kafka系统的CAP保证
CAP理论作为分布式系统的基础理论,它描述的是一个分布式系统在以下三个特性中:
- 一致性(Consistency)
- 可用性(Availability)
- 分区容错性(Partition tolerance)
最多满足其中的两个特性。也就是下图所描述的。分布式系统要么满足CA,要么CP,要么AP。无法同时满足CAP。
分区容错性:指的分布式系统中的某个节点或者网络分区出现了故障的时候,整个系统仍然能对外提供满足一致性和可用性的服务。也就是说部分故障不影响整体使用。事实上我们在设计分布式系统时都会考虑到bug,硬件,网络等各种原因造成的故障,所以即使部分节点或者网络出现故障,我们要求整个系统还是要继续使用的(不继续使用,相当于只有一个分区,那么也就没有后续的一致性和可用性了)
可用性:一直可以正常的做读写操作。简单而言就是客户端一直可以正常访问并得到系统的正常响应。用户角度来看就是不会出现系统操作失败或者访问超时等问题。
一致性:在分布式系统完成某写操作后任何读操作,都应该获取到该写操作写入的那个最新的值。相当于要求分布式系统中的各节点时时刻刻保持数据的一致性。
分区副本机制
kafka 从 0.8.0 版本开始引入了分区副本;引入了数据冗余
用CAP理论来说,就是通过副本及副本leader动态选举机制提高了kafka的 分区容错性和可用性
但从而也带来了数据一致性的巨大困难!
分区副本的数据一致性困难
kafka让分区多副本同步的基本手段是: follower副本定期向leader请求数据同步!
既然是定期同步,则leader和follower之间必然存在各种数据不一致的情景!
- 问题1:分区副本间动态不一致

- 问题2:消费者所见不一致
如果此时leader宕机,follower1或follower2被选为新的leader,则leader换届前后,消费者所能读取到的数据发生了不一致;

- 问题3:分区副本间最终不一致

一致性问题解决方案(HW)
