ChatGPT的学习过程【分析ChatGPT原理】+如何高效使用GPT
此处借鉴:台湾大学李宏毅老师的讲解
资料:pan.baidu.com/s/1Jk1phne3ArfOERYNTPL12Q?pwd=1111
GPT=Generative Pre-trained Transformer生成式预训练转换模型
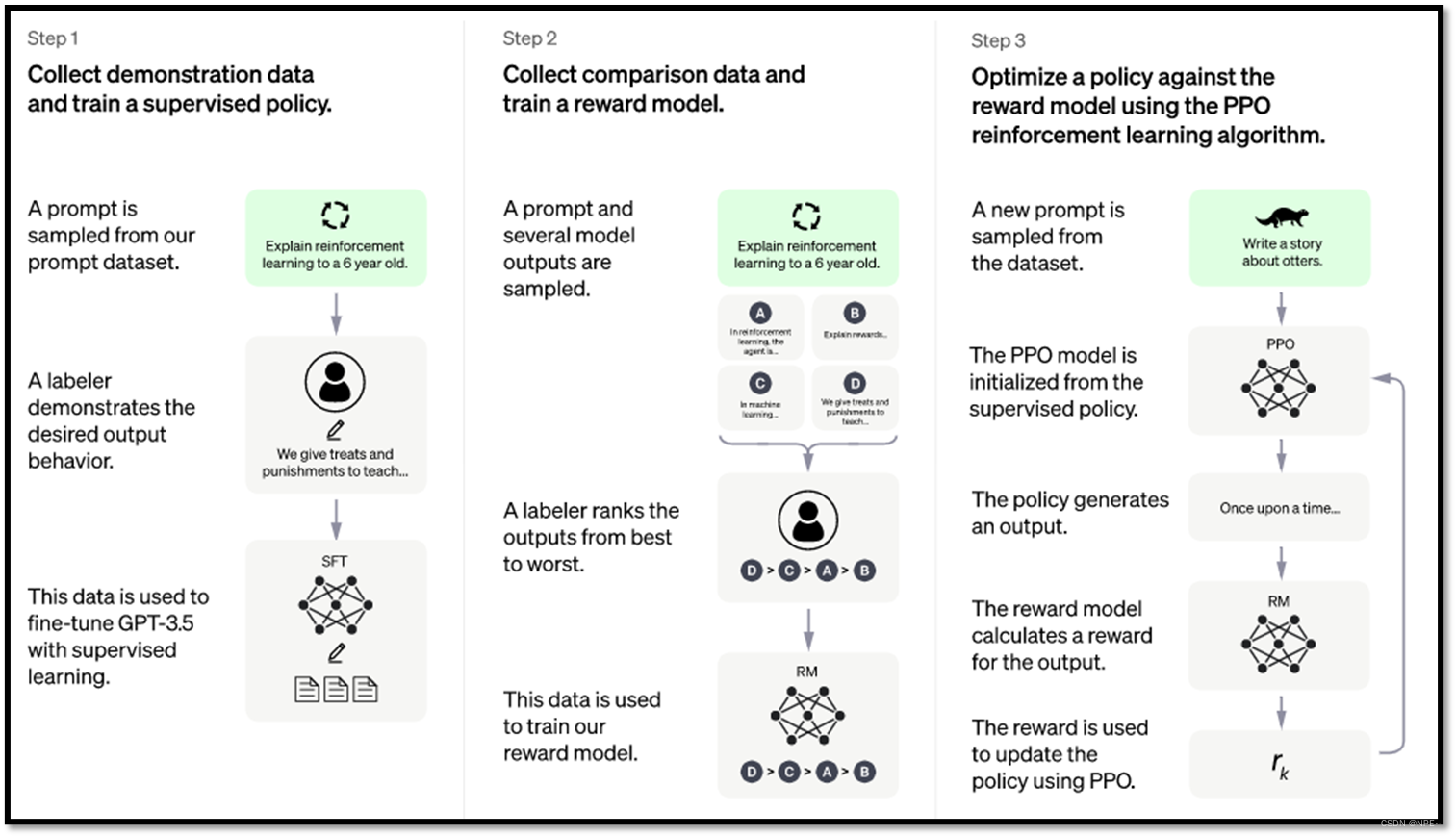
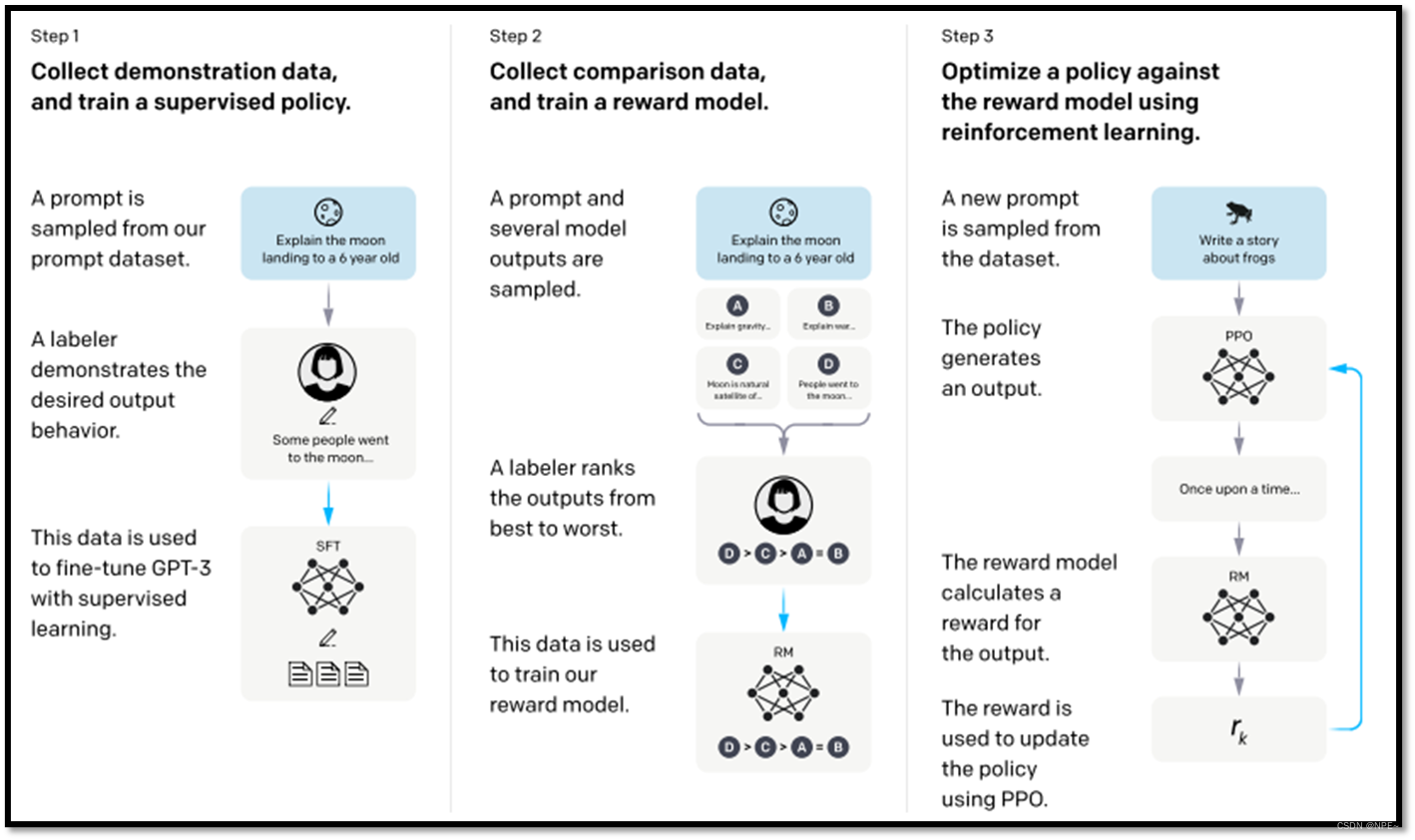
