文章目录
- 1. 为什么需要消息引擎?
- 2. Kafka 相关术语
- 3. Kafka 基本概念
1. 为什么需要消息引擎?
答案就是“削峰填谷”。 所谓的“削峰填谷”就是指缓冲上下游瞬时突发流量,使其更平滑。特别是对于那种发送能力很强的上游系统,如果没有消息引擎的保护,“脆弱”的下游系统可能会直接被压垮导致全链路服务“雪崩”。但是,一旦有了消息引擎,它能够有效地对抗上游的流量冲击,真正做到将上游的“峰”填满到“谷”中,避免了流量的震荡。消息引擎系统的另一大好处在于发送方和接收方的松耦合,这也在一定程度上简化了应用的开发,减少了系统间不必要的交互。
比如,极客付费课程都有一个专门的订阅按钮,点击之后进入到付费页面。这个简单的流程中就可能包含多个子服务,比如点击订阅按钮会调用订单系统生成对应的订单,而处理该订单会依次调用下游的多个子系统服务 ,比如调用支付宝和微信支付的接口、查询你的登录信息、验证课程信息等。显然上游的订单操作比较简单,它的 TPS 要远高于处理订单的下游服务,因此如果上下游系统直接对接,势必会出现下游服务无法及时处理上游订单从而造成订单堆积的情形。特别是当出现类似于秒杀这样的业务时,上游订单流量会瞬时增加,可能出现的结果就是直接压跨下游子系统服务。
解决此问题的一个常见做法是我们对上游系统进行限速,但这种做法对上游系统而言显然是不合理的,毕竟问题并不出现在它那里。所以更常见的办法是引入像 Kafka 这样的消息引擎系统来对抗这种上下游系统 TPS 的错配以及瞬时峰值流量。
还是这个例子,当引入了 Kafka 之后。上游订单服务不再直接与下游子服务进行交互。当新订单生成后它仅仅是向 Kafka Broker 发送一条订单消息即可。类似地,下游的各个子服务订阅 Kafka 中的对应主题,并实时从该主题的各自分区(Partition)中获取到订单消息进行处理,从而实现了上游订单服务与下游订单处理服务的解耦。这样当出现秒杀业务时,Kafka 能够将瞬时增加的订单流量全部以消息形式保存在对应的主题中,既不影响上游服务的 TPS,同时也给下游子服务留出了充足的时间去消费它们。这就是 Kafka 这类消息引擎系统的最大意义所在。
2. Kafka 相关术语
