点击上方“Python爬虫与数据挖掘”,进行关注
回复“书籍”即可获赠Python从入门到进阶共10本电子书
今
日
鸡
汤
在天愿作比翼鸟,在地愿为连理枝。
大家好,我是皮皮。
一、前言
前几天在Python最强王者群【刘桓鸣】问了一个Python网络爬虫的问题,这里拿出来给大家分享下。
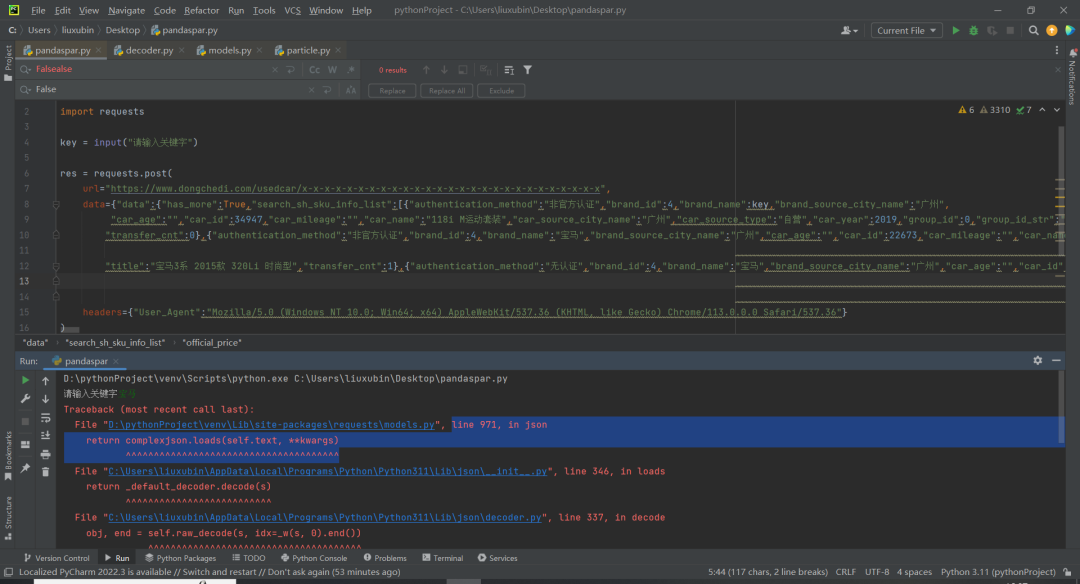
他自己的代码如下:
import requests
key = input("请输入关键字")
res = requests.post(
url="https://jf.10086.cn/cmcc-web-shop/search/query",
data={
"sortColumn" : "default",
"sortType": "DESC",
"pageSize": "60",
"pageNum": "1",
"firstKeyword": key,
"integral": "",
"province": ""},
headers={"User_Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"}
)
print(res.json())二、实现过程
这里【隔壁😼山楂】指出拿到的数据需要用json解析,后来【瑜亮老师】指出是参数加少了。
甯同学指出,需要在请求头里边加上origin,后来【eric】给出了一个对应代码,如下所示:
import requests
headers = {
"authority": "jf.10086.cn",
"accept": "*/*",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"content-type": "application/x-www-form-urlencoded;charset=UTF-8",
"origin": "https://jf.10086.cn",
"referer": "https://jf.10086.cn/",
"sec-ch-ua": "\"Microsoft Edge\";v=\"113\", \"Chromium\";v=\"113\", \"Not-A.Brand\";v=\"24\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"sessionid": "",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.42"
}
cookies = {
"sajssdk_2015_cross_new_user": "1",
"sensorsdata2015jssdkcross": "%7B%22distinct_id%22%3A%221882e060ca319-0c9999999999998-7b515477-921600-1882e060ca46ed%22%2C%22first_id%22%3A%22%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%24latest_referrer%22%3A%22%22%7D%2C%22identities%22%3A%22eyIkaWRlbnRpdHlfY29va2llX2lkIjoiMTg4MmUwNjBjYTMxOS0wYzk5OTk5OTk5OTk5OTgtN2I1MTU0NzctOTIxNjAwLTE4ODJlMDYwY2E0NmVkIn0%3D%22%2C%22history_login_id%22%3A%7B%22name%22%3A%22%22%2C%22value%22%3A%22%22%7D%2C%22%24device_id%22%3A%221882e060ca319-0c9999999999998-7b515477-921600-1882e060ca46ed%22%7D",
