文章目录
- 链表(头插法、尾插法、单链表反转)
- 二分查找算法:
- 哈夫曼编码
- 构建链表
- insert()创建链表👇
- 【1】尾插法
- 【2】头插法
- 【3】遍历输出链表
- 【4】输出链表的长度
- 【5】查找链表上是否有该元素
- 【6】指定位置插入数据
- 链表经典面试题
- 【1】返回单链表的后k个节点
- 【2】找到单链表的中间值
- 【3】判断链表是否成环
- 【4】判断成环的节点
- 【5】链表反转
————————————————————————————————
链表(头插法、尾插法、单链表反转)
每一个类是一个对象,
每一个节点的类

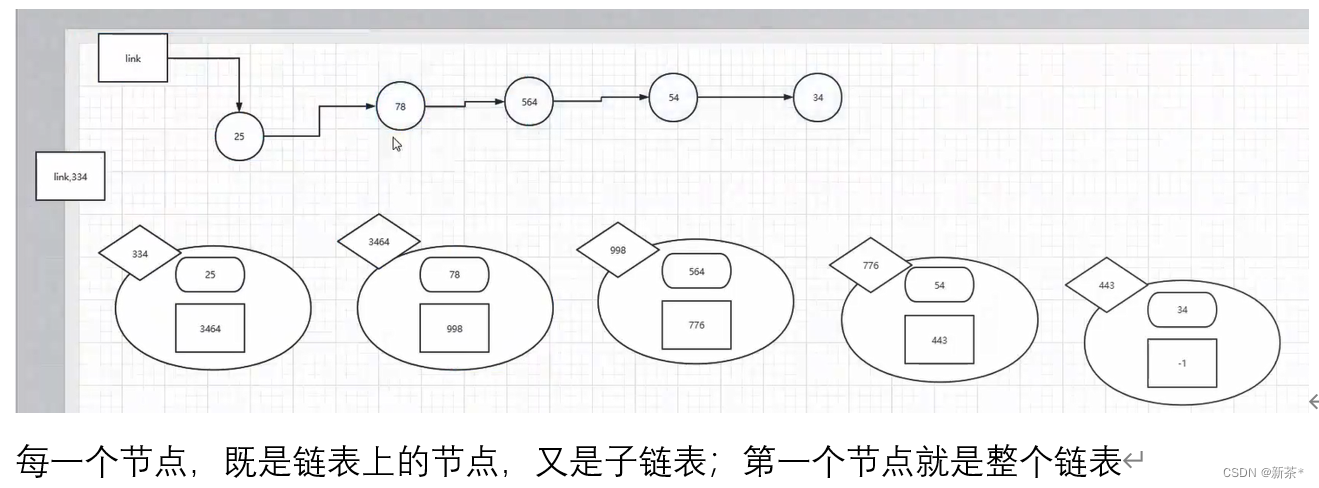
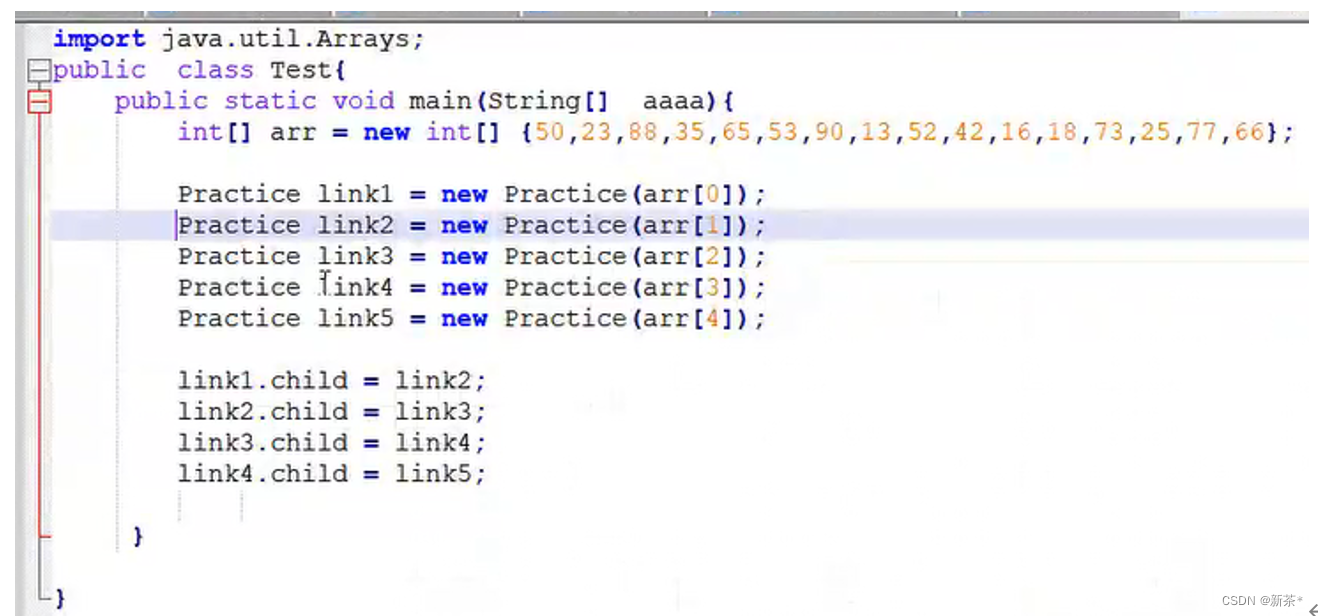
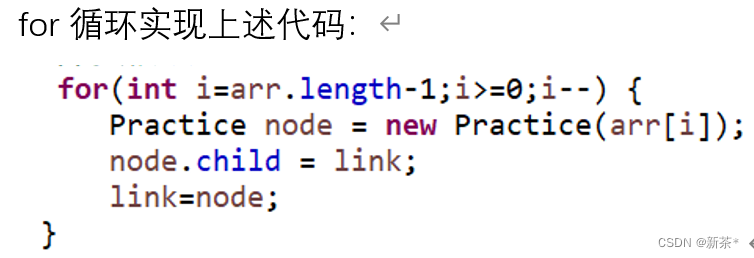
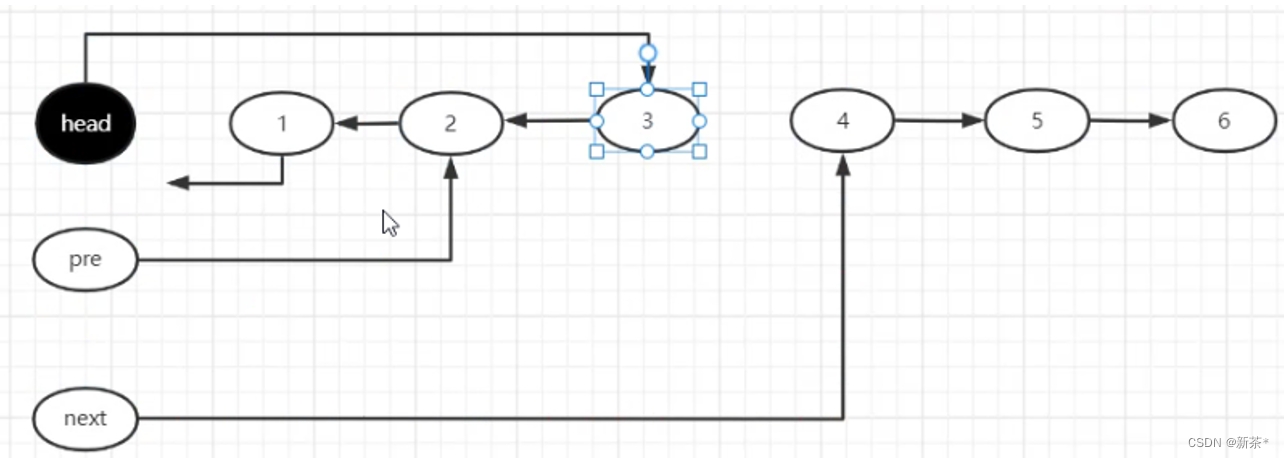
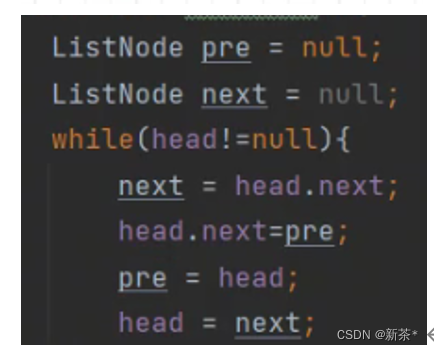
