✨博主:命运之光
🦄专栏:算法修炼之练气篇
🍓专栏:算法修炼之筑基篇
✨博主的其他文章:点击进入博主的主页
前言:学习了算法修炼之练气篇想必各位蒟蒻们的基础已经非常的扎实了,下来我们进阶到算法修炼之筑基篇的学习。筑基期和练气期难度可谓是天差地别,懂得都懂,题目难度相比起练气期的题目难度提升很多,所以要是各位蒟蒻小伙伴们看不懂筑基期的题目可以在练气期多积累积累,练气期的题目也会不断更新,大家一定要把基础打牢固了再来看筑基期的题目哈,这样子也可以提高大家的学习效率,一举两得,加油(●'◡'●)🎉🎉

目录
✨如何解决最长回文子串这类问题
✨最长回文子串(例题🦄)
🍓我们先用中心扩展法来写这道问题
🍓我们修改代码采用马拉车算法(Manacher's algorithm)来解决:
✨马拉车算法的标准模板
✨模板使用讲解+使用
✨结语
✨如何解决最长回文子串这类问题
常见方法包括暴力法、动态规划和马拉车算法。下面我将简要介绍这些方法:
- 暴力法: 暴力法是最简单直接的方法,即对于给定字符串的每个可能的子串,判断是否是回文串并记录最长的回文串。这种方法的时间复杂度为 O(n^3),其中 n 是字符串的长度。尽管暴力法的效率较低,但对于较小的输入规模,它是可行的。
- 动态规划: 动态规划方法可以通过构建状态转移方程来解决最长回文子串问题。定义一个二维数组 dp,其中 dp[i][j] 表示从下标 i 到下标 j 的子串是否是回文串。根据回文串的性质,有以下状态转移方程:
dp[i][j] = true, if i == j (单个字符是回文串)
dp[i][j] = (s[i] == s[j]), if j - i == 1 (相邻字符相等时是回文串)
dp[i][j] = (s[i] == s[j] && dp[i+1][j-1]), if j - i > 1 (首尾字符相等且内部子串是回文串时是回文串)通过填充动态规划表格 dp,可以找到最长回文子串的长度和起始位置。该方法的时间复杂度为 O(n^2)。
3.马拉车算法(Manacher's algorithm): 马拉车算法是一种高效的线性时间算法,用于找到最长回文子串。该算法通过利用回文串的对称性进行优化,避免了重复计算。马拉车算法的核心思想是利用一个数组 P 来记录以每个字符为中心的回文串半径长度(不包括中心字符)。通过维护一个当前已知回文串的中心和右边界,算法在线性时间内找到所有位置的最长回文串半径。通过预处理字符串,将其转换为更易处理的形式,然后应用马拉车算法,可以找到最长回文子串的长度和起始位置。马拉车算法的时间复杂度为 O(n)。
这些方法各有优劣,选择合适的方法取决于问题的规模和时间要求。对于较小的输入规模,可以使用暴力法或动态规划。对于较大的输入规模,马拉车算法是更高效的选择。
✨最长回文子串(例题🦄)

🍓我们先用中心扩展法来写这道问题
中心扩展法是一种简单直观的方法,用于寻找最长回文子串。它的基本思想是遍历字符串中的每个字符,将当前字符作为中心,同时考虑奇数长度和偶数长度的回文子串,通过不断向两边扩展并比较字符,找到以当前字符为中心的最长回文子串的长度。
中心扩展法的步骤如下:
- 遍历字符串中的每个字符,将其依次作为回文串的中心。
- 对于每个中心字符,分别向左右两边扩展,直到无法扩展或左右字符不相等为止。
- 记录每个中心字符的回文串长度,并更新最长回文串的长度和起始位置。
中心扩展法的时间复杂度为 O(n^2),其中 n 是字符串的长度。对于较小的输入规模,中心扩展法是一个简单易懂的选择。