动态过程中的副本数据不一致,是很难解决的;
kafka先尝试着解决上述“消费者所见不一致”及“副本间数据最终不一致”的问题;
核心思想
- 在动态不一致的过程中,维护一条步进式的“临时一致线”(既所谓的High Watermark);
- 高水位线HW = ISR副本中最小LEO(副本的最大消息位移+1);
- 底层逻辑就是:offset<HW的message,是各副本间一致的且安全的!
- 解决“消费者所见不一致” (消费者只允许看到HW以下的message)
- 解决“分区副本数据最终不一致” (follower数据按HW截断)

HW方案的天生缺陷
如前所述,看似HW解决了“分区数据最终不一致”的问题,以及“消费者所见不一致”的问题,但其实,这里面存在一个巨大的隐患,导致:
- “分区数据最终不一致”的问题依然存在
- producer设置acks=all后,依然有可能丢失数据的问题

第一次fetch请求,分leader端和follower端:
leader端:
- 读取底层log数据。
- 根据fetch带过来的offset=0的数据(就是follower的LEO,因为follower还没有写入数据,因此LEO=0),更新remote LEO为0。
- 一轮结束后尝试更新HW,做min(leader LEO,remote LEO)的计算,结果为0。
- 把读取到的三条log数据,加上leader HW=0,一起发给follower副本。
follower端: - 写入数据到log文件,更新自己的LEO=3。
- 更新HW,做min(leader HW,follower LEO)的计算,由于leader HW=0,因此更新后HW=0。
可以看出,第一次fetch请求后,leader和follower都成功写入了三条消息,但是HW都依然是0,对消费者来说都是不可见的,还需要第二次fetch请求。
第二次fetch请求,分leader端和follower端:
leader端:
- 读取底层log数据。
- 根据fetch带过来的offset=3的数据(上一次请求写入了数据,因此LEO=3),更新remote LEO为3。
- 尝试更新HW,做min(leader LEO,remote LEO)的计算,结果为3。
- 把读取到的log数据(其实没有数据),加上leader HW=3,一起发给follower副本。
follower端: - 写入数据到log文件,没有数据可以写,LEO依然是3。
- 更新HW,做min(leader HW,follower LEO)的计算,由于leader HW=3,因此更新后HW=3。
这个时候,才完成数据的写入,并且分区HW(分区HW指的就是leader副本的HW)更新为3,代表消费者可以消费offset=0,1,2的三条消息了,上面的过程就是kafka处理消息写入和备份的全流程。
HW会产生数据丢失和副本最终不一致问题
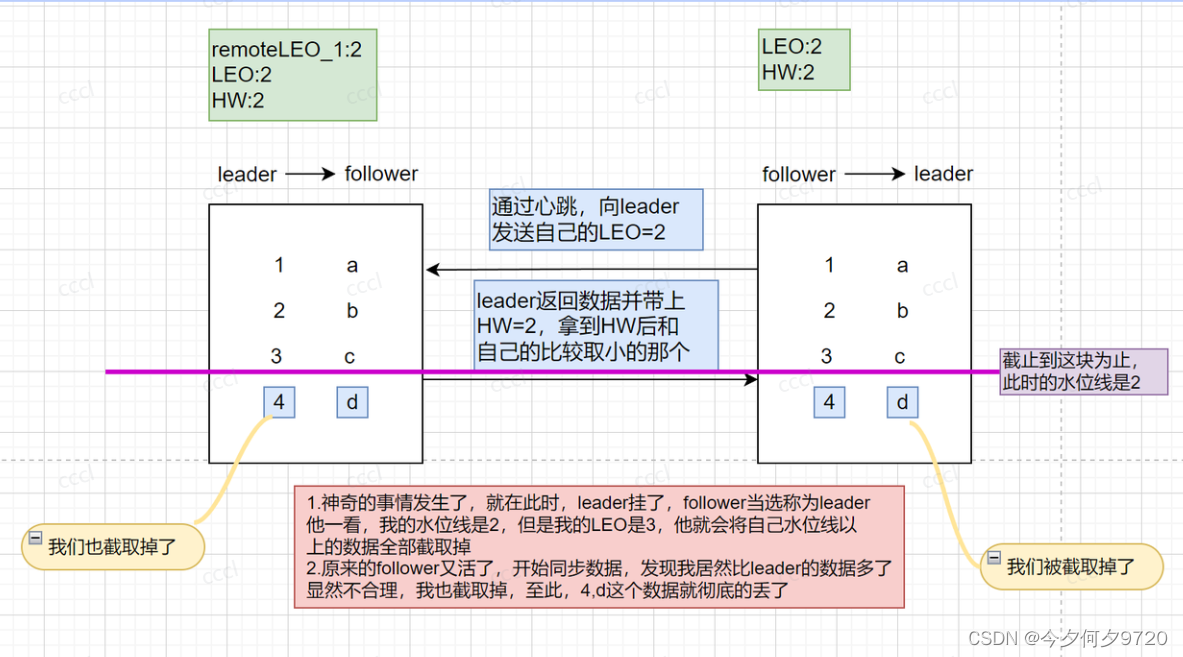
如上图所示:
- 状态起始:最新消息c已同步,但是水位线还没开始同步
- 在此时leader崩溃(即 follower 没能通过下一轮请求来更新 HW 值)
- follower成为了leader,会自动将 LEO 值调整到之前的 HW 值,即会进行日志截断
- 然后,原来的leader重启上线,会向新的leader发送请求请求,收到 fetch 响应后,拿到 HW 值,并更新本地 HW 值,发现我也要截取,悲剧发生了,数据丢了
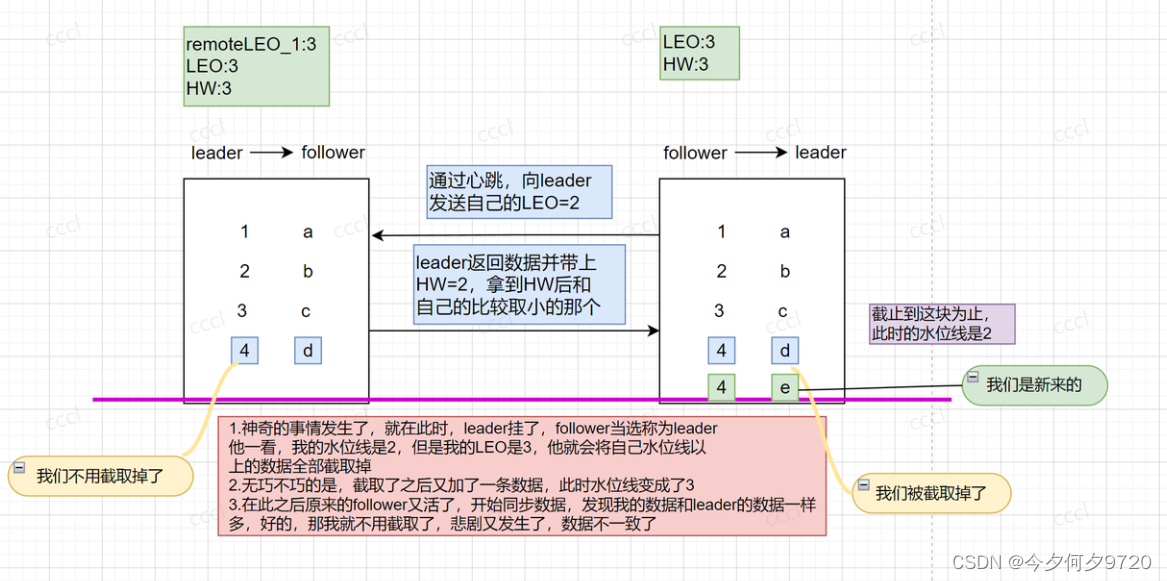
如上图所示:
- 状态起始:最新消息c已同步,但是水位线还没开始同步
- 在此时leader崩溃(即 follower 没能通过下一轮请求来更新 HW 值)
- follower成为了leader,会自动将 LEO 值调整到之前的 HW 值,即会进行日志截断
- 在截断日志之后,也就是这个d被截断了之后,我又加了一条数据是e