反转链表时注意点:
链表每一个节点必须有指向,否则会被回收
二分查找算法:
二分查找算法:
一个数x先与数组中间的数m比较,
x>m->左边舍弃,m移到右边中间;
x右边舍弃,m移到左边中间;
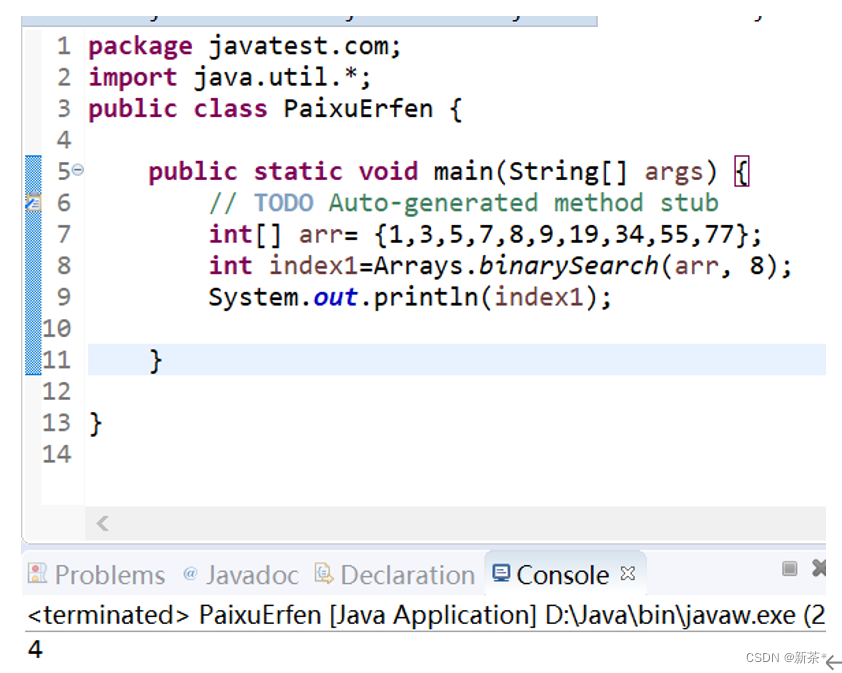
直接使用Arrays.binarySearch();别忘了引入import java.util.*;
代码如下:
哈夫曼编码
应用:压缩
不定长编码:每次都需要重新计算编码,有时间开销;不能用于传输
ascII编码是固定的,是定长编码
编码长度由字符种类决定
哈夫曼树:产生不定长编码又不会重复
先统计某个字符出现的频率,任选两个频率最低的生成两个节点;再选两个最小的
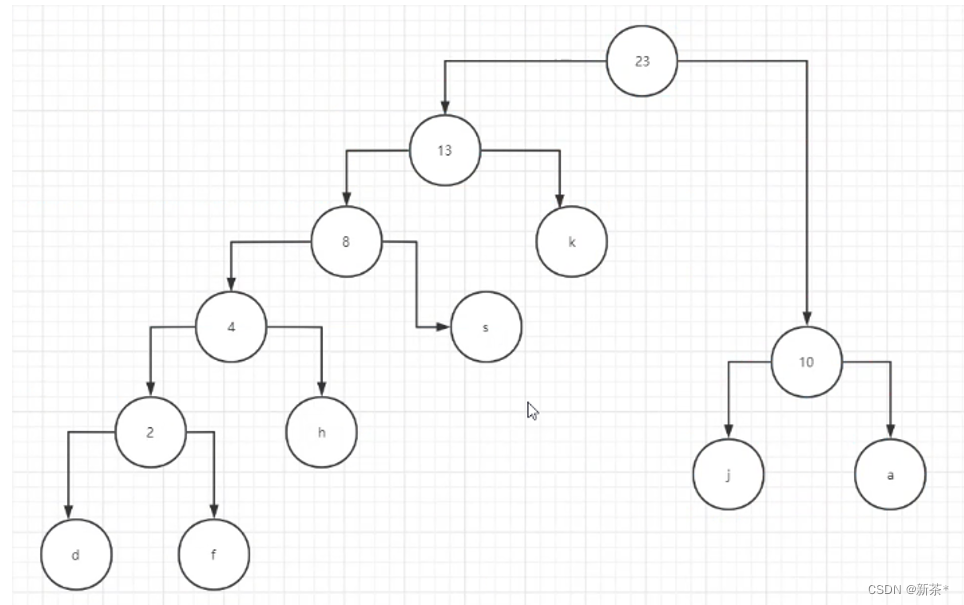
产生树之后,让每个节点的左侧=0,右侧=1(或左侧=1,右侧=0)
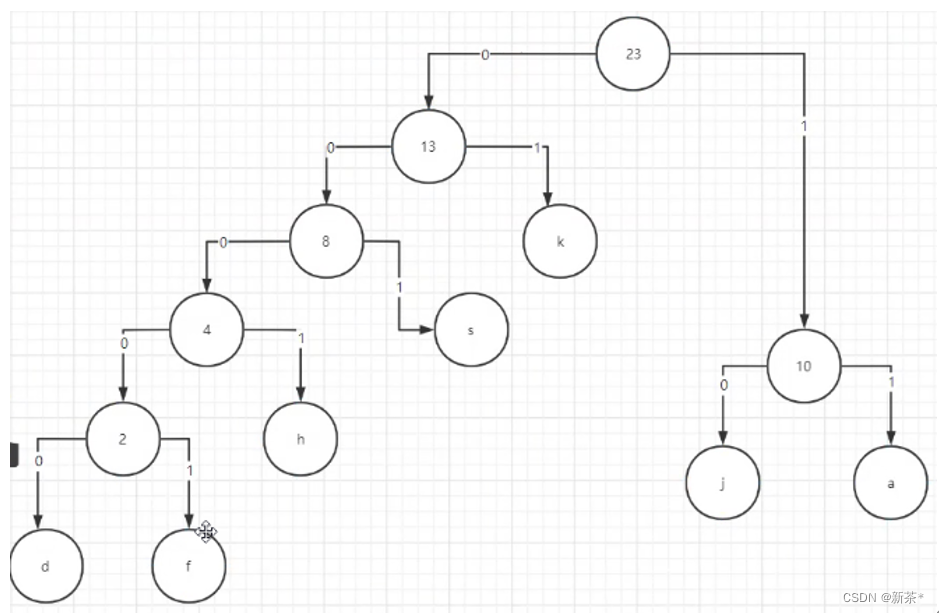
- 根据0和1和从根节点到某一结点的路径就能哈夫曼编码,哈夫曼编码不定长且不会重复
- 由于数据都在叶子节点,所以路径都不会出现包含关系
