前言
「语音处理」是实时互动领域中非常重要的一个场景,在声网发起的「RTC Dev Meetup丨语音处理在实时互动领域的技术实践和应用」活动中,来自百度、寰宇科技和依图的技术专家,围绕该话题进行了相关分享。
本文基于微软亚洲研究院主管研究员谭旭在活动中分享内容整理。关注公众号「声网开发者」,回复关键词「DM0428」即可下载活动相关 PPT 资料。
语音识别纠错通过检测并纠正语音识别结果中存在的错误,进一步提升识别准确率。目前,大部分纠错模型采用了基于注意力机制的自回归结构,延迟较高,影响模型线上部署。
本文将介绍一种低延迟、高精度的纠错模型 FastCorrect,通过利用编辑对齐以及多个候选结果,在取得 10% 的词错误率下降的同时,将模型加速 6-9 倍,相关研究论文已被 NeurIPS 2021 和 EMNLP 2021 收录。

01 背景资料
1、ASR(Automatic Speech Recognition 自动语音识别)
语音识别的准确率是影响语音识别广泛应用的最关键因素,如何降低语音识别在识别过程中的错误率对 ASR 来说非常重要。提升语音识别的精度、降低错误率存在很多不同的途径,传统方式是提升语音识别的核心模型。在以往的研究过程中,主要关注点在于如何改进语音识别的训练模型建模范式以及训练数据等。其实,除了提升语音识别模型本身的准确率,还可以对语音识别的识别结果进行后处理,进一步降低识别错误率。
2、ASR 后处理
在语音识别后处理场景下可以进行哪些操作呢?首先是 reranking,也就是重排序,通常在语音识别生成文字的时候会生成多个候选,我们可以通过对模型进行排序,从多个候选中选择较好的结果作为最终的识别结果以提升准确率。第二种方法是对语音识别的结果进行错误纠正,这样能进一步降低错误率。这两种方法都是语音识别后处理的可选方法,也是现在大家广泛采用的降低错误率的办法,而今天的分享主要聚焦于纠错手段。
3、为什么选择纠错
选择纠错手段的原因是,我们认为纠错是基于已有的语音识别的结果进行改正,能产生更好的语音识别结果。而 reranking 是从已有的语音识别返回的结果中产生一个较好的候选,如果纠错效果足够好,则会比 reranking 更有优势。
02 ASR 纠错任务的形式
上文介绍了技术方案选型,为什么要选择纠错手段。接下来定义 ASR 纠错任务(error correction)的形式。首先给定一个训练数据集合(S,T),其中 S 代表语音识别的输入语音,T 是对应的文本标注。然后 ASR 模型会将语音识别成文本,最终得到 M(S)。M(S) 和 T 两个数据配对组成了一个训练集,error correction 模型主要是在这个训练集中训练。训练完成以后,我们给定 ASR 识别的结果,也就是 M(S),返回正确结果。