Kafka 属于分布式的消息引擎系统,它的主要功能是提供一套完备的消息发布与订阅解决方案。在 Kafka 中,发布订阅的对象是主题(Topic),你可以为每个业务、每个应用甚至是每类数据都创建专属的主题。
向主题发布消息的客户端应用程序称为生产者(Producer),生产者程序通常持续不断地向一个或多个主题发送消息,而订阅这些主题消息的客户端应用程序就被称为消费者(Consumer)。和生产者类似,消费者也能够同时订阅多个主题的消息。我们把生产者和消费者统称为客户端(Clients)。你可以同时运行多个生产者和消费者实例,这些实例会不断地向 Kafka 集群中的多个主题生产和消费消息。
有客户端自然也就有服务器端。Kafka 的服务器端由被称为 Broker 的服务进程构成,即一个 Kafka 集群由多个 Broker 组成,Broker 负责接收和处理客户端发送过来的请求,以及对消息进行持久化。虽然多个 Broker 进程能够运行在同一台机器上,但更常见的做法是将不同的 Broker 分散运行在不同的机器上,这样如果集群中某一台机器宕机,即使在它上面运行的所有 Broker 进程都挂掉了,其他机器上的 Broker 也依然能够对外提供服务。这其
实就是 Kafka 提供高可用的手段之一。
实现高可用的另一个手段就是备份机制(Replication)。备份的思想很简单,就是把相同的数据拷贝到多台机器上,而这些相同的数据拷贝在 Kafka 中被称为副本(Replica)。好吧,其实在整个分布式系统里好像都叫这个名字。副本的数量是可以配置的,这些副本保存着相同的数据,但却有不同的角色和作用。Kafka 定义了两类副本: 领导者副本(LeaderReplica)和追随者副本(Follower Replica)。前者对外提供服务,这里的对外指的是与客户端程序进行交互;而后者只是被动地追随领导者副本而已,不能与外界进行交互。当然了,你可能知道在很多其他系统中追随者副本是可以对外提供服务的,比如 MySQL 的从库是可以处理读操作的,但是在 Kafka 中追随者副本不会对外提供服务。
副本的工作机制也很简单:生产者总是向领导者副本写消息;而消费者总是从领导者副本读消息。至于追随者副本,它只做一件事:向领导者副本发送请求,请求领导者把最新生产的消息发给它,这样它能保持与领导者的同步。