- 由于选频率最小数据的时候是任选两个,所以会有不同的哈夫曼树,会有不同的哈夫曼编码,但是最终占用存储的结果都是一样的,都是最优树
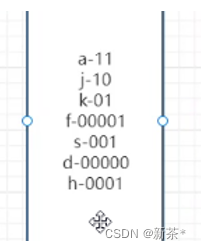
使用:存储的时候把数据换成哈夫曼编码
还原字符串:
先看一个比特,看能不能匹配到,不能就看两个比特,找到就还原,找到一个后,后面的编码重复该过程。
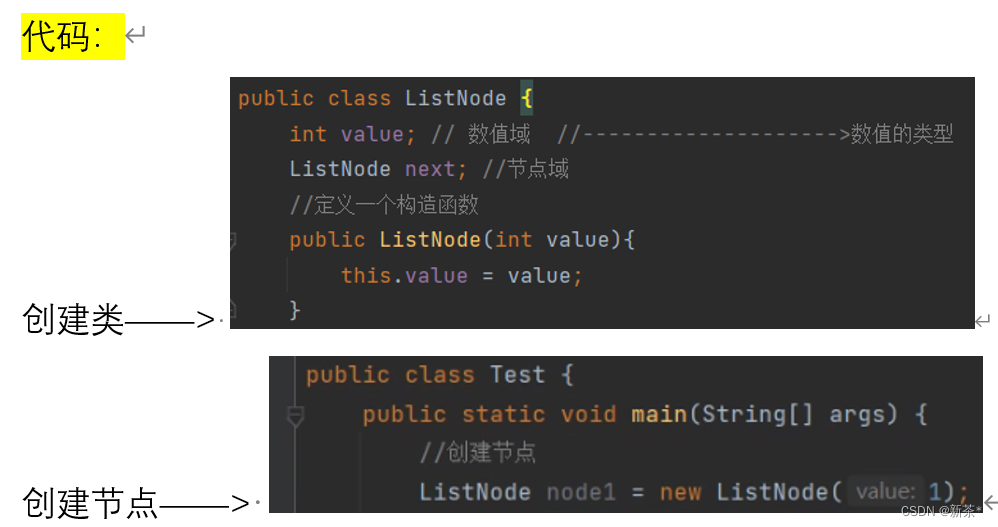
构建链表
构建数组(地址连续):int[] arr=newint[]{ };
链表:节点地址不连续

内存——>构建链表——>如何构建节点
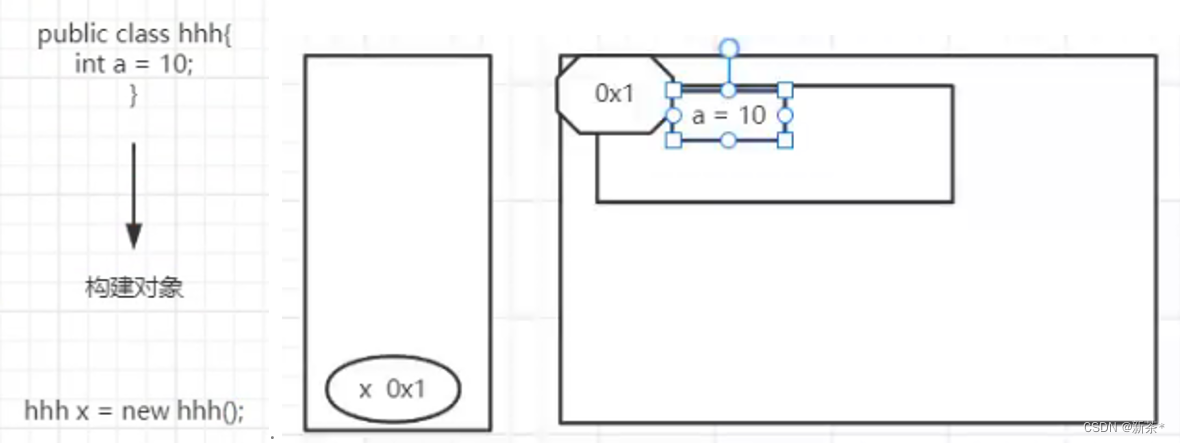
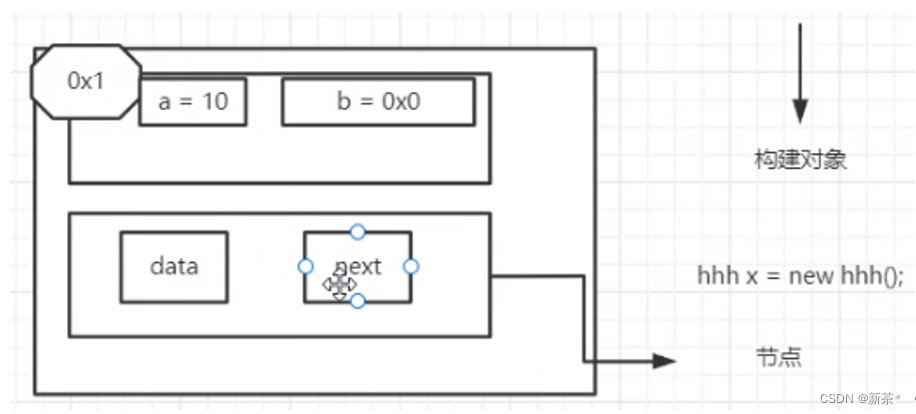
全局变量,存在对象内部👆
Java中节点表示对象,data记录数据,next记录下一个节点的地址👇

问题:👇
为什么节点域是ListNode类型:(和定义的类名保持一致)—>(需要直到java强数据类型知识)。
