目录
- Problems of Lexical Database 词汇数据库的问题
- 分布假设
- 根据上下文猜测单词含义
- Word vectors 词向量
- 词嵌入
- Count-based Word Vectors 基于计数的方法
- Document as Context: The Vector Space Model 向量空间模型
- TF-IDF
- Dimensionality Reduction 降维
- Words as Context 单词作为上下文
- Pointwise Mutual Information(PMI) 点互信息
- Word Embeddings 词嵌入
- 用于嵌入的神经网络模型
- Word2Vec
- Skip-gram Model Skip-gram 模型
- Word Similarity
- 嵌入展示有意义的几何关系
- Word Analogy
- 评估词向量
- Downstream Tasks 下游任务
- General Findings
这节课我们继续学习语义学相关内容,这次我们不再关注单词层面的语义学,而是从语料库中直接学习单词含义,这个领域也被称为 分布语义学(Distributional Semantics)。
Problems of Lexical Database 词汇数据库的问题
-
Manual constructed 需要手工构建
- Expensive 成本高
- Human annotation can be biased and noisy 人类的注解可能存在偏见和噪音
-
Language is dynamic 语言是动态的
- New words 新的单词:俚语、专业术语等等
- New senses 新的词义(senses)
-
The Internet provides us with massive amount of text. Using these text to obtain word meanings. 互联网为我们提供了大量的文本,我们可以利用它们获得单词含义吗?
分布假设
- “You shall know a word by the company it keeps(你可以通过其周围的上下文单词来了解一个目标单词)” —— (Firth, 1957)
- 共现文档通常指示了主题(文档(document) 作为上下文)。
- 例如:voting(投票)和 politics(政治)
- 如果我们观察文档,会发现这两个单词经常出现在同一文档中。因此,不同单词的共现文档在一定程度上反映了这些单词在某种主题方面的关联。
- 局部上下文反映了一个单词的语义类别(单词窗口(word window) 作为上下文)。
- 例如:eat a pizza, eat a burger
- 可以看到,pizza 和 burger 这两个单词都具有共同的局部上下文 eat a,由此我们可以知道这两个单词都具有和 eat a 相关的某种含义。
根据上下文猜测单词含义
- 根据其用法来学习一个未知单词。
- 例如:现在我们有一个单词 tezgüino,我们并不知道其含义,我们试图通过从该单词的一些用法中学习到其含义。下面是该单词出现过的一些例句:
作为人类,通过结合常识,我们可以大概猜测到 tezgüino 可能是某种含酒精饮品。

- 我们再查看一下在相同(或者类似)上下文中的其他单词的情况。
可以看到,单词 wine 出现过的类似场景最多。因此,尽管我们并不知道 tezgüino 的具体含义,我们还是可以认为 tezgüino 和 wine 在单词含义方面非常相近。

Word vectors 词向量
在前面的例子中,我们可以将这些由 0 和 1 组成的行视为词向量,因为它们能够很好地代表这些用例。例如:给定 100 个非常好的例句,我们可以基于这些单词是否出现在这些例句中,将其转换为 100 维的向量。

-
Each row can be thought of a word vector 每一行都可以视为一个 词向量(word vector)。
-
It describes the distributional properties of a word 它描述了单词的分布特性(目标单词附近的上下文单词信息)。
- Encodes information about its context words 对其上下文单词的信息进行编码
-
Capture all sorts of semantic relationships 捕获各种语义关系,例如:同义(synonymy)、类比(analogy)等。
词嵌入
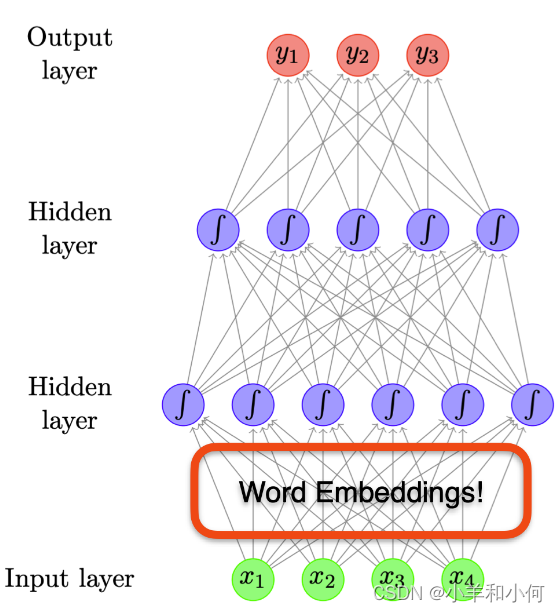
- 在之前的神经网络的章节中,我们已经见过另一种词向量:词嵌入(word embeddings)。
- 例如:在使用前馈神经网络进行文本分类时,第一层相当于是词嵌入层,该层的权重矩阵即词嵌入矩阵。
- 这里,我们将学习通过其他方法产生词向量:
- 基于计数的方法
- 专为学习词向量而设计的更高效的神经网络方法
Count-based Generation of Word Vectors
Count-based Word Vectors 基于计数的方法
- Generally two flavors: 一般来说有两种风格
- Use document as context 使用文件作为上下文
- Use neighboring words as context 使用邻近的词作为背景
Document as Context: The Vector Space Model 向量空间模型
-
Core idea: Represent word meaning as a vector 核心思想: 将词义表示为向量
-
Consider documents as context 通常,我们将 文档(documents)视为上下文。
-
One matrix two viewpoints: 一个矩阵,两种视角
- Documents represented by their words 一个文档由其所包含的单词表示
- Words represented by their documents 一个单词由其出现过的文档表示
-
E.g.:

这里,每一行都表示语料库中的一个文档,每一列表示语料库的词汇表中的一个单词,单元格中的数字表示该单词在对应文档中出现的频率。例如:单词 state 没有在文档 425 中出现过,所以对应的值为 0,但是它在文档 426 中出现过 3 次,所以对应值为 3。
当我们构建完成这样一个矩阵后,我们可以从两种视角来看待它:如果我们观察每一行,我们可以将其视为每个文档的词袋模型表示;如果我们观察每一列,我们可以将其视为每个单词的词向量表示。 -
Manipulating VSM: 操作 VSM
一旦我们构建了一个向量空间模型,我们可以对其进行一些操作:- Weighting the values 给值进行加权(不仅是频率):我们可以对矩阵中的值进行一些除了词频之外的更好的加权方式。
- Creating low-dimensional dense vectors 创建低维的密集向量:假如我们有非常多的文档,例如 100 万个,那么我们的词向量的维度也将会是 100 万维,因为每个维度都代表一个文档。但是,这样的话词向量的维度过高了,并且非常稀疏,其中大部分维度的值都是 0。
- 一旦我们完成了这些,我们就可以比较不同的词向量,并计算彼此之间的相似度等等。
TF-IDF
首先,我们学习一种比单纯的词频更好的加权方法:TF-IDF (Term Frequency-Inverse Document Frequency)。它是 信息检索(information retrieval)领域的一种标准加权方案。
-
Term Frequency - Inverse Document Frequency
-
Standard weighting scheme for information retrieval
-
Discounts for common words:
whereDis the count for total documents and dfw is the counts for documents that has wordw -
E.g.

我们首先可以得到一个 TF(term-frequency)矩阵,和之前一样,单元格中的数字表示该单词在对应文档中出现的频率。
然后,我们将计算该单词对应的 IDF(inverse document frequency)值。
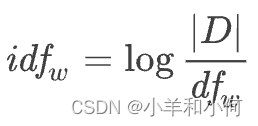
其中,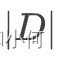 表示文档总数。
表示文档总数。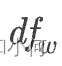 表示单词
表示单词 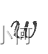 的文档频率,即该单词在所有文档(即语料库)中出现的总次数(TF 矩阵中最后一行)。这里,
的文档频率,即该单词在所有文档(即语料库)中出现的总次数(TF 矩阵中最后一行)。这里, 的底数为 2。
的底数为 2。
例如:假设一共有 500 个文档,单词 “the” 的 df 值为 500,那么这里单词 “the” 的 IDF 值为:
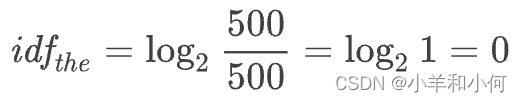
分别计算每个单词的 IDF 值,并将其和对应单元格的 TF 值相乘,我们可以得到下面的 TF-IDF 矩阵

