文章目录
- 前言
- 1. 数据集
- 1.1 数据初探
- 1.2 数据处理
- 1.2 训练前验证图片
- 1.4 翻车教训和进阶知识
- 2. 训练
- 3.效果展示
前言
又要到做跌倒识别了。
主流方案有两种:
1.基于关键点的识别,然后做业务判断,判断跌倒,用openpose可以做到。但这种适合背景比较干净的,类似抖音尬舞的输出;
2.基于目标监测的,有人躺下就标注为跌倒
第二种方案,适合在工地,或者工厂上班的情况,因为很容易有人围观,聚集起来,方案1就容易误报,因为它为了保障速度,使用的是自下而上的方式。很容易将不同人的关键点张冠李戴,造成误报。
因此我们使用方案2。
1. 数据集
1.1 数据初探
数据集是不缺少的,我找到了两个,一个是paddle的,一个是阿里的。
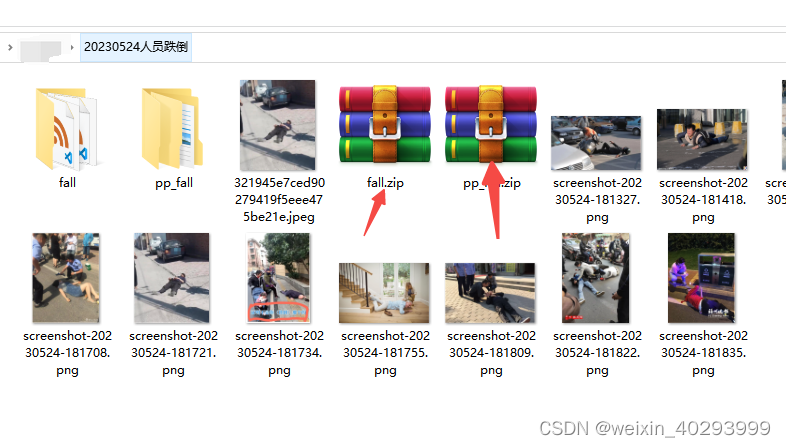
两份都是带标注的,可是问题是,他们划分的类别并不统一,pp_fall 只标注了跌倒的部分,其它的人和物都是背景类。
fall文件夹则标注了:10+(超过10个人),down,dog,people(能分开的人)四类。
这两个数据集一个1k+,一个8k+, 都是xml标注的。
外圈那个就是10个人,标注了10+
第一个文件夹:
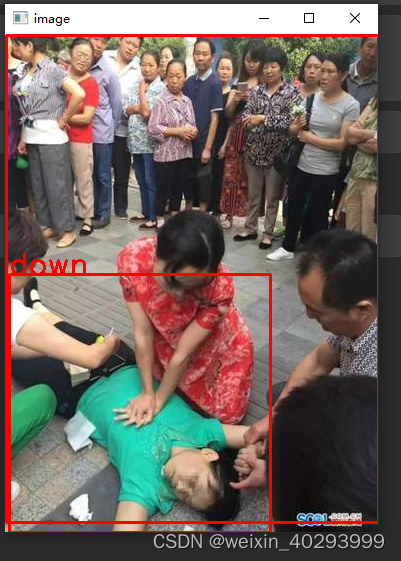
第二个文件夹:

1.2 数据处理
既然知道了两者的数据特点,就可以做数据合并了。
那必须是抽取bbox,只选取down的部分做目标,其它都做背景类。
同时把voc的xml格式转换成yolov的txt格式。
我个人习惯是,把数据集合并起来,原数据集保持不变。
合并策略:
建立两个文件夹 first_dir/images first_dir/labels 下面再分 train 和 val 比例9:1
第二个和第一个保持一致,
第一个文件夹过滤出down的标注
第二个文件夹过滤出fall的标注,并生成相应的yolov txt格式的文件,
0.5% 的抽样率看看生成的标注和图片能不能对上.
