VoteNet数据和源码配置调试过程请参考上一篇博文:【三维目标检测】VoteNet(一)_Coding的叶子的博客-CSDN博客。本文主要详细介绍VoteNet网络结构及其运行中间状态。
1 VoteNet模型总体过程
VoteNet核心思想在于通过霍夫投票的方法实现了端到端3D对象检测网络,属于anchor free的目标检测方式。传统基于anchor的三维目标检测方法会将三维点云投影到bev视图后采用二维目标检测的方式来生成目标候选框。这种方式很有可能会丢失物体细节。
VoteNet模型结构如下图所示。该模型大量用到了PointNet结构。在主干网络中,VoteNet利用PointNet采样分组和特征上采样得到了用于投票的种子点(seed)及其特征。种子点类比求解霍夫直线时的定点,也就是具备投票权的点。种子点投票结果为Votes,包含投票目标中心点和特征。VoteNet接着利用PointNet采样分组模块对投票点进行聚合,用聚合后的点分别预测目标有无、类别和位置。聚合的作用可类比霍夫直线参数空间中的直线交点,即聚合空间中的点投票给了同一个目标。

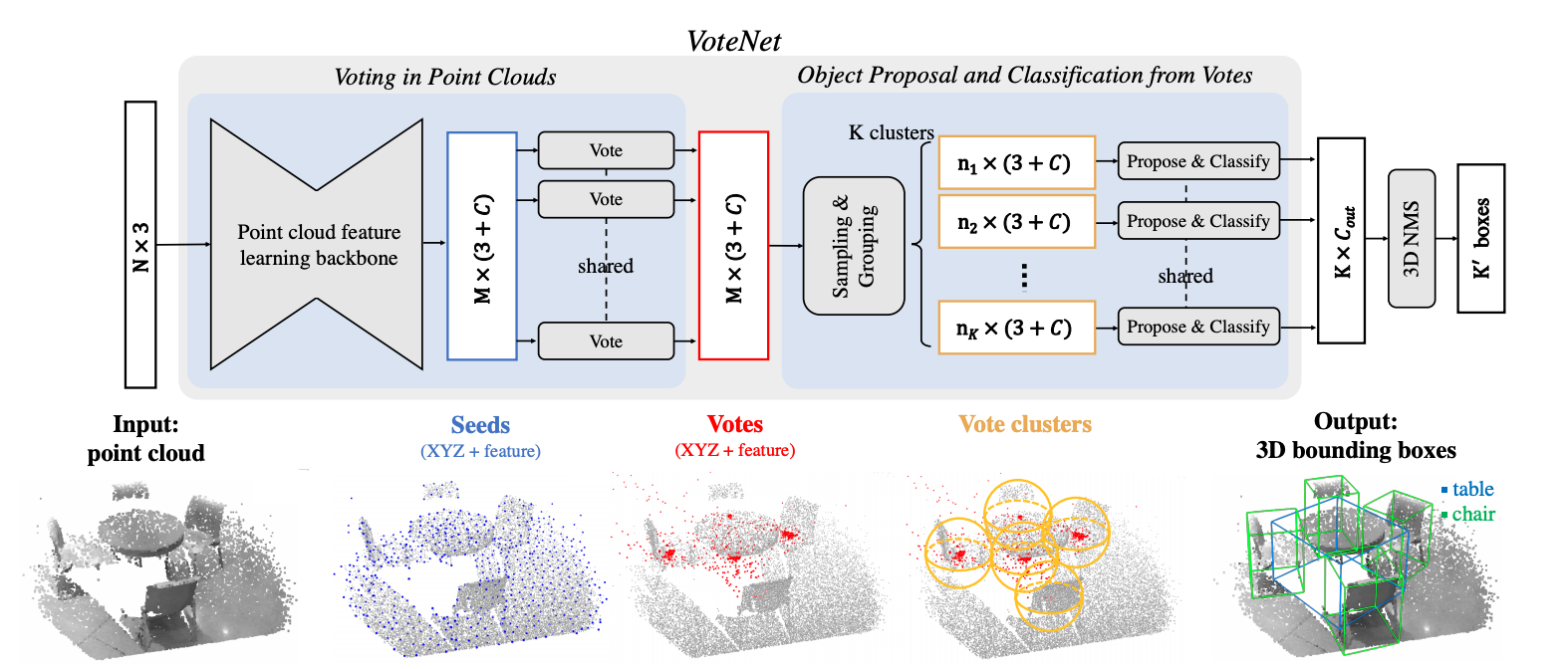
2 主要模块解析
模型输入数据points维度为Nx4,N=20000。
2.1 主干网络backbone特征提取
VoteNet主干网络采用的是PointNet2SASSG结构,其中SA模块的详细介绍请参考:【三维目标分类】PointNet++详解(一)_Coding的叶子的博客-CSDN博客_pointnet++详解。主干网络通过连续4个SA结构逐步对点云进行下采样、分组、特征提取得到采样坐标sa_xyz、采样特征sa_features和采样索引sa_indices。提取的特征再经过FP层上采样得到融合后的坐标fp_xyz、fp_features和索引fp_indices。特征上采样FP层的详细介绍请参考【三维语义分割】PointNet++ (二):模型结构详解_Coding的叶子的博客-CSDN博客。主干网络最终主要得到1024个种子点seed_points(1024x3)及其特征seed_features(1024x256)。
主干网络入口函数为self.backbone(points),关键部分介绍如下。
points -> xyz_0 20000x3,features_0 20000x1,indices_0 20000
SA1:num=2048,radius:0~0.2,g_sample_num=64,Conv2d(4, 64)、Conv2d(64, 64)、Conv2d(64, 128) -> xyz_1 2048x3,features_1 2048x128,indices_1 2048
SA2:num=1024,radius:0~0.4,g_sample_num=32,Conv2d(131, 128)、Conv2d(128, 128)、Conv2d(128, 256) -> xyz_2 1024x3,features_2 1024x256,indices_2 1024
SA3:num=512,radius:0~0.8,g_sample_num=16,Conv2d(259, 128)、Conv2d(128, 128)、Conv2d(128, 256) -> xyz_3 512x3,features_3 512x256,indices_3 512
SA4:num=256,radius:0~1.2,g_sample_num=16,Conv2d(259, 128)、Conv2d(128, 128)、Conv2d(128, 256) -> xyz_4 256x3,features_4 256x256,indices_4 256
FP1:fp_xyz_1 512x3,fp_features_1 512x256,fp_indices_1 512
FP2:fp_xyz_2 1024x3,fp_features_2 1024x256,fp_indices_2 1024VoteNet没有用到Neck结构,Neck结构提取的特征通常用于RPN网络。因此,extract_feat模块的输出与主干网络输出一致。输出包括以下6个组成部分:
(1)sa_xyz:[xyz_0, xyz_1, xyz_2, xyz_3, xyz_4],[20000x3, 2048x3, 1024x3, 512x3, 256x3]
(2)sa_features:[features_0, features_1, features_2, features_3, features_4],[20000x1, 2048x128, 1024x256, 512x256, 256x256]
(3)sa_indices:[indices_0, indices_1, indices_2, indices_3, indices_4],[20000, 2048, 1024, 512, 256]
(4)fp_xyz:[xyz_4, fp_xyz_1, fp_xyz_2],[256x3, 512x3, 1024x3]
(5)fp_features:[features_4, fp_features_1, fp_features_2],[256x256, 512x256, 1024x256]