它是解决最长回文子串问题的一个基本方法,易于理解和实现。虽然中心扩展法的时间复杂度较高,但对于规模较小的问题或者作为一种简单的初始方法,它是一个合理的选择。
#include <iostream>
#include <vector>
using namespace std;
// 中心扩展法
int expandAroundCenter(string s, int left, int right) {
while (left >= 0 && right < s.length() && s[left] == s[right]) {
left--;
right++;
}
return right - left - 1;
}
string longestPalindrome(string s) {
int start = 0, end = 0;
for (int i = 0; i < s.length(); i++) {
int len1 = expandAroundCenter(s, i, i);
int len2 = expandAroundCenter(s, i, i + 1);
int len = max(len1, len2);
if (len > end - start) {
start = i - (len - 1) / 2;
end = i + len / 2;
}
}
return s.substr(start, end - start + 1);
}
int main() {
string s;
cin >> s;
string longest = longestPalindrome(s);
cout << longest.length() << endl;
return 0;
}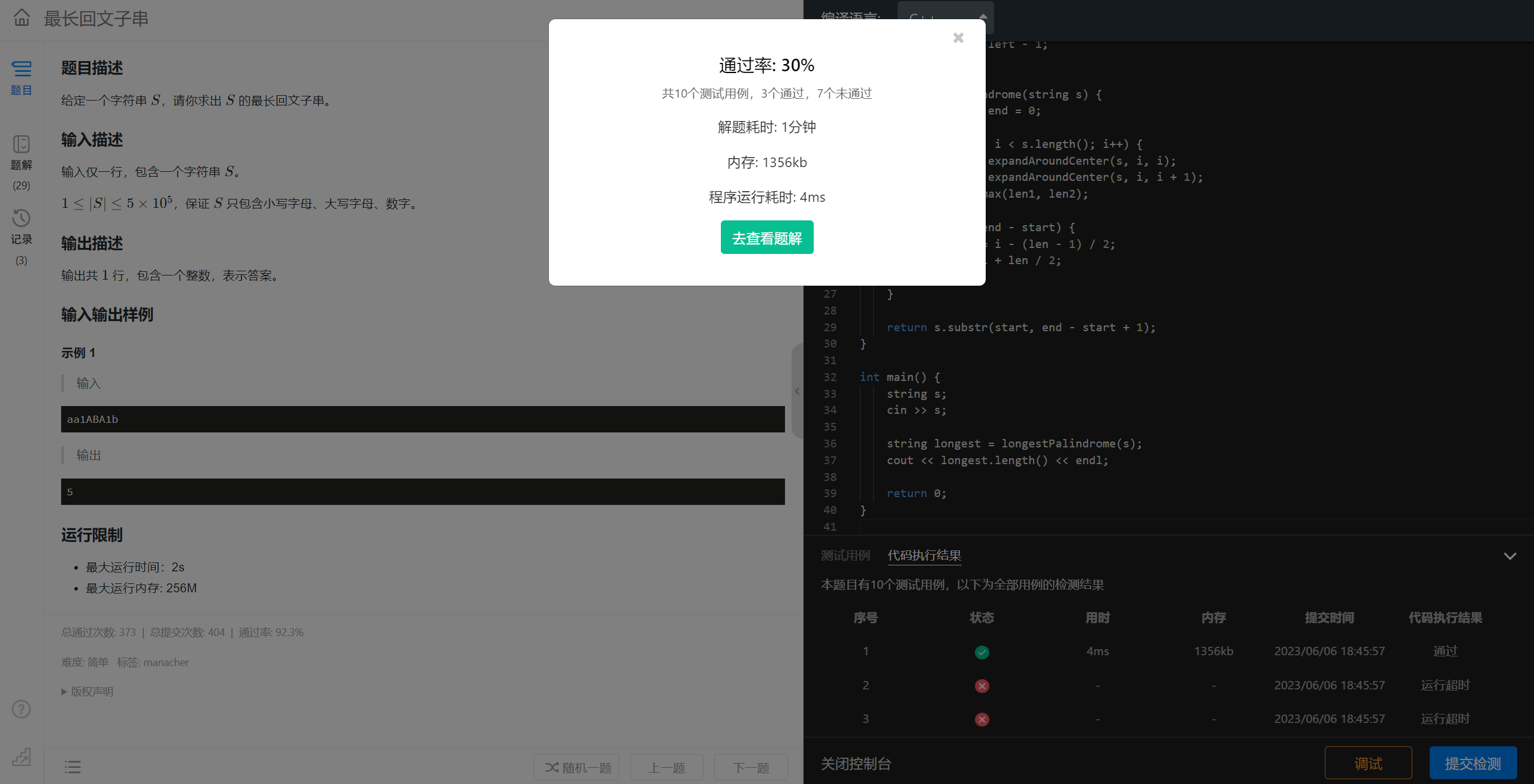
显然问题规模太大中心扩展法的时间复杂度爆掉了
🍓我们修改代码采用马拉车算法(Manacher's algorithm)来解决:
#include <iostream>
#include <vector>
using namespace std;
string preProcess(string s) {
int n = s.length();
if (n == 0) {
return "^$";
}
string processed = "^";
for (int i = 0; i < n; i++) {
processed += "#" + s.substr(i, 1);
}
processed += "#$";
return processed;
}
string longestPalindrome(string s) {
string processed = preProcess(s);
int n = processed.length();
vector<int> P(n, 0);
int center = 0, right = 0;
for (int i = 1; i < n - 1; i++) {
int i_mirror = 2 * center - i;
if (right > i) {
P[i] = min(right - i, P[i_mirror]);
}
while (processed[i + 1 + P[i]] == processed[i - 1 - P[i]]) {
P[i]++;
}
if (i + P[i] > right) {
center = i;
right = i + P[i];
}
}
