目录
前言
一.MySQL 日志管理
数据的重要性
造成数据丢失的原因
1、错误日志
2、通用查询日志
3、二进制日志
4、慢查询日志
5、查看日志
6.中继日志(relay log)
7、普通日志(general log)
配置文件
二、数据库备份的重要性与分类
1、数据备份的重要性
2、从物理与逻辑的角度,备份分为:
3、从数据库的备份策略角度,备份可分为:
三、常见的备份方法
1、物理冷备
2、专用备份工具mydump或mysqlhotcopy
3、启用二进制日志进行增量备份
4、第三方工具备份
四、MySQL完全备份
1、完全备份的概念
2、优点
3、缺点
4、数据库完全备份分类
4.1 物理冷备份与恢复
4.2 mysqldump备份与恢复
4.3增量备份
对比
MySQL完全备份
1、概念
2、特点
Mysql完全备份与恢复
mysqldump备份与恢复
完全恢复
方法一:使用source恢复数据库的步骤
方法二:使用mysql命令,无需登陆mysql数据库
增量恢复
前言
数据传输、数据存储、数据交换、软件故障、硬盘坏道等情况容易产生数据故障。如果没有采取数据备份和数据恢复手段与措施,就会导致数据的丢失。没有数据库的备份,就没有数据库的恢复,企业应当把企业数据备份的工作列为一项不可忽视的系统工作,为其选择相应的备份设备和技术,进行经济可靠的数据备份,从而避免损失。
一.MySQL 日志管理
数据的重要性
- 备份的主要目的是灾难恢复
- 在企业中,数据的安全性至关重要
- 任何数据的丢失都可能产生严重的后果
MySQL 的日志默认保存位置为 /usr/local/mysql/data
MySQL 的日志配置文件为/etc/my.cnf ,里面有个[mysqld]项
修改配置文件:
vim /etc/my.cnf
[mysqld]
造成数据丢失的原因
1、程序错误
2、人为操作错误
3、运算错误
4、磁盘故障
5、灾难 (如火灾、地震) 和盗窃
1、错误日志
错误日志,用来记录当MySQL启动、停止或运行时发生的错误信息,默认已开启
log-error=/usr/local/mysql/data/mysql_error.log #指定日志的保存位置和文件名
2、通用查询日志
通用查询日志,用来记录MySQL的所有连接和语句,默认是关闭的
general_log=ON
general_log_file=/usr/local/mysql/data/mysql_general.log
3、二进制日志
二进制日志(binlog),用来记录所有更新了数据或者已经潜在更新了数据的语句,记录了数据的更改,可用于数据恢复,默认已开启
log-bin=mysql-bin #也可以 log_bin=mysql-bin
4、慢查询日志
##慢查询日志,用来记录所有执行时间超过long_query_time秒的语句,可以找到哪些查询语句执行时间长,以便于优化,默认是关闭的
slow_query_log=ON