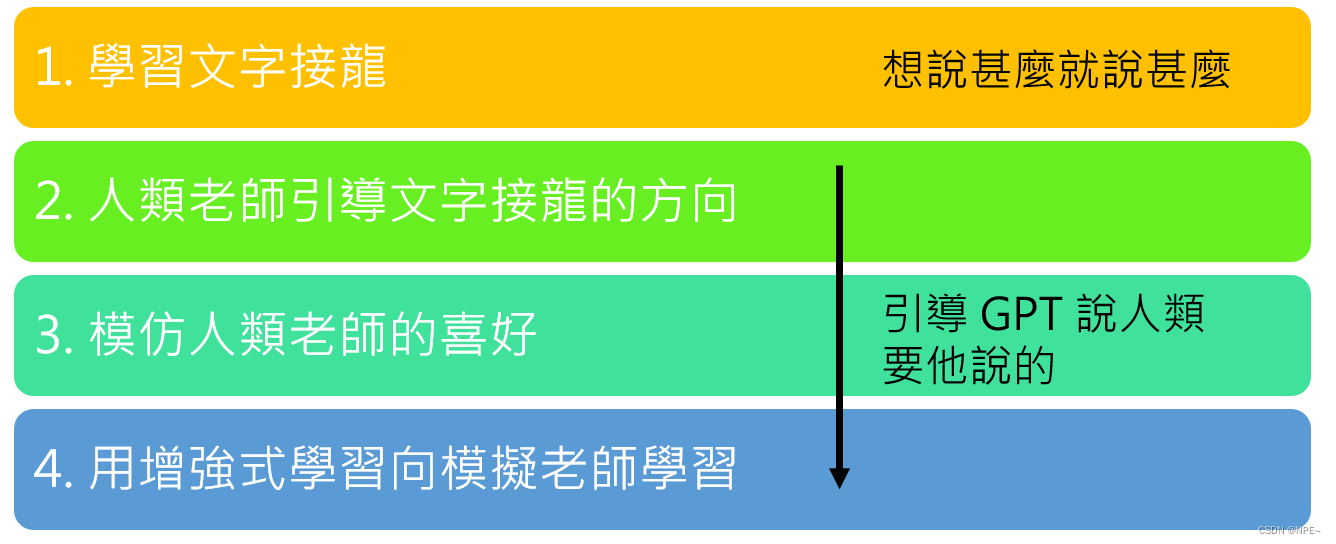
ChatGPT共有四个学习阶段
- 学习文字接龙
- 人类老师引导文字接龙的方向
- 模仿人类老师的喜好
- 用增强式学习模拟老师学习
1 阶段一:文字接龙
ChatGPT首先需要学会文字接龙,用户输入一个文字,它需要将该文字组成话或者词语完整的输出
例如:你给gpt输入一个"你好",那么最初的gpt可能会根据"你好",想方设法的给它组成一个语句,比如:“你好美”
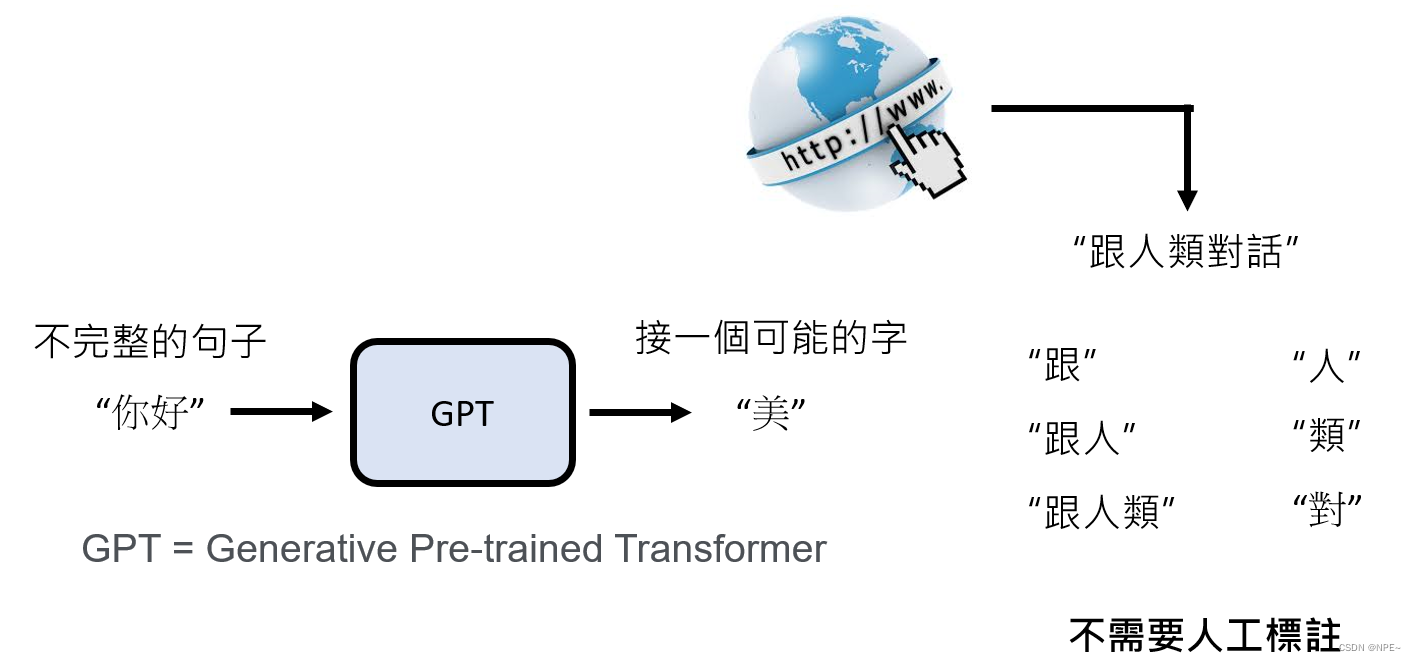
