1.RDD分区数
Task是作用在每个分区上的,每个分区至少需要一个Task去处理
改变分区数可间接改变任务的并行度,类似手动指定Reduce数量
第一个RDD的分区数由切片的数量决定 默认情况下子RDD的分区数等于父RDD的分区数
Shuflle类算子可手动指定RDD分区数 设置spark.default.parallelism参数可改变Shuffle类算子默认分区数
通过repartition/coalesce操作改变RDD分区数
repartition:通过shuffle的方式增加或减少分区数 coalesce:默认不通过shuffle的方式改变分区数,只能减少分区
优先级
决定分区数优先级,依次从高到低:
1.使用repartiton/coalesce手动改变
增加到8个分区:someRDD.repartition(numPartitions = 8)
减少到2个分区:someRDD.coalesce(numPartitions = 2)
2.使用shuffle类算子时手动指定 kvRDD.groupByKey(numPartitions = 4)
3.设置spark.default.parallelism参数 conf.set("spark.default.parallelism", "20")
4.基于默认情况 默认等于上一个RDD的分区数,如有多个RDD则分区数相加
package com.bigdata.core
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object DemoPartitions {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
conf.setMaster("local")
conf.setAppName("Demo21Partitions")
conf.set("spark.default.parallelism", "3")
val sc: SparkContext = new SparkContext(conf)
//1.第一个RDD的分区数由切片数量决定,但也会受到minPartitions的影响
val stuRDD: RDD[String] = sc.textFile("spark/data/stu/students.txt")
println(s"stuRDD的分区数:${stuRDD.getNumPartitions}")
//2.默认情况下,子分区RDD数量等于父RDD的分区数
val clazzKVRDD: RDD[(String, Int)] = stuRDD.map(line => (line.split(",")(4), 1))
println(s"clazzKVRDD的分区数为:${clazzKVRDD.getNumPartitions}")
//3.shuffle类算子可以手动指定分区数量
val grpRDD: RDD[(String, Iterable[Int])] = clazzKVRDD.groupByKey(4)
println(s"grpRDD的分区数为:${grpRDD.getNumPartitions}")
//4.如果shuffle类算子没有指定分区数,默认等于父RDD的分区数
// 当然也可以由Spark的一个参数决定:spark.default.parallelism
// shuffle类算子最后返回的RDD分区数决定因素:手动指定 > spark.default.parallelism > 父RDD的分区数
val grpRDD1: RDD[(String, Iterable[Int])] = clazzKVRDD.groupByKey()
println(s"grpRDD的分区数为:${grpRDD.getNumPartitions}")
val filterRDD: RDD[String] = stuRDD.filter(line => line.split(",")(4) == "文科一班")
println(s"filterRDD的分区数为:${filterRDD.getNumPartitions}")
coalesce只能用于减少分区数量
//coalesce默认不使用shuffle改变分区的数量,所以只适用于减少分区数
val filterCoalRDD: RDD[String] = filterRDD.coalesce(1)
println(s"filterCoalRDD的分区数为:${filterCoalRDD.getNumPartitions}")
/**
* repartition实际上就是调用了coalesce方法,只不过将shuffle开关置为true
* 即使用shuffle的方式改变分区数
* 使用repartition不仅可以增加分区数,也可以减少分区数
*/
val repoFilterRDD1: RDD[String] = filterRDD.repartition(3)
println(s"repofilterRDD1的分区数为:${repoFilterRDD1.getNumPartitions}")
val repoFilterRDD2: RDD[String] = filterRDD.repartition(1)
println(s"repofilterRDD2的分区数为:${repoFilterRDD2.getNumPartitions}")
}
}
如何选择coalesce还是repartition(coalesce不带shuffle操作,repartition为shuffle操作)
增加分区:repartition
减少分区:
后续是否要做shuffle类的操作:
需要:repartition
不需要:coalesce
2.Cache缓存
Spark中对每个RDD执行一个算子操作时,都会重新从源头处计算一遍 如果该RDD被多次使用,则会导致该RDD被重复计算 重复计算,浪费资源,消耗时间,影响整体性能
对多次使用的RDD可以通过cache/persist操作进行缓存
repeatRDD.cache() 默认以仅内存策略对RDD进行缓存
相当于repeatRDD.persist(StorageLevel.MEMORY_ONLY) ,可以设置StorageLevel

如何选择合适的缓存策略:
内存充足:MEMORY_ONLY
内存不够:MEMORY_AND_DISK_SER
缓存策略需要通过persist方法进行指定
package com.bigdata.core
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
object DemoCache {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
conf.setMaster("local")
conf.setAppName("Demo22Cache")
val sc: SparkContext = new SparkContext(conf)
val stuRDD: RDD[String] = sc.textFile("spark/data/stu/students.txt")
//使用该方法判断次数
val newStuRDD: RDD[String] = stuRDD.map(line => {
println("使用map方法")