int maxLen = 0, centerIndex = 0;
for (int i = 1; i < n - 1; i++) {
if (P[i] > maxLen) {
maxLen = P[i];
centerIndex = i;
}
}
int start = (centerIndex - maxLen) / 2;
return s.substr(start, maxLen);
}
int main() {
string s;
cin >> s;
string longest = longestPalindrome(s);
cout << longest.length() << endl;
return 0;
}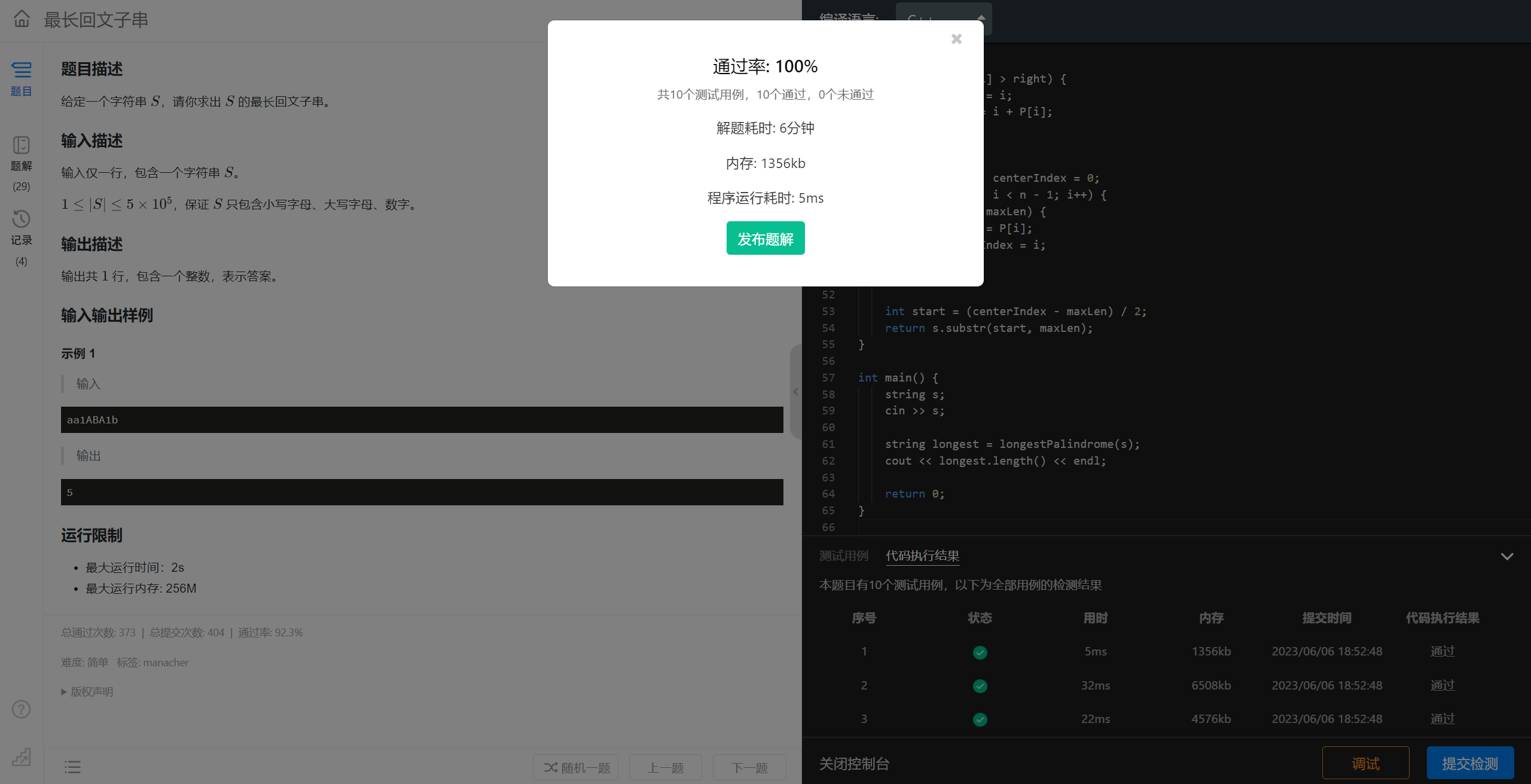
🎉🎉🎉成功通过🎉🎉🎉
🍓下来我们详细解释以下上述马拉车算法让没学过马拉车算法的小白也能听的懂
#include <iostream>
#include <vector>
using namespace std;
这部分是引入需要的头文件和命名空间。
string preProcess(string s) {
int n = s.length();
if (n == 0) {
return "^$";
}
string processed = "^";
for (int i = 0; i < n; i++) {
processed += "#" + s.substr(i, 1);
}
processed += "#$";
return processed;
}这是一个预处理函数 preProcess,它将原始字符串进行处理,以便进行马拉车算法。该函数在每个字符的左右两侧添加特殊字符(通常为不在原始字符串中出现的字符)以构建预处理字符串。
string longestPalindrome(string s) {
string processed = preProcess(s);
int n = processed.length();
vector<int> P(n, 0);
int center = 0, right = 0;
for (int i = 1; i < n - 1; i++) {
int i_mirror = 2 * center - i;
if (right > i) {
P[i] = min(right - i, P[i_mirror]);
}
while (processed[i + 1 + P[i]] == processed[i - 1 - P[i]]) {
P[i]++;
}
if (i + P[i] > right) {
center = i;
right = i + P[i];
}
}
int maxLen = 0, centerIndex = 0;
for (int i = 1; i < n - 1; i++) {
if (P[i] > maxLen) {
maxLen = P[i];
centerIndex = i;
}
}
int start = (centerIndex - maxLen) / 2;
return s.substr(start, maxLen);
}这是主要的函数 longestPalindrome,它使用马拉车算法找到最长回文子串。首先,我们调用 preProcess 函数对输入字符串进行预处理,得到预处理字符串 processed 和其长度 n。
我们创建了一个大小为 n 的数组 P,用于记录以每个字符为中心的回文串的半径长度(不包括中心字符)。同时,我们初始化两个变量 center 和 right,分别表示已知的回文串的中心和右边界。