核心代码如下:
# 创建文件夹
import os
import shutil
import cv2
import glob
import random
import traceback
base_label_dir = r"D:\Dataset\zhongwaiyun\fall\labels"
base_img_dir = r"D:\Dataset\zhongwaiyun\fall\images"
# 已经明确知道,两个文件夹只有这两个标签和迭代有关系,所以把他们过滤出来
classes = ["fall", "down"]
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def copy_pic_to_dest(raw_img_path, dst_img_path):
"""
移动图片
:param raw_img_path:
:param dst_img_path:
:return:
"""
shutil.copy(raw_img_path, dst_img_path)
return dst_img_path
def create_txt_to_dest(raw_xml_path, dst_img_path):
"""
在目标处生成txt文件
:param raw_xml_path:
:param dst_img_path:
:return:
"""
tree = ET.parse(raw_xml_path)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
dst_txt_path = dst_img_path.replace("images", "labels").replace(".jpg", ".txt")
show_pic_flag = random.randint(1, 1000) > 995
img = cv2.imread(dst_img_path)
if img is None:
print(dst_img_path,"is none")
return False
h,w,_ = img.shape
if show_pic_flag:
pass
with open(dst_txt_path, "w") as out_file:
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
#过滤非跌倒和难例的图片
continue
# 跌倒目标类都是0
cls_id = 0
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
print("bbbbbbbbb", b)
x_top_left, y_top_left, x_bottom_right, y_bottom_right = int(b[0]), int(b[2]), int(b[1]), int(b[3])
try:
bb = convert((w, h), b)
except:
print(traceback.format_exc())
print("raw_xml_path:::",raw_xml_path)
return False
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
if show_pic_flag:
cv2.putText(img, cls, (x_top_left, y_top_left), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)
cv2.rectangle(img, (x_top_left, y_top_left), (x_bottom_right, y_bottom_right), (0, 0, 255), thickness=2)
if show_pic_flag:
cv2.imshow("image", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
第一个文件夹调用:
# 第一个数据源:
source_img_dir1 = r"D:\日常资料\01项目\中外运\20230524人员跌倒\fall"
count_num = 0
for xml_path in glob.glob(source_img_dir1 + "\*.xml"):
if count_num%10==0:
dst_img_path = os.path.join(base_img_dir,"val",str(count_num) + ".jpg")
else:
dst_img_path = os.path.join(base_img_dir,"train",str(count_num) + ".jpg")
raw_img_path = xml_path.replace(".xml",".jpg")
if not os.path.exists(raw_img_path):
