觉得有帮助或有疑问麻烦点赞关注收藏后评论区私信留言~~~
一、句法分析
句法分析(syntactic parsing或者parsing)是识别句子包含的句法成分要素以及成分之间的内在关系,一般以句法树来表示句法分析的结果。实现该过程的应用称作句法分析器(Parser)。根据侧重目标分为完全句法分析和局部句法分析,完全句法分析以获取整个句子的句法结构为最终目的,而局部句法分析仅关注局部部分,依存句法分析属于局部分析法
自然语言处理句法分析目前面临的关键技术问题:
(1)语义消歧: 语言中存在很多一词多义的用法,歧义与消歧是自然语言理解中最核心的问题,在词语、句子、段落篇章等各个层次都会出现语言根据语境产生歧义的现象,消歧是指根据上下文识别语义的过程。
(2)路径优化: 句法分析的搜索空间和句子长度存在指数对应关系,因此,在句子长度超过特定阈值时,搜索空间会变得十分庞大,从而降低了处理效率。优化搜索路径,以确保能够在合理时间范围内查找到模型定义最优解,是句法分析的目标。
二、句法树
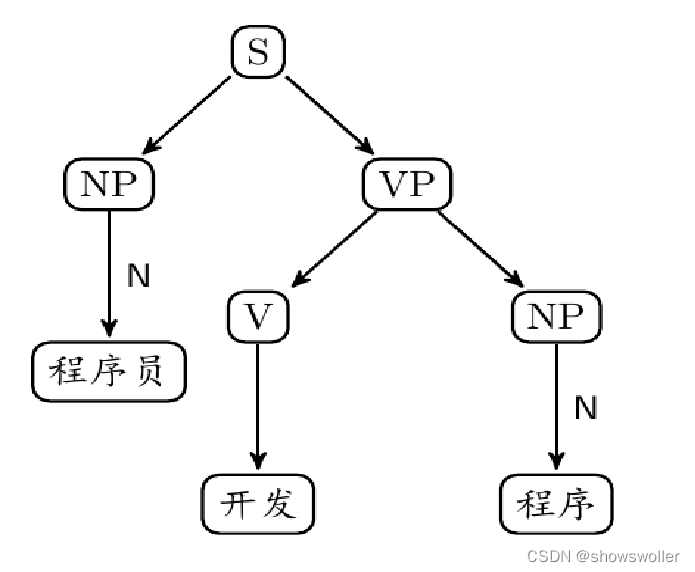
在计算机中,可以用树状结构图来表示文本结构,使用字符S代表句子,NP VP PP分别代表名词短语 动词短语 介词短语 N V P M则分别是名词 动词 介词 数量词和时量词
三、常用句法分析相关数据集
英国Lancaster- Leeds 树库
美国Penn 树库(涵盖中英文)
清华大学句法树库为基础的系列句法分析数据集
台湾 Sinica 中文树库等
四、句法分析方法
句法分析的基本任务是确定句子的语法结构或词汇间的依存关系,句法分析是自然语言处理实现目标的关键环节,句法分析通常分为结构分析和依存关系分析两种。
语言学家 Robinson 4 个约束性公理。
(1)有且仅有一个词语(ROOT,虚拟根节点)不依存于其他词语。
(2)除根节点之外其他单词存在依存关系。
(3)各单词不能依存于多个单词。
(4)如果单词 X 依存于 Y,那么位置处于 X 和 Y 之间的单词 Z 只能依存于 X、Y 或 XY 之间的单词。
句法分析中 有三个常见的评价标准
P为标记的准确率 R为召回率