接下来,我们从下标为 1 的字符开始遍历预处理字符串,依次计算 P 数组的值。首先,我们根据当前字符的对称性,找到它关于中心的镜像下标 i_mirror。如果当前字符在已知回文串的右边界内,我们可以利用回文串的对称性来快速计算 P[i] 的值。如果超出右边界,则以当前字符为中心,向两边扩展并比较字符,更新 P[i] 的值。
接下来,我们通过不断扩展和比较字符的循环,计算每个中心字符的回文串半径长度,并更新已知的回文串中心和右边界。
完成循环后,我们找到 P 数组中最大值,确定最长回文子串的长度 maxLen 和中心位置的下标 centerIndex。
最后,我们通过计算起始位置 start,从原始字符串 s 中提取出最长回文子串,并将其作为函数的返回值。
int main() {
string s;
cin >> s;
string longest = longestPalindrome(s);
cout << longest.length() << endl;
return 0;
}在 main 函数中,我们读取输入字符串 s,调用 longestPalindrome 函数找到最长回文子串,并输出其长度。
这样,通过马拉车算法的实现,我们可以找到给定字符串的最长回文子串。
上面给出的马拉车算法代码可以作为一个模板,用于解决求最长回文子串的问题。只要将输入的字符串传递给 longestPalindrome 函数,就可以得到最长回文子串的长度和具体子串。
当你遇到求最长回文子串的问题时,可以使用这个模板作为起点,进行适当的修改和调整来满足具体的问题要求。
例如,如果你需要返回最长回文子串的具体位置或者需要统计所有的最长回文子串,你可以对模板代码进行扩展。你可能需要记录每个回文子串的起始位置和长度,并在遍历过程中更新这些信息。
根据具体问题的要求,你还可以对代码进行优化和改进。马拉车算法有许多变种和优化技巧,如使用 manacher 数组来减少计算量,提前终止循环等。
记住马拉车算法是解决最长回文子串问题的高效算法,可以作为一个有用的模板来解决类似的问题,但你可能需要根据具体情况进行适当的修改和扩展。
✨马拉车算法的标准模板
#include <iostream>
#include <vector>
using namespace std;
string longestPalindrome(string s) {
string processed = "#";
for (int i = 0; i < s.length(); i++) {
processed += s[i];
processed += "#";
}
int n = processed.length();
vector<int> P(n, 0);
int center = 0, right = 0;
for (int i = 1; i < n - 1; i++) {
int i_mirror = 2 * center - i;
if (right > i) {
P[i] = min(right - i, P[i_mirror]);
}
while (processed[i + 1 + P[i]] == processed[i - 1 - P[i]]) {
P[i]++;
}
if (i + P[i] > right) {
center = i;
right = i + P[i];
}
}
int maxLen = 0, centerIndex = 0;