print("{} 不存在".format(raw_img_path))
continue
copy_pic_to_dest(raw_img_path, dst_img_path)
create_txt_to_dest(xml_path, dst_img_path)
count_num += 1
print(count_num)
验证结果:



空白背景类

第二个文件夹调用:
# 第二个数据源:
source_img_dir1 = r"D:\日常资料\01项目\中外运\20230524人员跌倒\pp_fall\Annotations"
count_num = 8000
for xml_path in glob.glob(source_img_dir1 + "\*.xml"):
if count_num%10==0:
dst_img_path = os.path.join(base_img_dir,"val",str(count_num) + ".jpg")
else:
dst_img_path = os.path.join(base_img_dir,"train",str(count_num) + ".jpg")
raw_img_path = xml_path.replace(".xml",".jpg").replace("Annotations","images")
if not os.path.exists(raw_img_path):
print("{} 不存在".format(raw_img_path))
continue
copy_pic_to_dest(raw_img_path, dst_img_path)
create_txt_to_dest(xml_path, dst_img_path)
count_num += 1
print(count_num)
1.2 训练前验证图片
# 跑一遍标签的数量,实例数量,和背景类数据
base_dir = r"D:\Dataset\zhongwaiyun\fall"
txt_path_list = glob.glob(base_dir + "\**\*.txt",recursive=True)
img_path_list = glob.glob(base_dir + "\**\*.jpg",recursive=True)
total_info = {}
txt_count = len(txt_path_list)
img_count = len(img_path_list)
# 标签数量
total_info["txt_count"] = txt_count
# 图片数量
total_info["img_count"] = img_count
# 只有图片而没有标签
total_info["img_without_txt_list"] = []
# 只有标签而没有图片
total_info["txt_without_img_list"] = []
# class_set
total_info["class_set"] = set()
# 每个类有多少个实例
total_info["instance_count_per_class"] = dict()
total_info["background_count"] = 0
txt_path_error = []
img_path_error = []
count_num = 0
for txt_path in txt_path_list:
if count_num !=0:
# continue
pass
if not os.path.exists(txt_path):
txt_path_error.append(txt_path)
img_path = txt_path.replace("labels", "images").replace(".txt", ".jpg")
if not os.path.exists(img_path):
total_info["txt_without_img_list"].append(txt_path)
show_flag = False
if count_num % 3000==0:
show_flag = True
print(img_path)
cv2_img = cv2.imread(img_path)
if cv2_img is None:
img_path_error.append(img_path)
continue
height, width, _ = cv2_img.shape
print(height, width, _)
with open(txt_path) as f:
line_list = f.readlines()
print(line_list)
for line_str in line_list:
info_list = line_str.strip().split(" ")
class_id = int(info_list[0])
total_info["class_set"].add(class_id)