slow_query_log_file=/usr/local/mysql/data/mysql_slow_query.log
long_query_time=5 #设置超过5秒执行的语句被记录,缺省时为10秒
systemctl restart mysqld
mysql -u root -p
5、查看日志
show variables like 'general%'; #查看通用查询日志是否开启
show variables like 'log_bin%'; #查看二进制日志是否开启
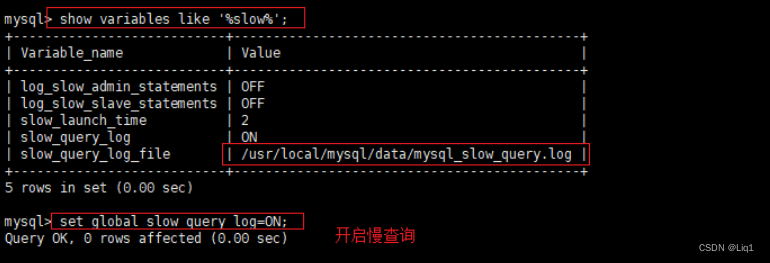
show variables like '%slow%'; #查看慢查询日功能是否开启
show variables like 'long_query_time'; #查看慢查询时间设置
set global show_query_log=ON; #在数据库中设置开启慢查询的方法
6.中继日志(relay log)
作用:用于数据库主从同步,将主库发来的bin log保存在本地,然后从库进行回放
7、普通日志(general log)
作用:记录数据库的操作明细,默认关闭,开启后会降低数据库性能
配置文件
vim /etc/my.cnf
#错误日志
log-error=/usr/local/mysql/data/mysql_error.log
#通用查询日志
general_log=ON
general_log_file=/usr/local/mysql/data/mysql_general.log
#二进制日志
log-bin=mysql-bin
#慢查询日志
slow_query_log=ON
slow_query_log_file=/usr/local/mysql/data/mysql_slow_query.log
long_query_time=5
配置文件添加完后需要重启MySQL
systemctl restart mysql

show variables like 'general%'; #查询通用日志是否开启
show variables like 'log_bin%'; #查询二进制日志是否开启
show variables like '%slow%'; #查询慢查询日志功能是否开启
show variables like 'long%'; #查询慢查询日志超时时间
set global slow_query_log=ON; #在数据库中设置开启慢查询的方法
PS:variables 表示变量 like 表示模糊查询
xxx% 以xxx为开头的字段
%xxx 以xxx为结尾的字段
%xxx% 只要出现xxx字段的都会显示出来
xxx 精准查询

二进制日志开启后,重启mysql会在目录中查看到二进制文件 
二、数据库备份的重要性与分类
1、数据备份的重要性
• 备份的主要目的是灾难恢复
• 在生产环境中,数据的安全性至关重要
• 任何数据的丢失都可能产生严重的后果
造成数据丢失的原因:
♢程序错误
♢人为操作错误
♢运算错误
