1. Web服务器网站
进一步把前面的Web网站的mysql.html, python.html, java.html丰富其中 的内容,并加上图形:
mysql.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>mysql</title>
</head>
<body>
<h3>MySQL数据库</h3>
<div>
MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,目前属于 Oracle 旗 下产品。MySQL 是最流行的关系型数据库管理系统之一,在 WEB 应用方面,MySQL是 最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软 件。
</div>
<div>
<img src="mysql.jpg" />
</div>
<a href="books.html">Home</a>
</body>
</html>java.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>java</title>
</head>
<body>
<h3>Java程序设计</h3>
<div>
Java是一门面向对象编程语言,不仅吸收了C++语言的各种优 点,还摒弃了C++里难以理解的多继承、指针等概念,因此 Java语言具有功能强大和简单易用两个特征。Java语言作为静 态面向对象编程语言的代表,极好地实现了面向对象理论,允 许程序员以优雅的思维方式进行复杂的编程.
</div>
<div>
<img src="java.jpg">
</div>
<a href="books.html">Home</a>
</body>
</html>python.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>python</title>
</head>
<body>
<h3>Python程序设计</h3>
<div>
Python (英国发音:/ˈpaɪθən/ 美国发音:/ˈpaɪθɑːn/), 是一 种面向对象的解释型计算机程序设计语言,由荷兰人Guido van Rossum于1989年发明,第一个公开发行版发行于1991年。
</div>
<div>
<img src="python.jpg">
</div>
<a href="books.html">Home</a>
</body>
</html>2. 爬取网站的复杂数据
服务器server.py程序还是前面3.2的,如下:
import flask
import os
app = flask.Flask(__name__)
def getFile(fileName):
data = b""
if os.path.exists(fileName):
fobj = open(fileName, "rb")
data = fobj.read()
fobj.close()
return data
@app.route("/")
def index():
return getFile("books.html")
@app.route("/<section>")
def process(section):
data = ""
if section != "":
data = getFile(section)
return data
if __name__ == "__main__":
app.run()
爬取网站中的mysql, python, java的简介与图像。我们看到简介在网页的第一个<div>中,图像在<img>中,而且只有这3个网页有这样的特征,
设计客户端client.py程序如下:
from bs4 import BeautifulSoup
import urllib.request
def spider(url):
global urls
if url not in urls:
urls.append(url)
try:
data = urllib.request.urlopen(url)
data = data.read().decode()
soup = BeautifulSoup(data, "lxml")
print(soup.find("h3").text)
divs = soup.select("div")
imgs = soup.select("img")
# 判断这个url页面是否有<div>与<img>,如果有就获取第一个<div>的文字,下载第一个<img>的图像
if len(divs) > 0 and len(imgs) > 0:
print(divs[0].text)
url = start_url + "/" + imgs[0]["src"]
urllib.request.urlretrieve(url, "downloaded-" + imgs[0]["src"])
print("download-", imgs[0]["src"])
links = soup.select("a")
for link in links:
href = link["href"]
url = start_url + "/" + href
spider(url)
except Exception as err:
print(err)