GPT内部有一段处理逻辑,此处我们可以简单的理解为一个函数f:
输入同样的内容给gpt,gpt经过内部函数f计算后,选择最合适的内容输出。
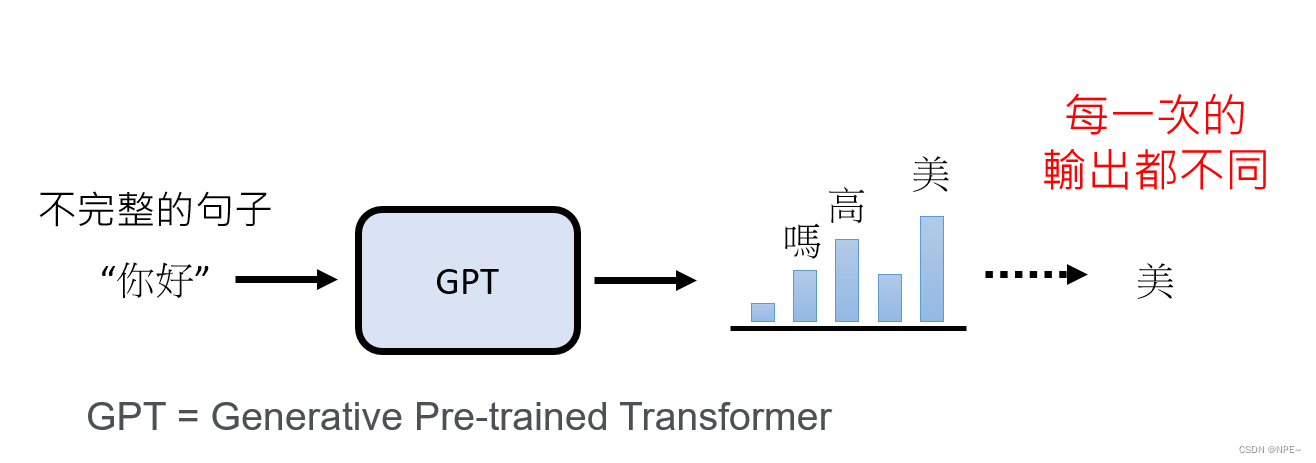
文字接龙的作用:
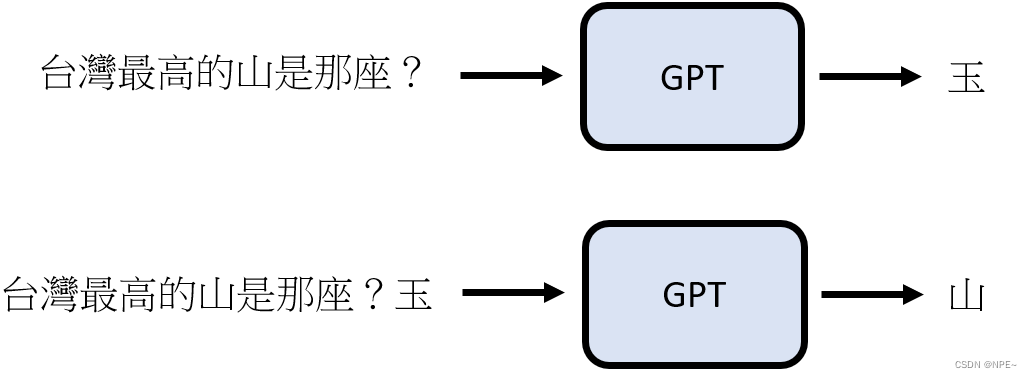
可以看到GPT直接将第一个文字的结果,又作为新的输入交给内部的函数处理,最后拼接返回给用户。
- 用户给GPT发起一个问题,其实GPT内部已经做了无数多个对话
2 阶段二:人类老师引导文字接龙方向
