什么是xxl-job?
xxl-job是一个分布式的任务调度平台,其核心设计目标是:学习简单、开发迅速、轻量级、易扩展,现在已经开放源代码并接入多家公司的线上产品线,开箱即用。xxl是xxl-job的开发者大众点评的许雪里名称的拼音开头。
xxl-job框架主要用于处理分布式的定时任务,其主要由调度中心和执行器组成。
- 调度模块(调度中心):
负责管理调度信息,按照调度配置发出调度请求,自身不承担业务代码。调度系统与任务解耦,提高了系统可用性和稳定性,同时调度系统性能不再受限于任务模块;
支持可视化、简单且动态的管理调度信息,包括任务新建,更新,删除,GLUE开发和任务报警等,所有上述操作都会实时生效,同时支持监控调度结果以及执行日志,支持执行器Failover。 - 执行模块(执行器):
负责接收调度请求并执行任务逻辑。任务模块专注于任务的执行等操作,开发和维护更加简单和高效;
接收“调度中心”的执行请求、终止请求和日志请求等。
总结:
调度中心:统一管理任务调度平台上的调度任务,负责触发调度执行,并且提供任务管理平台。
执行器:接收调度中心的调度并且执行,可以直接执行也可以集成到项目中。
调度中心和执行器两个模块分开部署,相互分离,两者之间通过RPC进行通信,其中调度中心主要是提供一个平台,管理调度信息,发送调度请求,自己不承担业务代码,而执行器接受调度中心的调度执行业务逻辑。
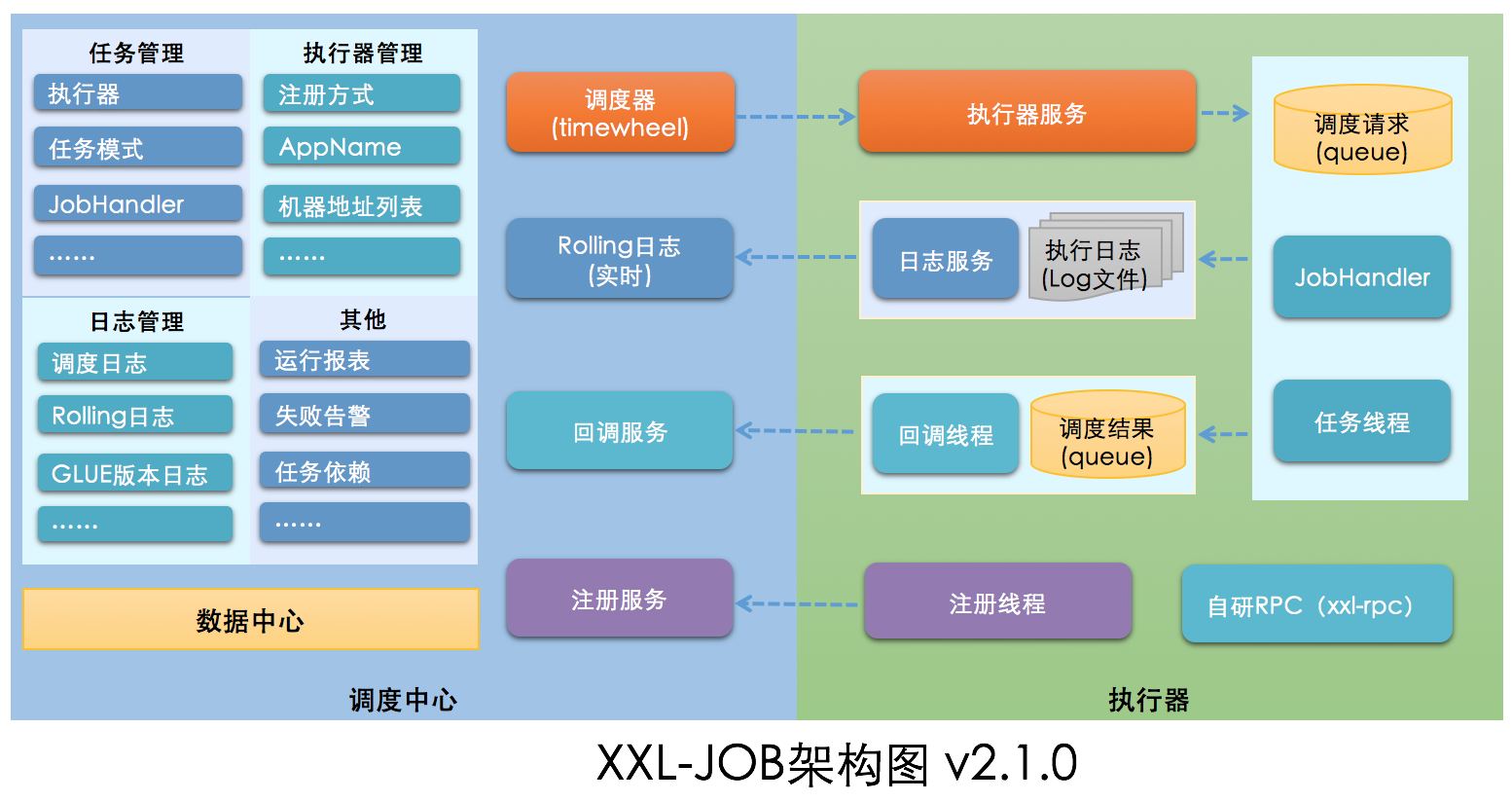
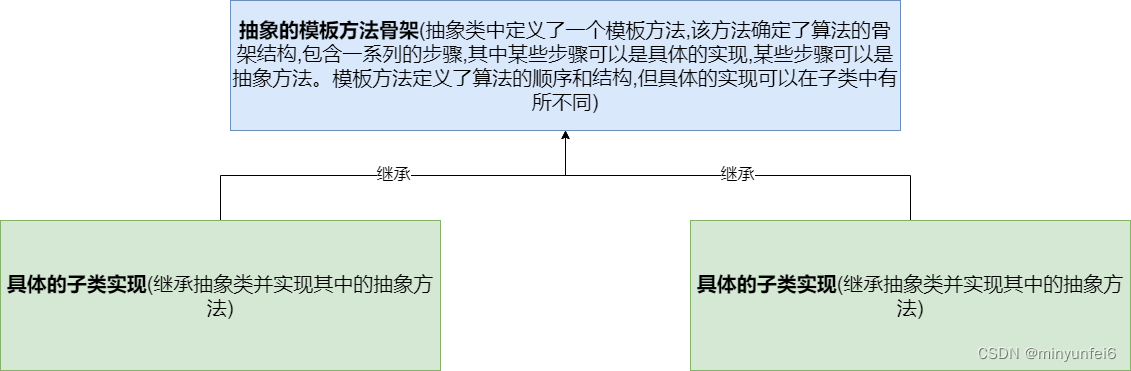
xxl-job的原理
-
执行器的注册和发现
执行器的注册和发现主要是关系两张表:
xxl_job_registry:执行器的实例表,保存实例信息和心跳信息,xxl_job_group:每个服务注册的实例列表。
执行器启动线程每隔30秒向注册表xxl_job_registry请求一次,更新执行器的心跳信息,调度中心启动线程每隔30秒检测一次xxl_job_registry,将超过90秒还没有收到心跳的实例信息从xxl_job_registry删除,并更新xxl_job_group服务的实例列表信息。
-
调度中心调用执行器
调度中心的操作:
调度中心通过循环不停的:
-
关闭自动提交事务
-
利用mysql的悲观锁,其他事务无法进入
select * from xxl_job_lock where lock_name = 'schedule_lock' for update -
读取数据库中的xxl_job_info:记录定时任务的相关信息,该表中有trigger_next_time字段表示下一次任务的触发时间。拿到距离当前时间5s内的任务列表,分为三种情况处理:
-
对于当前时间-任务的下一次触发时间>5,直接调过不执行,重置trigger_next_time的时间。(超过5s)
-
对于任务的下一次触发时间<当前时间<任务的下一次触发时间+5的任务(不超过5s的):
-
开线程处理执行触发逻辑,根据当前时间更新下一次任务触发时间
-
如果新的任务下一次触发时间-当前时间<5,放到时间轮中,时间轮是一个map:
private volatile static Map<Integer, List<Integer>> ringData = new ConcurrentHashMap<>(); -
根据新的任务下一次触发时间更新下下一次任务触发时间
-
-
对于任务的下一次触发时间>当前时间,将其放入时间轮中,根据任务下一次触发时间更新下下一次任务触发时间
