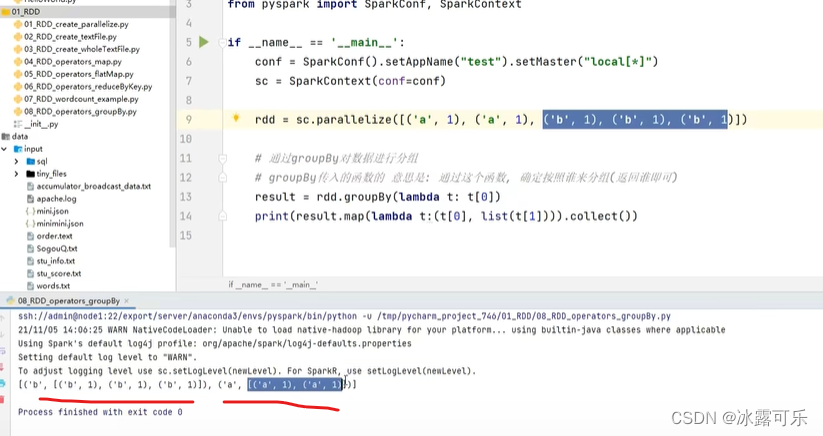
目录
- Discourse 语篇
- 三个关键的语篇任务
- Discourse Segmentation 语篇分段
- Unsupervised Approaches 无监督方法
- Supervised Approaches 有监督方法
- 有监督语篇分段器
- Discourse Analysis 语篇解析
- 语篇解析
- RST: Discourse Units
- RST: Discourse Relations
- Nucleus vs. Satellite 核心 vs. 伴随体
- RST Tree
- RST Parsing RST 解析
- Rule-based Parsing: Parsing Using Discourse Markers 使用语篇标记进行解析
- Parsing Using Machine Learning 使用机器学习进行解析
- Bottom-up Parsing
- Top-down Parsing
- Discourse Parsing Features 语篇解析特征
- Applications of Discourse Parsing 为什么要进行语篇解析?
- Anaphors 照应语
- Antecedent Restrictions 先行词约束
- Antecedent Preferences 先行词偏好
- Entities and Reference 实体和参照
- Centering Theory 中心理论
- Centering Algorithm 中心算法
- Supervised Anaphor Resolution 有监督指代消解
- 指代消解工具
- 指代消解的动机
- 总结
Discourse 语篇
这节课我们学习 语篇(Discourse),它是关于如何将文档中的句子组织成连贯的故事线。因此,我们将目光从理解单词和上下文含义上转移到一个更高的层次:理解文档含义以及句子是如何在文档中组织的。
-
Most tasks/models we learned operate at word or sentence level: 目前为止,我们学习的大部分任务/模型都是在 单词或者句子层面 操作的:
- POS tagging 词性标注:通常每次标注一个句子中所有单词的词性。
- Language models 语言模型:从 n-grams 语言模型到 RNN 语言模型,它们都是在句子层面操作的。
- Lexical/distributional semantics 词汇/分布语义学:当我们训练这些模型时通常也是以句子作为边界的。
-
But NLP often deals with documents 但是,NLP 也会经常需要处理 文档。
-
Discourse: Understanding how sentences relate to each other in a document 语篇(Discourse):理解文档中的句子之间是如何关联起来的。因此,当我们浏览一个文档时,语篇为我们提供了一个关于该文档的连贯的故事线。
三个关键的语篇任务
- 语篇分段(Discourse segmentation)
例如:我们有一篇文章,我们希望将它按照内容之间的连贯性分成一些独立的块(chunks)。例如,第一段是关于文章摘要(Abstract)的,第二段是关于文章内容介绍(Introduction)的,因此,我们希望在这两个段落之间插入一个分隔。

- 语篇解析(Discourse parsing)
语篇解析的核心思想是试图将文档组织为一种 层级结构(hierarchical structure)。例如:我们有一个包含 3 个句子的非常小的文档,语篇解析试图将这 3 个彼此关联的子句 (clauses) 组织为一个层级树形结构。可以看到,这段文本的中心句是第一个子句,后面的两个子句只是用来支持前面句子的观点的。因此,这三个子句被组织为下面的树形结构。

- 指代消解(Anaphora resolution)
指代消解的目的是关于消除文档中的指代词的歧义问题。例如:在下面的句子中,代词 “He” 在不同上下文中的指代对象是谁。