x, y, w, h = map(float, info_list[1:]) # 目标中心点坐标和宽高比例
if class_id not in total_info["instance_count_per_class"].keys():
total_info["instance_count_per_class"][class_id] = 1
else:
total_info["instance_count_per_class"][class_id] += 1
if show_flag:
# 计算出左上角和右下角坐标
left = int((x - w / 2) * width)
top = int((y - h / 2) * height)
right = int((x + w / 2) * width)
bottom = int((y + h / 2) * height)
print("--===---",(left, top), (right, bottom),class_id)
# 绘制矩形框和类别标签
cv2.rectangle(cv2_img, (left, top), (right, bottom), (0, 255, 0), 2)
label = class_id
cv2.putText(cv2_img, str(label), (left, top), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)
if len(line_list) == 0:
total_info["background_count"] += 1
if show_flag:
cv2.imshow('image', cv2_img)
cv2.waitKey(0)
cv2.destroyAllWindows()
count_num+=1
print(txt_path_error,img_path_error,total_info)

以标注为中心跑:
背景图片650张
实例图片:0(迭倒)==》 10493张
opencv 不能打开的图片:
['D:\\Dataset\\zhongwaiyun\\fall\\images\\train\\1979.jpg', 'D:\\Dataset\\zhongwaiyun\\fall\\images\\train\\2233.jpg', 'D:\\Dataset\\zhongwaiyun\\fall\\images\\train\\2371.jpg', 'D:\\Dataset\\zhongwaiyun\\fall\\images\\train\\3268.jpg', 'D:\\Dataset\\zhongwaiyun\\fall\\images\\train\\3746.jpg', 'D:\\Dataset\\zhongwaiyun\\fall\\images\\train\\4876.jpg', 'D:\\Dataset\\zhongwaiyun\\fall\\images\\train\\5204.jpg', 'D:\\Dataset\\zhongwaiyun\\fall\\images\\train\\5364.jpg', 'D:\\Dataset\\zhongwaiyun\\fall\\images\\train\\6418.jpg']
这个其实是一张动图,

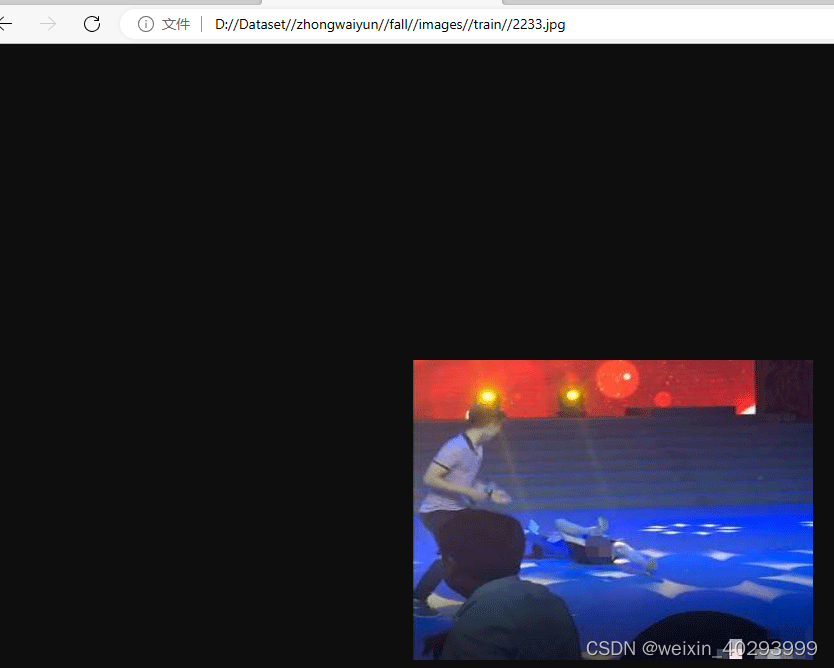
第二个不知道咋回事,opencv和pil都打不开
所以我懒一下,把这几个图片和标注都del
for img_path in img_path_error:
os.remove(img_path)
txt_path = img_path.replace("images","labels").replace(".jpg",".txt")
if os.path.exists(txt_path):
os.remove(txt_path)
print(txt_path)
1.4 翻车教训和进阶知识
- img = cv2.imread(xxxx)
h,w,c = img.shape
一定要记住h,w,c 它和 PIL 是不一样的
pil_img = Image.open(xxxx)
w,h = pil_img.size()
另外,目录参数,cv2.imread() 也未必能成功,还是要尽快找出一个万全之策。 - 现在已经拿到图片的数据描述了,多少张、多少实例、每类的分布,后面要判断出,多少小目标、类的均衡性(单一类别无所谓)、目标的密集度、分布度、曝光强度等,类别间相似度,一共是8个维度。
- 对场景识别的,漏报要分析原因,是8个维度的那个维度造成的。
- 对误报背景当成某一类,或者类A,当成类别B,要增加数据集。但是要
- 一个一个的验证太慢了,cv2.show() 要改成 Img.grid 的方式,一次性展示多张比较妥当。
2. 训练
fall.yaml