-
-
commit提交事务,同时释放排他锁
执行器的操作:
- 执行器接收到调度中心的调度信息,将调度信息放到对应的任务的等待队列中
- 执行器的任务处理线程从任务队列中取出调度信息,执行业务逻辑,将结果放入一个公共的等待队列中(每个任务都有一个单独的处理线程和等待队列,任务信息放入该队列中)
- 执行器有一个专门的回调线程定时批量从结果队列中取出任务结果,并且回调告知调度中心
-
xxl-job主要解决那些问题?
xxl-job主要用于解决分布式定时任务
类似于xxl-job的有哪些框架?xxl-job有哪些优势?
分布式定时任务指的是运行在分布式集群环境下的调度任务,同一份定时任务部署多份,则同一时刻应当只允许一个定时任务执行。
分布式定时任务调度的框架:quartz、elastic-job、xxl-job
| 功能 | quartz | elastic-job | xxl-job |
|---|---|---|---|
| HA(高可用) | 多节点部署,通过数据库锁来保证只有一个节点执行任务 | 通过zookeeper的注册和发现,可以动态添加服务器,支持水平扩容 | 集群部署 |
| 任务分片 | 不支持 | 支持 | 支持 |
| 文档完善 | 完善 | 完善 | 完善 |
| 管理界面 | 没有 | 有 | 有 |
| 难易程度 | 简单 | 较复杂 | 简单 |
| 公司 | OpenSymphony | 当当网 | 个人 |
| 缺点 | 没有管理界面不支持任务分片,不适用于分布式场景 | 需要引入zookeeper,增加系统复杂度,比较复杂 | 通过获取数据库锁的方式,保证集群中执行任务的唯一性,性能不好 |
-
quartz和xxl-job对比:
- quartz采用api的方式调用任务,不方便,但是xxl-job使用的是管理界面。
- quartz比xxl-job代码侵入更强
- quartz调度逻辑和QuartzJobBean耦合在一个项目中,当任务增多,逻辑复杂的时候,性能会受到影响
- quartz底层以抢占式获取db锁并且由抢占成功的节点运行,导致节点负载悬殊非常大;xxl-job通过执行器实现协同分配式运行任务,各个节点比较均衡。
-
elastic-job和xxl-job对比:
elastic-job是无中心化的,通过zookeeper的选举机制选出主服务器,如果主服务器挂了,重新选举出主服务器,因此elastic-job的扩展性和可用性较好,但是使用有一定的复杂度。使用于业务复杂,业务量大,服务器多。
xxl-job是中心式的调度平台调度执行器执行任务,使用的是DB锁来保证集群分布式调用的一致性,学习简单,操作容易,成本不高。
如何使用xxl-job?
-
准备阶段:
源码仓库地址:https://github.com/xuxueli/xxl-job
中央仓库地址:
<!-- http://repo1.maven.org/maven2/com/xuxueli/xxl-job-core/ --> <dependency> <groupId>com.xuxueli</groupId> <artifactId>xxl-job-core</artifactId> <version>${最新稳定版本}</version> </dependency>环境:
- Maven3+
- Jdk1.8+
- Mysql5.7+
-
快速入门
-
源码下载解压,用idea打开,结果如图:

文件介绍:
- doc :文档资料
- xxl-job-admin :调度中心,项目源码
- xxl-job-core :公共Jar依赖
- xxl-job-executor-samples :执行器,Sample示例项目(大家可以在该项目上进行开发,也可以将现有项目改造生成执行器项目)
-
初始化数据库,运行doc/db/tables_xxl_job.sql中的sql生成数据库和表,如图:
-

数据库中表介绍:
- xxl_job_group:执行器信息表,维护任务执行器信息;
- xxl_job_info:调度扩展信息表: 用于保存XXL-JOB调度任务的扩展信息,如任务分组、任务名、机器地址、执行器、执行入参和报警邮件等等;
- xxl_job_lock:任务调度锁表;
- xxl_job_log:调度日志表: 用于保存XXL-JOB任务调度的历史信息,如调度结果、执行结果、调度入参、调度机器和执行器等等;
- xxl_job_log_report:调度日志报表:用户存储XXL-JOB任务调度日志的报表,调度中心报表功能页面会用到;
- xxl_job_logglue:任务GLUE日志:用于保存GLUE更新历史,用于支持GLUE的版本回溯功能;
- xxl_job_registry:执行器注册表,维护在线的执行器和调度中心机器地址信息;
- xxl_job_user:系统用户表;
-
调度中心配置及部署
-
调度中心配置文件地址:/xxl-job/xxl-job-admin/src/main/resources/application.properties
配置文件的配置及说明:
### 调度中心JDBC链接 spring.datasource.url=jdbc:mysql://127.0.0.1:3306/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai spring.datasource.username=root spring.datasource.password=root spring.datasource.driver-class-name=com.mysql.jdbc.Driver ### 报警邮箱 spring.mail.host=smtp.qq.com spring.mail.port=25 spring.mail.username=xxx@qq.com spring.mail.password=xxx spring.mail.properties.mail.smtp.auth=true spring.mail.properties.mail.smtp.starttls.enable=true spring.mail.properties.mail.smtp.starttls.required=true spring.mail.properties.mail.smtp.socketFactory.class=javax.net.ssl.SSLSocketFactory ### 调度中心通讯TOKEN [选填]:非空时启用; xxl.job.accessToken= ### 调度中心国际化配置 [必填]: 默认为 "zh_CN"/中文简体, 可选范围为 "zh_CN"/中文简体, "zh_TC"/中文繁体 and "en"/英文; xxl.job.i18n=zh_CN ## 调度线程池最大线程配置【必填】 xxl.job.triggerpool.fast.max=200 xxl.job.triggerpool.slow.max=100 ### 调度中心日志表数据保存天数 [必填]:过期日志自动清理;限制大于等于7时生效,否则, 如-1,关闭自动清理功能; xxl.job.logretentiondays=30
部署调度中心
-