♢磁盘故障
♢不可控因素
2、从物理与逻辑的角度,备份分为:
• 物理备份: 对数据库操作系统的物理文件(如数据文件、日志文件等)的备份
• 逻辑备份:对数据库逻辑组件(如:表等数据库对象)的备份
♢ 物理备份方法:
▫ 冷备份(脱机备份):是在关闭数据库的时候进行的
▫ 热备份(联机备份):数据库处于运行状态,依赖于数据库的日志文件
▫ 温备份:数据库锁定表格(不可写入但可读)的状态下进行备份操作
3、从数据库的备份策略角度,备份可分为:
• 完全备份:每次对数据库进行完整的备份
• 差异备份:备份自从上次完全备份之后被修改过的文件
• 增量备份:只有在上次完全备份或者增量备份后被修改的文件才会被备份
三、常见的备份方法
1、物理冷备
• 备份时数据库处于关闭状态,直接打包数据库文件
• 备份速度快,恢复时也是最简单的
2、专用备份工具mydump或mysqlhotcopy
• myaqldump常用的逻辑备份工具
• mysqlhotcopy仅拥有备份MyISM和ARCHIVE表
3、启用二进制日志进行增量备份
• 进行增量备份,需要刷新二进制日志
4、第三方工具备份
• 免费MySQL热备份软件Percona XtraBackup
四、MySQL完全备份
1、完全备份的概念
是对整个数据库,数据库结构和文件结构的备份
保存的是备份完成时刻的数据库
是差异备份与增量备份的基础
2、优点
• 备份与恢复操作简单方便
3、缺点
• 数据存在大量的重复
• 占用大量的备份空间
• 备份与恢复时间长
4、数据库完全备份分类
4.1 物理冷备份与恢复
• 关闭MySQL数据库
• 使用tar命令直接打包数据库文件夹
• 直接替换现有MySQL目录即可
4.2 mysqldump备份与恢复
• Mysql自带的备份工具,可方便实现对MySQL的备份
• 可以将指定的库、表导出为SQL脚本
• 使用命令mysql导入备份的数据
4.3增量备份
只有那些在上次完全备份或者增量备份后被修改的文件才会被备份以上次完整备份或上次增量备份的时间为时间点,仅备份期间内的数据变化,因而备份的数据量小,占用空间小,备份速度快
但恢复时,需要从上一次的完整备份开始到最后一次增量备份之间的所有增量依次恢复,如中间某次的备份数据损坏,将导致数据的丢失
每次增量备份都是在备份在上一次完成全备份
每次增量备份都是备份在上一次完全备份或者增量备份之后的数据,不会出现重复数据的情况,也不会占用额外的磁盘空间
恢复数据,需要按照次序恢复完全备份和增量备份的数据
对比
| 备份方式 | 完全备份 | 差异备份 | 增量备份 |
|---|---|---|---|
| 完全备份时的状态 | 表1、表2 | 表1、表2 | 表1、表2 |
| 第1次添加内容 | 创建表3 | 创建表3 | 创建表3 |
| 备份内容 | 表1、表2、表3 | 表3 | 表3 |
| 第2次添加内容 | 创建表4 | 创建表4 | 创建表4 |
| 备份内容 | 表1、表2、表3、表4 | 表3、表4 | 表3、表4 |