虽然有了副本机制可以保证数据的持久化或消息不丢失,但没有解决伸缩性的问题。什么是伸缩性呢?我们拿副本来说,虽然现在有了领导者副本和追随者副本,但倘若领导者副本积累了太多的数据以至于单台 Broker 机器都无法容纳了,此时应该怎么办呢?一个很自然的想法就是,能否把数据分割成多份保存在不同的 Broker 上?如果你就是这么想的,那么恭喜你,Kafka 就是这么设计的。
这种机制就是所谓的分区(Partitioning)。如果你了解其他分布式系统,你可能听说过分片、分区域等提法,比如 MongoDB 和 Elasticsearch 中的 Sharding、HBase 中的Region,其实它们都是相同的原理,只是Partitioning 是最标准的名称。
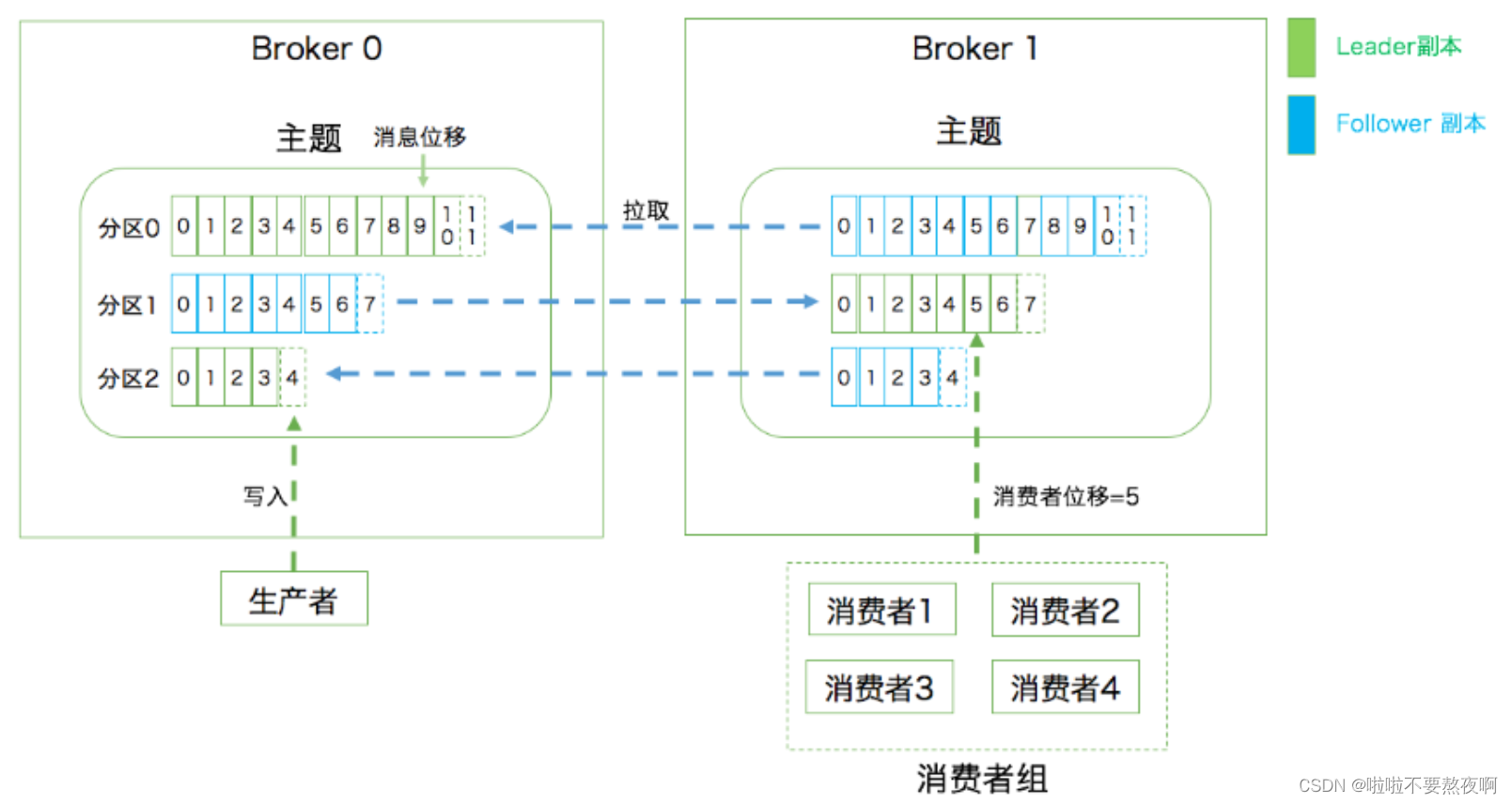
Kafka 中的分区机制指的是将每个主题划分成多个分区(Partition),每个分区是一组有序的消息日志。生产者生产的每条消息只会被发送到一个分区中,也就是说如果向一个双分区的主题发送一条消息,这条消息要么在分区 0 中,要么在分区 1 中。如你所见,Kafka的分区编号是从 0 开始的,如果 Topic 有 100 个分区,那么它们的分区号就是从 0 到99。
副本如何与这里的分区联系在一起呢? 实际上,副本是在分区这个层级定义的。每个分区下可以配置若干个副本,其中只能有 1 个领导者副本和 N-1 个追随者副本。生产者向分区写入消息,每条消息在分区中的位置信息由一个叫位移(Offset)的数据来表征。分区位移总是从 0 开始,假设一个生产者向一个空分区写入了 10 条消息,那么这 10 条消息的位移依次是 0、1、2、…、9。
至此我们能够完整地串联起 Kafka 的三层消息架构:
① 第一层是主题层,每个主题可以配置 M 个分区,而每个分区又可以配置 N 个副本。
② 第二层是分区层,每个分区的 N 个副本中只能有一个充当领导者角色,对外提供服务;其他 N-1 个副本是追随者副本,只是提供数据冗余之用。
③ 第三层是消息层,分区中包含若干条消息,每条消息的位移从 0 开始,依次递增。
