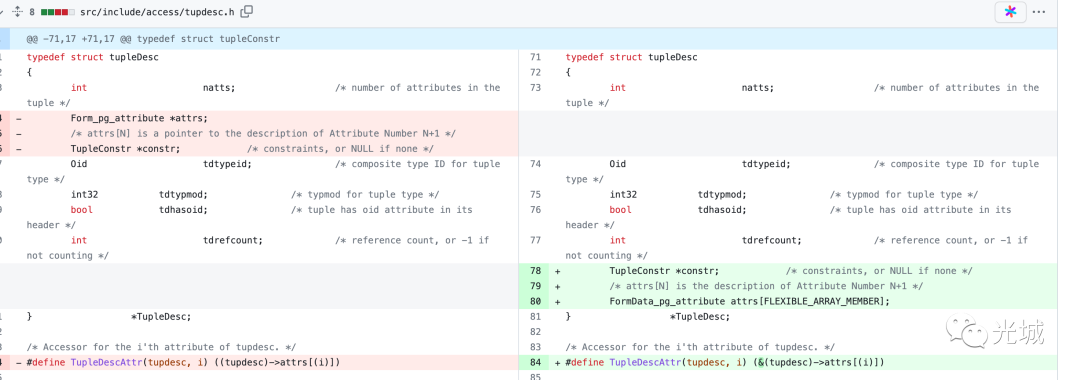
typedef struct TupleDescData
{
int natts; /* number of attributes in the tuple */
Oid tdtypeid; /* composite type ID for tuple type */
int32 tdtypmod; /* typmod for tuple type */
int tdrefcount; /* reference count, or -1 if not counting */
TupleConstr *constr; /* constraints, or NULL if none */
/* attrs[N] is the description of Attribute Number N+1 */
FormData_pg_attribute attrs[FLEXIBLE_ARRAY_MEMBER];
} TupleDescData;《C++那些事十日狂练》与《Mysql一周实战》持续更新中...

点击加入!