Error correction 模型的任务是典型的序列到序列学习任务,输入是一个语音识别生成的结果,而输出是纠错以后的正确结果。既然是序列到序列的模型,以前的工作会很自然地将其当成一个序列建模的任务,通过 encoder- attention-decoder 自回归解码的方式进行纠错,输入是错误的句子,输出是正确的句子。
在解码的过程当中采用自回归方式,比如生成 A,然后生成下一个词 B,再依次生成 C 和 D。这种方式存在一个问题,就是解码速度会比较慢。我们进行过实测,比如线上的 ASR 模型在 CPU 上的平均 latency 是 500 毫秒,如果再加一个自回归的纠错模型,则会带来额外的 660 毫秒的时延,使线上识别速度降低两倍以上,如图 1 所示。

■图 1
这种方案在实际部署的时候显然是不可取的,因此我们的目标是降低时延并保持纠错的精度。我们采用非自回归的方法来进行加速,前面提到的是自回归的方式,而非自回归不是每次生成一个 token,而是一次性生成所有 token,它能提升解码速度。
因为非自回归解码模型广泛应用于机器翻译中,所以我们直接利用典型的机器翻译中的非自回归模型进行尝试,发现它不但不能降低语音识别的错误率,反而还会使其增加,为什么会这样呢?首先我们发现,语音识别文本纠错的非自回归的训练任务和机器翻译是不一样的。比如机器翻译时输入是中文,而输出是英文,则输入序列中的所有 token 都需要被修改,使中文翻译为英文。但是在纠错任务中,输入的句子大部分是正确的,也就是说,输入的句子中大部分词是不需要修改的。
如果还是采用传统的方法,就很容易引发两个问题:漏改和错改。这给纠错任务带来了挑战,如何检测错误,以及如何修改错误,成为提升精度的关键。
03 Naive NAR solution fails
我们对这个问题进行了细致的分析,期望从任务中发现特点以设计具体的非自归建模方法。首先,机器翻译不同的语言(比如中文到英文)有语序交换的特点,因为中文的表达方式和英文的表达方式在语序上是不一样的,但是在错误纠正任务中,识语音识别生成的文本和最后正确的文本,实际上不会产生词的交换错误,而是单调的对齐关系。
其次,词本身错误的可能性有很多,比如插入错误、删除错误和替换错误。基于这两种先验知识,就能给纠错过程提供更细致的错误模式,以指导错误检测和错误纠正操作,我们针对这个问题进行了分析来启发设计相应的模型。
04 FastCorrect 系列模型介绍
微软针对 FastCorrect 模型开展了一些系列工作,包括 FastCorrect 1、FastCorrect 2 和 FastCorrect 3。每一项工作都针对不同的问题和场景。FastCorrect 1 在 NeurIPS 2021 会议上发表,主要是基于前面分析的任务的先验知识,通过文本的编辑距离提供增删改的指导信号,来对语音识别的结果进行纠错。而纠错的时候只针对语音识别最好的结果,因为语音识别可以得出一个结果,也可以通过 beam search 解码得出多个结果。FastCorrect 1 能实现 7~9 倍的加速,同时能达到 8% 的 WERR,也就是词错误率的减少。WERR 虽然看起来很小,但是在目前语音识别的精度已经非常高的情况下,能实现 8% 的 WERR 实际上也是比较不容易的。