start_url = "http://127.0.0.1:5000"
urls = []
spider(start_url)
print("The End")
运行结果如下:
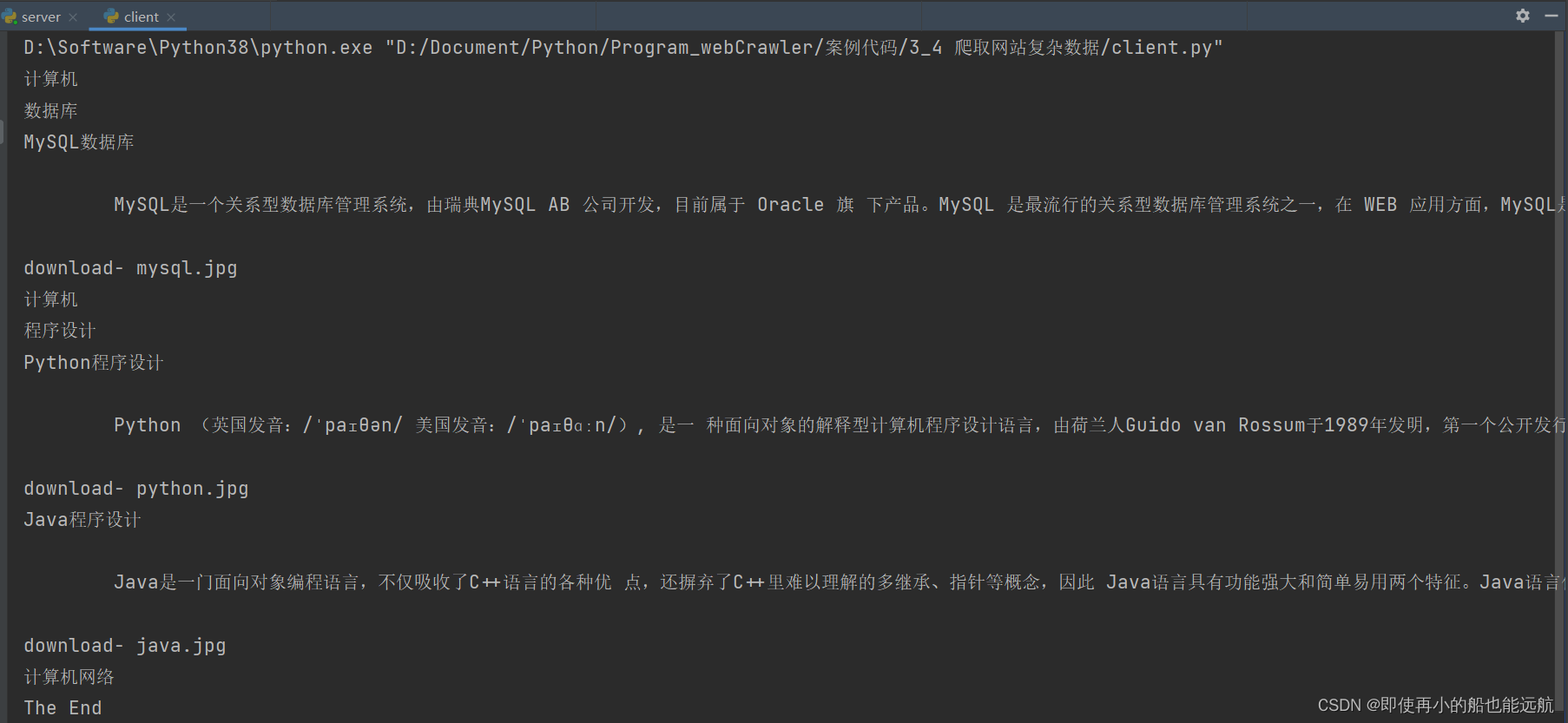
程序执行完毕后还看到下载了3个文件:
"downloaded-mysql.jpg"、 "downloadedpython.jpg"、"downloaded-java.jpg"
3. 爬取程序的改进
(1)服务器程序
由于我们的web网站时本地的,因此下载图像非常快,而实际应用中 Web网站是远程的一个服务器,由于网络原因可能下载会比较慢。为了 模拟这个过程,
改进后的服务器serverUpdate.py程序如下:
import flask
import os
import random
import time
app = flask.Flask(__name__)
def getFile(fileName):
data = b""
if os.path.exists(fileName):
fobj = open(fileName, "rb")
data = fobj.read()
fobj.close()
# 随机等待1-10秒
time.sleep(random.randint(1, 10))
return data
@app.route("/")
def index():
return getFile("books.html")
@app.route("/<section>")
def process(section):
data = ""
if section != "":
data = getFile(section)
return data
if __name__ == "__main__":
app.run()
该程序在每次返回一个网页或者图像的函数getFile中都随机等待了1- 10秒,这个过程十分类似网络条件较差的情景,即访问任何一个网页或 者图像都有1-10秒的延迟。
(2)客户端程序
从目前的程序来看这个程序在下载一个图像时是等待的,如果这个图像很大,那么下载时间很长,程序就必须一直等待,其它网页就无法继续访问,即卡死在一个网页的图像下载处。为了避免这个问题,一般可以对程序做以下改进:
- 设置urllib.request下载图像的时间,如果超过一定时间还没有完 成下载就放弃;
- 设置下载过程是一个与主线程不同的子线程,子线程完成下载 任务,不影响主线程继续访问别的网页。
改进后的客户端clientUpdate.py程序如下:
from bs4 import BeautifulSoup
import urllib.request
import threading
def download(url, fileName):
try:
# 设置下载时间最长100秒
data = urllib.request.urlopen(url, timeout=100)
data = data.read()
fobj = open("download" + fileName, "wb")
fobj.write(data)
fobj.close()
print("download", fileName)
except Exception as err:
print(err)
def spider(url):
global urls
if url not in urls:
urls.append(url)
try:
data = urllib.request.urlopen(url)
data = data.read().decode()
soup = BeautifulSoup(data, "lxml")
print(soup.find("h3").text)
links = soup.select("a")
divs = soup.select("div")
imgs = soup.select("img")
# 判断这个url页面是否有<div>与<img>,如果有就获取第一个<div>的文字,下载第一个<img>的图像
if len(divs) > 0 and len(imgs) > 0:
print(divs[0].text)
url = start_url + "/" + imgs[0]["src"]
# 启动一个下载线程下载图像
T = threading.Thread(target=download, args=(url, imgs[0]["src"]))
T.setDaemon(False)
T.start()
threads.append(T)
for link in links:
href = link["href"]
url = start_url + "/" + href
spider(url)
except Exception as err:
print(err)
start_url = "http://127.0.0.1:5000"
urls = []
threads = []
spider(start_url)
# 等待所有线程执行完毕
for t in threads:
t.join()
print("The End")
执行结果如下:

从结果看到访问java.htm网页后没有及时完成java.jpg的下载,java.jpg是在访问 network.htm网页后才完成下载的,这就是多线程的过程。