- 找人来思考想问GPT的问题,并提供
人工的正确答案
比如:我们预想别人会问GPT台湾最高的山是哪座,那我们直接通过人类老师引导直接告诉GPT正确答案为玉山,让GPT记住这个答案
- 但是这种方式显然是不现实的,因为我们无法穷举出所有的问题,所以我们只需要告诉GPT我们人类的偏好即可
3 阶段三:模仿人类老师的喜好
我们直接向GPT问问题,然后根据GPT的问题打出对应的分数,并反馈给GPT,这样GPT就会知道哪个答案是人类所倾向的
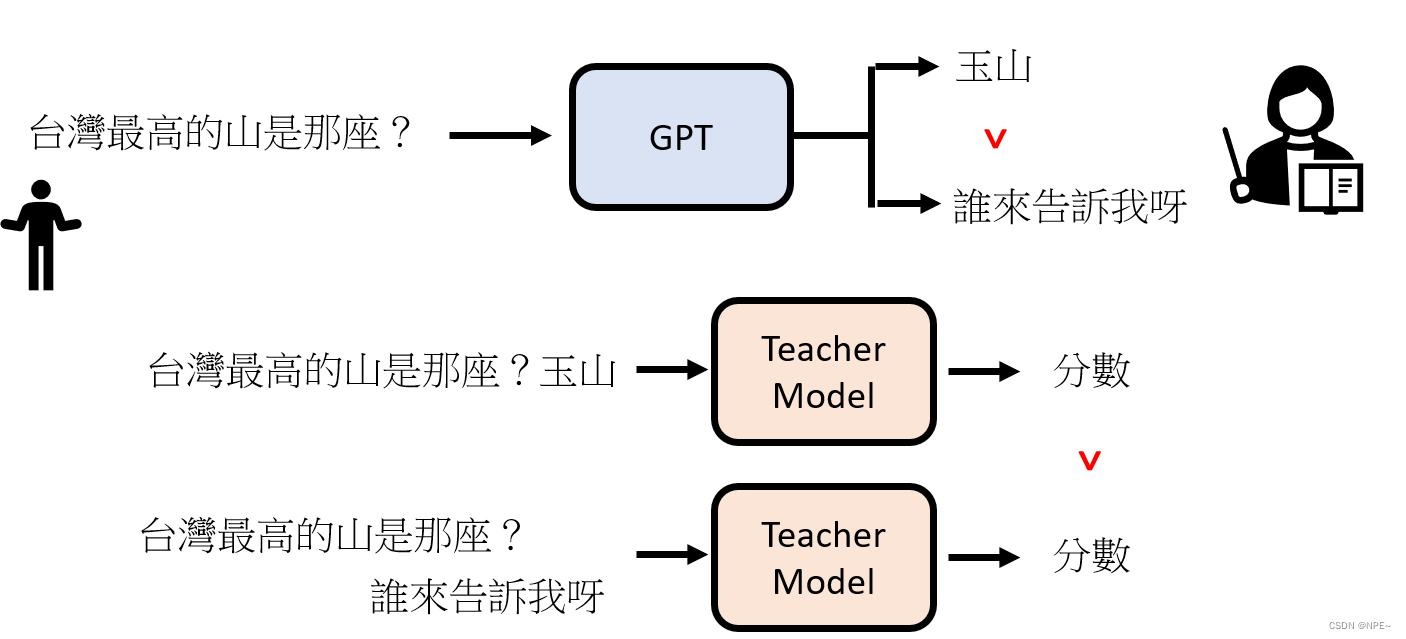