虽然通常情况下语音识别最终会返回一个 candidate,但是在语音识别解码的过程中,也会保留多个 candidate。如果多个待选之间能够提供互相印证的信息,能帮助我们更好地实现纠错。所以我们设计了 FastCorrect 2,它发表于 EMNLP 2021 findings,利用多个 candidate 协同作用,进一步降低词错误率。相比 FastCorrect 1,错误率能进一步降低,同时维持比较好的加速比。
这两个工作目前在 Microsoft 的 GitHub( https://github.com/microsoft/NeuralSpeech ) 下开源,大家有兴趣的话可以尝试使用。接下来将详细介绍两个工作的技术实现细节。
1、FastCorrect
FastCorrect 的核心是利用文本纠错中的先验知识,也就是增删改操作的信息,所以我们先将错误的文本和正确的文本进行了对齐操作,通过文本的编辑距离来指导对齐的逻辑,通过对齐就可以知道哪些词要删掉、哪些词要增加、哪些词要替换等。有了这些细粒度的监督信号,模型的建模就会更加容易。比如在删除操作中我们使用了 duration 的概念,duration 是指,为每一个输入的词提前给出信息,指明改到 target 的正确句子中,这个词会变成几个词,比如变成零个词就表示被删掉,变成一个词表示不变或者被替换,变成两个词以上表示进行了插入或者替换的操作。
有了这样的细粒度监督信号,模型的效果将会提升,而不是像机器翻译那样,是一个端到端的通过数据学习的手段。同时,非自归的模型设计也分为三部分,encoder 把错误的文本作为输入以提取信息;duration 预测器预测每个 source token 应该被改成多少个 target token;而 decoder 最终生成 target token。
(1) Edit alignment
接下来介绍 FastCorrect 中的编辑对齐操作,图 2 中左边的序列是语音识别输出的结果 BBDEF,Target 序列是实际的正确结果 ABCDF,这表明语音识别出错了,我们对它进行编辑距离对齐,向上的箭头表示删除,向左表示插入,指向斜对角表示替换。
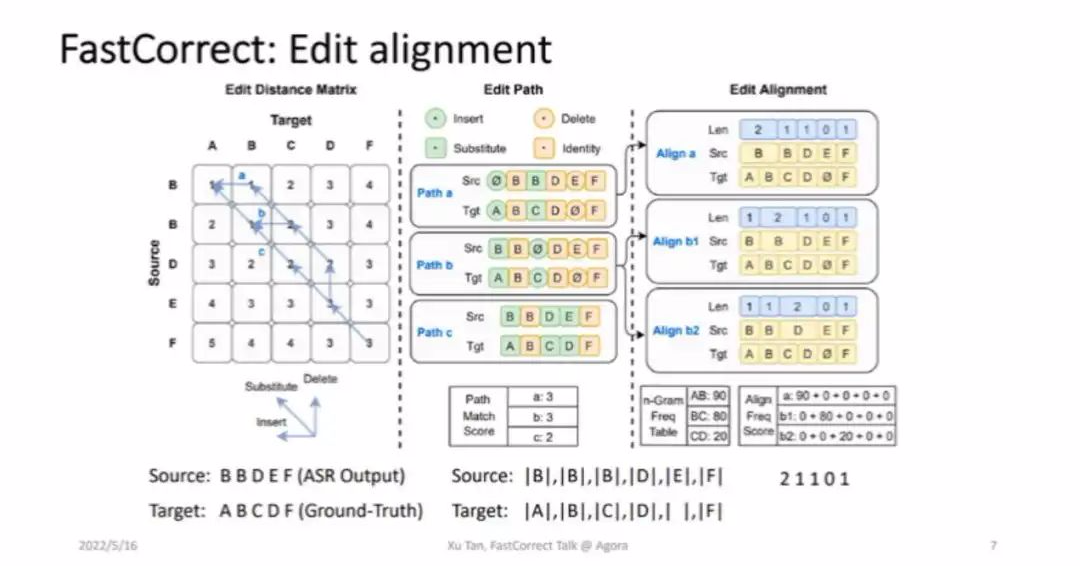
■图 2
编辑距离对齐以后可以得到几条不同的路径,每条路径的编辑距离都是一样的,针对每条路径,我们可以知道 source 的每个 token 和 target 的每个 token 的对齐关系。之后,可以选出一些 match 程度比较高的路径。比如 path a 和 path b 两条路径的 match 程度比 path c 要高,所以我们基于 path a 和 path b 两条路径再选择合适的对齐关系。从这两个 path 可以得到三个不同的对齐,比如在 Align a 中 B 的 token 对应 A 和 B,而 B 对应 C 等。同时 path 也会有不同的可能性,比如在 Align b1 中 B 也有可能对应 B 和 C,在 Align b2 中 D 也可能对应 C 和 D。接下来可以从文本语料中发现哪种是常见的组合,然后通过词的搭配频率来选出合理的对齐关系。