Discourse Segmentation
Discourse Segmentation 语篇分段
-
A document can be viewed as a sequence of segments 一个 文档(document)可以被视为 一个由分段组成的序列(a sequence of segments)。
-
A segment: a span of cohesive text 分段(Segment):一段连贯的文字。
-
Cohesion: organized around a topic or function 连贯性(Cohesion):
- 连贯性意味着这段文字是围绕某个特定 主题(topic)或 功能(function)来组织的。
- 维基百科里的人物类传记:早年经历 (early years)、主要事件 (major events)、其他方面的影响 (impact on others)
- 科学性的文章:简介 (introduction)、相关工作 (related work)、实验 (experiments)
- 连贯性意味着这段文字是围绕某个特定 主题(topic)或 功能(function)来组织的。
Unsupervised Approaches 无监督方法
-
TextTiling algorithm: Looking for points of low lexical cohesion between sentence TextTiling 算法:寻找句子之间具有较低词汇连贯性的点。
-
For each sentence gap: 对于每个句子间隙(sentence gap):
- Create two BOW vectors consisting of words from
ksentences on either side of gap 创建两个 词袋向量(BOW vectors),它们由间隙两侧的各自 K 个句子中的单词组成。 - Use cosine to get a similarity score
simfor two vectors 计算两个向量的余弦相似度得分。 - For gap
i, calculate a depth score, insert boundaries when depth is greater than some thresholdt对于间隙i,计算一个 深度分数(depth score),当深度分数超过某个 阈值(threshold)t 时,就在这个间隙处插入一个分界线。 -
- Create two BOW vectors consisting of words from
-
E.g.: 这里,我们来看一个具体的使用 TextTiling 算法进行语篇分段的例子,这里我们将相关参数设为k=1,t=0.9(即词袋向量来自间隙前后的各一个句子,深度分数的阈值为 0.9):

k = 1, t = 0.9

Supervised Approaches 有监督方法
我们也可以采用有监督方法来完成语篇分段任务。
- Get labelled data from easy sources: 我们可以从一些容易获得的渠道得到一些带标签数据:
- Scientific publications 科学出版物
- Wikipedia articles 维基百科的文章
-

例如,我们知道科学出版物一般会按照章节(sections)和子章节(subsections)等进行分段。假设现在我们希望创建一些分段(segments)来合并文章中的一些段落(paragraphs),所以现在我们不再以句子为边界,而是以段落为边界进行分段。
首先,我们将所有的段落单独分开,例如,上面的文章包含了 6 个单独的段落。然后,我们尝试对这些段落间隙进行标注:如果前后两个段落之间涉及到章节之间的跳转(例如,第 1 段到第 2 段是从 Abstract 跳到了 Introduction),那么我们将这两个段落之间的间隙给予一个正标签,即我们将对这两个段落进行切分;如果前后段落不涉及章节跳转(例如,第 2 段和第 3 段都属于 Introduction),我们将给予段落间隙一个负标签,即我们会不对这两个段落进行切分。然后,我们可以利用这些带标签数据来训练一个有监督分类器,再对测试集中的其他语篇数据进行分段。
有监督语篇分段器
-
Apply a binary classifier to identify boundaries. 应用一个二分类器来识别边界。
就像前面提到的例子,我们可以采用一个基于正负标签数据的二分类器来决定是否需要对给定的两个段落进行切分。 -
Or use sequential classifiers. 或者使用序列分类器。
我们也可以使用像 HMM 或者 RNN 这类序列模型进行分类。这种情况下,我们在分段时会考虑一些上下文信息,从而在分段时得到一个全局最优的决策结果。 -
Potentially include classification of section types 我们还可以潜在地包含分类的章节类型 (section type),例如:Introduction, Conclusion 等。
假如我们使用维基百科或者科学文章,我们知道其中每个章节都有特定的主题/功能,我们可以原问题转换为一个多任务问题:我们不仅对语篇文本进行分段,并且我们还需要给出每个分段所对应的章节。 -
Integrate a wider range of features: 我们还可以集成一些更宽泛的特征,包括:
- Distributional semantics 分布语义学
- Discourse markers 语篇标记(discourse markers),例如:therefore, and, however等。
语篇标记在这里要更加重要一些,因为它们通常对于语篇分段前后的差异具有放大效应。
Discourse Parsing
Discourse Analysis 语篇解析
现在,我们将讨论第二个主要任务:语篇解析(Discourse Parsing),其目标是将 语篇单元 (discourse units) 组织成层级结构中的故事线,例如:某段文本是否是对另一段文本的解释。
-
Identify discourse units, and the relations that hold between them
-
Rhetorical Structure Theory is a framework to do hierarchical analysis of discourse structure in documents
语篇解析
- 识别 语篇单元 (discourse units),以及它们之间所维系的 关系(relations)。
- 修辞结构理论 (Rhetorical Structure Theory, RST) 是一个对文档中的语篇结构进行层级分析的框架。RST 在计算机科学中具有广泛应用,例如:总结 (Summarisation)、问答 (QA) 等。
- 下面是之前提到过的一个例子,RST 可以将文档组织成语篇单元:
-

