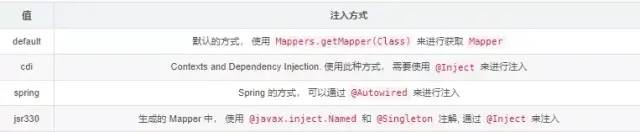
需求
自动识别法院和公积金中心的文书(调解书、判决书、裁定书、通知书)扫描件(PDF或图片),获取特定结构的数据,自动对比。抽取结构如:
['标题','诉讼案号','执行案号','公积金',{'原告': ['姓名', '单位', '生日', '身份证号']},{'被告': ['姓名', '单位', '生日', '身份证号']}]
思路
# 1.遍历目录获取源文件名; # 2.统一格式,PDF转JPG。自动识别图片方向,把图片转正; # 3.排序并获取整篇结构化内容,写TXT文件输出; # 4.导入 Label Studio 标记; # 5.导出 JSON 格式标记样本; # 6.将 label studio 导出的 JSON 数据文件格式转换成 doccano 导出的数据文件格式; # 7.构造网络训练; # 8.部署模型预测。
环境
Ubuntu 22.04 Anaconda PaddlePaddle Label Studio
步骤
预处理依赖
import os
from pdf2image import convert_from_path
from paddleclas import PaddleClas
from PIL import Image
import numpy as np
from paddleocr import PaddleOCR加载OCR模型
clas_engine = PaddleClas(model_name="text_image_orientation", use_gpu=False)
# 加载OCR模型
ocr = PaddleOCR(ocr_version='PP-OCRv3')遍历文件
def get_file_names(directory):
file_names = []
for root, dirs, files in os.walk(directory):
for file in files:
file_names.append(os.path.join(root, file))
return file_names获取文件后缀名
def get_file_extension(file_name):
_, extension = os.path.splitext(file_name)
return extensionpdf转jpg
def pdf_to_jpg(pdf_path, output_folder):
images = convert_from_path(pdf_path)
file_names = []
for i, image in enumerate(images):
str = f"{output_folder}/page_{i+1}.jpg"
image.save(str, "JPEG")
file_names.append(str)
return file_names自动创建目录
def create_directory(directory):
if not os.path.exists(directory):
os.makedirs(directory)
print(f"目录 '{directory}' 创建成功")
else:
print(f"目录 '{directory}' 已存在")识别图片方向
def model_inference_direction(image) -> tuple:
results = clas_engine.predict(image, print_pred=True)
try:
# 可能有无结果的,直接取值会报错,try忽略掉
results = list(results)[0][0]
results = int(results["label_names"][0])
except Exception as e:
print("An error occurred:", str(e))
return results识别文本
def ocr_gettext(image):
results = ocr.ocr(image)
text = ""
for result in results:
for res in result:
# print(res[1][0])
text = text + res[1][0]
return text执行
# 指定目录路径
directory_path = "D:/jerry/code/python/rap/dataset/test/"
# 获取目录及其子目录下的文件名
file_names = get_file_names(directory_path)
for file_name in file_names:
suffix_name = get_file_extension(file_name)
# 忽略大小写对比
if suffix_name.lower() == '.pdf'.lower():
# 调用函数进行转换
jpg_output = file_name.replace(".pdf","")
create_directory(jpg_output)
fnames = pdf_to_jpg(file_name, jpg_output)
file_names.extend(fnames)
elif suffix_name.lower() == '.txt'.lower():
os.remove(file_name)
file_names.remove(file_name)
else:
image = Image.open(file_name)
# 可能有4分量的,强制转为3分量
image = image.convert("RGB")
# 自动识别图片旋转角度(顺90 识别不准)
angle = model_inference_direction(np.asarray(image))
# 识别出参: 正角度为顺时针旋转
# 执行入参:正角度为逆时针旋转
image = image.rotate(angle)
# image.show()
text = ocr_gettext(np.asarray(image))
text_out = file_name.replace(suffix_name, ".txt")
with open(text_out, "w", encoding="utf-8") as file:
file.write(text)搭建label studio标记,标记完成后导出JSON。

Label Studio JSON转Doccano JSON
# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import os
import json
def append_attrs(data, item, label_id, relation_id):
mapp = {}
for anno in data["annotations"][0]["result"]:
if anno["type"] == "labels":
label_id += 1
item["entities"].append(
{
"id": label_id,
"label": anno["value"]["labels"][0],
"start_offset": anno["value"]["start"],
"end_offset": anno["value"]["end"],
}
)
mapp[anno["id"]] = label_id
for anno in data["annotations"][0]["result"]:
if anno["type"] == "relation":
relation_id += 1
item["relations"].append(
{
"id": relation_id,
"from_id": mapp[anno["from_id"]],
"to_id": mapp[anno["to_id"]],
"type": anno["labels"][0],
}
)
return item, label_id, relation_id
def convert(dataset):
results = []
outer_id = 0
label_id = 0
relation_id = 0
for data in dataset:
labels = data["annotations"][0]["result"]
outer_id += 1
item = {"id": outer_id, "text": data["data"]["value"], "entities": [], "relations": []}
item, label_id, relation_id = append_attrs(data, item, label_id, relation_id)
results.append(item)
return results
def do_convert(labelstudio_file, doccano_file):
with open(labelstudio_file, "r", encoding="utf-8") as infile:
for content in infile:
dataset = json.loads(content)
results = convert(dataset)
print(results)
with open(doccano_file, "w", encoding="utf-8") as outfile:
for item in results:
outline = json.dumps(item, ensure_ascii=False)
outfile.write(outline + "\n")
labelstudio_file = "data/project-11-at-2023-06-07-08-12-d7affacb.json"
doccano_file = "data/doccano_ext.json"
do_convert(labelstudio_file, doccano_file)
python3 ./labelstudio2doccano.py构造数据集
# coding=utf-8
# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import json
import os
import time
from decimal import Decimal
import numpy as np
from utils import convert_cls_examples, convert_ext_examples, set_seed
from paddlenlp.trainer.argparser import strtobool
from paddlenlp.utils.log import logger
def do_convert():
set_seed(args.seed)
tic_time = time.time()
if not os.path.exists(args.doccano_file):
raise ValueError("Please input the correct path of doccano file.")
if not os.path.exists(args.save_dir):
os.makedirs(args.save_dir)
if len(args.splits) != 0 and len(args.splits) != 3:
raise ValueError("Only []/ len(splits)==3 accepted for splits.")
def _check_sum(splits):
return Decimal(str(splits[0])) + Decimal(str(splits[1])) + Decimal(str(splits[2])) == Decimal("1")
if len(args.splits) == 3 and not _check_sum(args.splits):
raise ValueError("Please set correct splits, sum of elements in splits should be equal to 1.")
with open(args.doccano_file, "r", encoding="utf-8") as f:
raw_examples = f.readlines()
def _create_ext_examples(
examples,
negative_ratio,
prompt_prefix="情感倾向",
options=["正向", "负向"],
separator="##",
shuffle=False,
is_train=True,
schema_lang="ch",
):
entities, relations, aspects = convert_ext_examples(
examples, negative_ratio, prompt_prefix, options, separator, is_train, schema_lang
)
examples = entities + relations + aspects
if shuffle:
indexes = np.random.permutation(len(examples))
examples = [examples[i] for i in indexes]
return examples
def _create_cls_examples(examples, prompt_prefix, options, shuffle=False):
examples = convert_cls_examples(examples, prompt_prefix, options)
if shuffle:
indexes = np.random.permutation(len(examples))
examples = [examples[i] for i in indexes]
return examples
def _save_examples(save_dir, file_name, examples):
count = 0
save_path = os.path.join(save_dir, file_name)
with open(save_path, "w", encoding="utf-8") as f:
for example in examples:
f.write(json.dumps(example, ensure_ascii=False) + "\n")
count += 1
logger.info("Save %d examples to %s." % (count, save_path))
if len(args.splits) == 0:
if args.task_type == "ext":
examples = _create_ext_examples(
raw_examples,
args.negative_ratio,
args.prompt_prefix,
args.options,
args.separator,
args.is_shuffle,
schema_lang=args.schema_lang,
)
else:
examples = _create_cls_examples(raw_examples, args.prompt_prefix, args.options, args.is_shuffle)
_save_examples(args.save_dir, "train.txt", examples)
else:
if args.is_shuffle:
indexes = np.random.permutation(len(raw_examples))
index_list = indexes.tolist()
raw_examples = [raw_examples[i] for i in indexes]
else:
index_list = list(range(len(raw_examples)))
i1, i2, _ = args.splits
p1 = int(len(raw_examples) * i1)
p2 = int(len(raw_examples) * (i1 + i2))
train_ids = index_list[:p1]
dev_ids = index_list[p1:p2]
test_ids = index_list[p2:]
with open(os.path.join(args.save_dir, "sample_index.json"), "w") as fp:
maps = {"train_ids": train_ids, "dev_ids": dev_ids, "test_ids": test_ids}
fp.write(json.dumps(maps))
if args.task_type == "ext":
train_examples = _create_ext_examples(
raw_examples[:p1],
args.negative_ratio,
args.prompt_prefix,
args.options,
args.separator,
args.is_shuffle,
schema_lang=args.schema_lang,
)
dev_examples = _create_ext_examples(
raw_examples[p1:p2],
-1,
args.prompt_prefix,
args.options,
args.separator,
is_train=False,
schema_lang=args.schema_lang,
)
test_examples = _create_ext_examples(
raw_examples[p2:],
-1,
args.prompt_prefix,
args.options,
args.separator,
is_train=False,
schema_lang=args.schema_lang,
)
else:
train_examples = _create_cls_examples(raw_examples[:p1], args.prompt_prefix, args.options)
dev_examples = _create_cls_examples(raw_examples[p1:p2], args.prompt_prefix, args.options)
test_examples = _create_cls_examples(raw_examples[p2:], args.prompt_prefix, args.options)
_save_examples(args.save_dir, "train.txt", train_examples)
_save_examples(args.save_dir, "dev.txt", dev_examples)
_save_examples(args.save_dir, "test.txt", test_examples)
logger.info("Finished! It takes %.2f seconds" % (time.time() - tic_time))
if __name__ == "__main__":
# yapf: disable
parser = argparse.ArgumentParser()
parser.add_argument("--doccano_file", default="./data/doccano_ext.json", type=str, help="The doccano file exported from doccano platform.")
parser.add_argument("--save_dir", default="./data", type=str, help="The path of data that you wanna save.")
parser.add_argument("--negative_ratio", default=5, type=int, help="Used only for the extraction task, the ratio of positive and negative samples, number of negtive samples = negative_ratio * number of positive samples")
parser.add_argument("--splits", default=[0.8, 0.1, 0.1], type=float, nargs="*", help="The ratio of samples in datasets. [0.6, 0.2, 0.2] means 60% samples used for training, 20% for evaluation and 20% for test.")
parser.add_argument("--task_type", choices=['ext', 'cls'], default="ext", type=str, help="Select task type, ext for the extraction task and cls for the classification task, defaults to ext.")
parser.add_argument("--options", default=["正向", "负向"], type=str, nargs="+", help="Used only for the classification task, the options for classification")
parser.add_argument("--prompt_prefix", default="情感倾向", type=str, help="Used only for the classification task, the prompt prefix for classification")
parser.add_argument("--is_shuffle", default="True", type=strtobool, help="Whether to shuffle the labeled dataset, defaults to True.")
parser.add_argument("--seed", type=int, default=1000, help="Random seed for initialization")
parser.add_argument("--separator", type=str, default='##', help="Used only for entity/aspect-level classification task, separator for entity label and classification label")
parser.add_argument("--schema_lang", choices=["ch", "en"], default="ch", help="Select the language type for schema.")
args = parser.parse_args()
# yapf: enable
do_convert()python3 doccano.py --doccano_file ./data/doccano_ext.json --task_type ext --save_dir ./data --splits 0.8 0.2 0 --schema_lang ch
训练
# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
from dataclasses import dataclass, field
from functools import partial
from typing import List, Optional
import paddle
from utils import convert_example, reader
from paddlenlp.data import DataCollatorWithPadding
from paddlenlp.datasets import load_dataset
from paddlenlp.metrics import SpanEvaluator
from paddlenlp.trainer import (
CompressionArguments,
PdArgumentParser,
Trainer,
get_last_checkpoint,
)
from paddlenlp.transformers import UIE, UIEM, AutoTokenizer, export_model
from paddlenlp.utils.log import logger
@dataclass
class DataArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
Using `PdArgumentParser` we can turn this class into argparse arguments to be able to
specify them on the command line.
"""
train_path: str = field(
default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
)
dev_path: str = field(
default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
)
max_seq_length: Optional[int] = field(
default=512,
metadata={
"help": "The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
},
)
dynamic_max_length: Optional[List[int]] = field(
default=None,
metadata={"help": "dynamic max length from batch, it can be array of length, eg: 16 32 64 128"},
)
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
"""
model_name_or_path: Optional[str] = field(
default="uie-base",
metadata={
"help": "Path to pretrained model, such as 'uie-base', 'uie-tiny', "
"'uie-medium', 'uie-mini', 'uie-micro', 'uie-nano', 'uie-base-en', "
"'uie-m-base', 'uie-m-large', or finetuned model path."