从图 2 下方的 BBDEF 和 ABCDF 可以知道每一个 source token 应该被改成几个 token,比如 Align b1 中第一个 B 会改成 2 个,第二个 B 改成 1 个,D 改成 1 个,E 改成 0 个,F 改成 1 个。有了这些信号以后,就可以清楚地知道每一个 source token 应该被改成几个 token。
(2) NAR model
如图 3 所示,Encoder 输入是错误的句子,预测每一个句子要改成多少个词,再根据这个把句子铺开。比如说你看第一个 B 会改成两个词,我们就把 B 铺两遍。而这个 B 是一个词,我们就把它放在这。那如果它会被删掉,我们就把它删掉。然后最后作为 Decoder 的输入,然后并行的去解码出来。这就是模型的核心方法的设计。
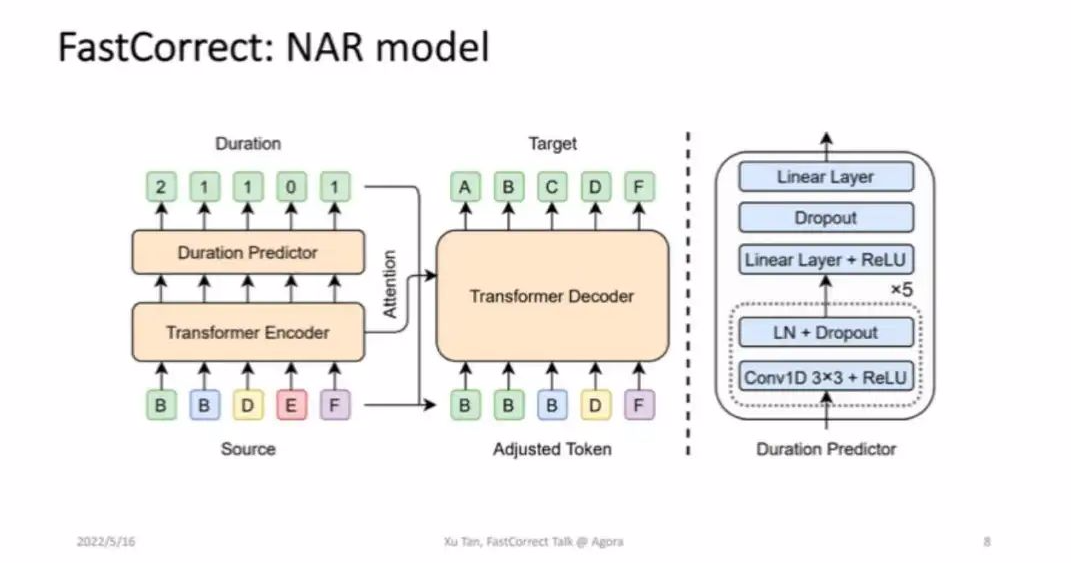
■图 3
(3) Pre-training
在纠错模型训练中,由于 ASR 词错误率比较低,错误的 case 一般 较少,有效训练数据不够,模型的训练效果也会降低,所以我们额外构造了一些错误的配对数据,也就是输入错误但输出正确的句子。因为以往仅靠语音识别的模型来提供数据是不够的,所以我们大规模伪造了这样的数据来进行预训练,再微调到真正的语音识别数据集上。我们在伪造数据的时候模拟了删除、插入和替换操作,因为这些操作要接近真实的语音识别产生错误率的模式,所以增删改的概率都和已有的语音识别的模型比较接近。同时,我们在做替换的时候会优先使用同音字,因为语音识别一般都是出现同音字错误,找到了这样的数据以后,就能很好地帮助模型进行训练。
(4) Experiments
接下来介绍一些实验细节,我们在一些学术数据以及微软内部的语音识别数据集中,聚焦于中文的语音识别纠错,同时选择了大约四亿条来自预训练模型的句子。
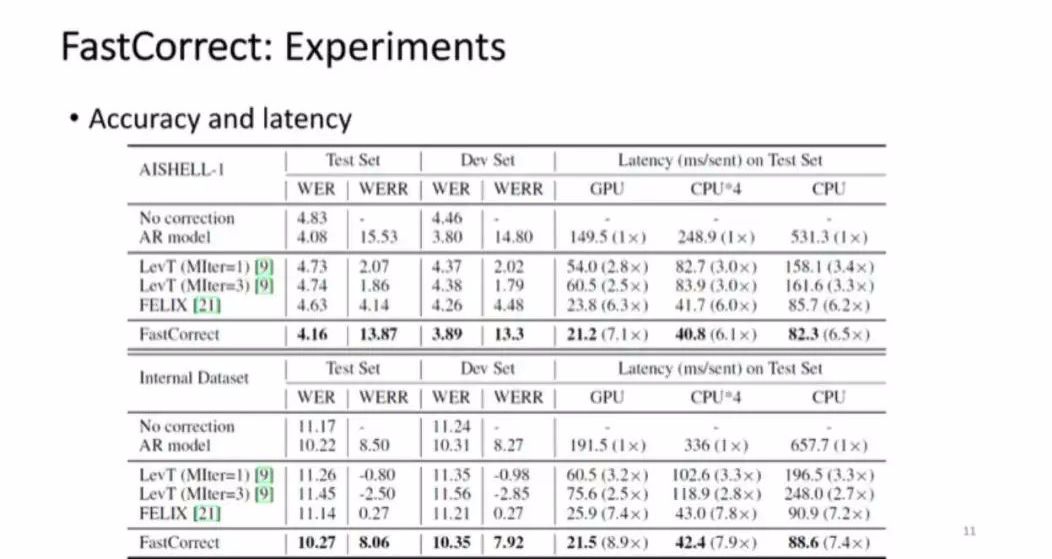
■图 4
实验结果如图 4 所示,可知原始的语音识别大概得到了 4.83 的词错误率,而如果用刚刚提到的自回归模型,也就是 encoder attention decoder,能实现 15% 的词错误率的下降,但是它的 latency 比较高。这是以往采用的方法,包括机器翻译中的非自归方法和文本编辑的一些方法。而我们的方法相比原始的语音识别错误,能达到 13% ~14% 的词错率的下降,接近于自回归模型,也就是说纠错能力几乎没有损失。但是 latency 相比自回归模型加速了 7 倍。可以看出 FastCorrect 方法能很好地维持词错误率下降,同时提升速度,实现线上部署的标准。