可以看到,单词 “the” 对应的列的值都为 0,这是因为其 IDF 值为 0,所以无论对应单元格的 TF 值为多少,相乘后得到的结果都是 0。
TF-IDF 的核心思想在于:对于在大部分文档中都频繁出现的单词(例如:“the”),我们给予更低的权重,因为它们包含的信息量很少。
Dimensionality Reduction 降维
-
Term-document matrices are very sparse Term-document 矩阵过于 稀疏(sparse)
-
Dimensionality reduction: create shorter, denser vectors 降维(Dimensionality reduction):创建更短、更密集的向量。
-
More practical because there are fewer features 更实用(特征更少)
-
Remove noise therefore avoid overfitting 消除噪声(更好地避免过拟合)
-
Singular Value Decomposition 奇异值分解(SVD)
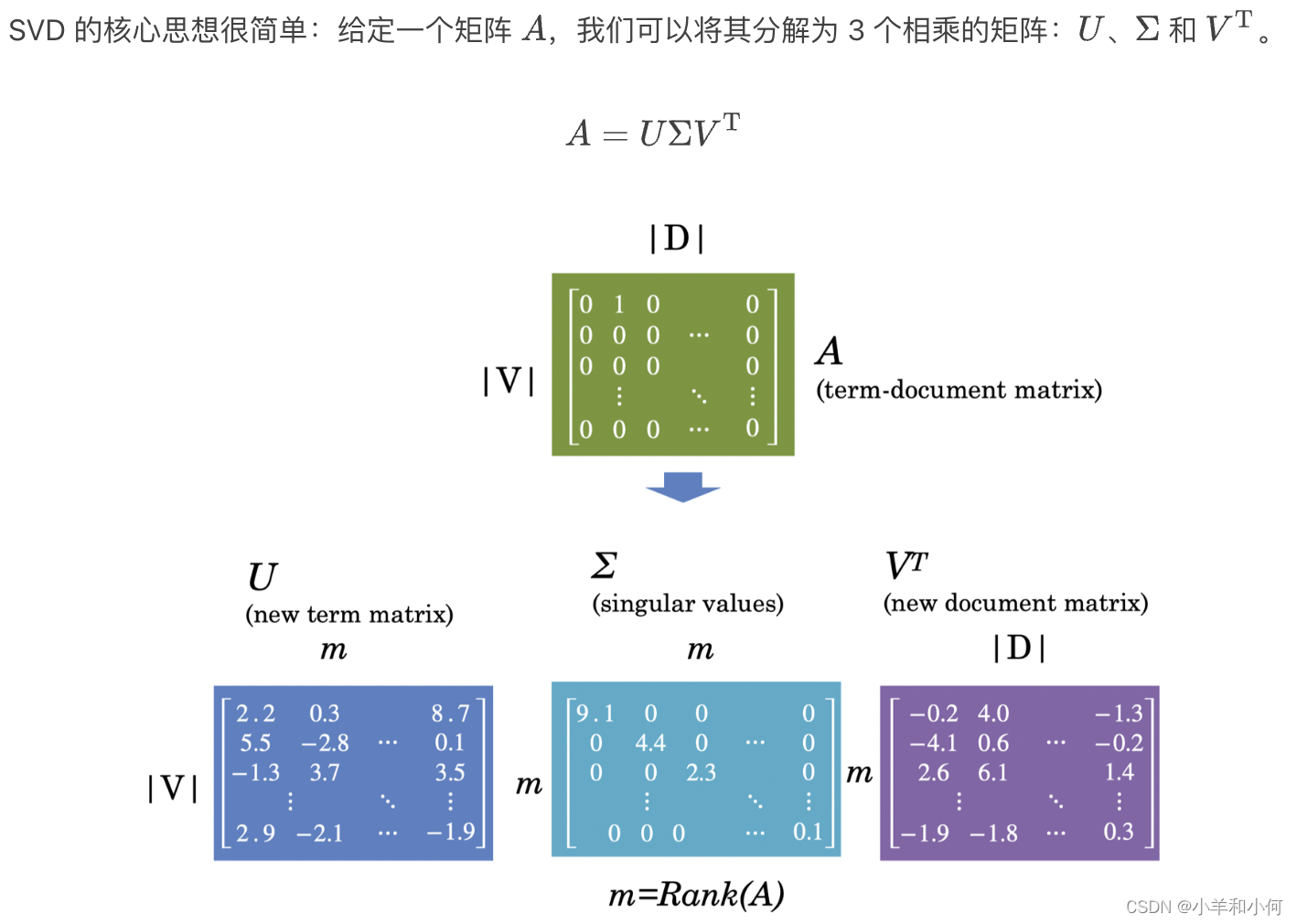