(6)fp_indices:[indices_4, fp_indices_1, fp_indices_2],[256, 512, 1024]2.2 VoteHead
VoteHead功能是为了得到预测目标的有无、分类和位置,共包含了投票点生成、投票点聚合、候选框预测和预测解码四个主要步骤。
(1)投票点生成
VoteNet主干网络中得到了具有投票资格的1024个点seed_points(1024x3)及其特征seed_features(1024x256)。每个种子点通过卷积网络会产生一个投票点vote_points(1024x3)及其特征vote_features(1024x256),并且投票点特征与种子点特征做了一次融合。关键程序部分如下。
results[’seed_points’] = feat_dict['fp_xyz'][-1]
seed_features = feat_dict['fp_features'][-1]
results[‘seed_indices’] = feat_dict['fp_indices'][-1]
results[‘vote_points’], results[‘vote_features’], results[‘vote_offset’] = self.vote_module(seed_points, seed_features)
seed_features 1024x256 Conv1d(256, 256)、Conv1d(256, 256)、Conv1d(256, 259)
votes 1024x259
offset = votes[:, :, :, 0:3]
vote_points = seed_points + offset
vote_feats_features = seed_features + votes[:, :, :, 3:] 1024x256(2)投票点聚合
投票点聚合的作用可类比霍夫直线中的直线交点,即聚合空间中的点投票给了同一个目标。在霍夫直线检测过程中,检测结果通过直线在某点相交的投票次数来决定,并且设置阈值来进行结果筛选。VoteNet是采用一组聚合的点来预测一个目标结果。
投标点聚合的方式仍然是采用PointNet中的SA模块,将1024个投票点聚合成256个点aggregated_points(256x3),其特征为aggregated_features(256x128)。关键程序部分如下。
aggregated_points, aggregated_features, aggregated_indices = self.vote_aggregation(vote_points, vote_features)
SA:num=256,radius:0~0.3,g_sample_num=16,Conv2d(259, 128)、Conv2d(128, 128)、Conv2d(128, 128 -> aggregated_points 256x3,aggregated_features 256x128,aggregated_indices 256(3)候选框预测
每个聚合后的点会投票产生一个候选结果。根据聚合后的特征,VoteNet通过分类head和回归head产生预测的候选框结果。aggregated_features(256x128)通过卷积 Conv1d(128, 128)和Conv1d(128, 128)进行更深层特征提取,提取后的特征分别经过卷积 Conv1d(128, 12)和 Conv1d(128, 67) 得到分类预测结果cls_precls_predictions(256x12)和位置回归预测结果reg_predictions(256x67)。关键程序部分如下。
cls_predictions, reg_predictions = self.conv_pred(aggregated_features)
aggregated_features 256x128 Conv1d(128, 128)、Conv1d(128, 128) 256x128特征
分类head:conv_cls Conv1d(128, 12) 256x12 cls_prediction
回归head:conv_reg Conv1d(128, 67) 256x67 reg_predictions
BaseConvBboxHead(
(shared_convs): Sequential(
(layer0): ConvModule(
(conv): Conv1d(128, 128, kernel_size=(1,), stride=(1,))
(bn): BatchNorm1d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(layer1): ConvModule(
(conv): Conv1d(128, 128, kernel_size=(1,), stride=(1,))
(bn): BatchNorm1d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
(conv_cls): Conv1d(128, 12, kernel_size=(1,), stride=(1,))
(conv_reg): Conv1d(128, 67, kernel_size=(1,), stride=(1,))
)(4)预测解码