我们也 study 每个模块预训练构造数据的方法,以及通过编辑距离做 alignment 的方法的有效性。从图 5 所示的两个数据集可以看到,如果去掉 FastCorrect 的相关模块,还是会导致精度的下降,表明 FastCorrect 的这些模块是比较有用的。

■图 5
自回归模型是一个 encoder decoder,decoder 比较耗时,需要自回归一个词的解码。可能大家会有疑问,为了提升自回归模型的速度,是否可以使 encoder 加深,decoder 变浅,实现同样的加速比并且维持精度呢?对此我们将 FastCorrect 和自回归模型的不同变体进行了对比实验,如图 6 所示,AR 6-6 代表 6 层 encoder 和 6 层 decoder,而 AR 11 -1 代表 11 层 encoder 和 1 层 decoder。可以看到,FastCorrect 方法效果更好,或者词错误率差不多,但是加速比效果提升更明显,这也打消了刚刚的疑问。
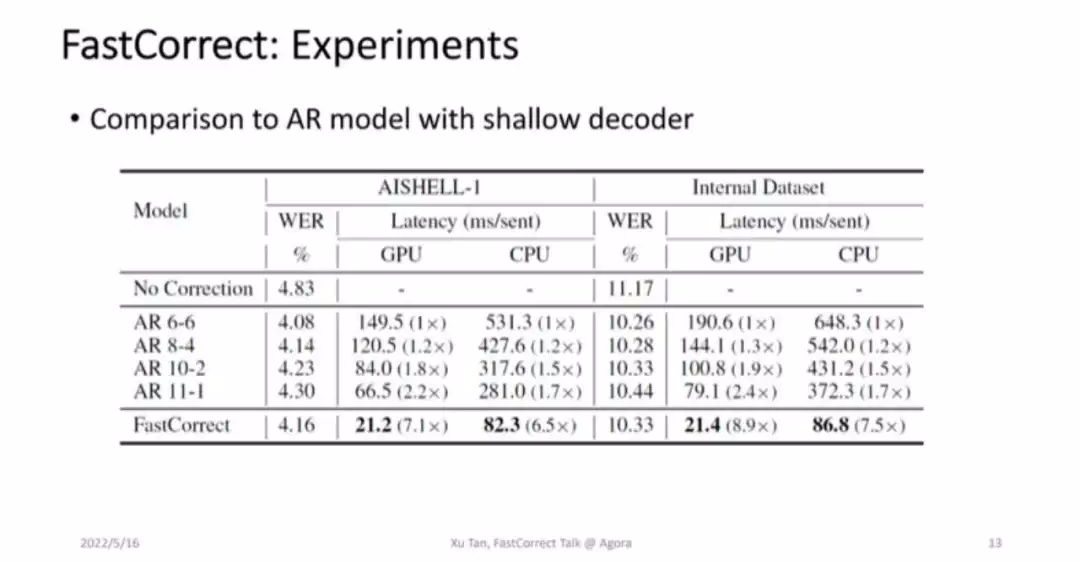
■图 6
前文提到,在文本纠错中怎么检测和纠正错误是非常重要的,我们对此也比较了检测的 precision 和 recall,以及纠错能力。通过对比发现,FastCorrect 方法的效果确实比以前的方法更好,这也验证了之前的一些猜想:通过先验知识提供一些细粒度的增删改指导信号,能帮助我们更好地检测和纠错。
2 FastCorrect 2
(1) Multiple candidates
FastCorrect 2 是 FastCorrect 1 的扩展版,因为 ASR 语音识别的模型得出的结果一般是多个句子,其中会提供一些额外的信息,叫作 voting effect。假设一段语音通过识别模型得到三个可能的句子,分别是“I have cat”“I have hat”“I have bat”,这三个句子互相印证能给我们提供额外的信息。首先,大概率来说前两个词的识别是正确的,因为三个结果都识别出了 I have,但是后面三个词都不一样,说明其中可能有多个是错误的或者都错了。但是大概率来说,这个词是以 at 发音结尾。得到这样的信息以后,纠错和改正的难度会大大降低。修改的时候可以从其中选一个更合理的词,帮助我们缩小问题的空间。这就是 FastCorrect 2 的设计思想。
(2) Model structure
设计模型的结果如图 7 所示,首先,在输入之前把语音识别的多个待选句子对齐,因为对齐后才能提供互相印证的信息。比如在前面的例子中,我们需要让 cat、hat 和 bat 对齐,按照这个思想把输入的句子进行对齐,然后 encoder 会把这些待选句子连结起来作为模型的输入,并预测每个句子的 duration,也就是修改后会改成几个词。还会用一个选择器来选择一个较好的待选,通过 loss 监督选择哪些 candidate 比较好,然后基于较好的 candidate 进行修改。图 7 中的第三个 candidate 较好,我们就把它作为 decoder 输入。这就是整个 FastCorrect 2 的 high level 的设计方法。