-
Truncating: Latent Semantic Analysis 截断:潜在语义分析(LSA)
我们还可以在 SVD 的基础上更进一步,采用 截断(truncating)方法,也被称为 潜在语义分析 (Latent Semantic Analysis, LSA)。- Truncating
UΣandVto k dimensions produces the best possible k rank approximation of original matrix - Uk is a new low dimensional representation of words
- Typical values for k are 100-5000
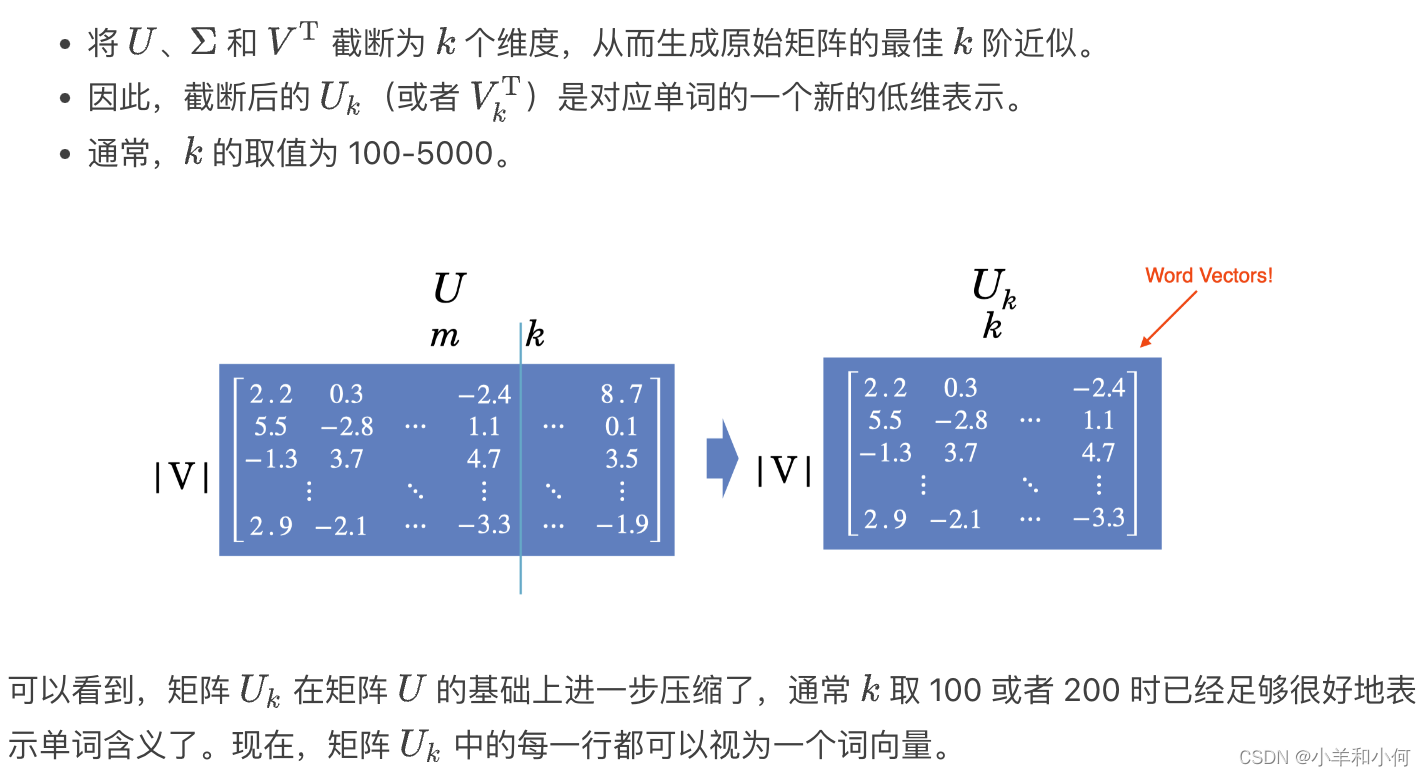
- Truncating
Words as Context 单词作为上下文
我们已经学习了将文档作为上下文,我们还可以将单词作为上下文。
-
List how often words appear with other words in some predefined context 构建一个矩阵,关于目标单词随着其他单词一起出现的频率。
- 在某些预定义的上下文中(通常是一个窗口)。
- 相比将文档作为上下文,我们可以选择目标单词附近固定范围内的某些单词作为上下文。例如:我们可以选择窗口大小为 5,即目标单词前后长度为 5 的范围内的单词作为上下文单词。
-
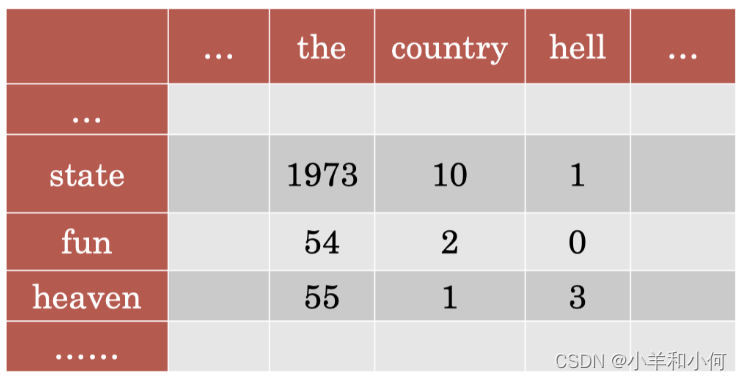
可以看到,在上面的矩阵中,每一行都表示一个单词,每一列也表示一个单词。单元格中的数字表示目标单词和上下文单词在整个语料库中所有大小为 5 的窗口内(即从语料库中提取所有的 five-grams)共同出现的频率。
-
The obvious problem with raw frequency: Dominated by common words. But we cannot use TF-IDF 但是,原始频率存在一个明显的问题:整个矩阵被常见单词所主导。
- 例如:我们可以看到,由于单词 “the” 出现频率很高,使得对应单元格内的值非常大。之前,我们采用 TF-IDF 加权来给予常见单词的值一个折扣。但是这里,我们无法采用 TF-IDF,因为这里我们没有涉及到文档。相应地,这里我们可以采用点互信息(PMI)的方法来处理这个问题。
Pointwise Mutual Information(PMI) 点互信息
点互信息(Pointwise Mutual Information,PMI)的思想非常简单,对于两个事件 x 和 y(即两个单词),PMI 计算二者的差异。
-
For two events
xandy, PMI computes the discrepancy between:- Their joint distribution:
它们的联合概率分布
- Their individual distributions assuming independence:
它们各自的概率分布(假设彼此之间互相独立)
- Their joint distribution:
-
Formulation:
-
E.g.


