Harvest: A high-performance fundamental frequency estimator from speech signals一种基于语音信号的高性能基频估计算法
Harvest的独特之处在于可以获得可靠的F0轮廓,减少了将浊音部分错误地识别为清音部分的错误。
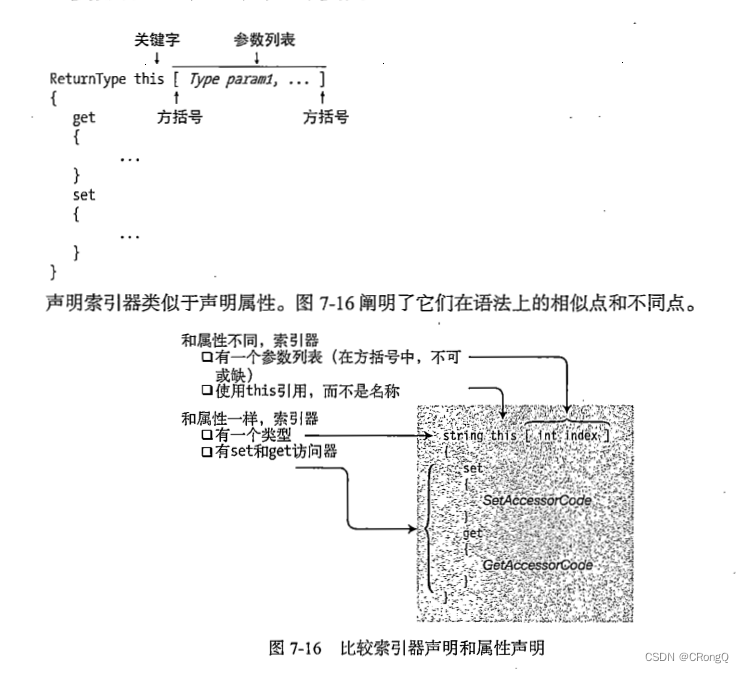
它包括两个步骤:估计F0候选点和在这些候选点的基础上生成可靠的F0轮廓。
在第一步中,算法使用多个不同中心频率的带通滤波器提取基本分量,从滤波信号中得到基本F0候选值;然后利用瞬时频率对基本F0候选对象进行细化和评分,然后估计出每帧中的几个F0候选对象。由于基于基本成分提取的逐帧处理对时间局部噪声的鲁棒性较差,在第二步中使用了使用相邻f0的连接算法。这种连接利用了F0等高线在短时间内不会急剧变化的事实。
引言
语音参数(基频(F0)、频谱包络和非周期性)被广泛用于统计参数语音合成SPSS。由于SPSS需要大量的语音数据进行训练,高性能的语音分析仪不仅可以提高音质,还可以避免手工进行后期处理。现在有很多语音分析方法,哪种合适取决于研究的目的。例如,实时语音转换需要一个实时F0估计器,而SPSS通常优先考虑估计精度而不是实时性。
在最近的SPSS中,使用连续F0建模的深度神经网络(DNNs)已被使用。该F0建模通过样条插值方法对清音部分给出一定的F0。此建模首选的F0估计器应该具有为所有帧提供平滑F0轮廓的功能。因此,Harvest旨在减少将浊音部分错误地识别为清音部分。
相关研究
传统的F0估计器使用波形特征和功率谱。在基于波形的算法中,提出了平均幅差函数[7]和加权自相关。YIN是一个主要的估计算法,并在2014年开发了改进版本。在基于功率谱的算法中,基于倒谱的方法比较流行,SWIPE作为一种高性能的F0估计器最近被提出。
对于实时语音分析/合成应用,如DIO及其改进版本。
对于高质量的语音分析/合成系统,NDF用于STRAIGHT, XSX用于TANDEM-STRAIGHT为首选。
具体算法
第一步:F0候选值估计
目的:收集所有F0候选值,即使它们包含估计错误。在每帧中获得许多F0候选项及其可信度分数。
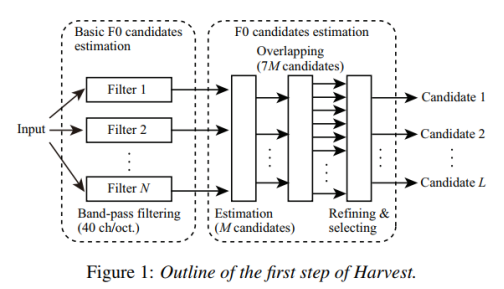
1.估计基本的F0候选值
首先,将语音波形输入到多个中心频率不同的带通滤波器进行滤波。滤波器h(t)由纳托尔窗w(t)与正弦波相乘。这与YANGsaf的想法相似。
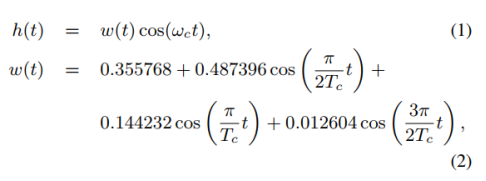
式中,ωc和Tc分别为滤波器的中心频率和周期(Tc = 2π/ωc)。滤波器的取值范围为−2Tc < t < 2Tc。功率谱的一个例子如图2所示。该滤波器可以提取基波分量,只要它包含在ωc Hz附近的范围内。将中心频率设置为从floor到ceiling每40ch/oct划分。