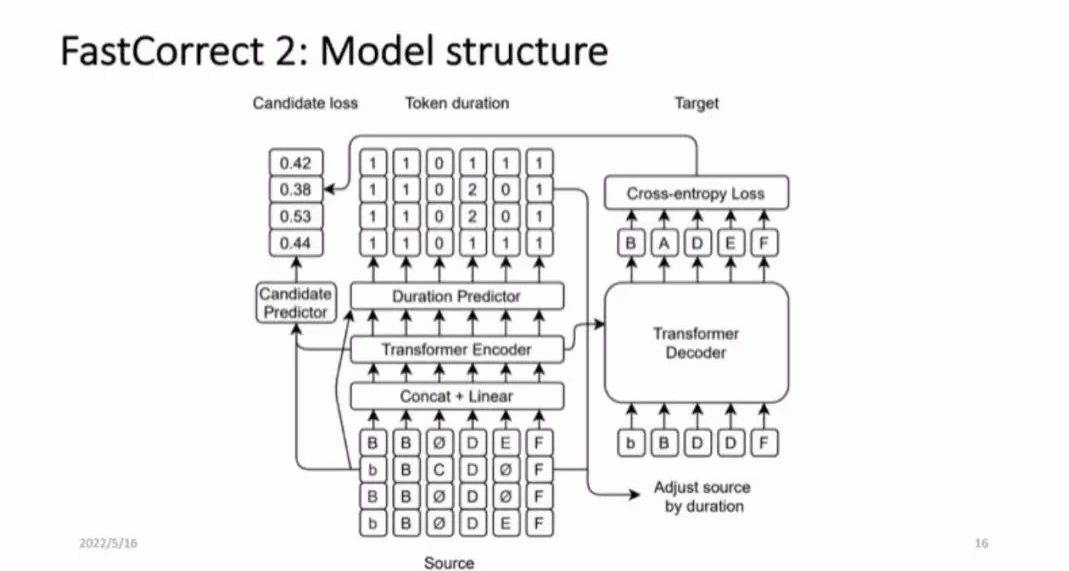
■图 7
(3) Align multiple candidates
这里有一个细节,就是如何将多个句子 Align 起来,使它有更准确的对应关系,对此我们任意找一个 anchor 的 candidate,然后使其他的句子都与该句进行对齐,这里的细节不过多介绍。这个对齐方法实际上和 FastCorrect 1 中介绍的一样,就是先计算编辑距离,然后得到编辑的 path 并从这个 path 中选择比较合理的对齐关系。也就是说,使每一个句子都和 anchor 句子 align 起来之后,就会得到所有句子和这个 anchor 句子的对齐关系,最后把这个 candidate merge 起来,就形成了一个多路的对齐。对齐以后就可以作为模型的输入。
这里有一个对比,就是如果不采用 FastCorrect 2 的对齐方法,而是采用 Naive Padding,就会看到图 8(b) 的情况,这里 B 都聚集在一起,但是 C 和 D 则是混合的。这一点很奇怪,因为就模型来说 C 和 D 实际上没有任何关系。但是因为我们用了一个很简单的方法,使其处在同一个位置,模型就不能获得互相验证的信号了,这就会出现 D、E 和 F 也混合在一起的现象,导致 cat、hat 和 bat 无法互相印证以帮助我们纠错。
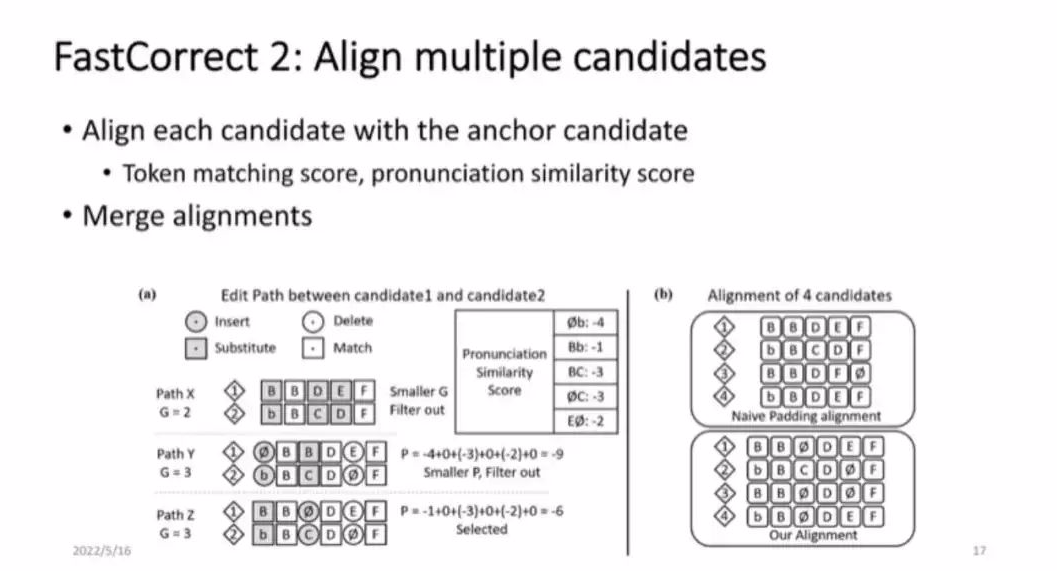
■图 8
(4) Results
接下来展示结果,如图 9 所示,第一行是语音识别结果的错误率,第二行是用自回归模型纠错以后的错误率,第三行是 FastCorrect 1 的结果。同时我们还进行了一些设置,之前提到语音识别的后处理有两种方式,一种是 reranking,另一种是纠错。既然这里涉及到多个 candidate,而 reranking 是基于多个 candidate 进行选择,所以我们就把两种方法叠加起来,先从多个 candidate 中通过 reranking 进行选择,再利用 FastCorrect 1 进行纠错。假设有 4 个 candidate,就对每一个 candidate 分别纠错,并从中选择较好的作为最终结果。FastCorrect 2 方法直接把多个 candidate 通过 align 以后互相对齐作为输入。
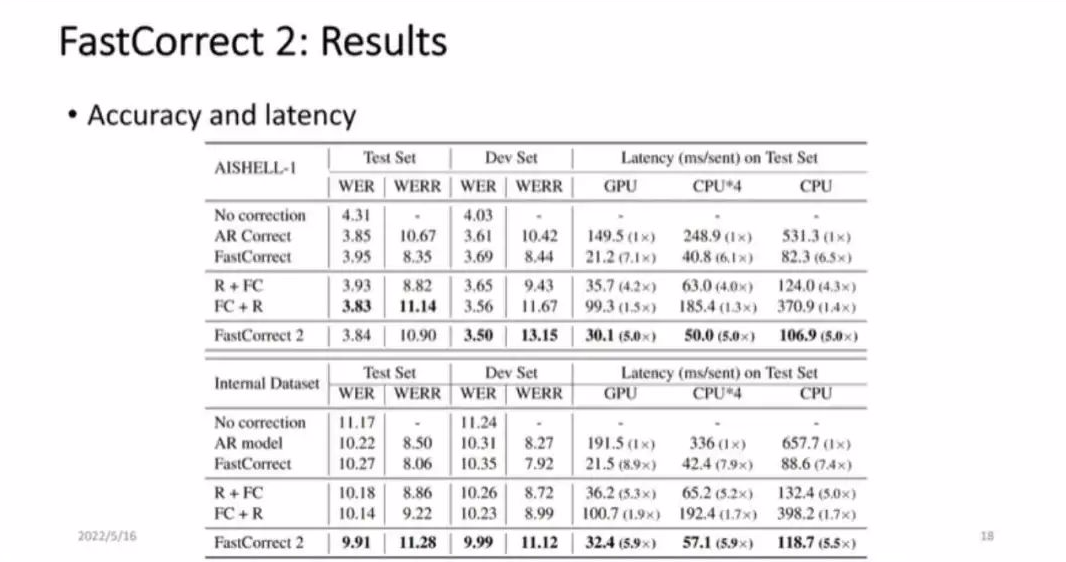
■图 9