},
)
export_model_dir: Optional[str] = field(
default=None,
metadata={"help": "Path to directory to store the exported inference model."},
)
multilingual: bool = field(default=False, metadata={"help": "Whether the model is a multilingual model."})
def main():
parser = PdArgumentParser((ModelArguments, DataArguments, CompressionArguments))
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
if model_args.model_name_or_path in ["uie-m-base", "uie-m-large"]:
model_args.multilingual = True
# Log model and data config
training_args.print_config(model_args, "Model")
training_args.print_config(data_args, "Data")
paddle.set_device(training_args.device)
# Log on each process the small summary:
logger.warning(
f"Process rank: {training_args.local_rank}, device: {training_args.device}, world_size: {training_args.world_size}, "
+ f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
)
# Detecting last checkpoint.
last_checkpoint = None
if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
last_checkpoint = get_last_checkpoint(training_args.output_dir)
if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
raise ValueError(
f"Output directory ({training_args.output_dir}) already exists and is not empty. "
"Use --overwrite_output_dir to overcome."
)
elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
logger.info(
f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
"the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
)
tokenizer = AutoTokenizer.from_pretrained(model_args.model_name_or_path)
if model_args.multilingual:
model = UIEM.from_pretrained(model_args.model_name_or_path)
else:
model = UIE.from_pretrained(model_args.model_name_or_path)
train_ds = load_dataset(reader, data_path=data_args.train_path, max_seq_len=data_args.max_seq_length, lazy=False)
dev_ds = load_dataset(reader, data_path=data_args.dev_path, max_seq_len=data_args.max_seq_length, lazy=False)
trans_fn = partial(
convert_example,
tokenizer=tokenizer,
max_seq_len=data_args.max_seq_length,
multilingual=model_args.multilingual,
dynamic_max_length=data_args.dynamic_max_length,
)
train_ds = train_ds.map(trans_fn)
dev_ds = dev_ds.map(trans_fn)
if training_args.device == "npu":
data_collator = DataCollatorWithPadding(tokenizer, padding="longest")
else:
data_collator = DataCollatorWithPadding(tokenizer)
criterion = paddle.nn.BCELoss()
def uie_loss_func(outputs, labels):
start_ids, end_ids = labels
start_prob, end_prob = outputs
start_ids = paddle.cast(start_ids, "float32")
end_ids = paddle.cast(end_ids, "float32")
loss_start = criterion(start_prob, start_ids)
loss_end = criterion(end_prob, end_ids)
loss = (loss_start + loss_end) / 2.0
return loss
def compute_metrics(p):
metric = SpanEvaluator()
start_prob, end_prob = p.predictions
start_ids, end_ids = p.label_ids
metric.reset()
num_correct, num_infer, num_label = metric.compute(start_prob, end_prob, start_ids, end_ids)
metric.update(num_correct, num_infer, num_label)
precision, recall, f1 = metric.accumulate()
metric.reset()
return {"precision": precision, "recall": recall, "f1": f1}
trainer = Trainer(
model=model,
criterion=uie_loss_func,
args=training_args,
data_collator=data_collator,
train_dataset=train_ds if training_args.do_train or training_args.do_compress else None,
eval_dataset=dev_ds if training_args.do_eval or training_args.do_compress else None,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
trainer.optimizer = paddle.optimizer.AdamW(
learning_rate=training_args.learning_rate, parameters=model.parameters()
)
checkpoint = None
if training_args.resume_from_checkpoint is not None:
checkpoint = training_args.resume_from_checkpoint
elif last_checkpoint is not None:
checkpoint = last_checkpoint
# Training
if training_args.do_train:
train_result = trainer.train(resume_from_checkpoint=checkpoint)
metrics = train_result.metrics
trainer.save_model()
trainer.log_metrics("train", metrics)
trainer.save_metrics("train", metrics)
trainer.save_state()
# Evaluate and tests model
if training_args.do_eval:
eval_metrics = trainer.evaluate()
trainer.log_metrics("eval", eval_metrics)
# export inference model
if training_args.do_export:
# You can also load from certain checkpoint
# trainer.load_state_dict_from_checkpoint("/path/to/checkpoint/")
if training_args.device == "npu":