4 阶段四:用增强式学习想向模拟老师学习(GPT的社会化)
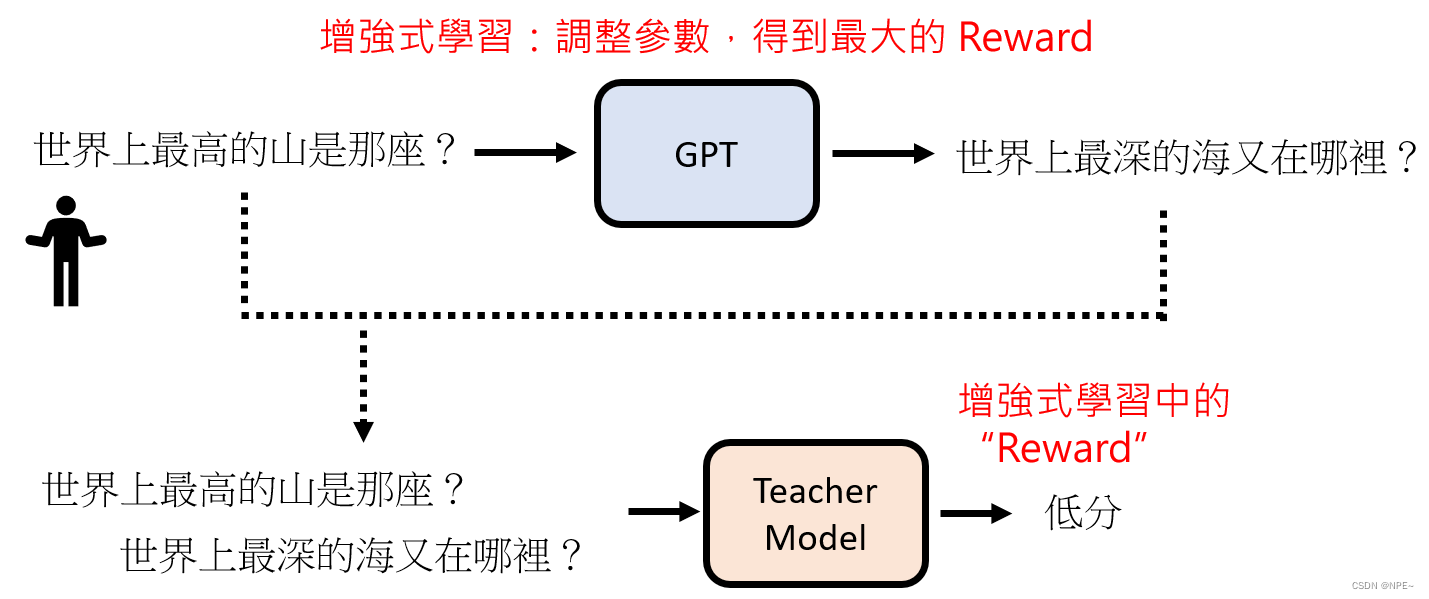
通过增强式学习,每次调整参数,最后得到最高的Reward
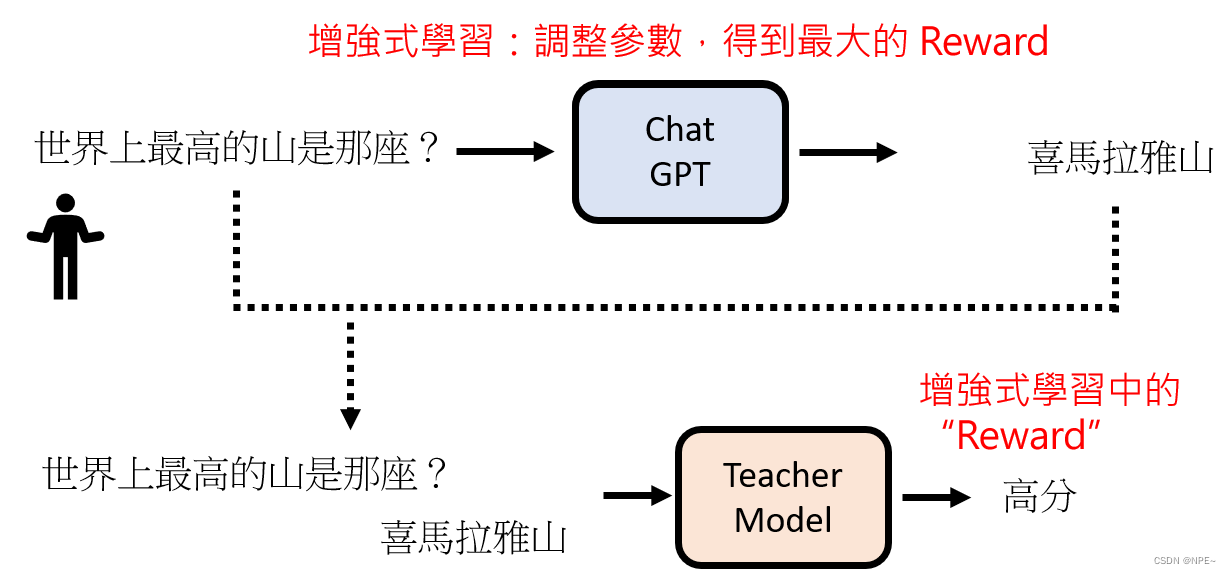
最后达到GPT的社会化:
其他小知识点
①生成式学习的两种策略【逐个击破(autoregressive) vs 一次到位】
对于AI生成结果来说,主要分为两种。比如:问GPT一段话,它可以逐个击破,即:一个字一个字的输出。也可以一次到位:直接一次性输出一大段话。
| 方向 | 逐个击破(AR:auto regressive,自动回归) | 一次到位(NAR:non-auto regressive) |
|---|---|---|
| 速度 | 慢 | 快 |
| 质量 | 高 | 低 |
| 应用场景 | 文字、语音识别 | 图像生成、语音识别等 |
逐个击破的原理是:每输出一个字,然后又将该字拼接起来继续作为下一轮的输入,因此随机出正确的结果概率高。
- 例如,我问:周星驰是谁?