- 然后,原来的leader重启上线,会向新的leader发送请求请求,收到 fetch 响应后,拿到 HW 值,并更新本地 HW 值,发现我的数据和leader的数据一样,好的,我就不用截取了,我更新HW就好了,就这样,一个新的悲剧又发生了,数据不一致了
Leader-Epoch机制的引入
为了解决 HW 更新时机是异步延迟的,而 HW 又是决定日志是否备份成功的标志,从而造成数据丢失和数据不一致的现象,Kafka 引入了 leader epoch 机制;
在每个副本日志目录下都创建一个 leader-epoch-checkpoint 文件,用于保存 leader 的 epoch 信息;
leader-epoch的含义
如下,leader epoch 长这样:
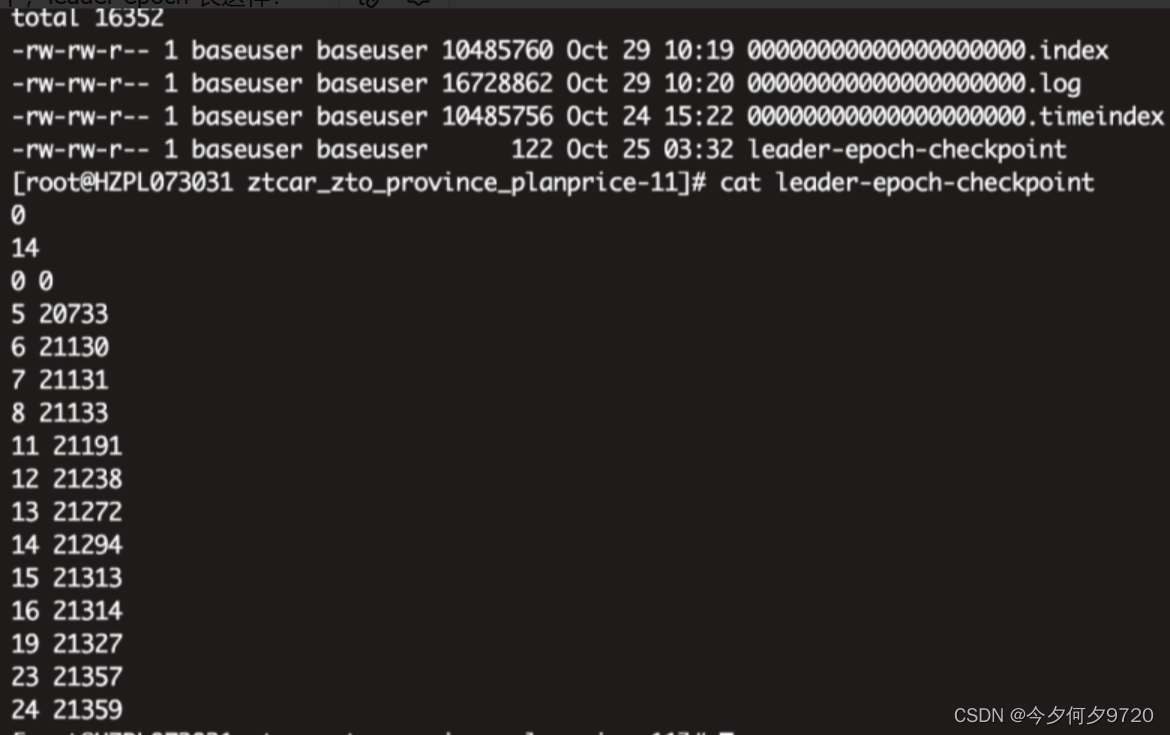
它的格式为 (epoch offset),epoch指的是 leader 版本,它是一个单调递增的一个正整数值,每次 leader 变更,epoch 版本都会 +1,offset 是每一代 leader 写入的第一条消息的位移值,比如:
(0,0)
(1,300)
以上第2个版本是从位移300开始写入消息,意味着第一个版本写入了 0-299 的消息。
leader epoch 具体的工作机制
- 当副本成为 leader 时:
这时,如果此时生产者有新消息发送过来,会首先更新leader epoch 以及LEO ,并添加到 leader-epoch-checkpoint 文件中; - 当副本变成 follower 时:
发送LeaderEpochRequest请求给leader副本,该请求包括了follower中最新的epoch 版本;
leader返回给follower的响应中包含了一个LastOffset,如果 follower last epoch = leader last epoch(纪元相同),则 LastOffset = leader LEO,否则取follower last epoch 中最小的 leader epoch 的 start offset 值;
