文章目录
- PolyFormer: Referring Image Segmentation as Sequential Polygon Generation\
- 摘要
- 本文方法
- Multi-modal Transformer Encoder
- Regression-based Transformer Decoder
- 实验结果
PolyFormer: Referring Image Segmentation as Sequential Polygon Generation\
摘要
- 在这项工作中,参考图像分割的问题被公式化为顺序多边形生成,而不是直接预测像素级分割掩码,并且预测的多边形可以稍后转换为分割掩码。
- 这是由一个新的序列到序列框架Polygon Transformer(PolyFormer)实现的,该框架以一系列图像patch和文本查询token作为输入,并自回归地输出一系列多边形顶点。
- 为了更精确的几何定位,提出了一种基于回归的解码器,它可以直接预测精确的浮点坐标,而没有任何坐标量化误差。
- 代码地址
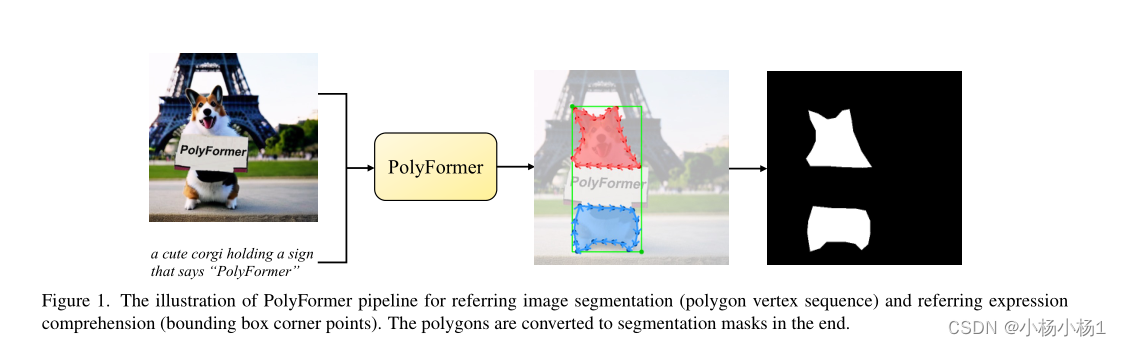
本文方法
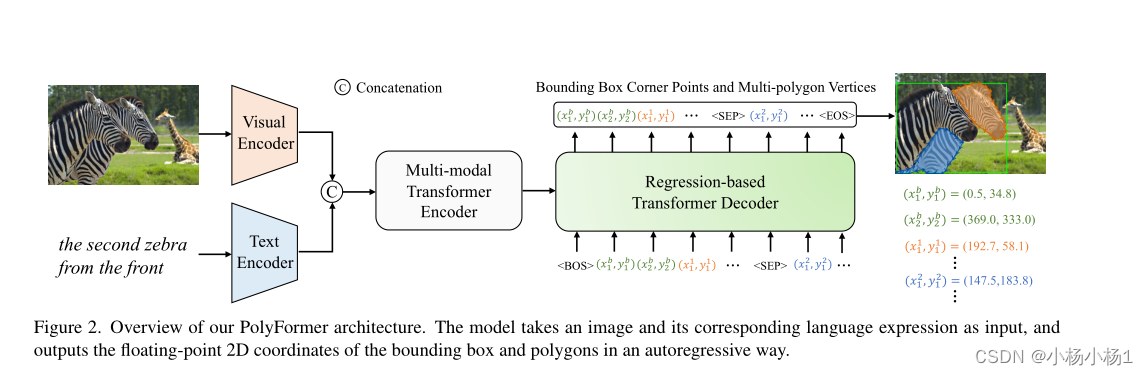
PolyFormer不是预测密集的分割mask,而是按顺序生成边界框的角点和勾勒对象轮廓的多边形的顶点。具体来说,我们首先使用视觉编码器和文本编码器分别提取图像和文本特征,然后将其投影到共享的嵌入空间中。接下来,我们将图像和文本特征连接起来,并将它们输入到多模式转换器编码器中。
最后,基于回归的变换器解码器获取编码的特征,并以自回归的方式输出连续浮点边界框角点和多边形顶点
分割mask生成为多边形所包含的区域
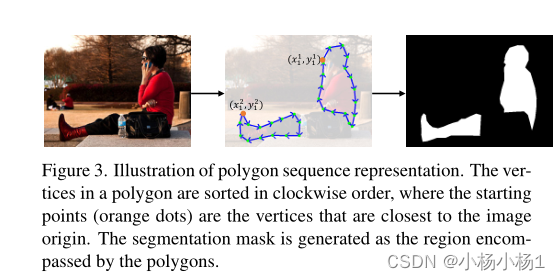
图3。多边形序列表示的图示。多边形中的顶点按顺时针顺序排序,其中起点(橙色点)是最靠近图像原点的顶点。分割遮罩生成为多边形所包含的区域。
Multi-modal Transformer Encoder
输入:图像为swin transformer
