朴素贝叶斯算法
- 一、什么是朴素贝叶斯分类方法
- 二、概率基础知识
- 1,联合概率
- 2,条件概率
- 三、贝叶斯公式
- 1,公式
- 2,拉普拉斯平滑系数
- 四、API
- 五、实操
- 案例:20类新闻分类
- 代码
- 六、总结
一、什么是朴素贝叶斯分类方法
朴素贝叶斯分类方法是一种基于贝叶斯定理的统计学习分类算法。它假设所有特征之间相互独立,且每个特征对于类别的影响是等价的,因此被称为“朴素”。该方法通过先验概率和观测数据的条件概率来计算后验概率,然后将待分类样本分配到具有最大后验概率的类别中。在文本分类、垃圾邮件过滤、情感分析等领域具有广泛应用。
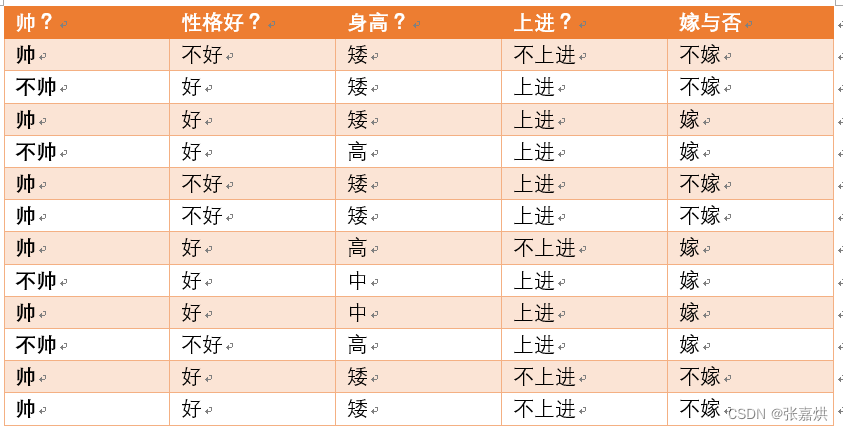
举例:根据以下数据,此时如果一个男生向女生求婚,男生的四个特点分别是不帅,性格不好,身高矮,不上进,请你判断一下女生是嫁还是不嫁?
二、概率基础知识
1,联合概率
包含多个条件,且所有条件同时成立的概率
记作:P(A,B)
特性:P(A, B) = P(A)P(B)
2,条件概率
事件A在另外一个事件B已经发生条件下的发生概率
记作:P(A|B)
特性:P(A1,A2|B) = P(A1|B)P(A2|B)
注意:此条件概率的成立,是由于A1,A2相互独立的结果(记忆)
三、贝叶斯公式
1,公式
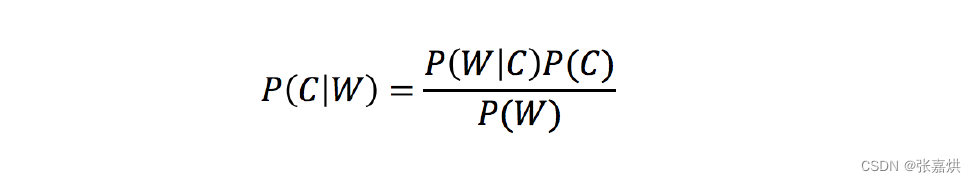
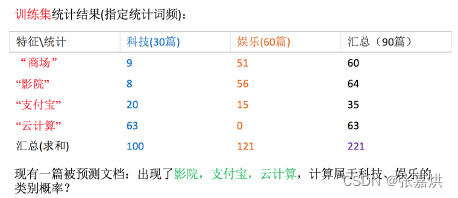
例如文章分类计算
代入公式:
# 由于分母 P(W) 相同,所以直接比较分子
科技:
P(科技|影院,支付宝,云计算)
= 𝑃(影院,支付宝,云计算|科技)∗P(科技)
= (8/100)∗(20/100)∗(63/100)∗(30/90)
= 0.00456109
娱乐:
P(娱乐|影院,支付宝,云计算)
= 𝑃(影院,支付宝,云计算|娱乐)∗P(娱乐)
= (56/121)∗(15/121)∗(0/121)∗(60/90)
= 0
是否为娱乐类别的计算概率为0,这显然不合适,所以用拉普拉斯平滑系数来防止计算概率为0
2,拉普拉斯平滑系数

此时我们再计算上述的文章类别
P(娱乐|影院,支付宝,云计算)
= P(影院,支付宝,云计算|娱乐)P(娱乐)
= P(影院|娱乐)*P(支付宝|娱乐)*P(云计算|娱乐)P(娱乐)
= (56+1/121+4)(15+1/121+4)(0+1/121+1*4)(60/90) = 0.00002
四、API
# alpha:拉普拉斯平滑系数
sklearn.naive_bayes.MultinomialNB(alpha = 1.0)
五、实操
案例:20类新闻分类
数据来源于 sklearn,大约有 20000 个新闻组文档,通过 sklearn.datasets.fetch_20newsgroups(subset='all') 来获取。
步骤:
- 获取数据
- 分割数据集
- tfidf进行特征抽取
- 朴素贝叶斯预测
代码
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
news = fetch_20newsgroups(subset='all')
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.3)
# 对于文本数据,进行特征抽取
tf = TfidfVectorizer()
x_train = tf.fit_transform(x_train)
# 不能调用fit_transform
x_test = tf.transform(x_test)
# estimator估计器流程
mlb = MultinomialNB(alpha=1.0)
mlb.fit(x_train, y_train)
# 进行预测
y_predict = mlb.predict(x_test)
print("预测每篇文章的类别:", y_predict[:100])
print("真实类别为:", y_test[:100])
print("预测准确率为:", mlb.score(x_test, y_test))
六、总结
优点:
- 朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率。
- 对缺失数据不太敏感,算法也比较简单,常用于文本分类。
- 分类准确度高,速度快
缺点:
- 由于使用了样本属性独立性的假设,所以如果特征属性有关联时其效果不好