④ 最后,客户端程序只能与分区的领导者副本进行交互。
我们来说说 Kafka Broker 是如何持久化数据的。总的来说,Kafka 使用消息日志(Log)来保存数据,一个日志就是磁盘上一个只能追加写(Append-only)消息的物理文件。因为只能追加写入,故避免了缓慢的随机 I/O 操作,改为性能较好的顺序I/O 写操作,这也是实现 Kafka 高吞吐量特性的一个重要手段。不过如果你不停地向一个
日志写入消息,最终也会耗尽所有的磁盘空间,因此 Kafka 必然要定期地删除消息以回收磁盘。怎么删除呢?简单来说就是通过日志段(Log Segment)机制。在 Kafka 底层,一个日志又近一步细分成多个日志段,消息被追加写到当前最新的日志段中,当写满了一个日志段后,Kafka 会自动切分出一个新的日志段,并将老的日志段封存起来。Kafka 在后台还有定时任务会定期地检查老的日志段是否能够被删除,从而实现回收磁盘空间的目的。
在 Kafka 中实现 P2P 模型的方法是引入了消费者组(Consumer Group)。所谓的消费者组,指的是多个消费者实例共同组成一个组来消费一组主题。这组主题中的每个分区都只会被组内的一个消费者实例消费,其他消费者实例不能消费它。为什么要引入消费者组呢?主要是为了提升消费者端的吞吐量。多个消费者实例同时消费,加速整个消费端的吞吐量(TPS)。
消费者组里面的所有消费者实例不仅“瓜分”订阅主题的数据,而且更酷的是它们还能彼此协助。假设组内某个实例挂掉了,Kafka 能够自动检测到,然后把这个 Failed 实例之前负责的分区转移给其他活着的消费者。这个过程就是 Kafka 中大名鼎鼎的“重平衡”(Rebalance)。
每个消费者在消费消息的过程中必然需要有个字段记录它当前消费到了分区的哪个位置上,这个字段就是消费者位移(Consumer Offset)。注意,这和上面所说的位移完全不是一个概念。上面的“位移”表征的是分区内的消息位置,它是不变的,即一旦消息被成功写入到一个分区上,它的位移值就是固定的了。而消费者位移则不同,它可能是随时变化的,毕竟它是消费者消费进度的指示器嘛。另外每个消费者有着自己的消费者位移,因此一定要区分这两类位移的区别。我个人把消息在分区中的位移称为分区位移,而把消费者端的位移称为消费者位移。
