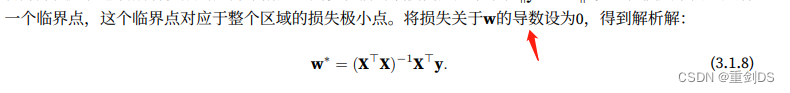眼睛是人心灵的窗户,我们可以通过凝视对方的眼神来理解他人。当有一天你走过一道需要刷脸才能通过的大门,突然间看到一个冰冷的摄像头在凝视着你的时候,你是否也曾若有所思地看着它,心中充满了疑惑——它是如何工作的?我每天的穿着打扮如此不同,它究竟是怎么认识我的?它有记忆吗?会思考吗?
如果要评选人类身上最精巧的器官,那么眼睛一定会在候选名单之中。
视觉能够给我们的生活带来极其丰富的体验,比如坐在海边一座安静的小屋门口,悠闲地看潮涨潮落,离不开视觉;在科研机构的实验室中,科学家们通过显微镜观察细胞的各种结构,靠的是视觉;在一次商业谈判中,我们通过观察对方代表的面部微表情,判断对方的心理从而让我方获取更大的利润,依旧离不开视觉。
通过视觉我们可以获得大量的外部信息,视觉也成为我们与外部世界交互中最有效的手段。
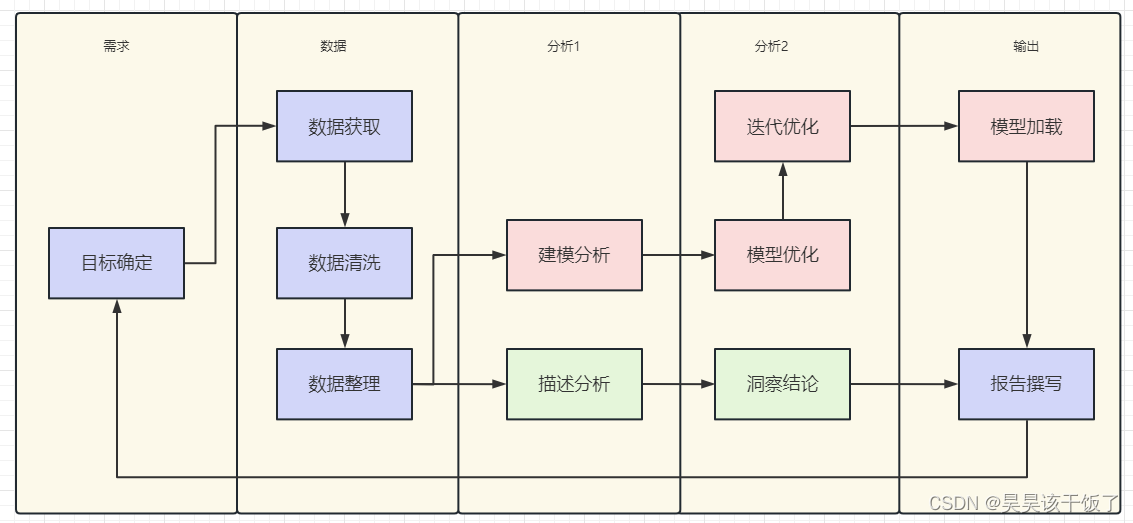
1、机器有视觉吗
视觉对于人类来说非常重要,那么计算机是否也能具有视觉呢?
答案是肯定的。
计算机视觉简称 CV(Computer Vision),这个概念在20世纪下半叶就已被提出。计算机的视觉器官主要是摄像头,如同我们的眼睛一样可以接收图像信号。但是如何处理与分析这些信号,产生“认知”并做出“决策”,才是计算机视觉这项技术的奥秘所在。
图像在计算机世界里通常以一系列网格状像素矩阵的形式出现,这一表示形式是大多数图像处理技术的基础。我们可以通过坐标位置来确定某个像素点的位置,并通过更改该点的像素值来更改图像的显示。
图像的色彩空间常用RGB表示,即 Red(红),Green(绿),Blue(蓝)。空间中的RGB 分布的取值范围为[0, 255],呈均匀分布,如图1所示。
■ 图1 分别输入R、G、B值就能得到想要的颜色(A 指透明度,取值在 0~1)
除了RGB,为了更好地表示图像信息,颜色空间还有两种常用的表示方法:HSV和HLS。
图像处理有很多实际的应用,比如图像增强。例如20世纪50年代末,卫星航拍的图像往往不够清晰,这时候人们通过计算机的图像增强功能来获取更加清晰的图像,从而为专家进行分析提供便利。图像的超分辨率研究如何从低像素图像而获得高分辨率的图像,如在交通领域应用的车牌清晰处理等。
模式识别主要是指识别出图像中某些特定的概念,例如找出图片中的一只猫(图 2), 或在一张充满汉字的图片上找到某个特定的汉字。