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# COCO128 dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics
# Example usage: python train.py --data coco128.yaml
# parent
# ├── yolov5
# └── datasets
# └── coco128 ← downloads here (7 MB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
train: ["/data_share/data_share/zhongwaiyun/fall/images/train"]
val: ["/data_share/data_share/zhongwaiyun/fall/images/val"]
test: # test images (optional)
# xxx/a/imag
# xxx/a/labels
## [xxx/a/images, xxx/b/images,...,....]
## [ xxx/a/labels]
# Classes
names:
0: fall
# Download script/URL (optional)
# download: https://ultralytics.com/assets/coco128.zip
训练命令,2张卡,用多卡训练
python -m torch.distributed.launch --nproc_per_node=2 train.py --img 640 --batch 48 --epochs 100 --dat a fall.yaml --weights weights/yolov5m6.pt --workers 8 --save-period 20
训练过程中的warning:
train: WARNING ⚠️ /data_share/data_share/zhongwaiyun/fall/images/train/75.jpg: corrupt JPEG restored and saved
train: WARNING ⚠️ /data_share/data_share/zhongwaiyun/fall/images/train/7599.jpg: corrupt JPEG restored and saved
train: WARNING ⚠️ /data_share/data_share/zhongwaiyun/fall/images/train/7602.jpg: corrupt JPEG restored and saved
train: WARNING ⚠️ /data_share/data_share/zhongwaiyun/fall/images/train/7608.jpg: corrupt JPEG restored and saved
train: WARNING ⚠️ /data_share/data_share/zhongwaiyun/fall/images/train/7618.jpg: corrupt JPEG restored and saved
train: WARNING ⚠️ /data_share/data_share/zhongwaiyun/fall/images/train/7671.jpg: corrupt JPEG restored and saved
train: WARNING ⚠️ /data_share/data_share/zhongwaiyun/fall/images/train/7696.jpg: ignoring corrupt image/label: image file is truncated (53 bytes not processed)
train: WARNING ⚠️ /data_share/data_share/zhongwaiyun/fall/images/train/7704.jpg: corrupt JPEG restored and saved
train: WARNING ⚠️ /data_share/data_share/zhongwaiyun/fall/images/train/7707.jpg: ignoring corrupt image/label: image file is truncated (16 bytes not processed)
train: WARNING ⚠️ /data_share/data_share/zhongwaiyun/fall/images/train/7717.jpg: ignoring corrupt image/label: image file is truncated (6 bytes not processed)
libpng warning: iCCP: known incorrect sRGB profile
