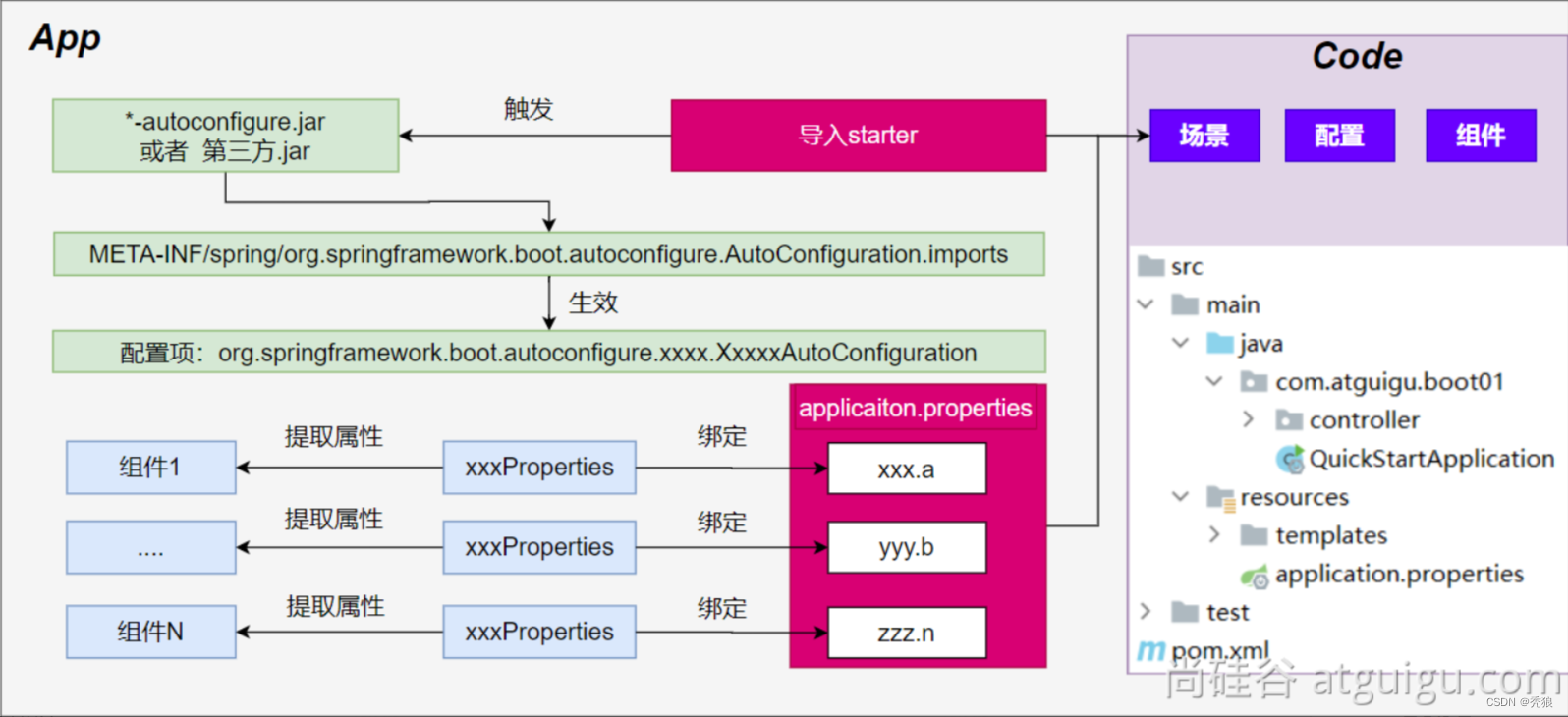
微软和openai在2023年4月的论文。
Capabilities of GPT-4 on Medical Challenge Problems
数据集介绍
USMLE Self Assessments:问题,有表格
USMLE Sample Exam:pdf,有图片
MedQA:多语种多选,
PubMedQA:判断题
MedMCQA:多选
MMLU:多选
评测方法
由于是评价选择题做得对不对,所以直接用准确率来衡量,即算做对了多少题。
对于需要给出原因的数据集,并没有在文中看到如何衡量gpt在这方面的表现
评测类型
1. 是zero-shot还是few-shot
2. 问题中提及了图像或图表,还是纯文本
3. 不同模型(GPT4-base、GPT-RLHF;GPT3.5、ChatGPT、Flan-PaLM 540B)在不同数据集上的表现
方向和局限
我觉得这部分写的很有意思,
1. Prompt策略
文章还尝试在prompt上做了实验,一是CoT,二是few-shot example是精心挑选的还是随机选的。对于前者,没有看到文章做什么实验,引用了别人的结果,说CoT不一定能很好的提高模型表现,还需要好好设计;而对于后者,作者也仿照前人做法进行了实验,结果example选择对模型表现结果影响不大。
2. 记忆
文章提及另外一个有意思点就是如何衡量模型数据的泄露程度,因为gpt4的训练数据没有开源,他就让模型生成给数据样本类似的样本集合,然后算这些生成样本和原始样本的相似性,来推断这个数据是不是就是训练数据。
使用的方法是memorization effects Levenshtein detector (MELD), 其实就是利用最短编辑距离算相似性

参考
1. Levenshtein Distance(编辑距离)算法与使用场景-腾讯云开发者社区-腾讯云
2.LOOCV - Leave-One-Out-Cross-Validation 留一交叉验证_leave-one-out cross-validation_肯德基套餐的博客-CSDN博客3. Few-Shot Prompting | Prompt Engineering Guide