MySQL完全备份
1、概念
是对整个数据库、数据库结构和文件结构的备份
保存的是备份完成时刻的数据库
是差异备份与增量备份的基础
2、特点
优点
备份与恢复操作简单
缺点
数据存在大量的重复
占用大量的备份空间
备份与恢复时间长
数据库完全备份分类
1、物理冷备份与恢复(tar)
关闭MySQL数据库
使用tar命令直接打包数据库文件夹
直接替换现有MySQL目录即可
2、mysqldump备份与恢复
MySQL自带的备份工具,可方便实现对MySQL的备份
可以将指定的库、表导出为SQL脚本
使用命令mysql导入备份数据
准备环境
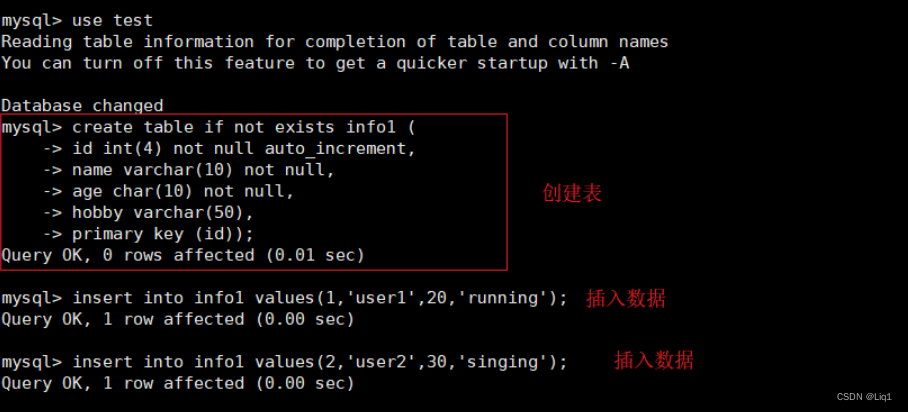
use test;
create table if not exists info1 (
id int(4) not null auto_increment,
name varchar(10) not null,
age char(10) not null,
hobby varchar(50),
primary key (id));
insert into info1 values(1,‘user1’,20,‘running’);
insert into info1 values(2,‘user2’,30,‘singing’);
Mysql完全备份与恢复
InnoDB 存储引擎的数据库在磁盘上存储成三个文件: db.opt(表属性文件)、表名.frm(表结构文件)、表名.ibd(表数据文件)。
systemctl stop mysqld
yum -y install xz 
#压缩备份
tar Jcvf /opt/mysql_all_$(date +%F).tar.xz /usr/local/mysql/data/
mv /usr/local/mysql/data/ /opt/
#解压恢复
tar Jxvf /opt/mysql_all_2022-09-19.tar.xz -C /usr/local/mysql/
cd /usr/local/mysql/data
systemctl start mysqld 
mysqldump备份与恢复
完全备份一个或多个完整的库(包括其中所有的表)
#格式:
mysqldump -u root -p[密码] --databases 库名1 [库名2] … > /备份路径/备份文件名.sql #导出的就是数据库脚本文件
#示例:
mysqldump -u root -pabc123 --databases test > /opt/test.sql #备份一个 test 库
mysqldump -u root -p --databases mysql test > /opt/mysql-test.sql #备份 mysql 与 zone 两个库
完全备份MySQL服务器中所有的库
#格式:
mysqldump -u root -p[密码] --all-databases > /备份路径/备份文件名.sql