消息:Record。Kafka 是消息引擎嘛,这里的消息就是指 Kafka 处理的主要对象。
主题:Topic。主题是承载消息的逻辑容器,在实际使用中多用来区分具体的业务。
分区:Partition。一个有序不变的消息序列。每个主题下可以有多个分区。
消息位移:Offset。表示分区中每条消息的位置信息,是一个单调递增且不变的值。
副本:Replica。Kafka 中同一条消息能够被拷贝到多个地方以提供数据冗余,这些地方就是所谓的副本。副本还分为领导者副本和追随者副本,各自有不同的角色划分。副本是在分区层级下的,即每个分区可配置多个副本实现高可用。
生产者:Producer。向主题发布新消息的应用程序。
消费者:Consumer。从主题订阅新消息的应用程序。
消费者位移:Consumer Offset。表征消费者消费进度,每个消费者都有自己的消费者位移。
消费者组:Consumer Group。多个消费者实例共同组成的一个组,同时消费多个分区以实现高吞吐。
重平衡:Rebalance。消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。Rebalance 是 Kafka 消费者端实现高可用的重要手段。
3. Kafka 基本概念
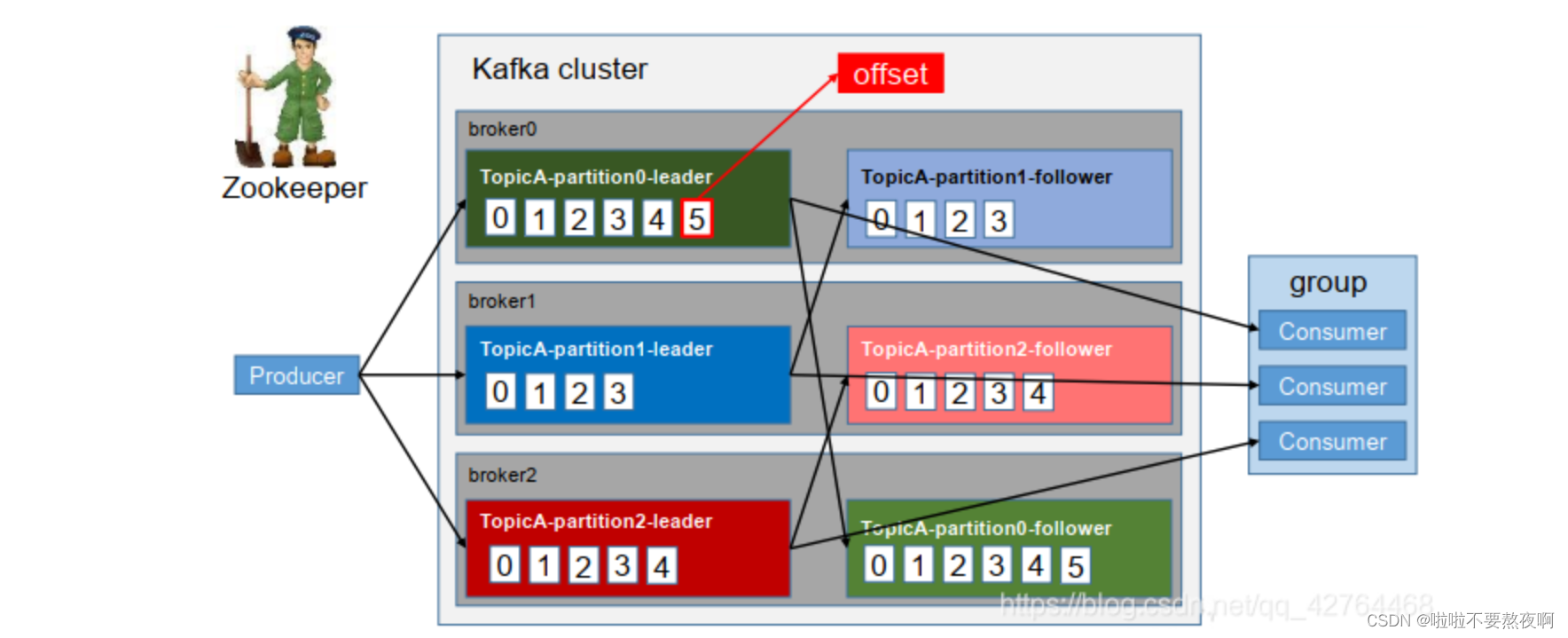
一个典型的 Kafka 体系架构包括若干 Producer、若干 Broker、若干Consumer,以及一个ZooKeeper集群。其中ZooKeeper是Kafka用来负责集群元数据的管理、控制器的选举等操作的。Producer将消息发送到Broker,Broker负责将收到的消息存储到磁盘中,而Consumer负责从Broker订阅并消费消息。
Producer:生产者,也就是发送消息的一方。生产者负责创建消息,然后将其投递到Kafka中。
Consumer:消费者,也就是接收消息的一方。消费者连接到Kafka上并接收消息,进而进行相应的业务逻辑处理。