最后可以看到,FastCorrect 2 的效果比 FastCorrect 1 好,因为它利用了更多的信息,在词错误率方面,FastCorrect 2 能继续下降两个多 WERR,同时速度也能得到比较好的维持。从图 9 中可以看出,R+FC 的方法更有优势,但是代价较大,因为要对多个 candidate 分别进行纠错,再进行 reranking,所以不能选用这样的方法,最终还是选择 FastCorrect 2 的策略。
在数据集中进行 Align 的过程中,可以考虑将发音比较近的词 Align 在一起,比如在之前提到的例子中,如何将 I have hat 和 I have cat 中的 cat 和 hat Align 在一起呢?此时有一个很重要的要素,就是发音音标的相似度。hat 和 cat 的发音是很接近的,优先考虑这样的发音相似度相近的词,能更好地构造 Align 关系。那么如果不考虑发音相似度,WER 是否会下降呢?如图 10 所示,发现去掉发音相似度以后,WER 确实略有下降。可见,如果语言模型中的词容易搭配,可以优先将这些词放在一起进行 Align,另外,注意到使用 Naive padding 方式此时是不合理的。
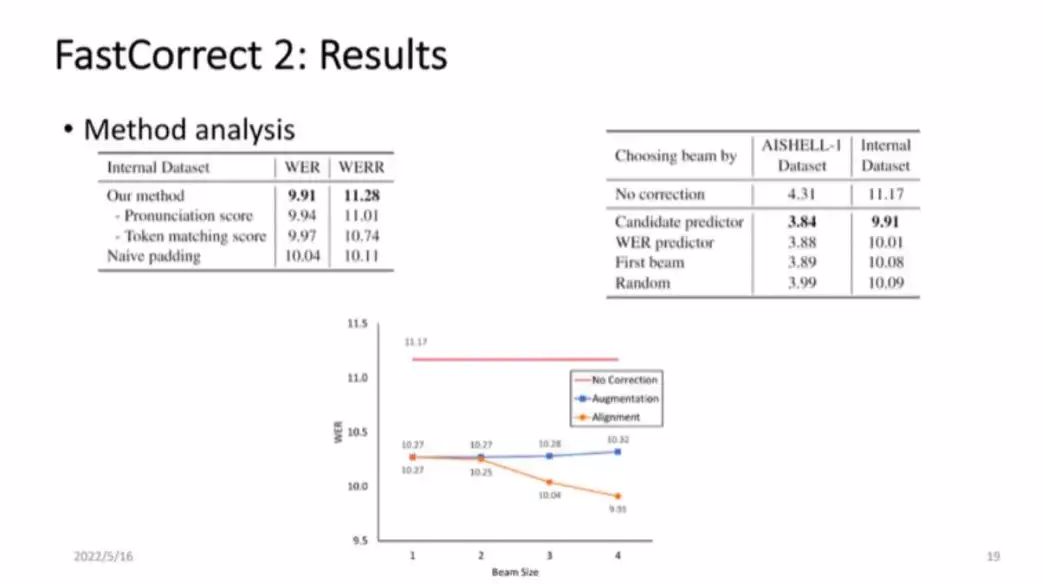
■图 10
我们将多个 candidate 作为输入进行纠错,那么是不是利用的 candidate 越多越好呢?实验证明 candidate 越多,时延会越差。从图 9 可以看到,candidate 增多,最终会面临 accuracy 和 latency 的 trade off。
有人可能会质疑这是不是由于数据变多造成的?因为相比以前的 one best correction 额外利用了多个 candidate 的句子输入作为模型的训练。为此,我们做了一个对比,就是把句子拆散,比如四个 candidate 对应一个正确的句子,将其拆成四个 pair,每个 pair 都是有一个 candidate 对应正确的句子,这样数据量就加大了四倍。但实际发现这种方法并不能降低错误率,反而会增加错误率。表明数据增多不是导致这种结果的原因,而是通过合理的 alignment 提供信号后使纠错效果更好了。
针对语音识别中如何降低错误率并提升精度的问题,在线上时延能够接受的情况下,我们开展了 FastCorrect 系列工作,如图 11 所示,FastCorrect 1 和 FastCorrect 2 分别在学术数据集和微软的内部产品数据集中,取得了比较好的效果,同时相对自回归纠错模型的错误率降低。大家如果感兴趣可以关注我们的 GitHub,我们当前还在基于这个问题进行一些分析设计,利用方法相关的 insight 构建 FastCorrect 3 模型,实现更好的错误检测和错误纠正能力。

■图 11
05 微软在语音领域的研究成果和项目介绍
微软在整个语音方面还开展了一系列的研究,如图 12 所示,包括语音合成的前端文本分析、语音合成低资源数据的建模,以及如何在线上部署时提升 inference 的速度、如何提升语音合成中的鲁棒性、如何推广语音合成能力等。

