近日由IEEE主办、被誉为世界范围内最大规模、也是最全面的信号处理及其应用方面的顶级学术会议ICASSP2023于希腊召开,该会议具有权威、广泛的学界以及工业界影响力,备受AI领域多方关注。会上火山语音多篇论文被接收并发表,内容涵盖众多前沿领域的技术创新,并有效解决了字音转换、语种混淆等实践问题。

图片来源:https://2023.ieeeicassp.org/
LiteG2P:一种快速、轻量级、高精度的字音转换模型(LiteG2P: A Fast, Light and High Accuracy Model for Grapheme-to-Phoneme Conversion )
研究背景: 众所周知,字音转换(G2P)旨在将单词转换为其对应的发音表示,通常被广泛应用于语音识别(ASR)及语音合成(TTS)等语音任务中,但现有方法中基于规则的方法预测精度往往较差,还需要大量专家经验的辅助;其中基于数据驱动的深度模型方案虽然精度高,但模型尺寸往往较大且计算效率偏低。对此,火山语音团队提出了一种高效快速、轻量级、高精度的字音转换模型,可进一步适用于多类端侧设备。
方法分析: LiteG2P结合数据驱动和知识驱动的优势,得以在控制模型尺寸较小的同时取得较高精度,模型层面上不同于传统的基于注意力机制的序列到序列预测模型,而是采用CTC损失进行字音的对齐,同时使得模型具备了并行预测音素序列的优势;除此之外,火山语音团队还额外引入了语言知识词典,用以指导字母扩展长度以及缩小目标预测音素集合。

The architecture of LiteG2P
效果呈现: 最终LiteG2P模型相较于主流基线模型具有高精度、并行化、轻量级、快速等优势,与主流基线模型在准确率相当的同时速度提升30倍以上,参数量小10倍以上;可一套模型架构同时部署在端云多种类型设备上,在端侧设备上单个单词的推理速度预测为5ms以内,云端设备2ms以内。
基于双向注意力机制的语音文本的多模态训练提升语音识别性能(SPEECH-TEXT BASED MULTI-MODAL TRAINING WITH BIDIRECTIONAL ATTENTION FOR IMPROVED SPEECH RECOGNITION)
研究背景: 如今,尽管端对端模型简化了训练流程,将声学模型、词典、语言模型合并在一个统一的模型中,但却非常依赖大量的带标签训练数据。相比于带标签数据,不成对的数据,例如纯音频或者纯文本数据更容易获取。为了缓解数据的稀疏性问题,往往会尝试将不成对的数据参与到训练中,有利于在低资源场景下训练出性能良好的端到端语音识别模型。本篇论文正是使用纯文本数据参与端到端模型解码器的训练,使解码器学习到更多的语义信息,从而改善模型性能。此过程需要使用文本编码器去拟合音频编码器的输出,从而解决解码器训练依赖于编码器的问题。由于音频和文本长度不一致,论文提出使用基于双向注意力机制的语音文本的多模态训练方式,自动学习语音和文本之间的对齐关系。