#示例:
mysqldump -u root -p --all-databases > /opt/all.sql完全备份指定库中的部分表
mysqldump -u root -p[密码] 库名 [表名1] [表名2] ... > /备份路径/备份文件名.sql
例:
mysqldump -u root -p [-d] test info1 > /opt/test_info1.sql
#使用 "-d" 选项,说明只保存数据库的表结构
#不使用 "-d" 选项,说明表数据也进行备份
#做为一个表结构模板

查看备份文件
grep -v "^--" /opt/test_info1.sql | grep -v "^/" | grep -v "^$"

完全恢复
方法一:使用source恢复数据库的步骤
登录到 MySQL 数据库
执行 source 备份 sql 脚本的路径
#模拟故障
use test;
delete from info1;
#恢复
source /opt/test.sql


方法二:使用mysql命令,无需登陆mysql数据库
使用 -e 选项用于指定连接mysql后执行的命令,删除数据表,执行完自动退出。执行 mysql 备份 sql 脚本的路径
mysql -uroot -pabc123 -e ‘drop database test;’
mysql -uroot -pabc123 -e ‘show databases;’
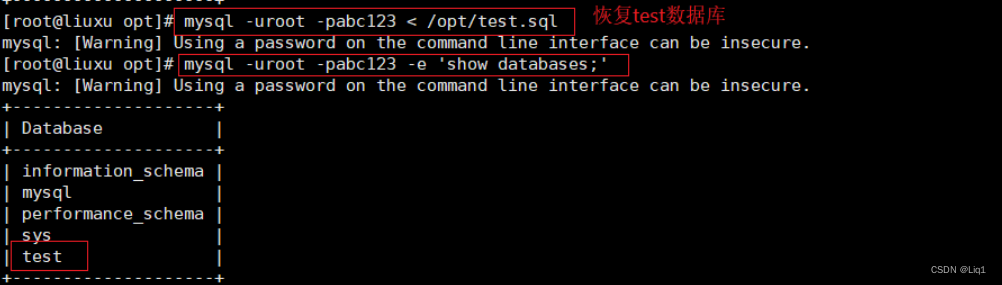
mysql -uroot -pabc123 < /opt/test.sql
mysql -uroot -pabc123 -e ‘show databases;’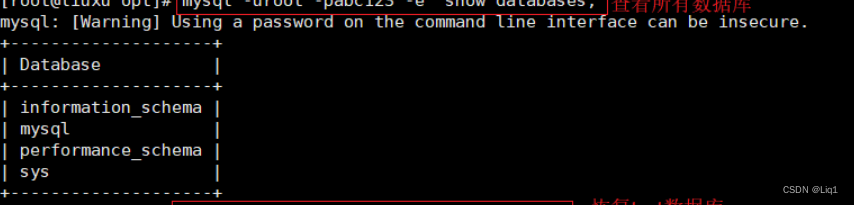
注意:mysqldump严格来说属于温备份,会需要对表进行写入的锁定
在全量备份与恢复实验中,假设现有 test 库,需要注意的一点为:
① 当备份时加 --databases,表示针对于 test 库
备份命令:
mysqldump -uroot -p123456 --databases test > /opt/test_01.sql 备份库后
恢复命令过程为:
mysql -uroot -pabc123;
drop database test;
quit
mysql -uroot -pabc123 < /opt/test_01.sql
② 当备份时不加 --databases,表示针对 test 库下的所有表
备份命令:
mysqldump -uroot -pabc123 test > /opt/test_all.sql
恢复过程:
mysql -uroot -pabc123
drop database test;
create database test;
quit
mysql -uroot -pabc123 test < /opt/test_all.sql