在这个文档中,我们一共有 3 个语篇单元,RST 试图在给定这些语篇单元的情况下,发现它们之间所维系的关系。例如:第 2 个从句和第 3 个从句之间存在 让步(Concession)关系,而这两个语篇单元作为整体又和第一个主要句子之间存在 详述(Elaboration)关系。一旦我们构建完成这样一个层级树形结构,我们就可以知道根结点代表的核心语篇单元以及用于支持它的其他语篇单元。
RST: Discourse Units
基本单元:基本语篇单元(elementary discourse units, EDUs)
-
Typically clauses of a sentence 通常是组成一个句子的 子句(clauses)。
-
Discourse Units do not cross sentence boundary EDUs 不会跨越句子边界。 例如,RST 将下面的句子划分为两个 EDUs:
-
E.g. [It does have beautiful scenery,] | [some of the best since Lord of the Rings]
-
2 merged DUs = another composite DU
RST: Discourse Relations
RST 还定义了语篇单元之间的 关系(relations)
-
Relations between discourse units:
- Conjunction, justify, concession, elaboration 连接 (conjuction),论证 (justify),让步 (concession),详述 (elaboration) 等。
-
E.g. 在之前的例句中,第二个 EDU 和第一个 EDU 之间是详述 (elaboration) 关系。

Nucleus vs. Satellite 核心 vs. 伴随体
-
Within a discourse relation, one argument is the nucleus (the primary argument). 在每个 RST 语篇关系中,都有一个论点作为 核心(nucleus),即主要论点。
-
The supporting argument is the satellite

-
Some relations are equal (conjunction), and so both arguments are nuclei 有些关系是对等的(例如:连接 conjunction),这种情况下,两个论点都是核心(nuclei)。

-
在 RST 关系中,总是存在作为核心的语篇单元,因此我们可以有两个核心,或者一个核心和一个伴随体,但是,不会存在只有伴随体组成的关系。
RST Tree
- An RST relation combines two or more DUs into composite DUs
- Process of combining DUs is repeated creating an RST Tree
- E.g.


RST Parsing RST 解析
- Task: given a document, recover the RST tree 任务:给定一个文件,恢复RST树
- Three approaches:
- Rule-based parsing
- Bottom-up approach
- Top-down approach
Rule-based Parsing: Parsing Using Discourse Markers 使用语篇标记进行解析
接下来我们将讨论 解析(Parsing),即给定一段文本,我们希望 自动化 地构建出包含了语篇单元及其关系的 RST 树形结构。
-
Some discourse markers explicitly indicate relations:
- although, but, for example, in other words, so, because, in conclusion
-
Can be used to build a simple rule-based parser
-
Problems:
- Many relations are not marked by discourse marker
- Many discourse marker ambiguous
-

Parsing Using Machine Learning 使用机器学习进行解析
我们可以尝试利用机器学习的方法(构建一个机器学习分类器)来处理语篇解析任务。
-
RST Discourse Treebank: 300+ documents annotated with RST trees
-
Basic idea:
- Segment document into DUs
- Combine adjacent DUs into composite DUs iteratively to create the full RST
-

-
那么,我们可以使用哪些机器学习方法呢?
-



Bottom-up Parsing
-
Transition-based parsing: Greedy, uses shift-reduce algorithm
-
CYK/chart parsing algorithm: Global, but some constraints prevent CYK from finding globally optimal tree for discourse parsing
Top-down Parsing
-
Segment documents into DUs
-
Decide a boundary to split into 2 segments
-
For each segment, repeat step 2
Discourse Parsing Features 语篇解析特征
- Bag of words 词袋(Bag of words)
- 显然,单词对于语篇解析非常重要。
- Discourse markers 语篇标记(Discourse markers)
- 语篇标记也非常重要,像 “however” 这类单词通常显式地表明了语篇单元之间的关系。
- Starting and ending n-grams 起始/结束 n-grams
- 通常,我们倾向于在句子开头和结尾使用一些特定的单词短语,它们也包含了一些句子之间逻辑上的转变。
- Location in the text 文本中的位置
- 文本中的句子之间的语篇关系转变有时和句子在文本中的位置有关。
- Syntax features 句法特征
- 通常,像词性(part-of-speech)等句法特征通常也包含了一些有用信息。
- Lexical and distributional similarities 词汇/分布语义学
- 单词含义及上下文信息通常也非常有用。
Applications of Discourse Parsing 为什么要进行语篇解析?
我们已经介绍了什么是语篇分析,以及为整个文档构建 RST 树等内容。但是,我们为什么需要进行语篇解析呢?或者说语篇解析有哪些应用场景?这里我们将通过一个简单例子来进行说明:

- Summarization
- Sentiment analysis
- Argumentation
- Authorship attribution
- Essay scoring
-

Anaphora Resolution 指代消解
最后,我们将介绍 指代消解(Anaphora Resolution),其目的是试图消除文本中指示代词的歧义性问题。Anaphors 照应语
-
Anaphor(照应语): Linguistic expressions that refer back to earlier elements in the text 照应语(Anaphor):回过头来引用文本中较早出现过的元素的一种语言表达。
-
Anaphor have a antecedent in the discourse, often but not always a noun phrase 照应语在语篇中有一个对应的 先行词(antecedent),先行词通常是一些名词短语,但并非总是如此。
- E.g.