方法分析: 具体方式,语音编码器输出与文本编码器输出经过双向注意力计算后,语音编码器输出长度会缩短到文本长度,文本编码器输出会拓展到音频长度。双向注意力机制的输出会使用Cosine distance loss、MLM loss、Grapheme CTC loss来进行训练,在训练过程中模型会学习到语音和文本之间的对齐,并且语音编码器和文本编码器能学习具备一致性的特征。
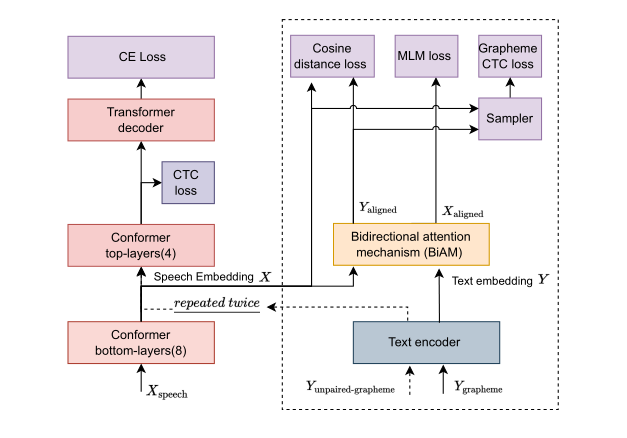
基于语音文本的双向注意机制多模态学习框架
如图所示,虚线框内是训练中增加的模块和损失函数,在解码时不会参与计算,所以不影响解码时期速度。Grapheme CTC loss 的作用是对经过重采样的语音嵌入和文本嵌入进行 Grapheme 的分类,MLM Loss 作用则是使文本编码器能够学习语义信息,Cosine Embedding loss 是为了拉近语音嵌入与文本嵌入之间的距离。这三个损失函数都是建立在双向注意力机制计算出来的、经过对齐的语音嵌入和文本嵌入上,从而隐性让嵌入之间获得对齐。经过语音和文本多模态训练后,文本编码器可以生成接近语音编码器输出的特征,火山语音团队使用纯文本数据送进Text encoder随后重复两次,减小语音和文本之间长度差异,用于解码器的训练,使其学习更多的语义信息。
效果呈现: 经过本论文提出的语音和文本多模态训练方式,在Librispeech公共数据集上获得性能提升,得出仅使用带标签数据训练时,可以实现达6.15%的相对词错误率提升;当使用更多的非配对文本数据时,相对词错误率提升可以达到9.23%。
利用字符级别语种分割减少跨语种语音识别中的语种混淆(Reducing Language Confusion for Code-switching Speech Recognition with Token-level Language Diarization)
研究背景: 通常,语种转换发生在语音信号的语种变换时会导致跨语种语音识别的语种混淆问题。对此,火山语音团队从融合和解耦语种信息两个角度解决语种混淆问题,从而提升跨语种语音识别的性能。
方法分析: 具体来说对于融合语种信息的过程,团队通过使用一个基于序列对序列的语种分割的副任务来生成字符级别的语种后验概率,并使用语种后验概率来动态调整跨语种语音识别模型;相反解耦的过程则是通过对抗减少不同语种间的差别,从而将不同语种归一化。两种不同方法实现构架如下图所示:
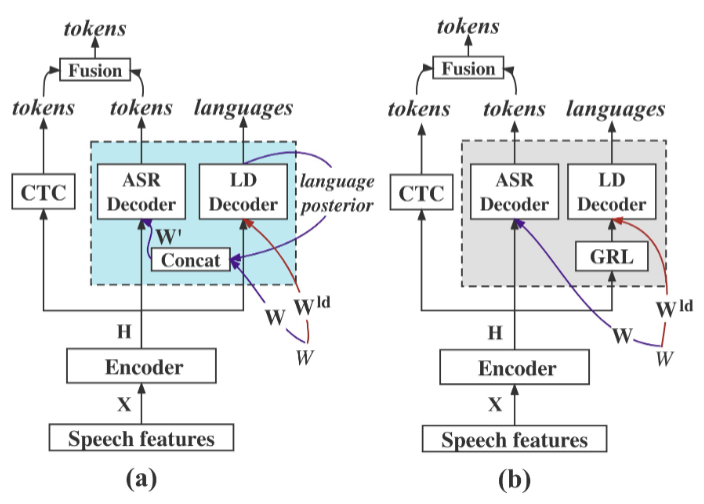