主要原因在于两种方式的备份(前者会从 “create databases” 开始,而后者则全是针对表格进行操作)
Mysql增量备份与恢复
恢复的方式
一般恢复
将所有备份的二进制日志内容全部恢复
基于位置恢复
数据库在某一时间点可能既有错误的操作也有正确的操作
可以基于精准的位置跳过错误的操作
发生错误节点之前的一个节点,上一次正确操作的位置点停止
基于时间点恢复
跳过某个发生错误的时间点实现数据恢复
在错误时间点停止,在下一个正确时间点开始
二进制日志(binlog)的三种不同记录格式
STATEMENT(基于SQL语句)、ROW(基于行)、MIXED(混合模式),默认为STATEMENT
vim /etc/my.cnf

STATEMENT(基于SQL语句)
每一条涉及到被修改的sql都会记录在binlog中
日志量过大,如sleep()函数,last_insert_id()>,以及user-definedfuctions ( udf) 、垂从复制等架构记录日志时会出现问题
增删改查通过sql语句来实现记录,如果用高并发可能会出错,可能时间差异或者延迟,可能不是我们想想的恢复可能你先删除或者在修改,可能会倒过来。准确率低
ROW(基于行)
只记录变动的记录,不记录sql的上下文环境
如果遇到update… …set… . .where true那么binlog的数据量会越来越大
update、 delete以多行数据起作用,来用行记录下来,只记录变动的记录,不记录sql的上下文环境,比如sql语句记录一行,但是Row就可能记录10行,但是准确性高,高并发的时候由于操作量能变低比较大所以记录都记下来。
MIXED 推荐使用
一般的语句使用STATEMENT,函数使用ROW方式存储。
查看二进制文件内容
cp /usr/local/mysql/data/mysql-bin.000002 /opt/
mysqlbinlog --no-defaults /opt/mysql-bin.000002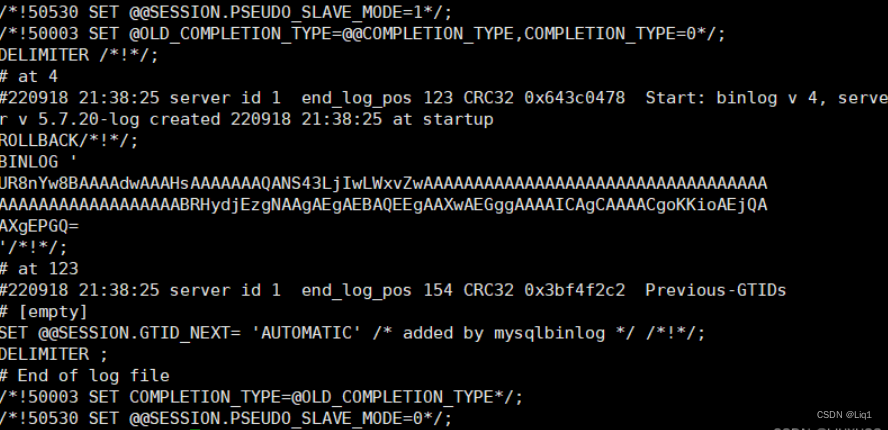
mysqlbinlog --no-defaults --base64-output=decode-rows -v /opt/mysql-bin.000002
#–base64-output=decode-rows:使用64位编码机制去解码(decode)并按行读取(rows)
#-v: 显示详细内容
#–no-defaults : 默认字符集(不加会报UTF-8的错误)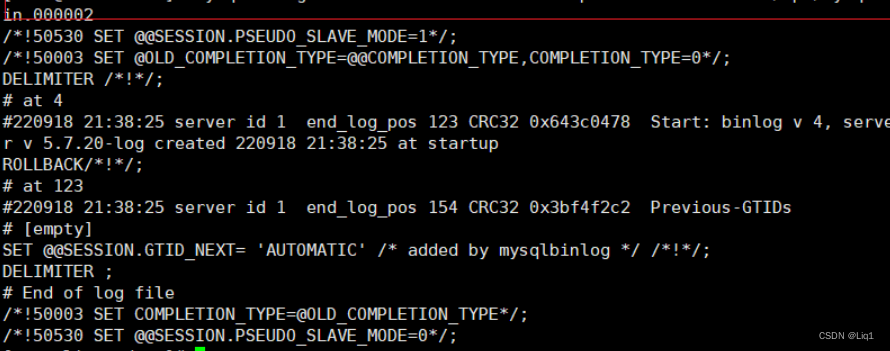
二进制日志中需要关
注的部分
at :开始的位置点
end_log_pos:结束的位置 position (位置点)
时间戳: 220918 21:38:25
SQL语句
增量备份过程(全备+增备)
使用mysqldump
mysqldump -uroot -pabc123 test info1 > /opt/test_info1_$(date +%F).sql