上一步我们得到了模型预测结果,那么预测结果如何与真实标签关联需要一一进行解码。真实标签主要包含目标有无、类别标签和目标回归位置。输入数据集共包含10个类别目标。目标位置包括方向和尺寸回归,并且各自都转换成了分类和偏移回归两部分。这种方式的候选框称为bin based box。函数入口为self.bbox_coder.split_pred(cls_predictions, reg_predictions, aggregated_points)。
解码结果的关键程序如下。
(1)目标中心位置
results['center'] = aggregated_points + reg_predictions[..., :3] 256x3
(2)目标方向类别
results['dir_class'] = reg_predictions..., 3:15] 256x12
(3)目标方向偏移
results['dir_res_norm'] = reg_predictions[..., 15:27] 256x12
results['dir_res'] = results['dir_res_norm'] * (np.pi / 12)
(4)目标尺寸类别
results['size_class'] = reg_predictions[..., 27:37] 256x10
(5)目标尺寸偏移
results['size_res_norm'] = reg_predictions[..., 37:67] 256x10x3
results['size_res'] = size_res_norm * mean_sizes 256x10x3
(6)目标有无得分
results['obj_scores'] = cls_preds_trans[..., 0:2] 256x2
(7)目标语义得分
results['obj_scores'] = cls_preds_trans[..., 2:12] 256x102.3 损失函数
2.3.1 标签计算
计算损失函数需要将上述预测结果与标签一一对应。计算标签的函数入口为self.get_targets(points, gt_bboxes_3d, gt_labels_3d, bbox_preds)。每个聚合点对应的真实标签为距离最近的目标标签。
关键程序解析如下。
#表明哪些点落在目标框内
vote_target_masks = points.new_zeros([num_points], dtype=torch.long)
box_indices_all = gt_bboxes_3d.points_in_boxes_all(points) 20000xM
votes点云中的点相对于目标几何中心的偏移
vote_targets,每个点投给相应目标的中心偏移。
vote_target_idx表示每个点实际投票的次数
vote_target_mask表示每个点是否参与了投票。1表示参与了投票,0表示未参与投票。
valid_gt_weights:有效真实标签除以标签数量得到,真实标签权重
center_targets 物体几何中心,即重心。Kx3,K为batch中单个样本含目标最多的数量,不足时补0,0,0,并用valid_gt_masks进行标识。
size_class_targets 尺寸类别与物体类别保持一致,默认不同物体有不同的尺寸,即平均尺寸
size_res_targets 物体尺寸与平均尺寸的差值除以平均尺寸。
dir_class_targets 目标角度从0~2Π范围划分为12个子区间,每个区间作为一个类别
dir_res_targets 角度相对子区间中心的偏移值,并除以区间大小进行归一化
objectness_targets聚合后的点aggregated_points距离最近目标中心点如果小于0.3则为1,即正样本标签,否则为0。正样本标签除以正样本数量得到box损失权重box_loss_weights,即仅对正样本进行box预测。
objectness_masks 聚合后的点aggregated_points距离最近目标中心点如果小于0.3或大于0.6则为1,否则为0。这表示将不考虑处于中间状态的目标,即困难样本。正负样本标签除以正负样本数量得到权重objectness_weights。
mask_targets 每个聚合点距离最近目标的分类标签。
assigned_center_targets 每个聚合点距离最近目标的分类中心。2.3.2 损失计算
VoteNet总体损失包括投票损失vote_loss、目标有无损失objectness_loss、中心损失center_loss、方向分类损失dir_class_loss、方向回归损失dir_res_loss、尺寸分类损失size_class_loss、尺寸回归损失size_res_loss、语义分类损失semantic_loss,也可增加iou损失等。各个损失函数计算关键程序及类型如下所示。
(1)投票损失vote_loss:ChamferDistance,计算投票中心与目标中心标签的最小倒角距离。
vote_loss = self.vote_module.get_loss(bbox_preds['seed_points'], bbox_preds['vote_points'], bbox_preds['seed_indices'], vote_target_masks, vote_targets)