The hybrid CTC/attention model (a) incorporating language information using language posterior bias, and (b) disentangling language via adversarial learning
效果呈现: 我们将提出的方法在SEAME数据集上进行了验证。和基线模型相比,结合了语种分割任务的多任务训练和团队提出的语种后验概率偏置方法均取得了性能提升。“与此同时,将融合和解耦语种信息的两种方法进行了比较,我们发现比较结果表面融合语种信息,可以更有效地提升跨语种的语音识别性能。”团队强调。
一种无需ASR的基于自监督学习的流利度评分方法 (An ASR-free Fluency Scoring Approach with Self-supervised Learning )
研究背景: 口语流利度,即发音语速快慢以及是否出现异常停顿,是反映对应习得语言熟练程度的重要指标之一。此前的大多数判断方法往往需要借助ASR系统获得语音单元(例如单词、音节、音素等)的时间对齐信息,基于此来进一步计算或表示语音流利度的特征,但目标语言的ASR系统并非总能轻易获得以上信息,此外在过程中还会产生不可避免的识别错误。对此火山语音团队提出了一种崭新且无需ASR系统的、基于自监督学习的流利度评分方法,也就是利用自监督预训练语音模型Wav2vec 2.0 产生的帧级语音表征,以及经过聚类算法生成的帧级伪标签,作为后续序列模型的输入,最终完成流利度分数的预测。
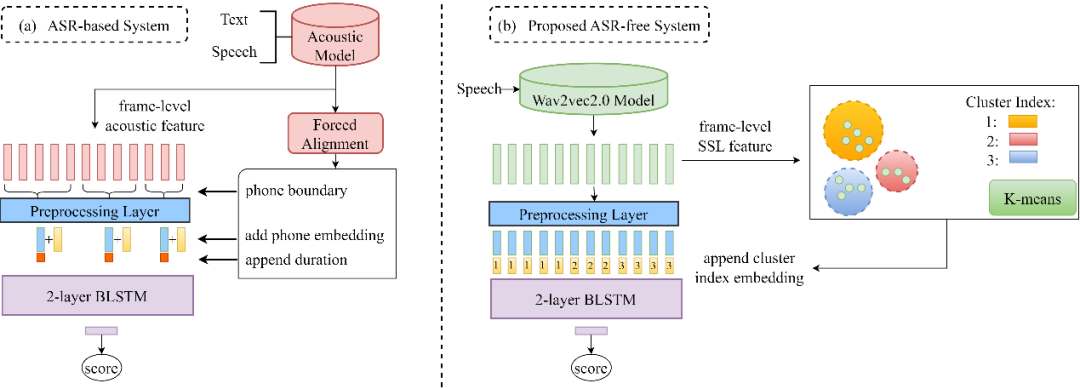
The proposed ASR-free fluency scoring framework
效果呈现: 后续实践结果表示,该方案在机器预测结果和人类专家打分之间的相关性达到了0.797, 明显好于之前依赖ASR系统的方法所达到的0.759。 方案利用了自监督语音特征强大的音素鉴别能力,使用帧级聚类伪标签序列来模拟基于ASR的音素时间对齐,不仅移除了对ASR的依赖而且展现了更可靠的评分性能。
利用音素级别的语言-声学相似度进行句子级别的发音评分 (Leveraging Phone-level Linguistic-Acoustic Similarity for Utterance-level Pronunciation Scoring)
研究背景: 所谓自动发音评分系统往往需要度量学习者实际发音和参考发音的偏离程度来估计整体的发音准确度,但以往方法大多数是通过加和或者连接声学嵌入和音素嵌入等这些隐式方式来实现的。对此,火山语音团队提出了利用音素级别的语言-声学相似度进行句子级别的发音评分方法,相比于隐式的度量方式,通过声学嵌入和音素嵌入的余弦相似度去显式描述实际发音和参考发音的偏离程度的方法效果更好,并将此作为额外特征与原有的两种嵌入序列一起融入后续的序列模型,来完成最终发音准确度的评分。