文本为bert
融合:
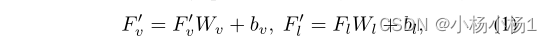
线性映射到相同形状,然后concat
多模编码器由N个transformer层组成,其中每一层由一个多头自注意层、一个层归一化和一个前馈网络组成。它采用级联特征FM并逐步生成多模态特征FNM。
Regression-based Transformer Decoder
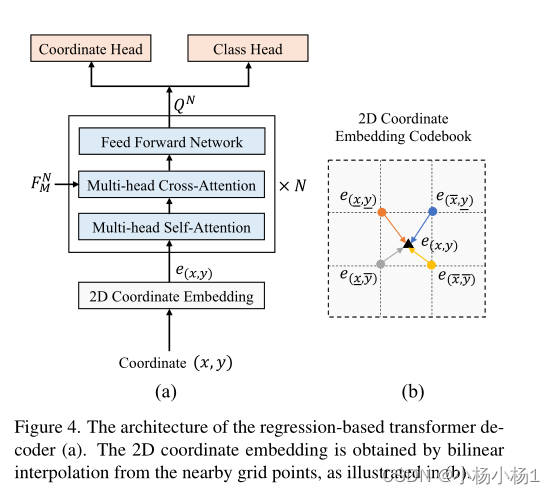
基于回归的transformer解码器的架构(a)。2D坐标嵌入是通过双线性插值从附近的网格点获得的,如(b)所示。
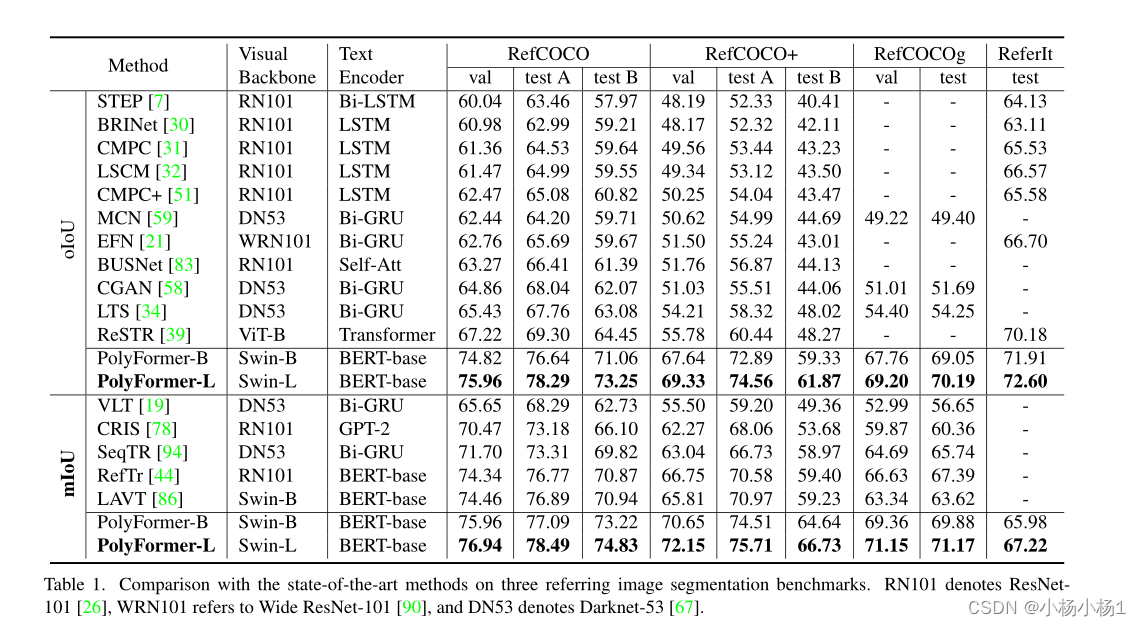
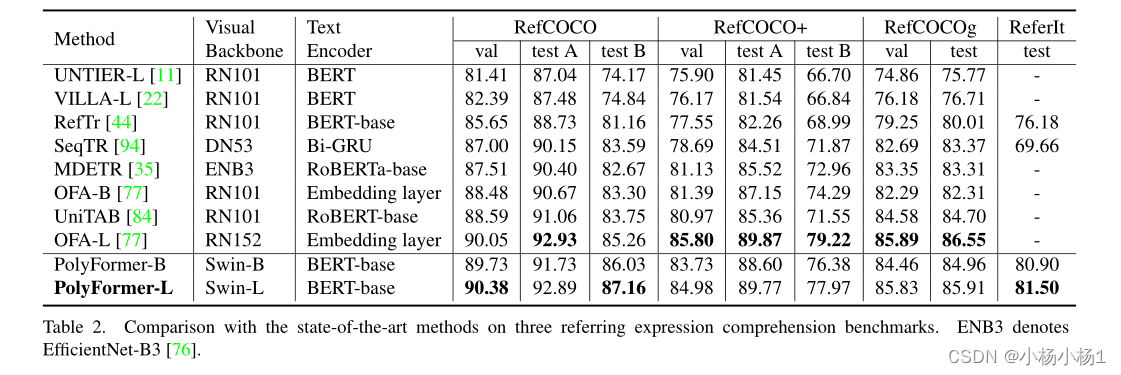
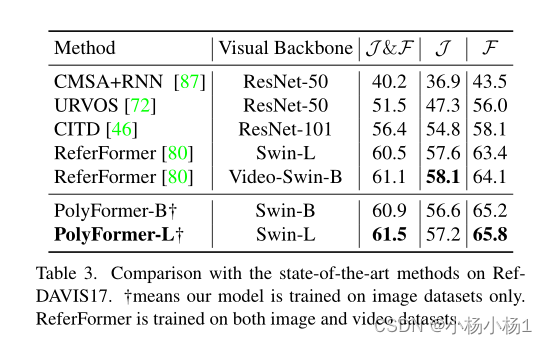
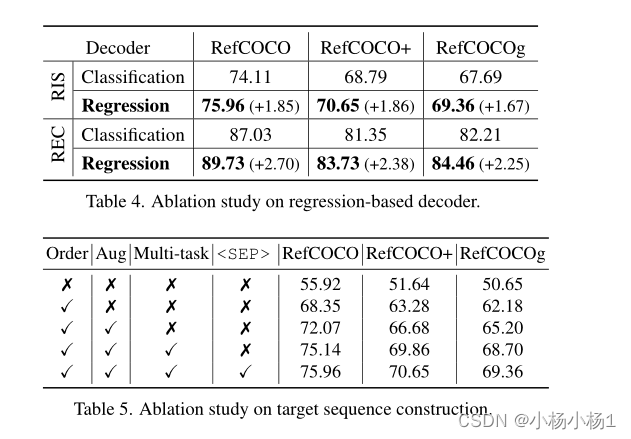
实验结果