- 因为next区域存储的是当前下一个节点(对象)的地址——>什么才能存储对象的地址——>(ListNode这个类定义的类型存储对象的地址)
👉ListNode node1= new ListNode(1);—>node1变量之所以能存储对象地址,因为ListNode这个类型定义着我们当前这个对象在内存中开辟什么样的内存空间。所以我们当前next变量的类型只能是List Node
- java的强数据类型:基本上数据类型,引用数据类型——>java为什么定义数据类型——>因为java定义数据类型决定如何开辟内存空间——>定义什么样的数据类型就认为在内存开辟什么样的内存空间(强类型语言在编译时就开辟空间,弱类型语言是在运行期间才开辟空间)
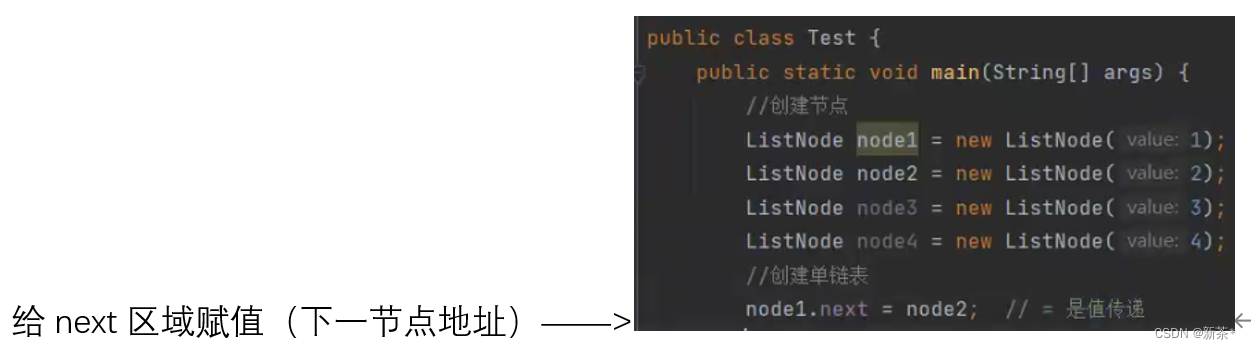
insert()创建链表👇
- 创建链表管理对象👇
创建head头节点(ListNode类型全局变量)、创建链表管理对象:链表记录器;
每次调用方法,都会创建节点,第一个节点的地址赋给head,第二个节点的地址赋给第一个节点的next……,每次调用方法都能新建节点形成链表。