Broker:服务代理节点。对于Kafka而言,Broker可以简单地看作一个独立的Kafka服务节点或Kafka服务实例。大多数情况下也可以将Broker看作一台Kafka服务器,前提是这台服务器上只部署了一个Kafka实例。一个或多个Broker组成了一个Kafka集群。
Kafka中的消息以主题为单位进行归类,生产者负责将消息发送到特定的主题,而消费者负责订阅主题并进行消费。主题是一个逻辑上的概念,它还可以细分为多个分区。同一主题下的不同分区包含的消息是不同的,分区在存储层面可以看作一个可追加的日志(Log)文件,消息在被追加到分区日志文件的时候都会分配一个特定的偏移量(offset)。offset是消息在分区中的唯一标识,Kafka通过它来保证消息在分区内的顺序性,不过offset并不跨越分区,也就是说,Kafka保证的是分区有序而不是主题有序。
每一条消息被发送到broker之前,会根据分区规则选择存储到哪个具体的分区。如果分区规则设定得合理,所有的消息都可以均匀地分配到不同的分区中。如果一个主题只对应一个文件,那么这个文件所在的机器 I/O 将会成为这个主题的性能瓶颈,而分区解决了这个问题。在创建主题的时候可以通过指定的参数来设置分区的个数,当然也可以在主题创建完成之后去修改分区的数量,通过增加分区的数量可以实现水平扩展。
Kafka 为分区引入了多副本(Replica)机制,通过增加副本数量可以提升容灾能力。同一分区的不同副本中保存的是相同的消息,副本之间是“一主多从”的关系,其中leader副本负责处理读写请求,follower副本只负责与leader副本的消息同步。副本处于不同的broker中,当leader副本出现故障时,从follower副本中重新选举新的leader副本对外提供服务。Kafka通过多副本机制实现了故障的自动转移,当Kafka集群中某个broker失效时仍然能保证服务可用。
Kafka 消费端也具备一定的容灾能力。Consumer 使用拉(Pull)模式从服务端拉取消息,并且保存消费的具体位置,当消费者宕机后恢复上线时可以根据之前保存的消费位置重新拉取需要的消息进行消费,这样就不会造成消息丢失。