# npu will transform int64 to int32 for internal calculation.
# To reduce useless transformation, we feed int32 inputs.
input_spec_dtype = "int32"
else:
input_spec_dtype = "int64"
if model_args.multilingual:
input_spec = [
paddle.static.InputSpec(shape=[None, None], dtype=input_spec_dtype, name="input_ids"),
paddle.static.InputSpec(shape=[None, None], dtype=input_spec_dtype, name="position_ids"),
]
else:
input_spec = [
paddle.static.InputSpec(shape=[None, None], dtype=input_spec_dtype, name="input_ids"),
paddle.static.InputSpec(shape=[None, None], dtype=input_spec_dtype, name="token_type_ids"),
paddle.static.InputSpec(shape=[None, None], dtype=input_spec_dtype, name="position_ids"),
paddle.static.InputSpec(shape=[None, None], dtype=input_spec_dtype, name="attention_mask"),
]
if model_args.export_model_dir is None:
model_args.export_model_dir = os.path.join(training_args.output_dir, "export")
export_model(model=trainer.model, input_spec=input_spec, path=model_args.export_model_dir)
trainer.tokenizer.save_pretrained(model_args.export_model_dir)
if training_args.do_compress:
@paddle.no_grad()
def custom_evaluate(self, model, data_loader):
metric = SpanEvaluator()
model.eval()
metric.reset()
for batch in data_loader:
if model_args.multilingual:
logits = model(input_ids=batch["input_ids"], position_ids=batch["position_ids"])
else:
logits = model(
input_ids=batch["input_ids"],
token_type_ids=batch["token_type_ids"],
position_ids=batch["position_ids"],
attention_mask=batch["attention_mask"],
)
start_prob, end_prob = logits
start_ids, end_ids = batch["start_positions"], batch["end_positions"]
num_correct, num_infer, num_label = metric.compute(start_prob, end_prob, start_ids, end_ids)
metric.update(num_correct, num_infer, num_label)
precision, recall, f1 = metric.accumulate()
logger.info("f1: %s, precision: %s, recall: %s" % (f1, precision, f1))
model.train()
return f1
trainer.compress(custom_evaluate=custom_evaluate)
if __name__ == "__main__":
main()