【1】尾插法
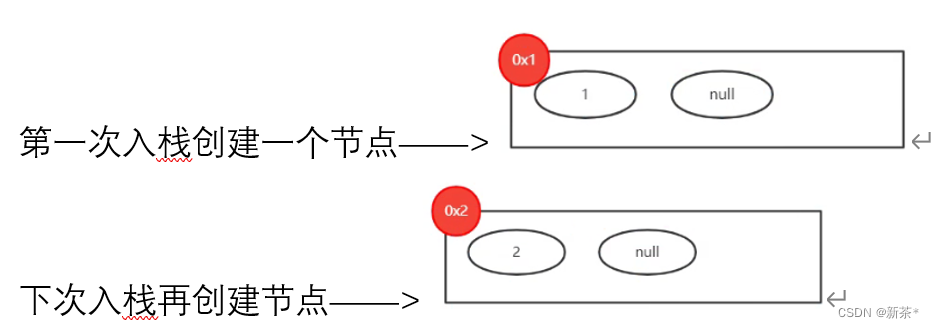
—1—>创建节点
—2—>生成链表:1)判断链表记录器有没有值——没有值: 2)定义游标indexNode
—3—>链表记录器没有值时:第一个节点的地址赋给head;
—4—>链表记录器有值时:head赋给indexNode,相当于让indexNode指向第一个节点,向后遍历链表;
—5—>判断indexNode.next是否为空:
不为空—>将indexNode.next赋给indexNode,实现indexNode游标指向下一个节点,
为空时—>使新节点newNode赋给indexNode.next,实现新节点插在链表尾部
【2】头插法
—1—>创建节点
—2—>生成链表:1)判断链表记录器有没有值——没有值: 2)定义游标indexNode
—3—>链表记录器没有值时:第一个节点的地址赋给head;
—4—>链表记录器有值时:使新节点newNode的next指向head(第一个节点),再让head指向newNode
【3】遍历输出链表