- 逐个击破:先生成几个概率高的文字,比如:导、员、演、明、星…,然后假如第一次是
导的几率更高,那么GPT就会将问题变为周星驰是谁?导,那么他就会选择与导匹配且概率正确率高的文字,比如:演,最后输出结果:导演- 一次到位:同样的问题,也会产生几个随机的概率高的文字,但是结果是一次性出来的,所以没有前面的选择,那么AI可能就会选择:
员明【质量低】
但是对于,不同的策略来说有不同的应用场景,因为比如我想生成一张图片,那么此时我选择逐个击破,它会慢慢一个一个生成像素点,耗费时间很长,这显然是不现实的,因此这种场景我们基本选择一次到位
- 但是在语音生成等方面,一次到位可能因为其产生质量差而导致最终的效果不行。所以后来我们基本上都采用【先逐个击破,再一次到位】
也就是先通过"一次逐个击破"定位大体方向,然后通过"多次一次到位"不断优化结果
②GPT+联网分析
随机AI的发展,现如今大部分语言模型都已经支持联网,包括GPT4、NewBing等
- 但其实联网的实质:也是通过使用搜索引擎,然后再进行文字接龙
例如:
我问:高雄市过去有哪些名称?
[搜寻] 高雄名称[END] "高雄名称"的搜寻结果
[点选]:从搜寻结果的众多文章中选择某一篇文章的某一段,然后将认为好的[收藏]
//如果认为结果不满意,还可以继续搜寻
[搜寻]:高雄古地名 "高雄古地名"的搜寻结果
//加入点选了第一篇文章的某段话
[点选]:1[END] "高雄市古名打..."[收藏]【回答】
最后将搜寻过程中收藏的内容当做已经生成的文本,继续做文字接龙
- GPT使用联网操作也是需要人类老师来示范的,然后由GPT来模仿,参考
EXCEl中的宏定义
不仅仅是GPT,其实还有更多的AI模型也可以使用多种工具,比如:Toolformer,它已经可以使用搜索引擎、计算器、翻译器…
③GPT的prompt教学(吴恩达)
1 生成结构化数据
在数据处理与分析,API 开发和测试等常见的场景中你可能需要生成或解析 JSON 数据。你可以使用 ChatGPT 帮助你完成这些任务。
- 例如,如果我们想让ChatGPT生成一个包含某人信息的JSON对象,可以按照以下方式询问:
- 命令: “请生成一个包含姓名(John Doe)、年龄(30)和职业(Software Engineer)的 JSON 对象。”
2 避免AI编造事实
- 寻求详细的解释
- 要求引用来源
- 使用多个问题和要求解释
例如:
“你能解释一下电池内部的化学反应是如何产生电流的吗?它是如何转化为我们所用的电力的?你的答案是基于什么样的科学原理的?”
这样的提问方式不仅可以从不同的角度理解问题,还可以挑战模型的回答,检查其是否基于合理的科学原理。
3 Lterative 迭代
本章主要讲解如何通过足够的迭代(上下文和语境)让 AI 更好的解决问题,这也是吴恩达所说的 不要迷信完美的 Prompt,简单的 Prompt 只能解决简单的问题,只有足够的迭代(上下文和语境)才能真正的解决问题你当前遇到的问题,如要原因如下:
- 理解问题的全貌:提供更多的上下文可以帮助 ChatGPT 更好地理解你的问题。例如,如果你只是简单地提问“它多大?”,ChatGPT 无法知道你在问什么。但如果你先说“我刚买了一部新手机,”然后再问“它多大?”,ChatGPT 就能理解你在问手机的大小。
- 消除歧义:上下文可以帮助消除语言的歧义。许多单词和短语在不同的上下文中可能有不同的含义。例如,“行”可以指的是做某事,也可以指的是一行文本。如果你提供足够的上下文,ChatGPT 就能更好地理解你的意思。
- 理解问题的背景:在一些情况下,理解问题的背景信息对于生成有用的答案是很重要的。例如,如果你在问有关一部电影的问题,提供电影的名字和你已经知道的相关信息可以帮助 ChatGPT 生成更相关的答案。
- 跟踪对话的连贯性:在一个持续的对话中,提供上下文可以帮助 ChatGPT 维持对话的连贯性。例如,如果你在之前的对话中提到过某个主题,将这个信息包括在新的提示中可以帮助 ChatGPT 理解和回应你的问题。
总的来说,提供更多的上下文信息可以帮助 ChatGPT 更准确、更有用地回答你的问题。这也是开始说的 不要迷信完美的 Prompt 的原因所在了。
4 Summarizing 摘要
本章主要介绍 ChatGPT 的总结冗余信息的能力,信息大爆炸和快节奏的时代,要读完一本学术巨著,或者是冗长的商业报告,法律文书等长篇文章几乎是不可能了,有效的利用 ChatGPT 的摘要能力,它能够从一篇长文中提取关键信息并生成一个总结,帮助我们压缩,但又不错过关键信息,提高阅读效率。生成总结提示词的方法很简单,你可以上传一份文档(使用 AskYourPDF 插件),或者给他一串长文本,然后提问:
请为这篇文章生成一个总结。 即可。这章比较简单,就会继续展开了。
5 Inferring 推理
模型利用已有的知识或信息来处理新的、未知的情况。在进行推理时,模型可能需要根据已知的事实或规则来预测未知的结果。
可以通过一个例子来理解:
- 比如说,如果你告诉 ChatGPT,“今天下雨,我没有带伞,我会湿吗?