■ 图2 不知道这张“猫片”计算机能不能识别出来?
如何在一个基于数学逻辑的机器上形成某种概念,是模式识别和机器学习研究的重点。模式识别在20世纪60年代初开始得到广泛认可,当时就已经有识别程序,能够识别图片中的英文字符。虽然识别效果和现代技术不可同日而语,但模式识别还是能够减少一部分人工的工作量,人们不再需要将字符一个个手动输入计算机。
1965 年,罗伯茨的研究是计算机视觉研究从二维转向三维的标志。

通过一遍遍地让计算机观察圆锥、圆球、立方体等模型的图片(如图3所示),一遍遍地调试程序,罗伯茨成功地让计算机识别出二维图像中的三维结构和空间布局,这使得计算机从二维图像中提取三维信息成为了可能。从此,计算机视觉领域得到突飞猛进的发展。
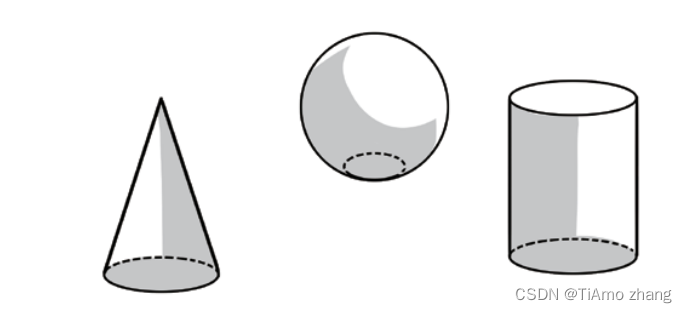
■ 图3 罗伯茨成功地让计算机识别出二维图像中的三维结构和空间布局
2、计算机视觉能帮我们做什么
如今,计算机视觉在多个领域得到了广泛应用,例如图像增强技术已被广泛应用于医疗、航空航天以及交通监控等方面。
在以往的 X 光检测中,由于一些器官的特殊结构,这些器官在X光片中清晰度不够,从而给医疗诊断带来极大不便。将图像增强技术应用于 X 光检测领域,可以让医生更加准确地诊断病人的病情。
在航空航天以及工业领域,图像增强技术可以有效去除图像中的干扰,获取更清晰的图像以供分析。在图像增强技术和更先进的光学镜头的帮助下,人们在一些军用卫星拍摄的照片中甚至能清晰地分辨出地面上几厘米长度的线段。
在交通监控领域,图像增强技术也带来了巨大的便利。在晴朗的天气中,交通摄像头固然能够良好运作,而在雨天、雾天或是夜晚,摄像头取得的图像会受到干扰。此时,图像增强技术就可以在一定程度上去除这些干扰,更好地监控路面信息以保护我们的安全。
在模式识别方面,计算机视觉的发展就更令人惊叹。现在我们拿起手机拍照时,手机不 仅能够快速且准确地从图片中识别人脸的位置,还能够识别人脸的表情,在微笑时自动拍照(微笑快门)。此外,大家对手机拍照中的美颜功能并不陌生,除了准确识别五官的位置,手机还能在拍照时就针对性地对眼睛、鼻子、皮肤等进行相应的美颜,省去了人们在拍照之后还要花时间去处理图片的烦恼。
2015 年,微软推出了一个网站——How-old.net,这个网站可以对人们上传的图片中的人脸进行识别,根据相应算法预测其年龄。虽然有时候结果不够准确,但完全不影响人们乐此不疲地上传照片。当我们的行李从地铁站、火车站或机场的安检仪中快速滑过时,计算机能根据 X 光图像对行李箱中的物品进行识别,不同物品会以不同颜色色块的形式清晰地呈现在安检员面前。