定义游标indexNode指向head,判断游标indexNode是否指向空,不指向空时,输出节点的value,再将indexNode.next赋给indexNode,实现游标向后移动
注意:为什么是indexNode != null,因为如果让indexNode.next != null时,意味着无法遍历到最后一个节点值。
【4】输出链表的长度
遍历时做一个计数器

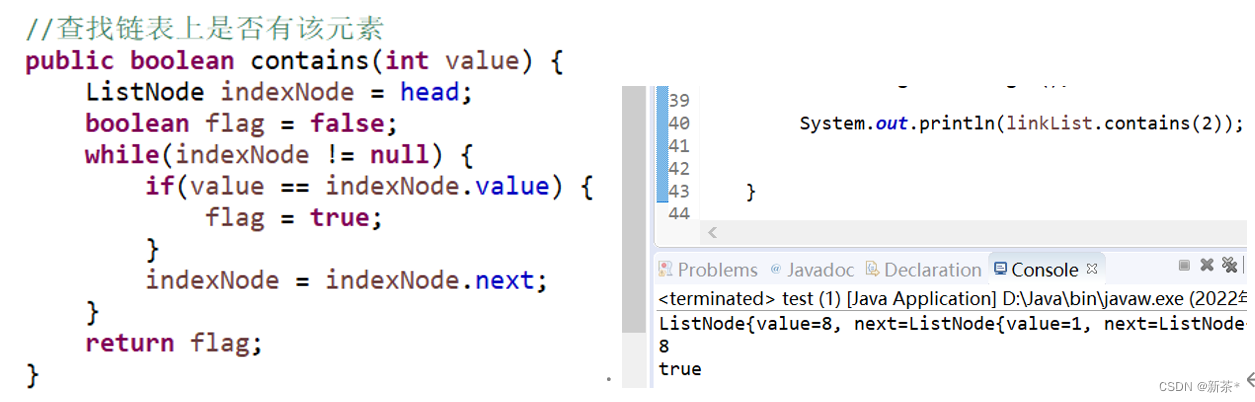
【5】查找链表上是否有该元素
遍历时判断indexNode.value和需要查找的值value是否相等
【6】指定位置插入数据
index0:头插法;index最后:尾插法
index在中间:
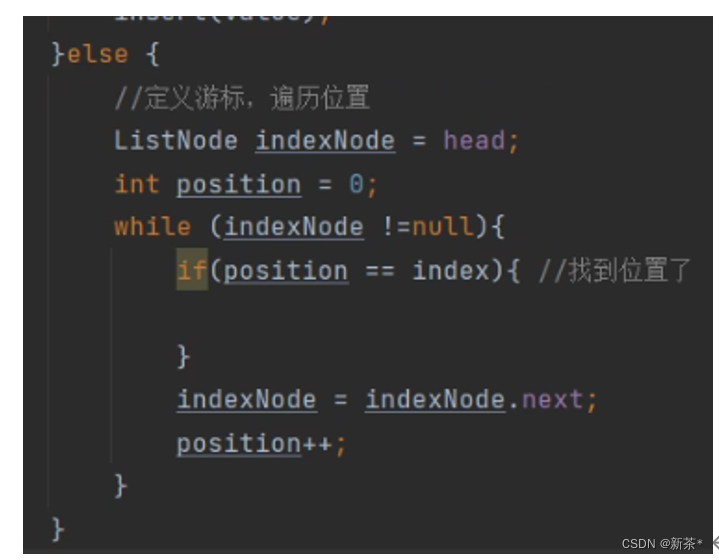
—1—>定义indexNode游标遍历链表
—2—>定义position判断是否找到了位置:没找到就实现indexNode游标向下移动,同时position++;
—3—>定义新游标,指向indexNode的前一个
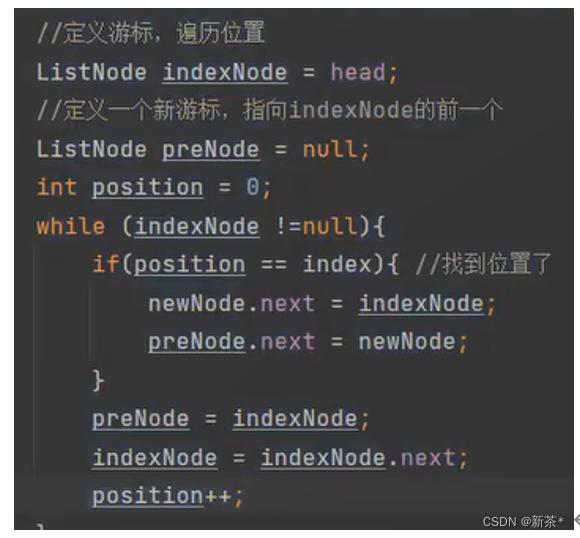