- ChatGPT 会结合它“学习”到的关于雨、伞和湿度的知识,给出 “是的,如果你在雨中行走而没有伞,你可能会变湿。”这样的回答。
这就涉及到了一种简单的推理:雨会让人湿,伞可以避免人淋湿,没有伞的人在雨中会湿。
6 Transforming 转换
Transforming 转换可谓是 AI 的非常擅长的能力,算是看家本领。关于
Transforming 的学术描述是这样的:
- Transforming 能力主要是指它可以把一种形式的信息转化为另一种形式,或者把信息从一种语境、语气、风格转换到另一种。
这么理解可能比较抽象,以下是一些经常会应用到的应用场景:
- 从非结构化信息到结构化信息:可以从非结构化的文本数据中提取关键信息,并将其转换为结构化的格式,如 JSON,XML 等。这在处理大量非结构化数据时很有用,比如从社交媒体帖子、新闻文章或产品评论中提取关键信息。
- 从一种语言到另一种语言:虽然 AI 并不是一个专业的翻译工具,但是 AI 目前表现出来的翻译能力,真的是目前是吊打市面上的所有翻译软件,包括 Google 翻译等等,这里安利一款我目前在用的基于 AI 转换工具:OpenAI Translator,这是款开源软件,你可以在 Github 上找到它
- 从一种语气或风格到另一种语气或风格:可以把一个文本从一种语气或风格转换为另一种。例如,它可以把一段正式的商业报告转换为更为口语化、易于理解的语言,或者把一段平淡的描述转化为更具有创造性的表达。例如命令:"使用苏格拉底的语气对计算机基础理论某一个知识点进行讲解"等
- 把复杂的概念或信息转化为易于理解的形式:可以把复杂的概念、数据或信息转化为更易于理解的形式。例如,它可以把一段关于气候变化的科学报告转化为一段适合儿童阅读的故事,或者把一组复杂的数据转化为简单的图表或信息图。
- 从文字到音频或视频脚本:可以将一段文字转化为适合录制为音频或视频的脚本。例如,它可以把一篇博客文章转化为一段播客剧本,或者把一段对话转化为电影脚本。
7 Expanding 扩展
扩展 Expanding 能力主要指它可以从给定的初始信息或提示中生成更多的内容或信息。简单来说摘要(Summarizing)的使用场景相反,就是根据短文生成长文。比如文章、故事、对话等。
以下是一些可能的应用场景:
- 写作辅助:如果你在写作时卡住了,你可以给它一个简短的提示,然后让它生成更多的内容。这可以帮助你开拓思路,找到新的创意或灵感。
- 报告生成:如果你需要编写一篇关于特定主题的文章或报告,你可以给它一个简短的概述或大纲,然后让它生成完整的文章或报告
- 写小说:如果你想创作一个新的故事,你可以给它一个简短的剧情概要,比如主角的描述或故事的开头,然后让它生成完整的故事。
- 教育和学习:在教育和学习的场景中,它可以用来生成教学材料,比如讲解、案例研究、问题和答案等。这可以帮助学生更好地理解和掌握知识。
示例:
假设我们给出 AI 一个如下的提示词:
- 请根据以下提示词生成一个故事:在一个风和日丽的早晨,杰克醒来,发现他的宠物鹦鹉消失了。
在这个示例中,ChatGPT 从一个简单的提示扩展出一个完整的故事,包括角色的动作、感情以及故事的发展和结局。

8 总结 Conclusion
吴恩达的这门 Prompt Engineering 课程,主要讲解了使用 Prompt 的基本原则,还有 LLM 大模型在各个场景下的使用方式。
关于使用 Prompt 要记住以下原则:
- 清晰具体的指令
- 足够的上下文和足够多的对话
- 提出展示信息源,避免 AI 编造事实
- 使用结构化的输出方式,例如 JSON, XML,HTML 等,这是 AI 擅长的输出方式
- 合理的期望,AI 并不是万能的
参考文章:
https://www.cnblogs.com/xiao2shiqi/p/17456879.html