分区中的所有副本统称为AR(Assigned Replicas)。所有与leader副本保持一定程度同步的副本(包括leader副本在内)组成ISR(In-Sync Replicas),ISR集合是AR集合中的一个子集。消息会先发送到leader副本,然后follower副本才能从leader副本中拉取消息进行同步,同步期间内follower副本相对于leader副本而言会有一定程度的滞后。前面所说的“一定程度的同步”是指可忍受的滞后范围,这个范围可以通过参数进行配置。与leader副本同步滞后过多的副本(不包括leader副本)组成OSR(Out-of-Sync Replicas),由此可见,AR=ISR+OSR。在正常情况下,所有的 follower 副本都应该与 leader 副本保持一定程度的同步,即AR=ISR,OSR集合为空。
leader副本负责维护和跟踪ISR集合中所有follower副本的滞后状态,当follower副本落后太多或失效时,leader副本会把它从ISR集合中剔除。如果OSR集合中有follower副本“追上”了leader副本,那么leader副本会把它从OSR集合转移至ISR集合。默认情况下,当leader副本发生故障时,只有在ISR集合中的副本才有资格被选举为新的leader,而在OSR集合中的副本则没有任何机会。
ISR与HW和LEO也有紧密的关系。HW是High Watermark的缩写,俗称高水位,它标识了一个特定的消息偏移量(offset),消费者只能拉取到这个offset之前的消息。
如图所示,它代表一个日志文件,这个日志文件中有 9 条消息,第一条消息的 offset(LogStartOffset)为0,最后一条消息的offset为8,offset为9的消息用虚线框表示,代表下一条待写入的消息。日志文件的HW为6,表示消费者只能拉取到offset在0至5之间的消息,而offset为6的消息对消费者而言是不可见的。
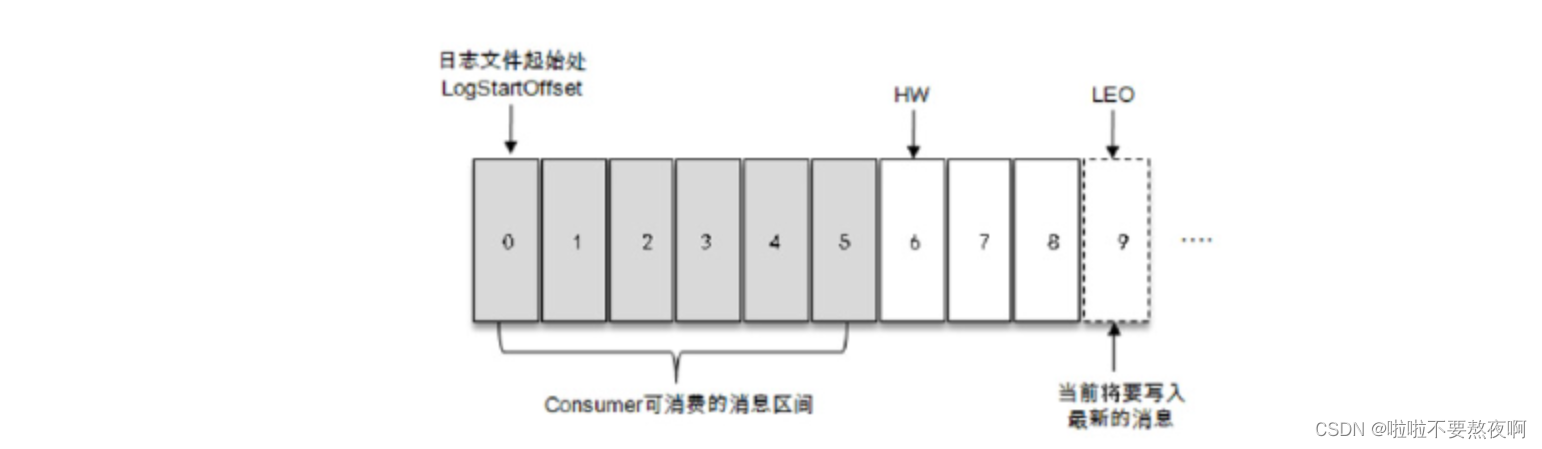
LEO是Log End Offset的缩写,它标识当前日志文件中下一条待写入消息的offset,图中offset为9的位置即为当前日志文件的LEO,LEO的大小相当于当前日志分区中最后一条消息的offset值加1。分区ISR集合中的每个副本都会维护自身的LEO,而ISR集合中最小的LEO即为分区的HW,对消费者而言只能消费HW之前的消息。