## CPU训练
python finetune.py --device cpu --logging_steps 10 --save_steps 100 --eval_steps 100 --seed 42 --model_name_or_path uie-base --output_dir model --train_path data/train.txt --dev_path data/dev.txt --max_seq_length 512 --per_device_eval_batch_size 16 --per_device_train_batch_size 16 --num_train_epochs 20 --learning_rate 1e-5 --label_names "start_positions" "end_positions" --do_train --do_eval --do_export --export_model_dir model --overwrite_output_dir --disable_tqdm True --metric_for_best_model eval_f1 --load_best_model_at_end True --save_total_limit 1
## GPU多卡训练
python3 -u -m paddle.distributed.launch --gpus "0,1" finetune.py --device gpu --logging_steps 10 --save_steps 100 --eval_steps 100 --seed 42 --model_name_or_path uie-base --output_dir model --train_path data/train.txt --dev_path data/dev.txt --max_seq_length 512 --per_device_eval_batch_size 7 --per_device_train_batch_size 7 --num_train_epochs 20 --learning_rate 1e-5 --label_names "start_positions" "end_positions" --do_train --do_eval --do_export --export_model_dir model --overwrite_output_dir --disable_tqdm True --metric_for_best_model eval_f1 --load_best_model_at_end True --save_total_limit 1
模型部署预测
import gradio as gr
from paddlenlp import Taskflow
schema = ['时间', '选手', '赛事名称']
ie = Taskflow('information_extraction', schema=schema, task_path='model')
# UGC: Define the inference fn() for your models
def model_inference(schema, text):
ie.set_schema(eval(schema))
res = ie(text)
json_out = {"text": text, "result": res}
return json_out
def clear_all():
return None, None, None
with gr.Blocks() as demo:
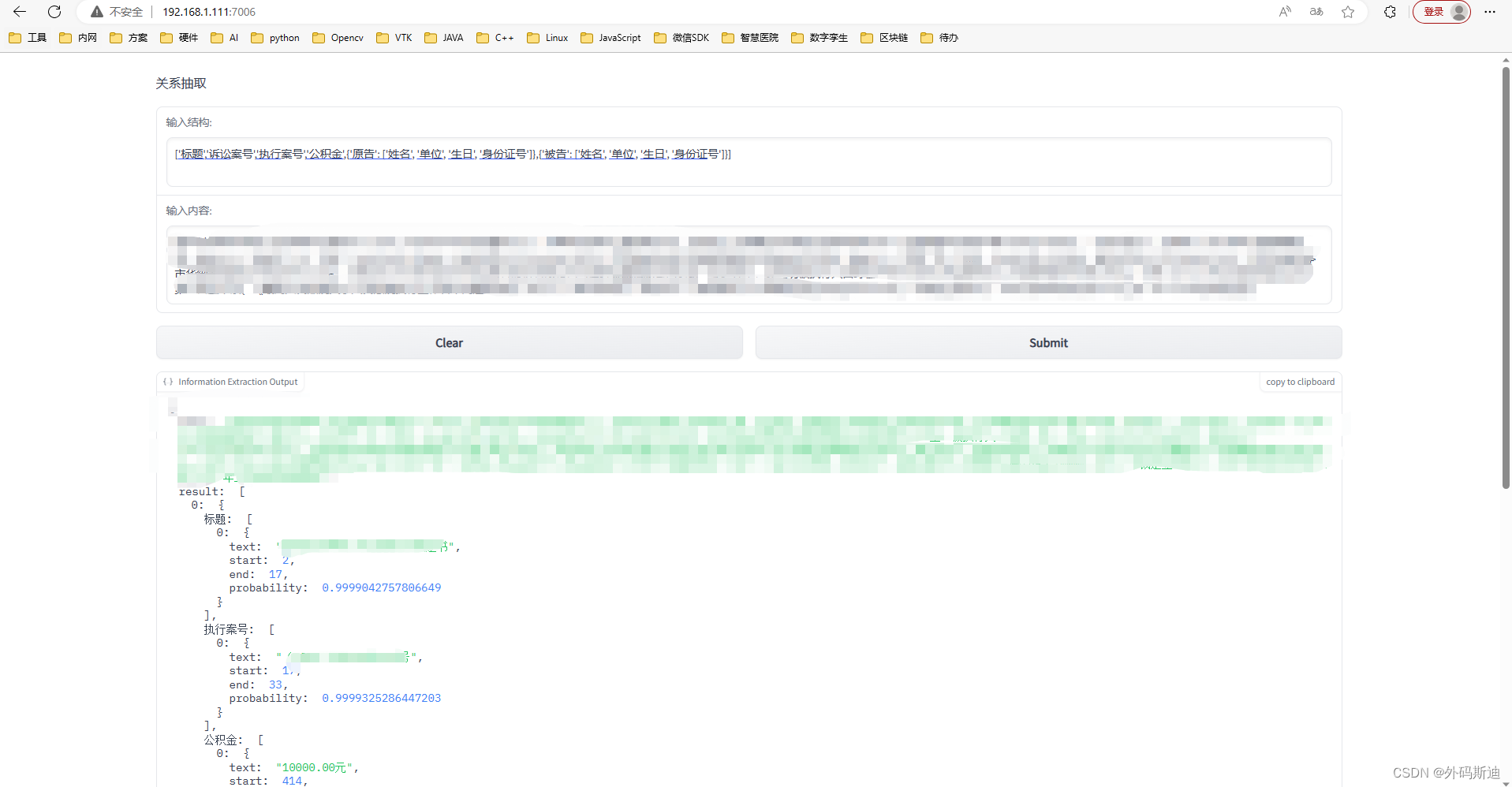
gr.Markdown("关系抽取")
with gr.Column(scale=1, min_width=100):
schema = gr.Textbox(
placeholder="['时间', '选手', '赛事名称']",
label="输入结构:",
lines=2)
text = gr.Textbox(
placeholder="2月8日上午北京冬奥会自由式滑雪女子大跳台决赛中中国选手谷爱凌以188.25分获得金牌!",
label="输入内容:",
lines=2)
with gr.Row():
btn1 = gr.Button("Clear")
btn2 = gr.Button("Submit")
json_out = gr.JSON(label="Information Extraction Output")
btn1.click(fn=clear_all, inputs=None, outputs=[schema, text, json_out])
btn2.click(fn=model_inference, inputs=[schema, text], outputs=[json_out])
gr.Button.style(1)
demo.launch(server_name='192.168.1.111', share=True, server_port=7006)
## 裁定书 ['标题',{'申请执行人': ['姓名', '生于', '身份证号']},{'被执行人': ['姓名', '生于', '身份证号']},'公积金']
## 调解书 ['法院',{'原告': ['姓名', '生于', '身份证号']},{'被告': ['公司']},'公积金']
## 测试 ['标题','诉讼案号','执行案号','公积金',{'原告': ['姓名', '单位', '生日', '身份证号']},{'被告': ['姓名', '单位', '生日', '身份证号']}]
python3 ./app.py