for (int i = 1; i < n - 1; i++) {
if (P[i] > maxLen) {
maxLen = P[i];
centerIndex = i;
}
}
int start = (centerIndex - maxLen) / 2;
return s.substr(start, maxLen);
}
int main() {
string s;
cin >> s;
string longest = longestPalindrome(s);
cout << longest << endl;
return 0;
}这个模板包含了马拉车算法的核心部分,可以直接用于求解最长回文子串问题。
你只需将输入的字符串传递给 longestPalindrome 函数,即可得到最长回文子串。注意,此模板假设输入字符串只包含小写字母、大写字母和数字。
你可以根据需要,自行扩展和修改模板代码,例如记录回文子串的位置、统计所有最长回文子串等。另外,为了适应不同的比赛环境,你可能需要添加适当的输入输出代码。
✨模板使用讲解+使用
🦄相信肯定有许多小伙伴看不懂模板,也不会用模板,没关系,下来详细的讲解一下模板,和模板的使用。
string longestPalindrome(string s) {
string processed = "#";
for (int i = 0; i < s.length(); i++) {
processed += s[i];
processed += "#";
}这部分代码定义了 longestPalindrome 函数,它接收一个字符串 s 作为参数,并返回最长回文子串。
首先,我们创建了一个新的字符串 processed,并在其开头插入一个特殊字符 #。接下来,我们遍历输入字符串 s 中的每个字符,将其插入 processed 中,并在字符之间插入特殊字符 #。这样做是为了将原始字符串的每个字符作为回文串的中心字符,以便更方便地处理回文串的奇偶长度情况。
int n = processed.length();
vector<int> P(n, 0);
int center = 0, right = 0;
for (int i = 1; i < n - 1; i++) {
int i_mirror = 2 * center - i;
if (right > i) {
P[i] = min(right - i, P[i_mirror]);
}
while (processed[i + 1 + P[i]] == processed[i - 1 - P[i]]) {
P[i]++;
}
if (i + P[i] > right) {
center = i;
right = i + P[i];
}
}在这一部分中,我们执行马拉车算法的核心部分。我们首先创建一个大小为 n 的数组 P,用于记录以每个字符为中心的回文串的半径长度。
然后,我们初始化两个变量 center 和 right,表示当前已知的回文串的中心和右边界。在循环中,我们从下标为 1 的字符开始遍历 processed 字符串。
对于每个下标 i,我们计算其关于中心的镜像下标 i_mirror。接下来,我们根据已知回文串的右边界来计算 P[i] 的初始值。如果 right 大于 i,我们可以利用回文串的对称性来快速计算 P[i]。具体来说,P[i] 取 right - i 和 P[i_mirror] 中的较小值。