如图所示,假设某个分区的ISR集合中有3个副本,即一个leader副本和2个follower副本,此时分区的LEO和HW都为3:
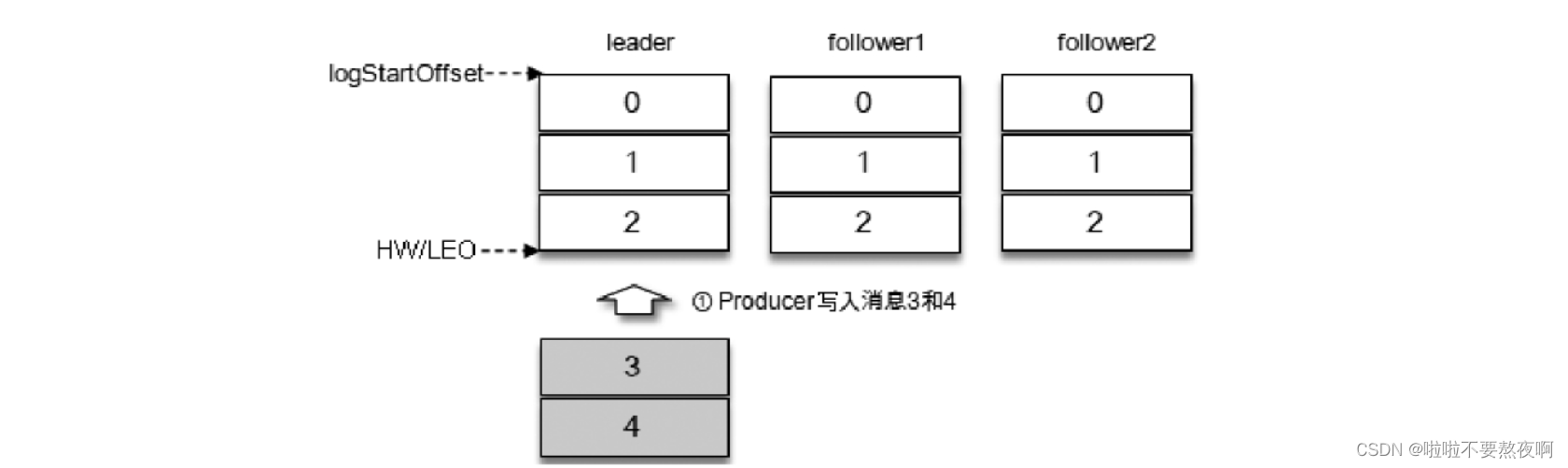
消息3和消息4从生产者发出之后会被先存入leader副本:
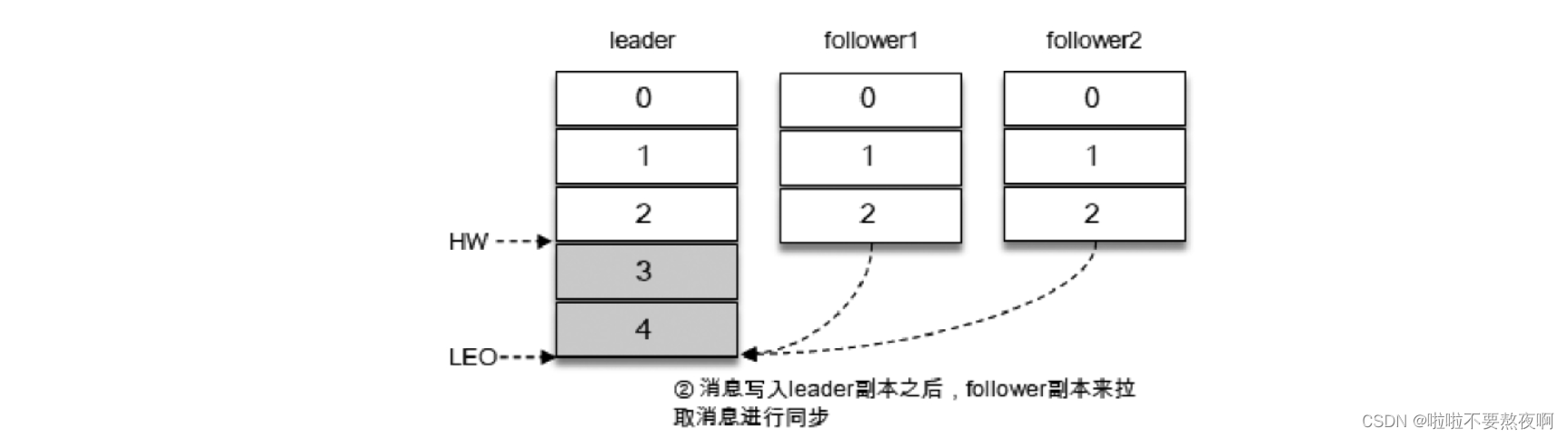
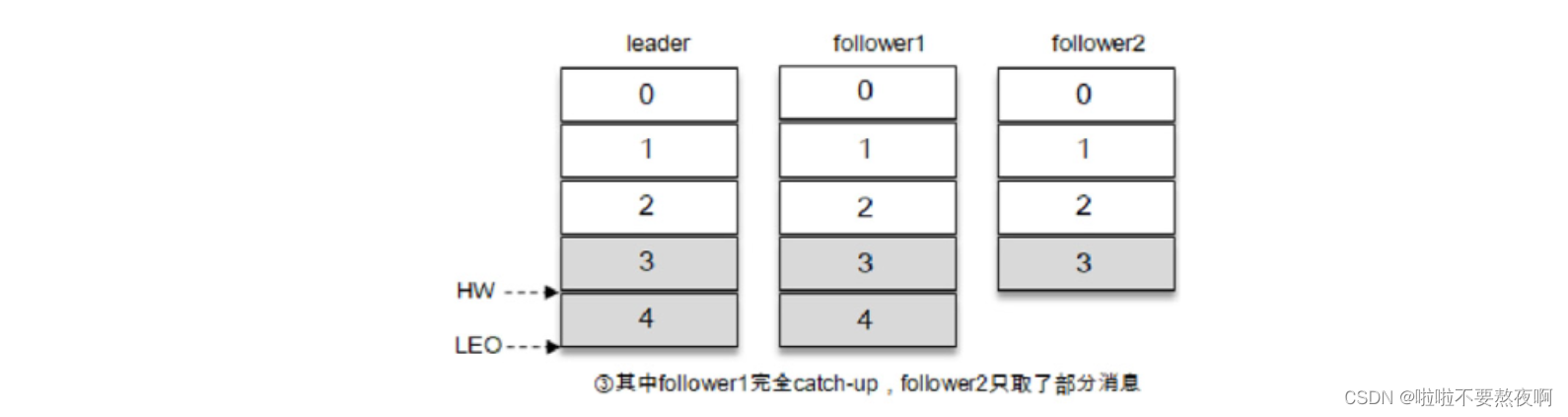
在消息写入leader副本之后,follower副本会发送拉取请求来拉取消息3和消息4以进行消息同步。在同步过程中,不同的 follower 副本的同步效率也不尽相同。如图所示,在某一时刻follower1完全跟上了leader副本而follower2只同步了消息3,如此leader副本的LEO为5,follower1的LEO为5,follower2的LEO为4,那么当前分区的HW取最小值4,此时消费者可以消费到offset为0至3之间的消息。
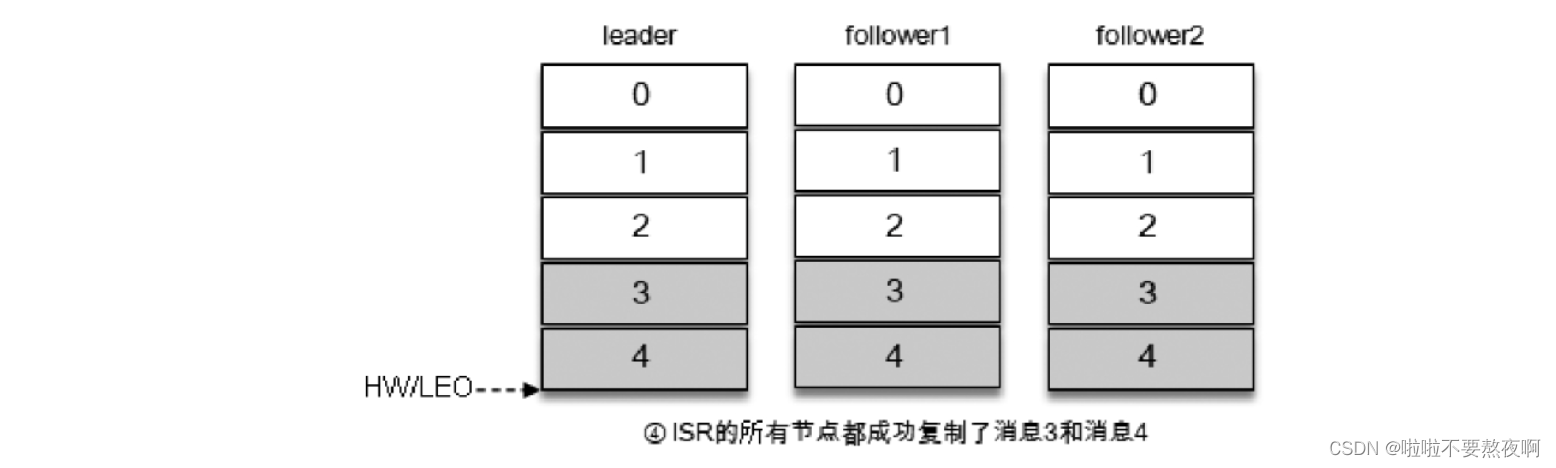
写入消息,所有的副本都成功写入了消息3和消息4,整个分区的HW和LEO都变为5,因此消费者可以消费到offset为4的消息了。
由此可见,Kafka 的复制机制既不是完全的同步复制,也不是单纯的异步复制。事实上,同步复制要求所有能工作的 follower 副本都复制完,这条消息才会被确认为已成功提交,这种复制方式极大地影响了性能。而在异步复制方式下,follower副本异步地从leader副本中复制数据,数据只要被leader副本写入就被认为已经成功提交。在这种情况下,如果follower副本都还没有复制完而落后于leader副本,突然leader副本宕机,则会造成数据丢失。Kafka使用的这种ISR的方式则有效地权衡了数据可靠性和性能之间的关系。







![[附源码]计算机毕业设计小区物业管理系统Springboot程序](https://img-blog.csdnimg.cn/d24bfd52952744f787159cbf42e66215.png)