欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://blog.csdn.net/caroline_wendy/article/details/131102145

在强化学习中,状态价值 (State Value) 是指在特定状态下,智能体能够从该状态开始执行一系列动作,并且按照某个策略进行决策,所能获得的期望累积回报。状态价值函数用于衡量状态的好坏程度,指导智能体在不同状态下,选择最优的行动。
蒙特卡洛方法是一种基于随机采样和统计的强化学习方法,用于估计值函数或优化策略,得名于摩纳哥的蒙特卡洛赌场,因为这种方法使用了大量的随机模拟。在蒙特卡洛方法中,智能体通过与环境的交互来学习,其基本思想是通过多次采样来估计状态或动作的值函数,并根据估计的值函数进行策略改进。蒙特卡洛方法不需要对环境模型进行假设,只需通过与环境的交互来获得样本。
使用蒙特卡洛方法计算状态价值的具体过程,如下:
- 使用策略 π \pi π 采样若干条序列。
- 对每一条序列中,每一时间步 t t t 的状态 s s s ,更新计数器 N ( s ) ← N ( s ) + 1 N(s) \leftarrow N(s)+1 N(s)←N(s)+1,更新总回报 M ( s ) ← M ( s ) + G t M(s) \leftarrow M(s)+G_{t} M(s)←M(s)+Gt。
- 每一个状态的价值被估计为回报的平均值, V ( s ) = M ( s ) N ( s ) V(s)=\frac{M(s)}{N(s)} V(s)=N(s)M(s)
也可以使用增量更新,即
G
←
r
+
γ
∗
G
V
(
s
)
←
V
(
s
)
+
1
N
(
s
)
(
G
−
V
(
s
)
)
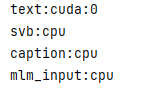
G \leftarrow r + \gamma*G \\ V(s) \leftarrow V(s) +\frac{1}{N(s)}(G-V(s))
G←r+γ∗GV(s)←V(s)+N(s)1(G−V(s))
序列的单个步骤是(s,a,r,s_next),即从状态s中,(随机)选择a,(s,a)的奖励是r,(随机)跳转至s_next。
蒙特卡洛方法的采样源码:
# 把输入的两个字符串通过“-”连接,便于使用上述定义的P、R变量
def join(str1, str2):
return str1 + '-' + str2
def sample(MDP, Pi, timestep_max, number):
"""
采样函数
:param MDP: MDP的元组
:param Pi: 策略
:param timestep_max: 最长时间步
:param number: 采样的序列数
:return: 全部采样
"""
S, A, P, R, gamma = MDP
episodes = []
for _ in range(number):
episode = []
timestep = 0
s = S[np.random.randint(4)] # 随机选择一个除s5以外的状态s作为起点
# 当前状态为终止状态或者时间步太长时,一次采样结束
while s != "s5" and timestep <= timestep_max:
timestep += 1
rand, temp = np.random.rand(), 0
# 在状态s下根据策略选择动作
for a_opt in A:
temp += Pi.get(join(s, a_opt), 0) # 概率逐渐累加至1
if temp > rand: # 最终一定会选择某个动作 a_opt
a = a_opt
r = R.get(join(s, a), 0)
break
rand, temp = np.random.rand(), 0
# 根据状态转移概率得到下一个状态s_next
for s_opt in S:
temp += P.get(join(join(s, a), s_opt), 0)
if temp > rand: # 概率逐渐累加至1
s_next = s_opt # 最终一定会跳转至下个状态s_opt
break
episode.append((s, a, r, s_next)) # 把(s,a,r,s_next)元组放入序列中
s = s_next # s_next变成当前状态,开始接下来的循环
episodes.append(episode)
return episodes
计算状态价值的源码:
# 对所有采样序列计算所有状态的价值,不断更新V[s]
def MC(episodes, V, N, gamma):
for episode in episodes:
G = 0
for i in range(len(episode) - 1, -1, -1): #一个序列从后往前计算
(s, a, r, s_next) = episode[i]
G = r + gamma * G
N[s] = N[s] + 1
V[s] = V[s] + (G - V[s]) / N[s]
测试输出:
def main():
np.random.seed(0)
S = ["s1", "s2", "s3", "s4", "s5"] # 状态集合
A = ["保持s1", "前往s1", "前往s2", "前往s3", "前往s4", "前往s5", "概率前往"] # 动作集合
# 状态转移函数
P = {
"s1-保持s1-s1": 1.0,
"s1-前往s2-s2": 1.0,
"s2-前往s1-s1": 1.0,
"s2-前往s3-s3": 1.0,
"s3-前往s4-s4": 1.0,
"s3-前往s5-s5": 1.0,
"s4-前往s5-s5": 1.0,
"s4-概率前往-s2": 0.2,
"s4-概率前往-s3": 0.4,
"s4-概率前往-s4": 0.4,
}
# 奖励函数
R = {
"s1-保持s1": -1,
"s1-前往s2": 0,
"s2-前往s1": -1,
"s2-前往s3": -2,
"s3-前往s4": -2,
"s3-前往s5": 0,
"s4-前往s5": 10,
"s4-概率前往": 1,
}
gamma = 0.5 # 折扣因子
MDP = (S, A, P, R, gamma)
# 策略1,随机策略
Pi_1 = {
"s1-保持s1": 0.5,
"s1-前往s2": 0.5,
"s2-前往s1": 0.5,
"s2-前往s3": 0.5,
"s3-前往s4": 0.5,
"s3-前往s5": 0.5,
"s4-前往s5": 0.5,
"s4-概率前往": 0.5,
}
# 采样5次,每个序列最长不超过20步
episodes = sample(MDP, Pi_1, 20, 5)
print('第一条序列\n', episodes[0])
print('第二条序列\n', episodes[1])
print('第五条序列\n', episodes[4])
timestep_max = 20
# 采样1000次,可以自行修改
episodes = sample(MDP, Pi_1, timestep_max, 1000)
gamma = 0.5
V = {"s1": 0, "s2": 0, "s3": 0, "s4": 0, "s5": 0}
N = {"s1": 0, "s2": 0, "s3": 0, "s4": 0, "s5": 0}
MC(episodes, V, N, gamma)
print("使用蒙特卡洛方法计算MDP的状态价值为\n", V)
if __name__ == '__main__':
main()
输出结果:
# 使用蒙特卡洛方法计算MDP的状态价值
{'s1': -1.228923788722258, 's2': -1.6955696284402704, 's3': 0.4823809701532294, 's4': 5.967514743019431, 's5': 0}
# 通过MRP计算的状态价值
[[-1.22555411] [-1.67666232] [ 0.51890482] [ 6.0756193 ] [ 0. ]]
状态价值,可以用于计算状态动作价值,具有指导意义。