在漫画创作中,最为费时费力的部分就是给漫画中的角色上色了,很多漫画大师(如宫 崎骏)都是在创作出基础人设和线稿后,将具体人物和分镜头交给工作室的资深漫画家来做, 而上色部分则是最没有技术含量但是最耗费人工的部分。
如果用基于机器学习的图像处理方法,算法可以学习到一个线稿与颜色之间的关系,然后自动给漫画上色。比如图4中的小猫,即使我们改变它的形态,算法仍然可以学习到为其上色的方法。
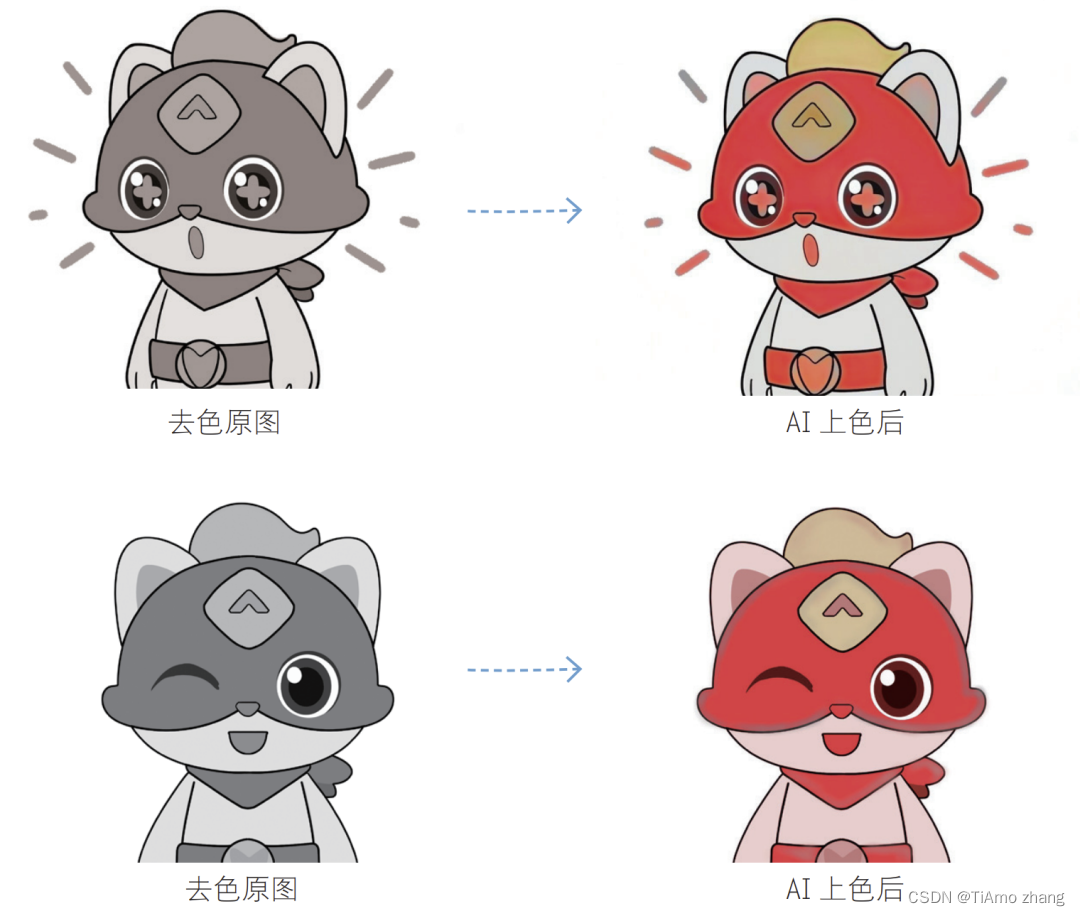
■ 图4 漫画自动上色
3、如何让计算机理解“眼前”的世界
在计算机视觉发展初期,研究的重点还仅限于“看见”。对于人类来说,视觉不仅仅是为了看见,而是为了对看见的事物做出反应,更好地理解这个世界。因此专家们也希望能赋予计算机这样的能力。
一款名为Kinect 的带有深度传感器的摄像头能够捕捉这个人做出的动作,根据不同的动作,Kinect 背后的计算机会做出不同的反应,这也就是人们常说的“体感游戏”。这种不需要手柄,靠自己的身体动作来操纵的游戏机在当时受到了热烈追捧。
还有一项计算机视觉技术也正逐步来到我们身边。我们在看电影时一定都见过这样的场景,在一个人流量巨大的场所(比如机场),警察为了追踪一个罪犯,在监控室中将罪犯的头像与监控器中的人脸进行比对。在经过短暂的比对后,罪犯的人脸在监控画面上被标记出来。更令人惊叹的是,监控摄像头一旦锁定了目标,就一直自动跟随着目标移动,直至罪犯被警察抓住。

今天的计算机视觉技术包括多个不同的研究方向,其中关注度较高的领域有目标检测、语义分割、运动和跟踪、视觉问答等。
目标检测是计算机视觉中非常重要的一个研究方向——通过输入的图片识别图片中的特定物体,并输出其所属类别及位置。根据不同检测对象,可以衍生出人脸检测、车辆检测等细分的检测算法。
4、文末送书
参与方式:文章三连并评论“卷不动了就歇会”参与抽奖,48小时后程序会自动从评论区抽取6位小伙伴送出技术图书1本(本/人)!
本次送出的书籍:

作者:[美] 道格·罗斯(Doug Rose)
译者:刘强

作者:[美] 保罗·戴特尔,[Paul,J.Deitel]
[美] 哈维·戴特尔(Harvey
译者:王恺、王刚、于名飞 等

作者:[美] 马克·E.芬纳(Mark E. Fenner)
译者:江红,余青松,余靖

作者:[美] 劳拉·格雷泽(Laura Graesser) 等
译者:许静、过辰楷、金骁、刘磊、朱静雯 等

作者:[美] 安德鲁·凯莱赫(Andrew Kelleher)
亚当·凯莱赫(Adam,K
译者:陈子墨、刘瀚文