val: Scanning '/data_share/data_share/zhongwaiyun/fall/labels/val' images and labels...922 found, 0 missing, 72 empty, 0 corrupt: 100%|██████████| 922/922 [00:01<00:00, 598.34it/s]
val: WARNING ⚠️ /data_share/data_share/zhongwaiyun/fall/images/val/1070.jpg: corrupt JPEG restored and saved
val: WARNING ⚠️ /data_share/data_share/zhongwaiyun/fall/images/val/1480.jpg: corrupt JPEG restored and saved
val: WARNING ⚠️ /data_share/data_share/zhongwaiyun/fall/images/val/1550.jpg: corrupt JPEG restored and saved
val: WARNING ⚠️ /data_share/data_share/zhongwaiyun/fall/images/val/1580.jpg: corrupt JPEG restored and saved
val: WARNING ⚠️ /data_share/data_share/zhongwaiyun/fall/images/val/1630.jpg: corrupt JPEG restored and saved
val: WARNING ⚠️ /data_share/data_share/zhongwaiyun/fall/images/val/1650.jpg: corrupt JPEG restored and saved
val: WARNING ⚠️ /data_share/data_share/zhongwaiyun/fall/images/val/1690.jpg: corrupt JPEG restored and saved
val: WARNING ⚠️ /data_share/data_share/zhongwaiyun/fall/images/val/2580.jpg: corrupt JPEG restored and saved
val: WARNING ⚠️ /data_share/data_share/zhongwaiyun/fall/images/val/4850.jpg: corrupt JPEG restored and saved
val: WARNING ⚠️ /data_share/data_share/zhongwaiyun/fall/images/val/4880.jpg: corrupt JPEG restored and saved
val: WARNING ⚠️ /data_share/data_share/zhongwaiyun/fall/images/val/4940.jpg: corrupt JPEG restored and saved
val: WARNING ⚠️ /data_share/data_share/zhongwaiyun/fall/images/val/650.jpg: corrupt JPEG restored and saved
val: WARNING ⚠️ /data_share/data_share/zhongwaiyun/fall/images/val/7410.jpg: corrupt JPEG restored and saved
val: WARNING ⚠️ /data_share/data_share/zhongwaiyun/fall/images/val/7600.jpg: corrupt JPEG restored and saved
val: WARNING ⚠️ /data_share/data_share/zhongwaiyun/fall/images/val/8460.jpg: corrupt JPEG restored and saved
是因为图片损坏所致,不影响训练,但warning说明图片已损坏,可能影响最终效果
解决方案:
import glob
from PIL import Image
base_dir = r"D:\Dataset\zhongwaiyun\fall"
# txt_path_list = glob.glob(base_dir + "\**\*.txt",recursive=True)
img_path_list = glob.glob(base_dir + "\**\*.jpg",recursive=True)
import os
for img_path in img_path_list:
try:
# 打开图片文件
img = Image.open(img_path)