follwer 拿到 LastOffset 之后,会对比当前 LEO 值是否大于 LastOffset,如果当前 LEO 大于 LastOffset,则从 LastOffset 截断日志;
follower 开始发送 fetch 请求给 leader 保持消息同步。
leader epoch 如何解决HW的备份缺陷
- 解决数据丢失和数据不一致的问题
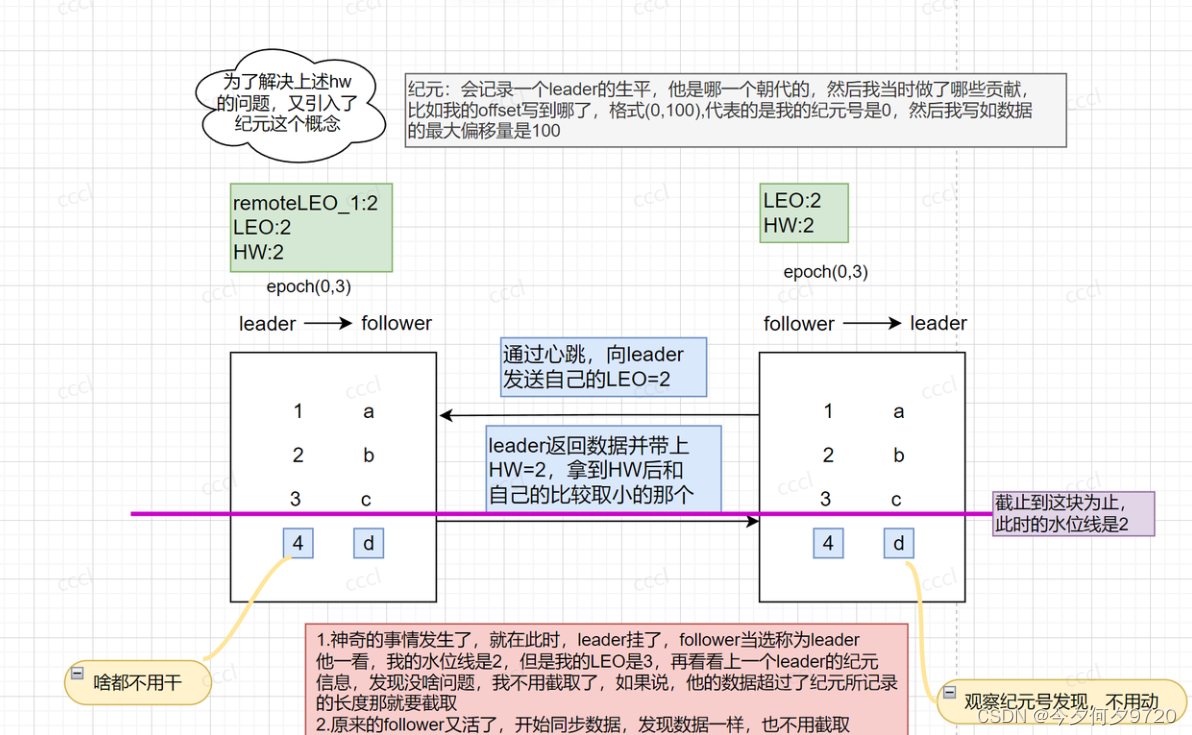
如上图所示:
follower当选leader后,收到纪元消息,发现 LastOffset等于当前 LEO 值,故不用进行日志截断。
follower重启后同步消息,发现自己也不用截取,数据一致,齐活儿
当然,如果说后来增加消息以后,也不需要截取,直接同步数据就行(当ack=-1)
LEO/HW/LSO等相关术语速查
LEO:(last end offset)就是该副本中消息的最大偏移量的值+1 ;
HW:(high watermark)各副本中LEO的最小值。这个值规定了消费者仅能消费HW之前的数据;
LW:(low watermark)一个副本的log中,最小的消息偏移量; 应该是和log里面的偏移量有关系
LSO:(last stable offset) 最后一个稳定的offset;对未完成的事务而言,LSO 的值等于事务中第一条消息的位置(firstUnstableOffset),对已完成的事务而言,它的值同 HW 相同;
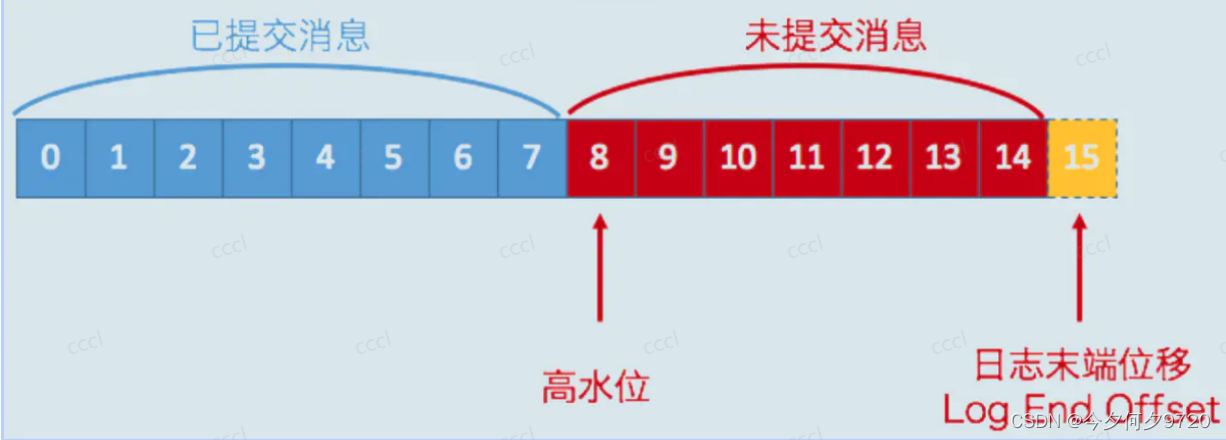
LEO与HW 与数据一致性密切相关;
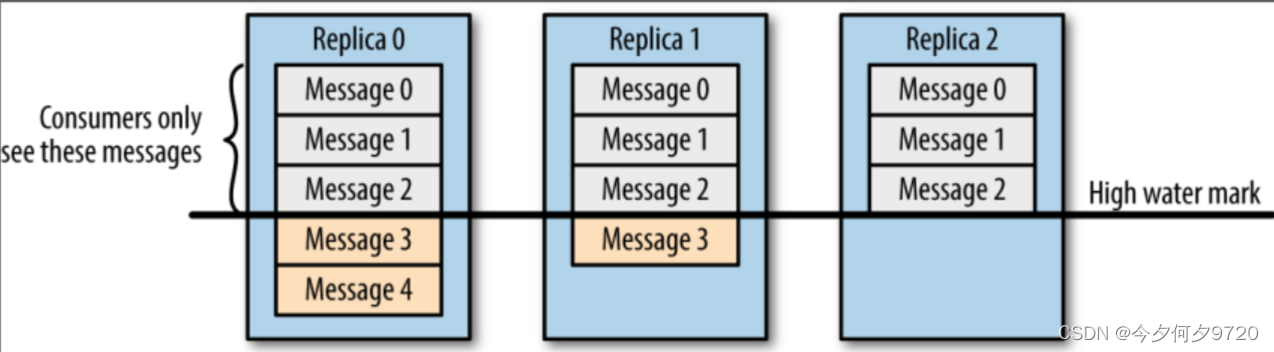
如图,各副本中最小的LEO是3,所以HW是3,所以,消费者此刻最多能读到Msg2;