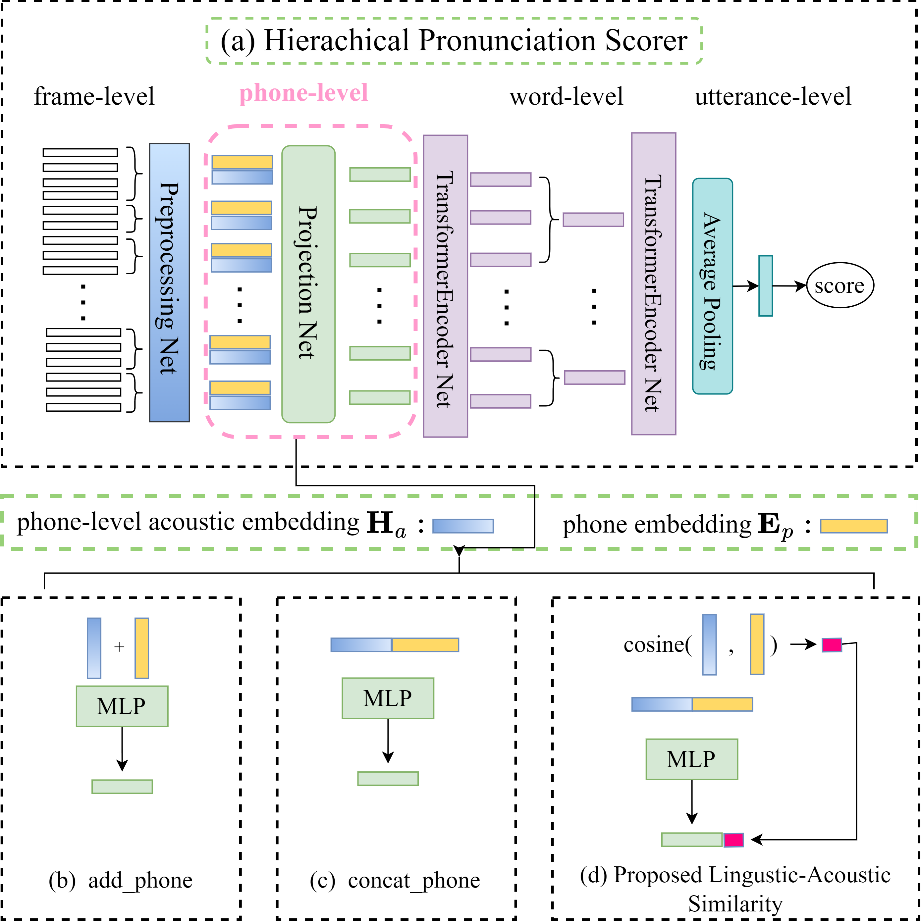
The hierarchical architecture of the pronunciation scoring network, where phone-level features can be calculated by using add\_phone, concat\_phone or our proposed method
效果呈现: 这种显式的度量方法在内部与公开数据集上被证实明显优于以往的加和与连接的隐式度量方法,也就是说基于音素级别GOP的预训练在所有的度量方式上均取得了较大提升;结合语言-声学相似度的显示度量和GOP预训练的打分系统取得了最佳评分性能,其机器预测结果和人类专家打分之间的相关性达到了0.858,显著高于论文报告的多个基线系统。
基于内部语言模型估计的跨域自适应的语言模型融合(Internal Language Model Estimation based Adaptive Language Model Fusion for Domain Adaptation)
研究背景: 只要在通用领域或特定目标领域有足够多的文本,内部语言模型融合就能显著改善端到端语音识别性能。但当一个通用领域商业语音识别系统部署后,由于数据访问受到限制,用户往往只具有与自己相关的特定目标领域文本数据,也就是说由于数据保密等原因,用户不能获取原通用领域文本数据,因此通过内部语言融合的自动语音识别系统只能在用户特定的领域获取性能改善,而在通用领域性能上则会造成损伤、显著降低。 基于上述原因,论文提出一种在用户只具有特定目标领域文本数据前提下,相对传统的内部语言模型估计融合方法,实现在特定领域获取性能显著改善,而在通用领域仍然能取得较好性能的自适应性语言模型融合方法。
方法分析: 该方法基于内部语言模型估计,前提是当一个语音识别系统交付上线后,提供用户访问的子系统有端到端语音识别系统以及内部语言模型。用户只需关注自己特定领域的语言模型,就能获取在特定领域性能明显改善,并且在通用领域性能达到很小损失的结果。具体做法,识别系统在做语言模型融合的时候,比较基于每个子词在内部语言模型和用户特定语言模型的得分,根据大小来决定是否做内部语言模型融合,实现所谓的自适应融合功能。
效果呈现: 为验证该方法的有效性,火山语音团队以10万小时训练得到的中文语音识别系统为通用领域识别系统,另外将医疗和小说搜索定义为特定领域,结果证明可以在特定领域取得18.6% 相对字错误率降低,而在通用领域只有2.4%的相对字错误率的升高。
一直以来,火山语音团队面向字节跳动内部各业务线,提供优质的语音AI技术能力以及全栈语音产品解决方案,并通过火山引擎对外提供服务。自 2017 年成立以来,团队专注研发行业领先的 AI 智能语音技术,不断探索AI 与业务场景的高效结合,以实现更大的用户价值。