流程:要在2和3之间插入数据,
(1)首先indexNode游标指向第一个节点(head),pre指向indexNode前一个节点(空),position=0;
(2)判断position是否是插入的位置(index),不是就让pre指向indexNode现在指向的,indexNode向下遍历一个(实现pre永远指向indexNode前一个),再让position++;
(3)while循环判断position是否是插入的位置(index),再经过下面操作;
(4)当position==index,实现新节点插入
链表经典面试题
【1】返回单链表的后k个节点

单链表中游标不能向前走
双指针: fast,slow;fast先走k步,然后fast和slow同时走,fast走到最后时,slow后面的就是k个,slow到后面遍历输出
做题步骤:
1)画图分析
2)代码实现:逻辑实现(先按逻辑写伪代码);判断边界条件。
3)测试
【2】找到单链表的中间值
- 双指针:fast走两步,slow走一步
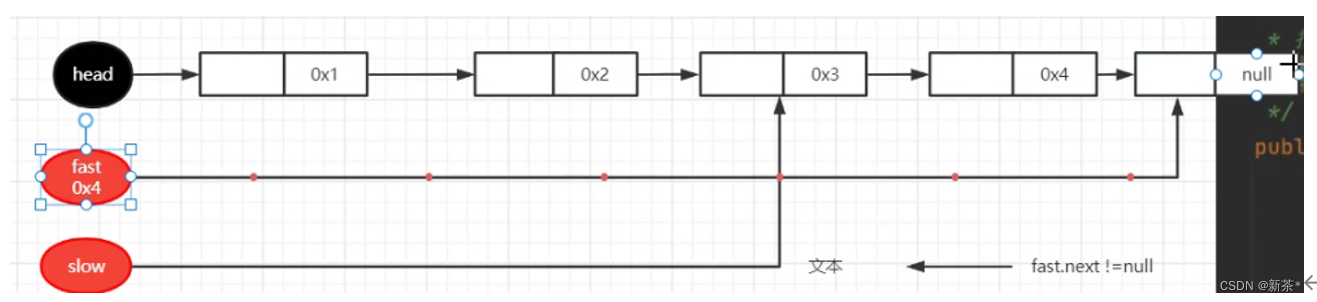