然后,我们通过扩展和比较字符的循环,来计算每个中心字符的回文串半径长度。我们不断地将 i 扩展到左右字符相等的位置,并更新 P[i] 的值。这一过程结束后,我们可能会更新已知回文串的中心 center 和右边界 right。
int maxLen = 0, centerIndex = 0;
for (int i = 1; i < n - 1; i++) {
if (P[i] > maxLen) {
maxLen = P[i];
centerIndex = i;
}
}
int start = (centerIndex - maxLen) / 2;
return s.substr(start, maxLen);
}在最后一部分,我们通过遍历 P 数组来找到最长回文子串的长度和中心位置。我们初始化 maxLen 和 centerIndex 为 0,然后遍历 P 数组,如果发现某个回文串的半径长度 P[i] 大于 maxLen,就更新 maxLen 和 centerIndex 的值。
最后,我们根据中心位置 centerIndex 和回文串的长度 maxLen,计算出最长回文子串在原始字符串 s 中的起始位置 start。最终,我们使用 substr 函数从 s 中提取出最长回文子串,并将其作为函数的返回值。
当你需要根据具体要求修改代码时,可以根据以下几个方面进行调整:
- 记录回文串的位置:模板中只返回了最长回文子串本身,如果你还需要记录回文串在原始字符串中的位置,可以在模板中添加相应的变量和逻辑。你可以使用额外的变量来记录最长回文子串的起始位置和长度,然后根据这些信息从原始字符串中提取出回文串。
- 统计所有的最长回文子串:如果题目要求统计所有的最长回文子串,而不仅仅是返回一个最长回文子串,你可以修改代码来存储所有满足最长长度的回文串。你可以使用容器(如向量或列表)来存储这些回文串的起始位置和长度,然后在遍历过程中更新和添加相应的信息。
- 处理特殊字符或其他要求:根据题目要求,你可能需要对字符串中的特殊字符进行处理,或者进行其他特定的操作。在模板中,我们使用了特殊字符 # 来处理回文串的奇偶长度情况,但在某些情况下,你可能需要使用其他字符或进行其他处理。根据题目要求,修改代码以满足特定的需求。
在进行任何修改之前,建议先充分理解模板代码的原理和逻辑,并根据题目要求明确你需要实现的功能。然后,根据需要添加变量、数据结构和逻辑来实现所需的功能。在修改代码时,务必进行充分的测试和调试,确保修改后的代码仍然正确且符合题目要求。
✨结语
🍓🍓在本次博客中,我们讨论了求解最长回文子串的问题。首先,我们介绍了两种常用的算法:中心扩展法和马拉车算法。中心扩展法是一种简单直观的方法,通过以每个字符为中心向两侧扩展来找到回文串。而马拉车算法则是一种更高效的算法,利用回文串的对称性和已知回文串的信息来加速搜索过程。
🍓🍓我们详细讲解了马拉车算法的实现,并提供了一个标准的马拉车算法模板供参考。该模板使用了预处理和动态规划的思想,通过添加特殊字符和记录回文串的半径长度来快速计算最长回文子串。
🍓🍓此外,我们还探讨了如何根据具体要求修改马拉车算法的模板。根据题目要求,你可以记录回文串的位置、统计所有的最长回文子串,并根据特殊字符或其他要求进行相应的调整。
🍓🍓最后,我们强调了对算法的理解和测试的重要性。在使用算法模板时,确保理解每个部分的原理和逻辑,并根据具体需求进行修改。进行充分的测试和调试,确保修改后的代码仍然正确且满足题目要求。
希望本次博客对你理解最长回文子串的求解方法有所帮助,并为你在解决类似问题时提供了指导和思路。如果你有任何其他问题,我们随时欢迎帮助解答。祝你在竞赛中取得优异的成绩!