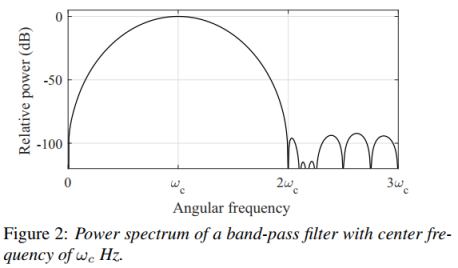
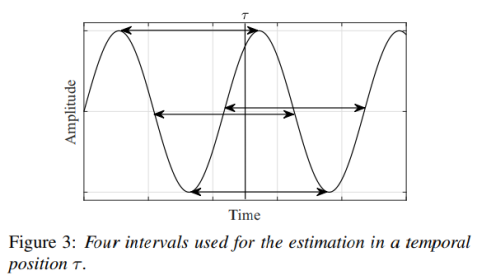
当只提取到基本分量时,输出信号波形正好为正弦波。此时,图3所示的波形四个间隔值相同(说明提到了基频或谐频)。四个间期的平均值的倒数,就是F0候选值。Harvest去除ωc±10%范围以外的估计候选值。
2.从基本候选F0中再估计候选F0(筛选)
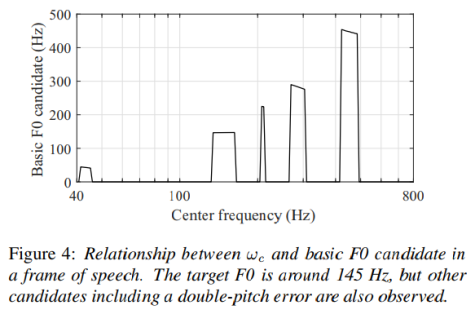
图4显示了语音框架中中心频率ωc和基本候选F0之间的关系。当基本候选F0来自基波分量时,在一定带宽内观察到相同的值(梯形上面),因为中心频率在wc附近的滤波器输出的几乎都是相同的波形。当滤波器在一定带宽内输出相同的基本F0候选时,Harvest获得候选F0。我们把这个带宽设为ωc ± 10% Hz。
3.重叠F0候选值
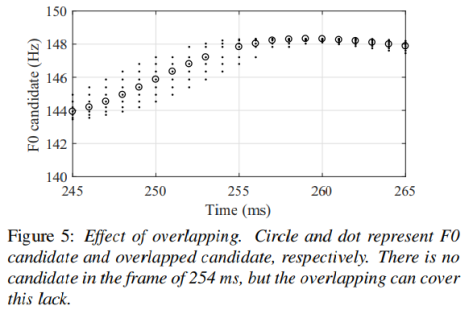
由于该算法的精度取决于每帧的信噪比,因此由于噪声的影响,通常会出现没有候选帧的情况。Harvest将所有F0候选值重叠3毫秒。
如:图5显示了重叠效果的一个示例。圆圈和圆点分别代表F0候选点和重叠候选点。在这个例子中,第254毫秒的帧中没有候选帧,但是重叠可以弥补这个不足。接下来的过程中,所有的F0候选项都被细化并通过瞬时频率进行评分。
4.对所有F0候选值通过瞬时频率进行细化
如图4所示,不仅对目标F0进行了估计,还对几个误差进行了估计。为了有效地选择目标F0, Harvest利用瞬时频率对所有候选F0进行细化和评分。
瞬时频率即波形相位的导数。采用Flanagan公式[31]计算瞬时频率ωi(ω,t):
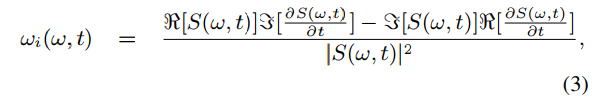
其中S(ω, t)表示位移为t的窗函数,加窗的波形的频谱。Harvest使用Blackman窗,窗长为3T0,周期T0是候选值F0的倒数。R[x]和ζ[x]为输入信号x的实部和虚部。
周期信号的瞬时频率是指频率在F0附近时接近F0的值。由于F0附近的频谱具有更大的功率,因此这种细化比通过滤波提取基本分量更健壮。因此,即使候选F0包含一定数量的噪声误差,也可以将F0细化为更精确的F0。
实际的细化是用下面的公式进行的。在时间位置t处的细化F0候选值ω0:
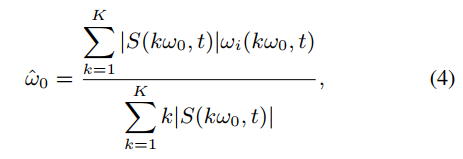
其中ω0表示候选值F0在时间位置t的角频率,K表示用于细化的谐波数。由于语音具有谐波结构,使用一些谐波成分有助于语音的细化。在Harvest中将谐波K的个数设置为6。
细化前的候选F0等于目标F0的情况下,候选F0和细化后的候选F0表示相同的值。同理,ωi(kω0, t)表示kω0。因此,它们之间的差异可以用作可靠性评分。分数r为:
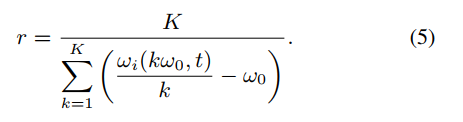 在此处理过程中,分数低于2.5的F0候选值将被删除。
在此处理过程中,分数低于2.5的F0候选值将被删除。
第二步:在估计候选F0的基础上生成最佳F0轮廓
在第一步中,每帧得到多个F0候选图像。第二步的目的是从所有候选F0中生成可靠的F0轮廓。首先,选取可靠性最高的F0候选轮廓作为基本F0轮廓。
1.删除不需要的候选F0
由于浊音是周期信号,根据F0的定义,F0轮廓在一个基本周期内不会发生快速变化。因此将超过阈值的快速变化的F0删除,并将此帧计算为清音部分。图6显示了可以算作浊音部分的频率范围。
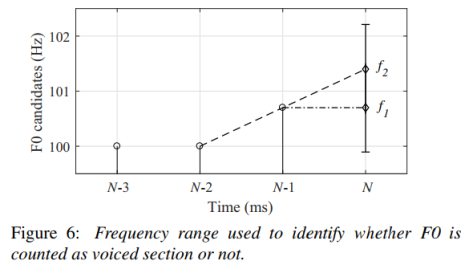 N ms内的频率范围由N−1和N−2 ms处的F0s决定。两个频率f1和f2分别计算为f0(N−1)和2f0(N−1)- f0(N−2)。如果N ms的F0候选值不在f1±0.8%或f2±0.8%的范围内,则将其移除。
N ms内的频率范围由N−1和N−2 ms处的F0s决定。两个频率f1和f2分别计算为f0(N−1)和2f0(N−1)- f0(N−2)。如果N ms的F0候选值不在f1±0.8%或f2±0.8%的范围内,则将其移除。
2.去除过短的浊音部分
F0轮廓至少具有基本周期的长度,并且噪声可能偶然导致具有短周期的连续F0。长度低于阈值的短浊音段将被删除并计算为非浊音段。我们将阈值设置为6毫秒,以便删除不需要的部分。
3.扩展每个浊音部分
每个浊音部分通过使用清音部分的F0候选值扩展。用浊音帧N ms处的F0候选值来确定清音帧N + 1 ms处的F0。如果在N + 1 ms时最接近的候选f0包含在f0 (N)±18%的范围内,则选择并扩展为浊音帧。如果在N + 1 ms内没有F0候选,则在下一帧N + 2 ms内进行相同的处理。如果在N + 1 ~ N + 3ms内没有F0候选节点,则扩展过程结束。最大扩展限制为100ms。
这种扩张是在前后方向上进行的。扩展后harvest会再次移除短浊音部分。阈值设置为2200 / fms,其中f是浊音部分F0s的平均值。当扩展的F0等高线重叠时,选择重叠部分中平均可靠度得分较高的F0等高线。
4.F0轮廓的插值和平滑
因为Harvest的目的之一是防止浊音部分被误识别为清音部分,短清音部分被修改为F0s。将9 ms周期内的非浊音部分作为浊音,该部分的f0由其边界的前后浊音部分的f0之间的线性插值得到。
连接的F0轮廓在每个浊音部分通过零延时巴特沃斯滤波器平滑。清音部分中的f0由每个边界中的f0填充。平滑后,清音部分的F0被重置为0。平滑结果也是Harvest估计的最终F0轮廓。我们将滤波器的阶数设置为2,截止频率设置为30 Hz。