line
})
//对多次使用的RDD进行缓存
// newStuRDD.cache()
// cache相当于默认使用MEMORY_ONLY的缓存策略
newStuRDD.persist(StorageLevel.MEMORY_AND_DISK_SER)
// 统计班级人数
newStuRDD.map(line => (line.split(",")(4), 1)).reduceByKey(_ + _).foreach(println)
// 统计性别人数
newStuRDD.map(line => (line.split(",")(3), 1)).reduceByKey(_ + _).foreach(println)
// 统计年龄分布情况
newStuRDD.map(line => (line.split(",")(2).toInt, 1)).reduceByKey(_ + _).foreach(println)
newStuRDD.unpersist()
}
}
3.CheckPoint检查点
Checkpoint 检查点是一种容错容灾机制(类似于快照操作)
将某一时刻运行的内存数据和状态进行持久化
通常会持久化到磁盘
或者是分布式文件系统,例如HDFS
CheckPoint 的执行原理: 当RDD的job执行完毕后,会从最后一个RDD往前回溯 当回溯到某个RDD调用了checkpoint方法后,Spark会启动一个新的job 该任务会重新计算该RDD的数据,并持久化到HDFS上
package com.bigdata.core
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object DemoCheckPoint {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
conf.setMaster("local")
conf.setAppName("Demo23CheckPoint")
val sc: SparkContext = new SparkContext(conf)
//CheckPoint操作执行前需要先指定目录来存放检查点(快照)
sc.setCheckpointDir("spark/data/ck")
val stuRDD: RDD[String] = sc.textFile("spark/data/stu/students.txt")
val newStuRDD: RDD[String] = stuRDD.map(line => {
println("调用map方法")
line
})
newStuRDD.cache()
//对多次使用或者计算量较大的RDD做CheckPoint
newStuRDD.checkpoint()
// 统计班级人数
newStuRDD.map(line => (line.split(",")(4), 1)).reduceByKey(_ + _).foreach(println)
// 统计性别人数
newStuRDD.map(line => (line.split(",")(3), 1)).reduceByKey(_ + _).foreach(println)
// 统计年龄分布情况
newStuRDD.map(line => (line.split(",")(2).toInt, 1)).reduceByKey(_ + _).foreach(println)
}
}
可以先对需要执行checkpoint操作的RDD先进行cache操作,防止重复计算,提高性能
checkpoint vs cache

4.Lineage血统
Spark中解决节点失效、数据丢失等问题时采用的一种机制或方案 为了保证RDD 中数据的鲁棒性,RDD数据集通过所谓的血统关系(Lineage)记住了它是如何从其它RDD中演变过来的 将每种形态看做一个RDD
相比其它系统的细粒度容错机制
内存数据更新级别的备份或者LOG机制
Redis中的RDB策略
HBase的WAL机制
RDD的Lineage记录的是粗粒度的
RDD之间的转换操作都会会被记录
例如filter, map, join等操作都会被记录
有点类似Redis中的AOF策略
当RDD的分区数据丢失时 ,可通过Lineage来重新运算并恢复丢失的数据
宽依赖的分区数据重算开销要远大于窄依赖
5.广播变量
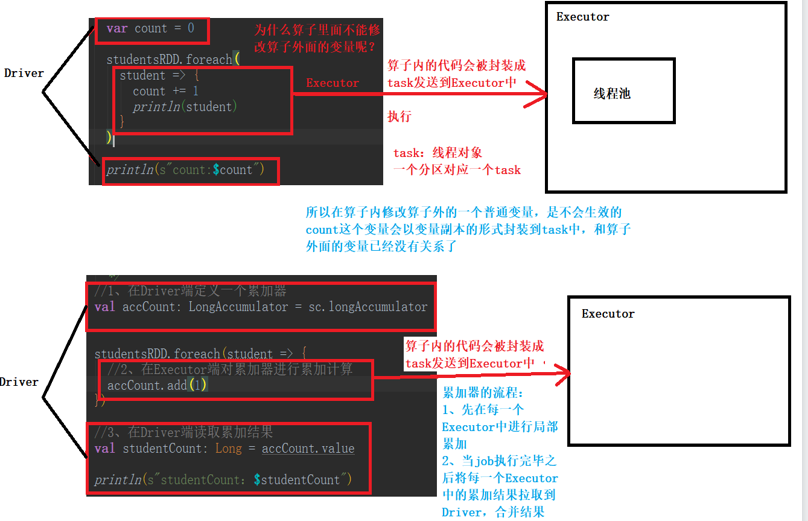
算子内部的代码最终会被封装到Task并发送到Executor中执行 如果在算子内部使用了算子外部的变量,变量也会封装到Task中 Task中使用的实际上是外部变量的副本 Task的数量决定了外部变量副本的数量 Task是在Executor中执行的 Task的数量会远大于Executor的数量 故可将外部变量广播到每个Executor中,减少变量的副本数 进而减少网络中传输的数据量,提升运行效率
val conf: SparkConf = new SparkConf()
conf.setMaster("local")
conf.setAppName("Demo19MapJoin")
val sc: SparkContext = new SparkContext(conf)
val stuRDD: RDD[String] = sc
.textFile("spark/data/stu/students.txt")
val scoreRDD: RDD[String] = sc
.textFile("spark/data/stu/score.txt")
//求出每个学生的总分
val sumScoreRDD: RDD[(String, Int)] = scoreRDD.map(line => {
val splits: Array[String] = line.split(",")
(splits(0), splits(2).toInt)
}).reduceByKey(_ + _)
//不可以在RDD中嵌套RDD,故需要先将RDD转换成map
val sumScoreMap: Map[String, Int] = sumScoreRDD.collect().toMap
//在此处通过map的getOrElse来获取上部中被转化的map中的学生总分
stuRDD.map(line=>{
val splits: Array[String] = line.split(",")
val id: String = splits(0)
val sumScore: Int = sumScoreMap.getOrElse(id, 0)
s"$id,${splits(1)},${splits(4)},$sumScore"
}).foreach(println)广播变量是Executor之间的共享变量 广播变量在Driver中一次性创建
Executor对这些变量只能进行读取操作 一般会对本地变量进行广播
例如整形、List集合、Map集合等
但通常是当变量较大时才会进行广播
例如将RDD转换成本地集合再进行广播
广播变量会广播到每个Executor,由BlockManager维护
在Executor上运行的Task都可以访问广播变量
6.累加器
使用及执行原理如图所示
在Driver端定义 sc.longAccumulator
在算子内部累加 accCount.add
在Driver端汇总 accCount.value