(1)判断条件是fast.next!= null,在奇数正确,在偶数报错:
在偶数的时候,第一个fast.next指向空后,执行第二个fast = fast.next;语句会报错;
(2)判断条件是fast!= null,在偶数正确,在奇数报错
在奇数的时候,第一个fast.next指向空后,执行第二个fast = fast.next;语句会报错;
因此,判断条件要同时满足上面两个,才能保证正确
【3】判断链表是否成环
双指针:fast走两步,slow走一步
如果fast != null && fast.next != null不成立就返回false;
成立就执行slow = slow.next; fast = fast.next.next;
判断fast和slow是否
【4】判断成环的节点
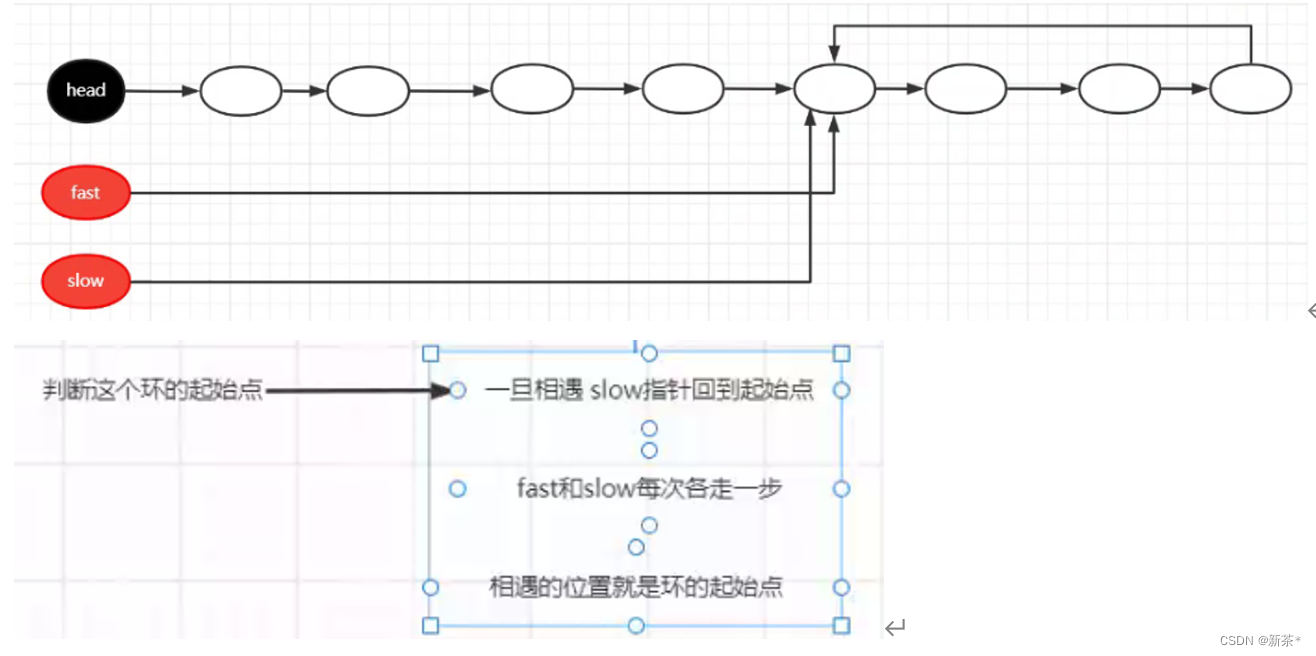
【5】链表反转







![[附源码]计算机毕业设计基于springboot的小区宠物管理系统](https://img-blog.csdnimg.cn/5fd465a2ba824d229b3123c84c3aa17d.png)