调度中心访问地址:http://localhost:8080/xxl-job-admin ,默认登录账号 “admin/123456”, 登录后运行界面如下图所示。

调度中心部署总结:
调度中心部署简单方便,耦合性比较低,如果集群部署需要保证其数据库的配置是一样的(保证一致性)和机器时钟保持 一致。
-
执行器配置及部署
-
pom中jar包的引入:
<dependency> <groupId>com.xuxueli</groupId> <artifactId>xxl-job-core</artifactId> <version>2.4.0-SNAPSHOT</version> </dependency> -
执行器配置及说明
### 调度中心部署根地址 [选填]:如调度中心集群部署存在多个地址则用逗号分隔。执行器将会使用该地址进行"执行器心跳注册"和"任务结果回调";为空则关闭自动注册; xxl.job.admin.addresses=http://127.0.0.1:8080/xxl-job-admin ### 执行器通讯TOKEN [选填]:非空时启用; xxl.job.accessToken= ### 执行器AppName [选填]:执行器心跳注册分组依据;为空则关闭自动注册 xxl.job.executor.appname=xxl-job-demo ### 执行器注册 [选填]:优先使用该配置作为注册地址,为空时使用内嵌服务 ”IP:PORT“ 作为注册地址。从而更灵活的支持容器类型执行器动态IP和动态映射端口问题。 xxl.job.executor.address= ### 执行器IP [选填]:默认为空表示自动获取IP,多网卡时可手动设置指定IP,该IP不会绑定Host仅作为通讯实用;地址信息用于 "执行器注册" 和 "调度中心请求并触发任务"; xxl.job.executor.ip= ### 执行器端口号 [选填]:小于等于0则自动获取;默认端口为9999,单机部署多个执行器时,注意要配置不同执行器端口; xxl.job.executor.port=9999 ### 执行器运行日志文件存储磁盘路径 [选填] :需要对该路径拥有读写权限;为空则使用默认路径; xxl.job.executor.logpath=/data/applogs/xxl-job/jobhandler ### 执行器日志文件保存天数 [选填] : 过期日志自动清理, 限制值大于等于3时生效; 否则, 如-1, 关闭自动清理功能; xxl.job.executor.logretentiondays=30 -
执行器中的XxlJobConfig将根据配置文件中配置生成XxlJobSpringExecutor:
@Bean public XxlJobSpringExecutor xxlJobExecutor() { logger.info(">>>>>>>>>>> xxl-job config init."); XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor(); xxlJobSpringExecutor.setAdminAddresses(adminAddresses); xxlJobSpringExecutor.setAppname(appname); xxlJobSpringExecutor.setAddress(address); xxlJobSpringExecutor.setIp(ip); xxlJobSpringExecutor.setPort(port); xxlJobSpringExecutor.setAccessToken(accessToken); xxlJobSpringExecutor.setLogPath(logPath); xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays); return xxlJobSpringExecutor; } -
Bean模式下新建任务:(bean模式:以jobHandler方式维护在执行器端;需要结合JobHandler属性匹配执行器中的任务)
-
类模式
- 继承抽象类IJobHandler中的execute()方法,IJobHandler还有init()和destory()方法,如图:

继承后execute()放入需要执行的业务逻辑,通过XxlJobExecutor.registJobHandler(“JobHandler的名称”,IJobHandler的实例);如图:

- 在调度中心添加调度器实例:

- 在调度中心任务管理模块,添加Cron表达式,路由策略等等信息

- 启动调度中心admin模块和执行器模块,执行器打印结果,本人设置的实例为两个,路由策略为轮询,所以结果如图:

总结:类模式,每个任务对应一个java类-
方式模式(需要在spring的容器中开发job)
-
为Job方法添加注解 “@XxlJob(value=“自定义jobhandler名称”, init = “JobHandler初始化方法”, destroy = “JobHandler销毁方法”)”,注解value值对应的是调度中心新建任务的JobHandler属性的值。如图:

-
在调度中心添加执行器实例
-
在调度中心任务管理中添加调度任务
-

-
启动调度中心和执行器模块
方法模式一个方式表示一个任务。
执行器部署总结:
执行器回调地址保持一致xxl.job.admin.addresses,执行器将会使用该地址进行"执行器心跳注册"和"任务结果回调";为空则关闭自动注册;
同一个执行器集群中xxl.job.executor.appname需要保持一致,配置中心根据该配置发现不同集群在线执行器实例的列表。
附加调度中心新增任务是的路由策略和任务超时时间和失败重试次数:
路由策略:当执行器集群部署时,提供丰富的路由策略,包括; FIRST(第一个):固定选择第一个机器; LAST(最后一个):固定选择最后一个机器; ROUND(轮询):; RANDOM(随机):随机选择在线的机器; CONSISTENT_HASH(一致性HASH):每个任务按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上。 LEAST_FREQUENTLY_USED(最不经常使用):使用频率最低的机器优先被选举; LEAST_RECENTLY_USED(最近最久未使用):最久未使用的机器优先被选举; FAILOVER(故障转移):按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度; BUSYOVER(忙碌转移):按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度; SHARDING_BROADCAST(分片广播):广播触发对应集群中所有机器执行一次任务,同时系统自动传递分片参数;可根据分片 参数开发分片任务; 任务超时时间:支持自定义任务超时时间,任务运行超时将会主动中断任务; 失败重试次数;支持自定义任务失败重试次数,当任务失败时将会按照预设的失败重试次数主动进行重试; -
-
xxl-job的总结
xxl-job是一个中心式分布式的调度平台,调度中心和执行器解耦,执行器和业务代码耦合,代码的侵入性少,学习简单、开发简单、轻量级。
xxl-job的官方文档https://www.xuxueli.com/xxl-job