# 检查图像模式,并转换为RGB,如果不是RGB模式
if img.mode != 'RGB':
img = img.convert('RGB')
# 将其保存为JPEG格式
img.save(img_path, 'JPEG')
except Exception as e:
os.remove(img_path)
txt_path = img_path.replace("images","labels").replace(".jpg",".txt")
os.remove(txt_path)
print(e,txt_path,img_path)
bug:https://zhuanlan.zhihu.com/p/132554622
Image file is truncated( bytes not processed)
这个是图片太大所致,找到它,把它删除,或者ImageFile.LOAD_TRUNCATED_IMAGES = True 设置一下即可。
经过以上操作后,图片损坏的warning没有了:
Transferred 619/627 items from weights/yolov5m6.pt
AMP: checks passed ✅
optimizer: SGD(lr=0.01) with parameter groups 103 weight(decay=0.0), 107 weight(decay=0.000375), 107 bias
train: Scanning '/data_share/data_share/zhongwaiyun/fall/labels/train' images and labels...8289 found, 0 missing, 578 empty, 1 corrupt: 100%|██████████| 8289/8289 [00:09<00:00, 8
train: WARNING ⚠️ /data_share/data_share/zhongwaiyun/fall/images/train/1185.jpg: ignoring corrupt image/label: non-normalized or out of bounds coordinates [ 1.0163]
train: New cache created: /data_share/data_share/zhongwaiyun/fall/labels/train.cache
val: Scanning '/data_share/data_share/zhongwaiyun/fall/labels/val' images and labels...922 found, 0 missing, 72 empty, 0 corrupt: 100%|██████████| 922/922 [00:00<00:00, 1016.17it
val: New cache created: /data_share/data_share/zhongwaiyun/fall/labels/val.cache
AutoAnchor: 6.63 anchors/target, 1.000 Best Possible Recall (BPR). Current anchors are a good fit to dataset ✅
Plotting labels to runs/train/exp3/labels.jpg...
Image sizes 640 train, 640 val
Using 8 dataloader workers
Logging results to runs/train/exp3
Starting training for 100 epochs...
训练时的bug:
RuntimeError: Address already in use pytorch分布式训练
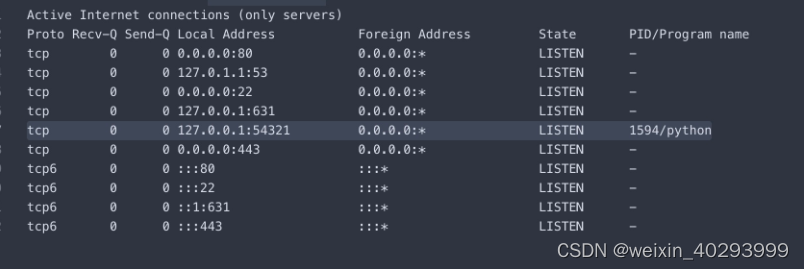
分布式训练时会遇到,说是端口占用,指引在这里:https://github.com/NVIDIA/tacotron2/issues/181
Your previous execution is not completely terminated.
netstat -nltp this command will show process lists which are listen ports. Now, you have to kill process which is listen 54321 port. kill -9 PID. in this case. kill -9 1594. Then try to start training.
在这里插入图片描述
实在不行,reboot肯定好用。
两张卡都没闲着
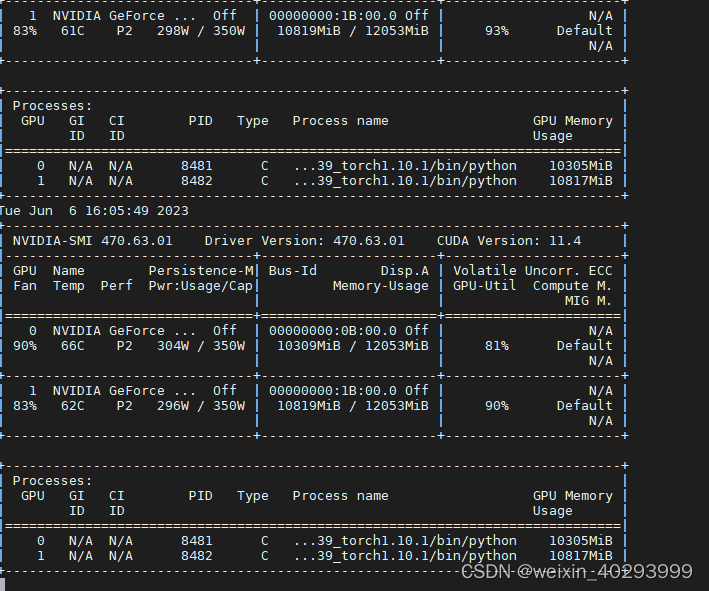
3.效果展示


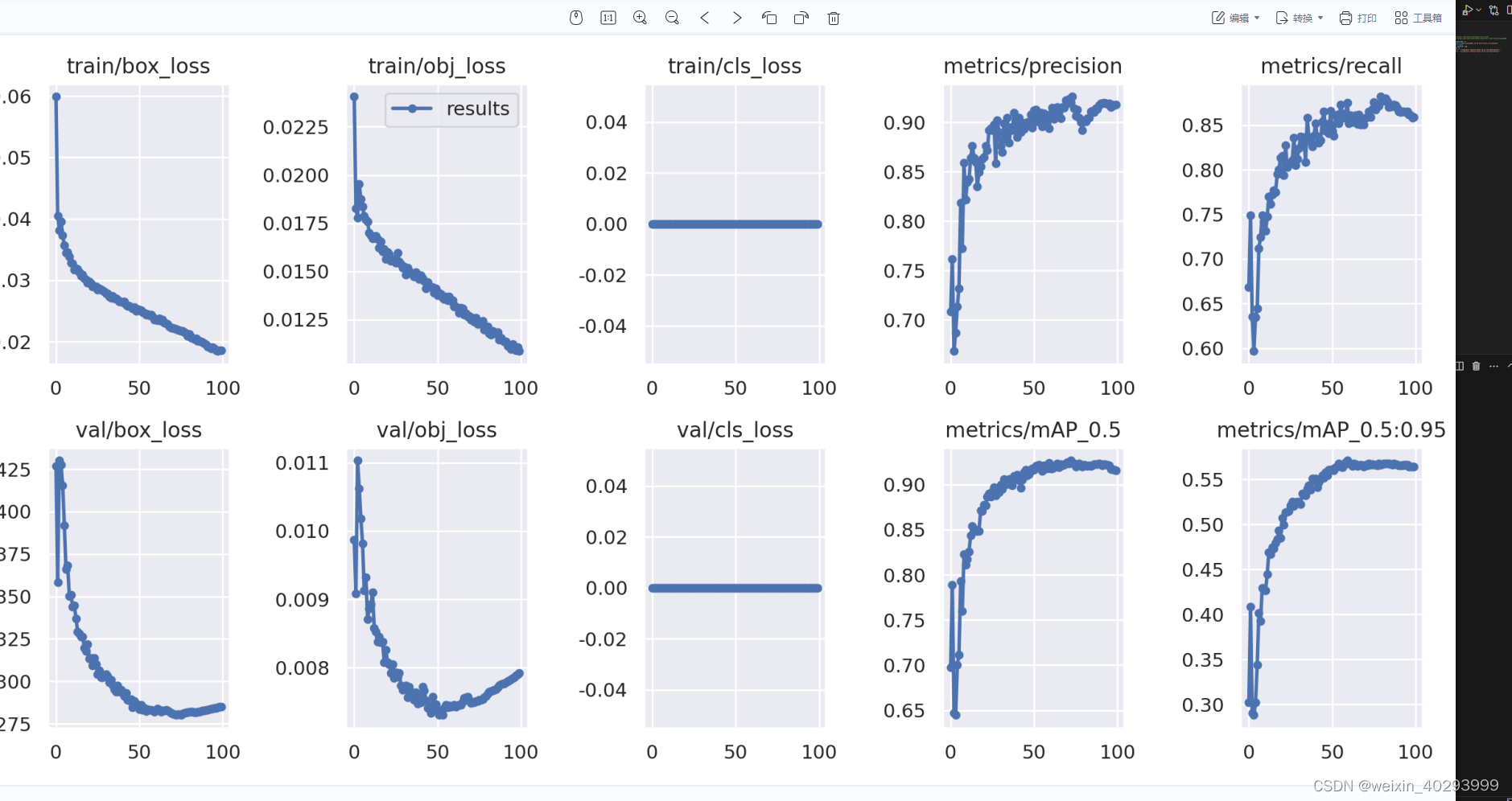
epochs 在60~80 的时候是不错的。