- E.g.
-
Pronouns are the most common anaphor 代词(Pronouns)是最常见的照应语
- 但是还有其他各种照应语 指示代词(Demonstratives)
-
Motivation: Essential for deep semantic analysis 动机: 对深度语义分析至关重要
- Very useful for question answering and reading comprehension 对回答问题和阅读理解非常有用
Antecedent Restrictions 先行词约束
-
Pronouns must agree in number with their antecedents 代词必须在 数量 上与其对应的先行词保持一致。

-
Pronouns must agree in gender with their antecedents 代词必须在 性别 上与其对应的先行词保持一致。

-
Pronouns whose antecedents are the subject of the same syntactic clause must be reflexive 代词必须是 反身(reflexive)的,即 “-self” 形式,如果其先行词和该代词在同一个子句中,并且先行词充当主语。

Antecedent Preferences 先行词偏好
-
The antecedents of pronouns should be recent 代词对应的先行词应该是距离最近的 (recent)。

-
The antecedent should be salient, as determined by grammatical position: 根据语法位置,先行词应该出于突出的 (salient) 位置。因此,当我们选择先行词时,我们通常遵循以下优先级:
- Subject > object > argument of preposition 主语(subject)> 宾语(object)> 介词主题(argument of preposition)

Entities and Reference 实体和参照
我们来看一下 实体(Entities)和 参照(Reference)对于语篇连贯性的影响,给定下面两段语篇:

- Discourse 16.1 is more coherent 左边 16.1 的语篇要更具连贯性。
- Pronouns all refer to John consistently, the protagonist 因为 16.1 中的所有代词的指代对象都是主人公 John。
Centering Theory 中心理论
因此,通过前面的例子,我们可以引出所谓的 中心理论(Centering Theory):
- A unified account of relationship between discourse structure and entity reference 语篇结构与实体参照之间关系的统一描述。
RST 为我们描述了如何表示这些语篇结构,而中心理论要更进一步,它告诉我们如何将语篇结构中的这些实体和参照联系起来。并且,中心理论为我们提供了一种方式来解释为什么之前例子中的 16.1 的语篇要比 16.2 的语篇更具连贯性。 - Every utterance in the discourse is characterized by a set of entities, known as centers 语篇中的每个 表述(utterance)都通过一个 实体集(a set of entities)给出,我们将其称为 中心(centers)。
- Explain preference of certain entities for ambiguous pronouns 在解释一些具有歧义性的代词时,我们会偏向于某些特定实体。
For an Utterance Un

-
Forward-looking centers:
- All entities in Un:
-
- Ordered by syntactic prominence: subjects > objects
- All entities in Un:
-
Backward-looking center:
- Highest ranked forward-looking center in previous utterance
- Candidate entities in 16.1 b =
[John, music store] -
- Not
music storebecauseJohnhas a higher rank in previous utterance’s forward-looking centers
Centering Algorithm 中心算法
-
When resolving entity for anaphora resolution, choose the entity such that top forward-looking center matches with the backward-looking center
-
Because the text reads more fluent when this condition is satisfied
-

-


Supervised Anaphor Resolution 有监督指代消解
-
Build a binary classifier for anaphor/antecedent pairs 为照应语/先行词对构建一个二分类器。
-
Convert restrictions and preferences into features: 将先行词的约束和偏好转换为特征:
- Binary features for number/gender compatibility 二进制特征可以用于数量/性别约束
- Position of antecedent in text 先行词在文本中的位置
- Include features about type of antecedent 包含有关先行词类别的特征
-
With enough data, can approximate the centering algorithm 如果我们有充足的数据量,我们可以利用有监督机器学习来近似中心算法。
-
But also easy to include features that are potentially helpful. 而且还可以很容易囊括一些和趋势(而非规则)相关的特征。
- Words around anaphor/antecedent 例如:重复(repetition),排比(parallelism)等。
指代消解工具

指代消解的动机

总结
- 对于许多任务,考虑上下文要比考虑句子本身更重要。
- 传统上,许多流行的 NLP 应用程序的关注点都在句子层面(例如机器翻译),但是这种情况已经开始改变……