#根据vote_target_mask(20000)和bbox_preds['seed_indices'](1024)得到投票成功的种子点,seed_gt_votes_mask(1024)
#根据vote_targets和bbox_preds['seed_indices']得到投票成功的种子点的目标中心偏移seed_gt_votes(1024x9)加上bbox_preds['seed_points']得到种子点对应投票的目标中心坐标标签。
# seed_gt_votes_mask除以投票成功的种子点总数得到权重weights。
#计算vote_points和seed_gt_votes之间的倒角距离。
(2)目标有无损失objectness_loss:CrossEntropyLoss
objectness_loss = self.objectness_loss(bbox_preds['obj_scores'].transpose(2, 1), objectness_targets, weight=objectness_weights)
(3)中心损失center_loss:ChamferDistance
source2target_loss, target2source_loss = self.center_loss(bbox_preds['center'], center_targets, src_weight=box_loss_weights, dst_weight=valid_gt_weights)
center_loss = source2target_loss + target2source_loss
(4)方向分类损失dir_class_loss:CrossEntropyLoss
dir_class_loss = self.dir_class_loss(bbox_preds['dir_class'].transpose(2, 1), dir_class_targets, weight=box_loss_weights)
(5)方向回归损失dir_res_loss:SmoothL1Loss
dir_res_loss = self.dir_res_loss(dir_res_norm, dir_res_targets, weight=box_loss_weights)
(6)尺寸分类损失size_class_loss:CrossEntropyLoss
size_class_loss = self.size_class_loss(bbox_preds['size_class'].transpose(2, 1), size_class_targets, weight=box_loss_weights)
(7)尺寸回归损失size_res_loss:SmoothL1Loss
size_res_loss = self.size_res_loss(size_residual_norm, size_res_targets, weight=box_loss_weights_expand)
(8)语义分类损失semantic_loss:CrossEntropyLoss
semantic_loss = self.semantic_loss(bbox_preds['sem_scores'], mask_targets, weight=box_loss_weights)2.4 顶层结构
顶层结构主要包含以下三部分:
- 特征提取:self.extract_feat,通过PointNet2SASSG主干网络进行特征提取,输出结果见2.1节。
- VoteHead:结果预测与解码,见2.2节。
- 损失函数:见2.3节。
def forward_train(self, points, img_metas, gt_bboxes_3d, gt_labels_3d, pts_semantic_mask=None, pts_instance_mask=None, gt_bboxes_ignore=None):
points_cat = torch.stack(points)
x = self.extract_feat(points_cat)
bbox_preds = self.bbox_head(x, self.train_cfg.sample_mod)
loss_inputs = (points, gt_bboxes_3d, gt_labels_3d, pts_semantic_mask, pts_instance_mask, img_metas)
losses = self.bbox_head.loss(bbox_preds, *loss_inputs, gt_bboxes_ignore=gt_bboxes_ignore)
return losses3 训练命令
python tools/train.py configs/votenet/votenet_16x8_sunrgbd-3d-10class.py4 运行结果
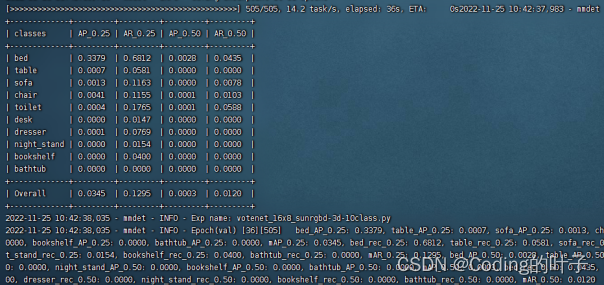
![[附源码]计算机毕业设计基于SpringBoot的高校课程知识库](https://img-blog.csdnimg.cn/7485b57496174afe8f8a86ce7473ae94.png)