五、概率分布上下文无关文法
由于语法的解析存在歧义性,因此结果可能导致多种语法树可供备选,从中找出可能性最高的句法树,即概率最大的句法树,是概率分布上下文无关语法 (Probabilistic Context-Free Grammar:PCFG)的基本处理逻辑。概率分布上下文无关语法源自上下文无关文法
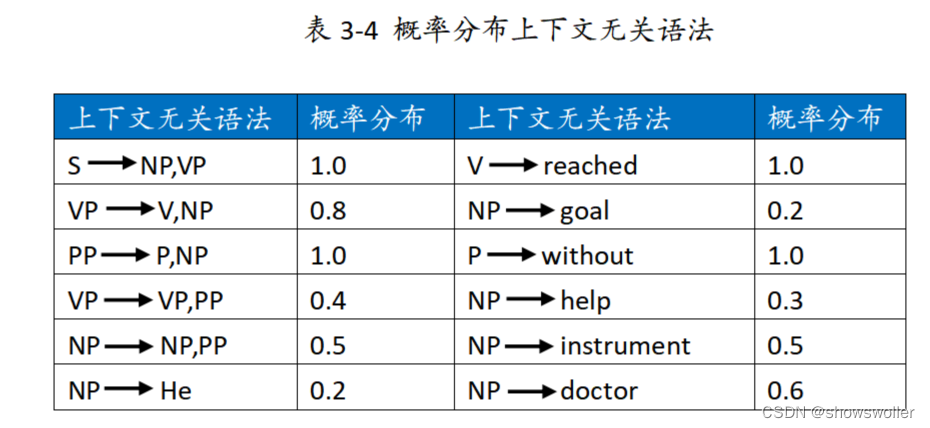
基于上述信息,得出相应句法树的生成概率为: P1=P(S)×P(NP)×P(VP)×P(V)×P(NP)×P(NP)×P(PP)×P(P)×P(NP) =1.0×0.2×0.8×1.0×0.5×0.2×1.0×1.0×0.2=0.0032
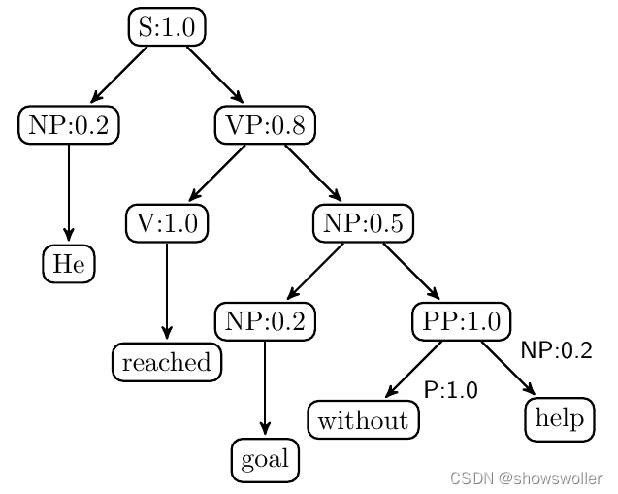
基于歧义的观点,如果存在另外一种理解导致各规则以及各结点的概率值呈现为下图结果,根据概率上下文无关语法得出该句法树的概率则表示未下
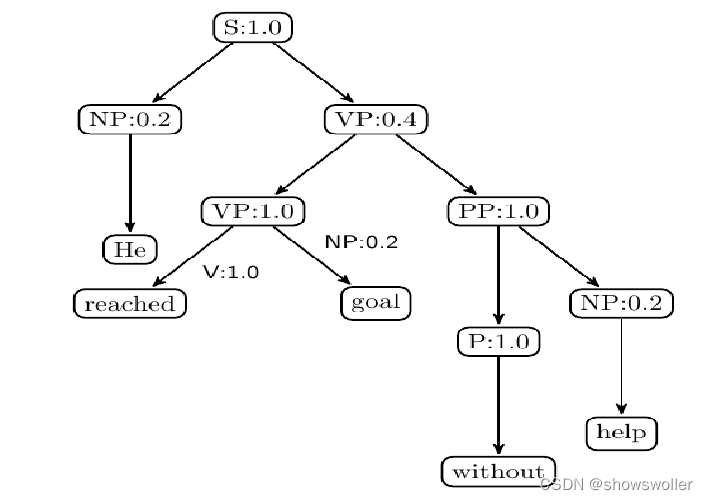
根据概率分布上下文无关语法得出该句法树的概率为: P2=P(S)×P(NP)×P(VP)×P(VP)×P(V)×P(NP)×P(PP)×P(P)×P(NP) =1.0×0.2×0.7×1.0×1.0×0.2×1.0×1.0×0.2=0.0056
比较上述两个概率值,第二个句法树的生成概率高,因此选择第二颗句法树作为最终结果,如果存在多种歧义,可以使用类似的方法求出概率最大的句法树
六、神经网络句法分析
神经网络能够对特征信息进行自动建模,具有自足学习能力,可以对特征进行自动优化,避免了大量的手动特征标注工程,并且,基于神经网络的句法分析模型的处理性能一般也优于传统的句法分析模型,因此,开发性能优异的神经网络算法成为近年研究的聚焦点。
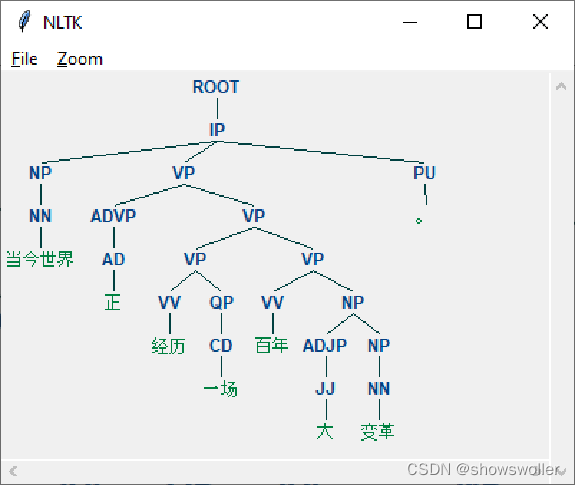
下面使用斯坦福句法分析器进行中文句法分析实战
假定对象文本分析为“当今世界正经历一场百年大变革” 利用斯坦福句法程序分析得到的句法结构如下

创作不易 觉得有帮助请点赞关注收藏~~~




![[附源码]计算机毕业设计校园帮平台管理系统Springboot程序](https://img-blog.csdnimg.cn/d6f9d1048cbf4c6f97b181ca4a091cd8.png)