■图 12
此外,我们还对语音合成场景进行了扩展,比如 talking face generation,输入语音,输出则是说话人脸以及手势等视频;我们还进行人声和器乐的声音合成,并在 TTS 领域开展了详细的 survey 工作,同时举办了 tutorial 演讲教程。近期,我们开发了一个语音合成系统 NaturalSpeech,生成的语音能达到人类水平,如果大家对语音合成感兴趣,可以多多交流。
微软在 AI 音乐方面也开展了一些工作,比如传统的音乐信息检索理解任务,以及音乐生成任务(包括词曲创作、伴奏生成、编曲、音色合成以及混音)等。如果大家对 AI 音乐感兴趣,也可以关注我们的开源项目,具体如图 13 所示。微软在语音 Azure 方面提供了语音合成、语音识别、语音翻译等服务,如果大家感兴趣,也可以通过图 14 所示的网站进行使用。

■图 13

■图 14
微软亚洲研究院机器学习组目前正在招聘正式的研究员和研究实习生,招聘方向包括语音、NLP、机器学习以及生成模型等,欢迎大家加入我们!

06 问答环节
1、FastCorrect 与 BART 的关系和区别
BART 是 NLP 中的预训练模型,用于序列到序列任务,它可以进行机器翻译,应用于任何与文本相关的序列到序列学习的任务。文本纠错任务本身也属于序列到序列学习,它是传统的自回归方法。在传统方法领域,BART 可以直接使用,因为它也是通过自回归的方式解码。而 FastCorrect 解决了自回归方法的解码速度较慢的问题,它是一个非自回归模型,不像 BART 一样逐字读取,而是一次性读取整个句子,这样提升了线上 inference 速度,这也是我们的设计核心,所以从这个角度来说两者有较大的不同。
2、对于纠错有没有针对性的设计?
除了通用的语音识别模型,我们还有很多定制化的场景,对于这些场景来说,其中的数据包含大量专业词汇。为了取得更好的识别效果,在纠错的时候可以引入增强的知识库或者适配的操作。假设通用的语音识别模型要应用在法律、医疗等场景,这些领域包含的专业术语是很少见的,那么可以为语音识别模型提供主题,告知当前识别段落的场景涉及主题的关联词,供模型参考以进行识别。纠错就可以使用这种机制。另外,在中文纠错场景,对齐相对比较容易,但在英文或其他语言中,一个词可能对应另一个词的部分字符,如何针对这些语言设计方法是在适配过程中需要考虑的问题。
关于声网云市场
声网云市场是声网推出的实时互动一站式解决方案,通过集成技术合作伙伴的能力,为开发者提供一站式开发体验,解决实时互动模块的选型、比价、集成、账号打通和购买,帮助开发者快速添加各类 RTE 功能,快速将应用推向市场,节约 95% 集成 RTE 功能时间。
微软实时语音识别(多语种)服务目前已经上架声网云市场。借助该服务,可将音频流实时听录为文本,并可与语音服务的翻译和文本转语音产品/服务无缝地协同工作。
大家可以点击此处立即体验。