-
PMI Matrix: PMI 矩阵
我们可以按照前面的方法计算所有单元格的 PMI,从而得到 PMI 矩阵。
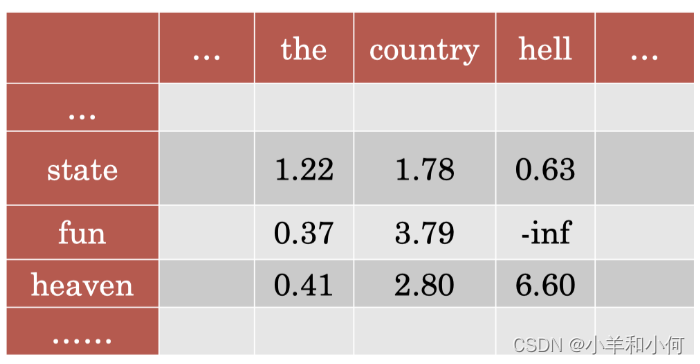

-
PMI Tricks: PMI 技巧
我们可以采取一些技巧来避免 PMI 的一些问题:- Positive PMI: Zero all negative values. Avoid
-infand unreliable negative values 将所有负值取 0(PPMI),避免了-inf和不可靠的负值,该方法在实践中效果很好。 - Normalized PMI: Counter bias towards rare events. 处理罕见事件的偏见问题
方法类似之前 n-grams 中的平滑概率。
- Positive PMI: Zero all negative values. Avoid
-
SVD:
- Regardless of whether we use document or word as context, SVD can be applied to create dense vectors
- 我们已经学习了将文档作为上下文的 TF-IDF 矩阵,以及将单词作为上下文的 PMI/PPMI 矩阵。很重要的一点是,无论我们采用文档还是单词作为上下文信息,我们都可以利用 SVD 来创建密集向量。但是,通过不同的上下文信息所捕获到的关系是不一样的,如果我们采用 TF-IDF,我们捕获到的语义学信息会更加宽泛,通常和某种主题关联;如果我们采用 PMI/PPMI,我们捕获到的词向量更多是关于局部单词上下文的语义学信息。
-
相似度:
- 词相似度(Word similarity)= 词向量之间的比较(例如:余弦相似度,cosine similarity)。
- 根据向量空间中的 邻近度(proximity)查找 同义词(synonyms)。
- 自动构建词汇资源
- 将词向量作为分类器中的特征:相比其他输入形式(例如词频等)更具鲁棒性。
- 例如:movie vs. film 二者的词向量距离实际上非常近。
Neural Methods for Word Vectors 神经网络方法
我们已经介绍了利用 SVD 结合 TF-IDF 或者 PMI 等方法创建单词的密集向量,我们也可以利用神经网络完成同样的事情。
Word Embeddings 词嵌入
- Word embeddings are just by-product of neural network models
- 在之前章节中,我们已经见过神经网络(前馈或循环)使用的 词嵌入 (word embeddings)。
- 但是这些模型是为其他任务设计的:
- 分类
- 语言模型
- 词嵌入只是这些模型的一部分。
用于嵌入的神经网络模型
- 我们可以设计专用于学习词嵌入的神经网络吗?
- 理想模型:
- 无监督
- 我们希望该模型是无监督的,因为有监督模型需要标签信息,而标签信息需要依赖语言学专家进行手工标注。
- 高效
- 我们希望模型是高效的,因此,我们可以很容易地将其扩展到非常大的语料库上。
- 有用的表示
- 最重要的是,我们希望学习到的词嵌入能够用于各种下游任务中。
- 无监督
Word2Vec
-
神经网络启发了一些方法,试图学习单词及其上下文的向量表示。
-
Core idea: Predict a word using context words
-
关键思想:
- 目标单词的嵌入应与其相邻单词的嵌入相似。
- 并且应当与不会出现在其附近的其他单词的嵌入不相似。
-
在训练阶段,将向量点积用于向量 “比较”。
-

-
在测试阶段,我们仍然采用余弦相似度进行比较。
-
-
Framed as learning a classifier: Word2Vec 的框架是学习一个分类器,有以下 2 种算法:
- Skip-gram: Predict surrounding words of target word Skip-gram :给定目标单词,预测该单词周围的局部上下文单词。

-
CBOW: Predict target word using surrounding words CBOW:给定目标单词周围的局部上下文单词,预测位于中心的目标单词。
-
L: Use surrounding words within L positions 局部上下文是指和目标单词距离 L 个位置以内的单词,在上图的例子中,L=2。
Skip-gram Model Skip-gram 模型
-
Predicts each neighboring word given target word 根据给定的中心单词,生成相应的上下文单词。

-
Total probability is defined as 全概率被定义为:
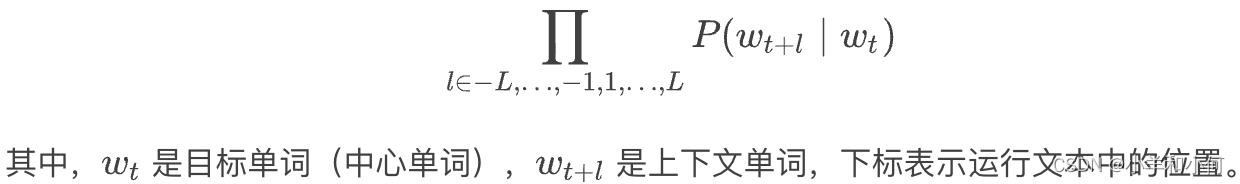
-
Using a logistic regression model:

-
Embedding parameterization: 嵌入参数化
- Two word embedding matrices (W and C) 你可能已经意识到了,这里实际上有两个嵌入矩阵:目标单词的嵌入矩阵和上下文单词的嵌入矩阵。


- Two word embedding matrices (W and C) 你可能已经意识到了,这里实际上有两个嵌入矩阵:目标单词的嵌入矩阵和上下文单词的嵌入矩阵。
-
Skip-gram Architecture:


-
Training: 训练 Skip-gram 模型
-
Train to maximize likelihood of raw text 训练目标是最大化 原始文本(raw text)的似然。
-
Too slow in practice, due to the normalization over |V| 实践中非常缓慢,因为我们需要在整个词汇表 |V| 上进行 归一化(normalisation)。
-
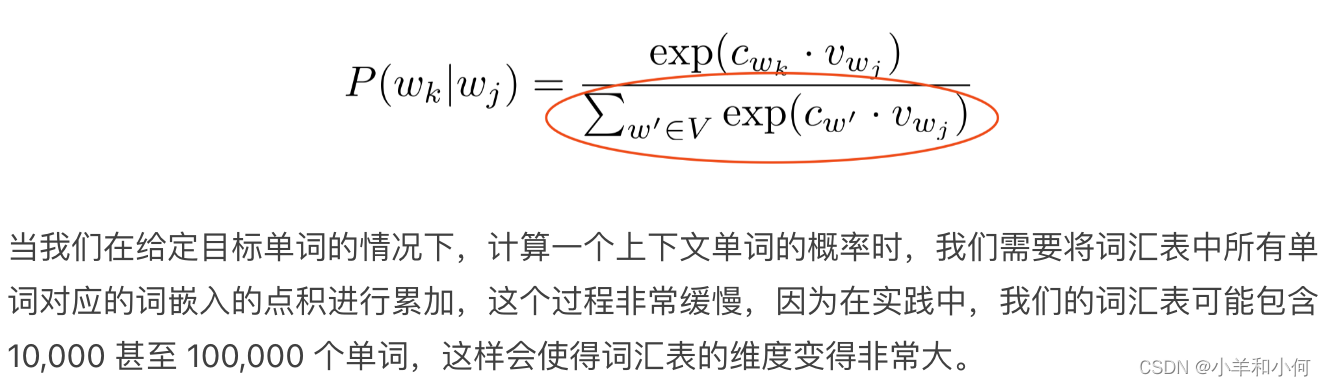
-
Therefore, reduce problem to binary classification:
-
(life, rests)-> real context word -
(aardvark, rest)-> non-context word -
Randomly draw negative samples from V
-

-
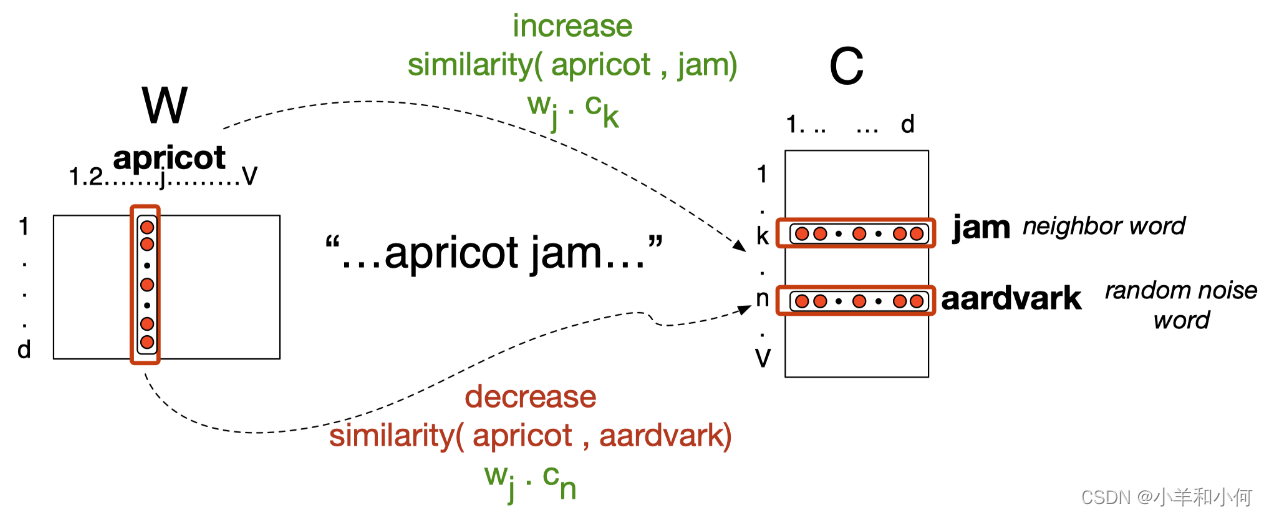
负采样
这里我们来看一个 负采样(Negative Sampling)的具体例子:


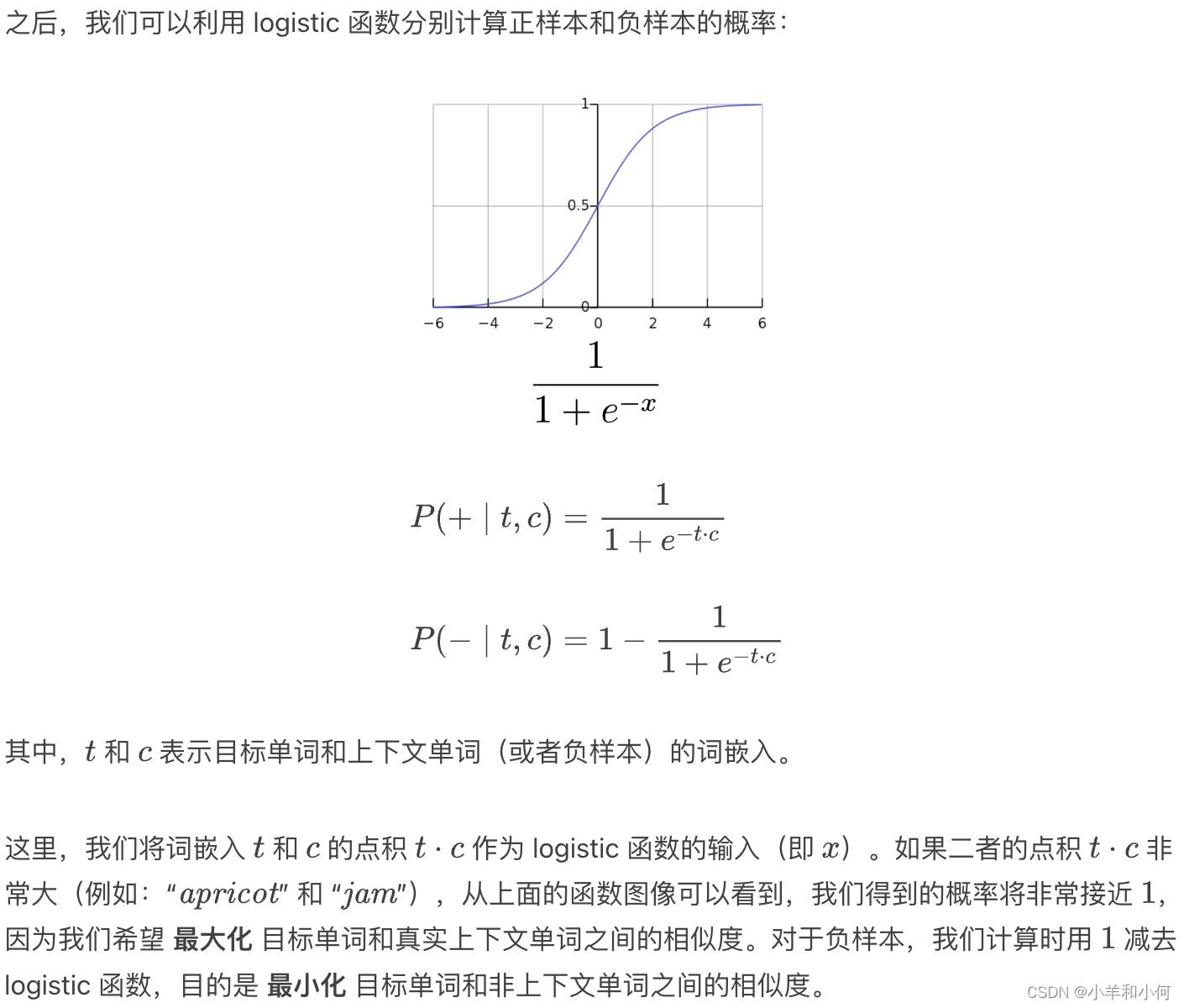
- Skip-gram 模型的损失函数

-
-
-
训练说明
- 训练过程和其他神经网络模型一样,采用 迭代 过程(例如:随机梯度下降)。
- 在每个迭代步中,我们尝试利用正样本来将目标单词和真实上下文单词的嵌入向彼此靠近的方向移动。这是由正样本的概率提供的。
- 例如:“apricot” 和 “jam”,在每个迭代步中,我们都尝试减小二者的词嵌入之间的距离,让二者更加靠近,即增加二者词嵌入之间的相似度。
- 对于随机采样得到的单词(即负样本),我们希望其和目标单词的嵌入之间尽量拉远距离。
- 例如:“apricot” 和 “aardrark”,我们希望二者词嵌入之间的距离尽可能远。
-
-
Desiderata: 理想模型
-
Unsupervised: Unlabelled corpus 无监督 原始的、无标签的语料库 正如前面所述,我们的模型无需标签,只要从给定的语料库按照窗口大小对其中出现的单词进行计数,并计算概率,进行学习即可。
-
Efficient: 高效
- Negative sampling: Avoid softmax over full vocabulary 负采样(避免在整个词汇表上计算 softmax)
- Scales to large corpus 可以扩展到非常大的语料库上 还有一些在非常大的语料库上预训练的词向量,我们也可以直接下载使用。
-
-
Problems:
- Difficult to quantify the quality of word vectors 难以对词向量的质量进行量化
- Don’t capture polysemous word(多义词)
Evaluation for Word Vectors 评估词向量
Word Similarity
-
Measure similarity of two words using cosine similarity
-
Compare predicted similarity with human intuition
-
Datasets:
- WordSim-353 are pairs of nouns with judged relatedness
- SimLex-999 also covers verbs and adjectives
-