mysqldump -uroot -pabc123 test > /opt/test_all_$(date +%F).sql
mysqldump -uroot -pabc123 --all-databases > /opt/all_$(date +%F).sql

进行增量备份,生成二进制日志文件
每天进行增量备份操作,生成新的二进制日志文件(例如:mysql-bin.000002)
如果刚开启了二进制日志功能,只有 mysql-bin.000001,刷新后就有了 mysql-bin.000002
mysqladmin -u root -pabc123 flush-logs
插入新数据,以模拟数据的增加或变更
在第一次完全备份之后刷新二进制文件,在第二个二进制文件中记载着增量备份的数据
mysql -uroot -pabc123
create database test1;
use test1;
create table class1 (id int(4),name varchar(4));
insert into class1 values(1,‘one’);
insert into class1 values(2,‘two’);
select * from class1;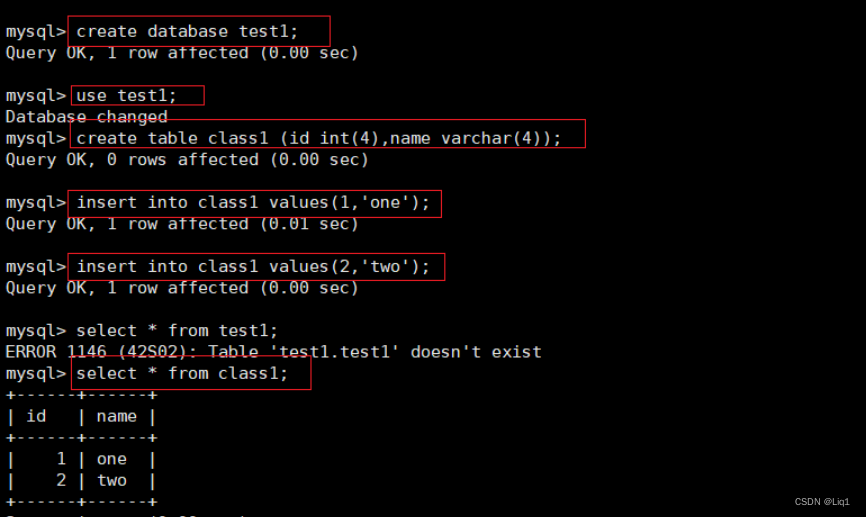
再次生成新的二进制日志文件
mysqladmin -u root -pabc123 flush-logs
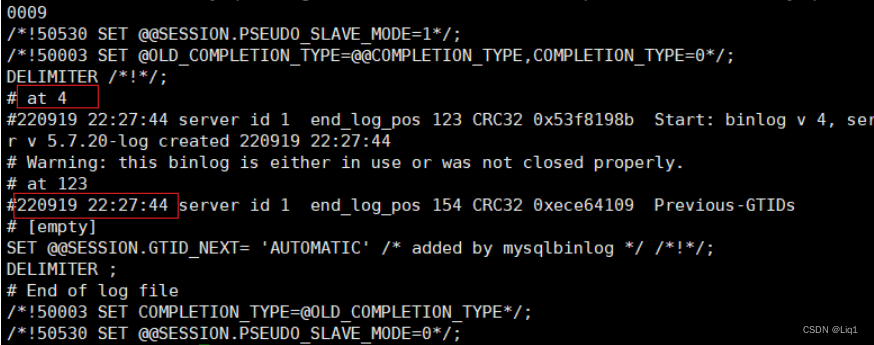
增量恢复
模拟丢失更改的数据的恢复步骤
备份test1库中的class1表
mysql -uroot -pabc123 -e ‘drop database test1’;
#模拟test1.class1 表中的所有数据全部丢失。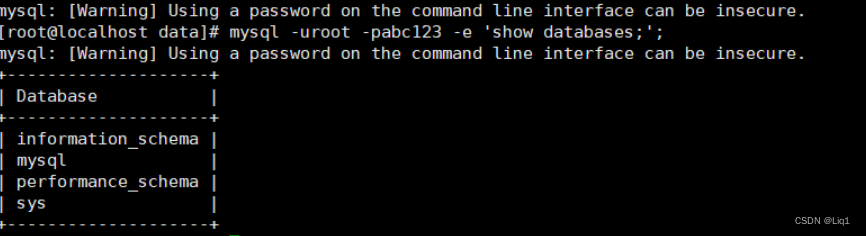
 现在需要还原test1.class1表
现在需要还原test1.class1表
mysqlbinlog --no-defaults /usr/local/mysql/data/mysql-bin.000001 | mysql -uroot -pabc123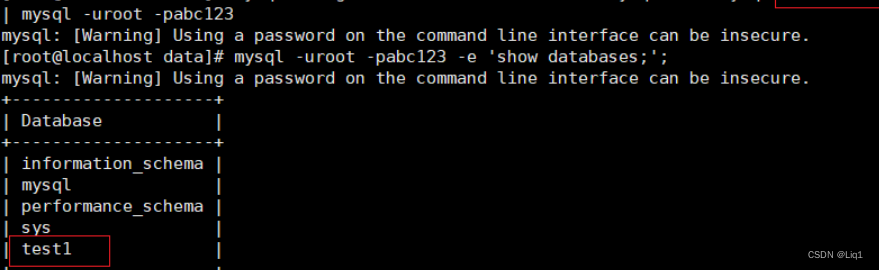
断点恢复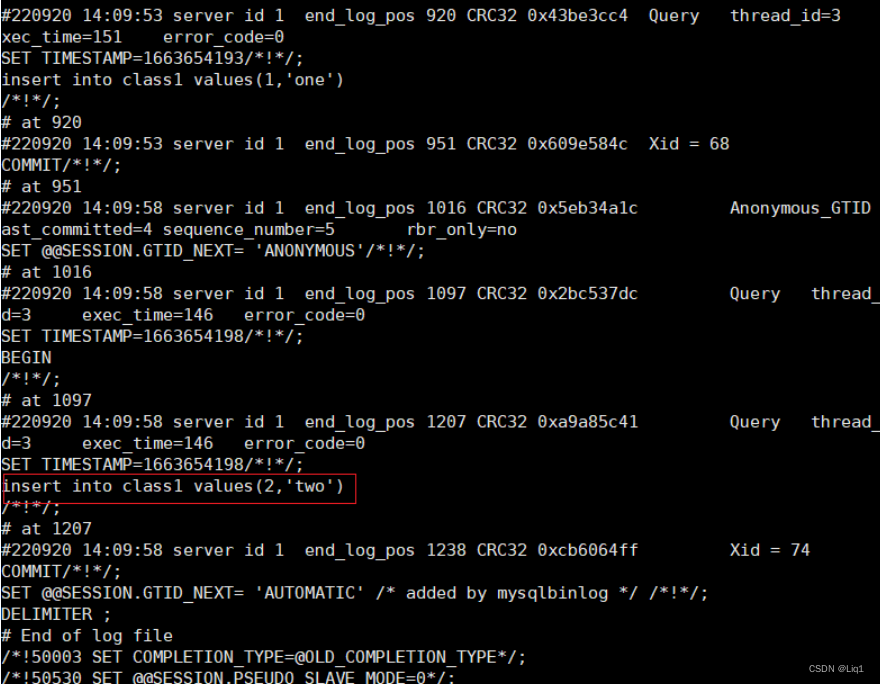
基于节点恢复
mysqlbinlog --no-defaults --start-position=‘379’ --stop-position=‘1097’ /usr/local/mysql/data/mysql-bin.000002 | mysql -uroot -pabc123











![[附源码]Python计算机毕业设计Django三星小区车辆登记系统](https://img-blog.csdnimg.cn/c3e456a4ab5a4908b9489a5828161873.png)