"BSFIT_EXPIRATION": "1684453169465",
"BSFIT_DEVICEID": "eNgfgPaqBaS8qXzJHKXgXxJUCen3U5WF8tO1cjBaMqaDL7EKt2xK0J5XwThnB_kC-VbJC2t-N4axkF2UXAKhRvM7w7kNMRWX8pyxlMitEPPbnWVSnXSU4e2MZvpGBme1L3PX7et2B40xYhXg0MpYpfmUtnuJJTEQ"
}
url = "https://jf.10086.cn/cmcc-web-shop/search/query"
data = {
"sortColumn": "default",
"sortType": "DESC",
"pageSize": "60",
"pageNum": "1",
"firstKeyword": "食用油",
"integral": "",
"province": ""
}
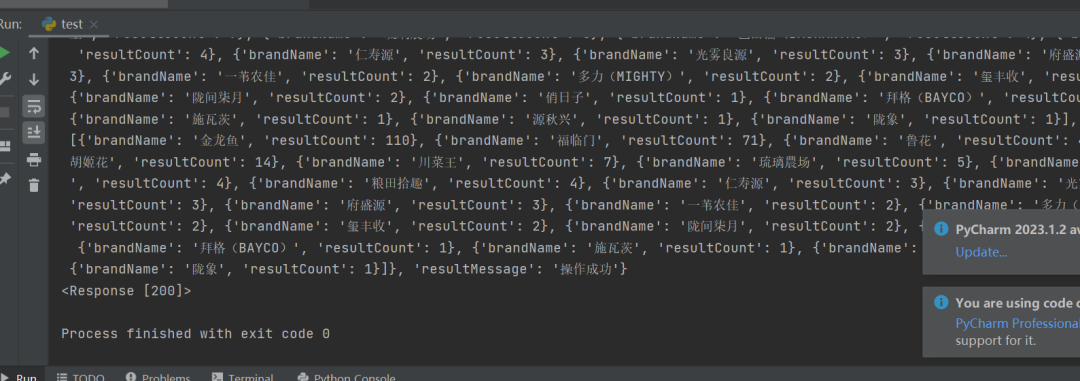
response = requests.post(url, headers=headers, cookies=cookies, data=data)代码运行之后,可以得到预期的数据:
这里【甯同学】也给出了对应的代码,如下所示:
后来【瑜亮老师】测试发现,请求头里边只需要增加ua和origin就可以了。
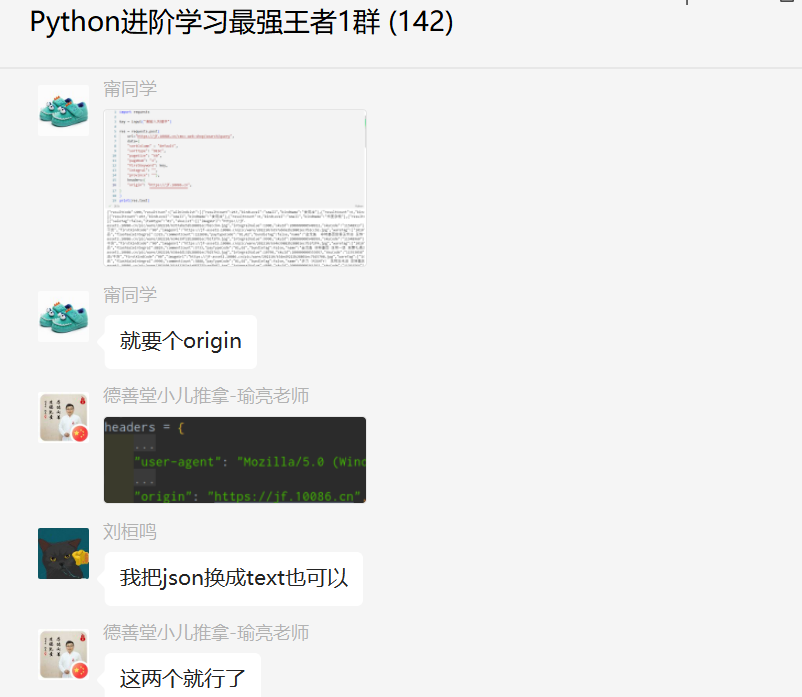
顺利地解决了粉丝的问题。
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Python网络爬虫的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【刘桓鸣】提问,感谢【隔壁😼山楂】、【瑜亮老师】、【eric】、【甯同学】给出的思路和代码解析,感谢【冷喵】、【Ineverleft】、【༺࿈黑科技·鼓包࿈༻】等人参与学习交流。
【提问补充】温馨提示,大家在群里提问的时候。可以注意下面几点:如果涉及到大文件数据,可以数据脱敏后,发点demo数据来(小文件的意思),然后贴点代码(可以复制的那种),记得发报错截图(截全)。代码不多的话,直接发代码文字即可,代码超过50行这样的话,发个.py文件就行。

大家在学习过程中如果有遇到问题,欢迎随时联系我解决(我的微信:pdcfighting1),应粉丝要求,我创建了一些高质量的Python付费学习交流群和付费接单群,欢迎大家加入我的Python学习交流群和接单群!

小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。

------------------- End -------------------
往期精彩文章推荐:
if a and b and c and d:这种代码有优雅的写法吗?
Pycharm和Python到底啥关系?
都说chatGPT编程怎么怎么厉害,今天试了一下,有个静态网页,chatGPT居然没搞定?
站不住就准备加仓,这个pandas语句该咋写?

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~