嵌入展示有意义的几何关系
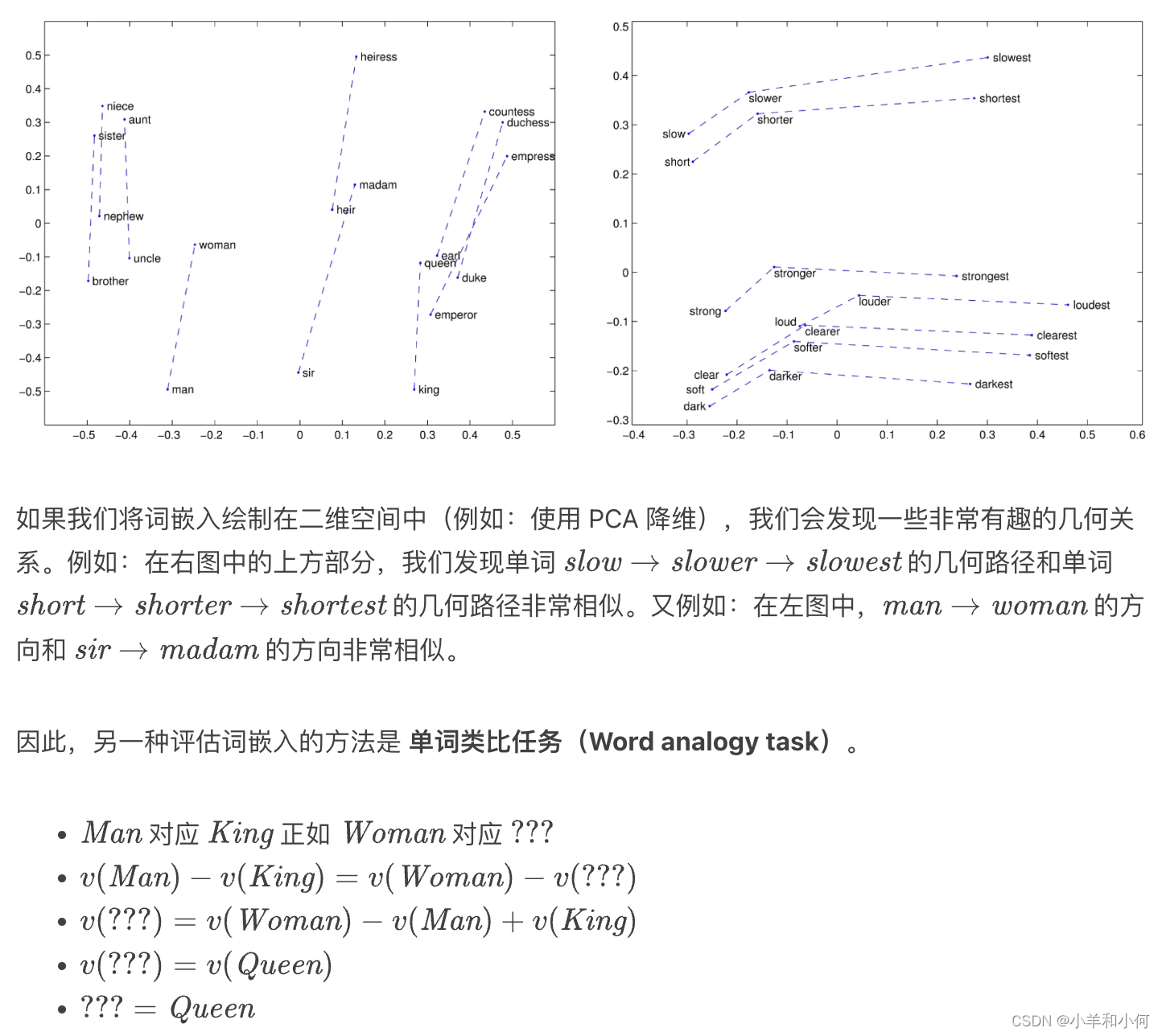
Word Analogy
-
E.g.
Manis toKingasWomanto???v(Man) - v(King)=v(Woman) - v(???)- Find word whose embedding is closest to
v(Woman) - v(Man) + v(King)
-
Embedding Space
- Word2Vec embeddings show interesting geometry
- Explains why they are good in word analogy task
评估词向量

Downstream Tasks 下游任务
- Best evaluation is in other downstream tasks 最好的评价是在其他下游任务中
- Use Bag-of-Word embeddings as a feature representation in a classifier 在分类器中使用袋状词嵌入作为特征表示
- First layer of most deep learning models is to embed input text 大多数深度学习模型的第一层是嵌入输入文本
- Initialize them with pretrained word vectors 用预训练的词向量初始化它们
General Findings
-
neural > count
-
Contextual word representation is shown to work better 上下文的单词表示法被证明效果更好
-
Dynamic word vectors that change depending on context 根据上下文变化的动态词向量