大家好,我是小米,在技术的海洋中畅游的小编。今天,我要带你探索SQL JOIN的神奇原理,为你解锁高效数据查询的技巧!无论你是初学者还是资深开发者,相信这篇文章都能给你带来新的启发。废话不多说,我们立即进入主题!
JOIN基本概念
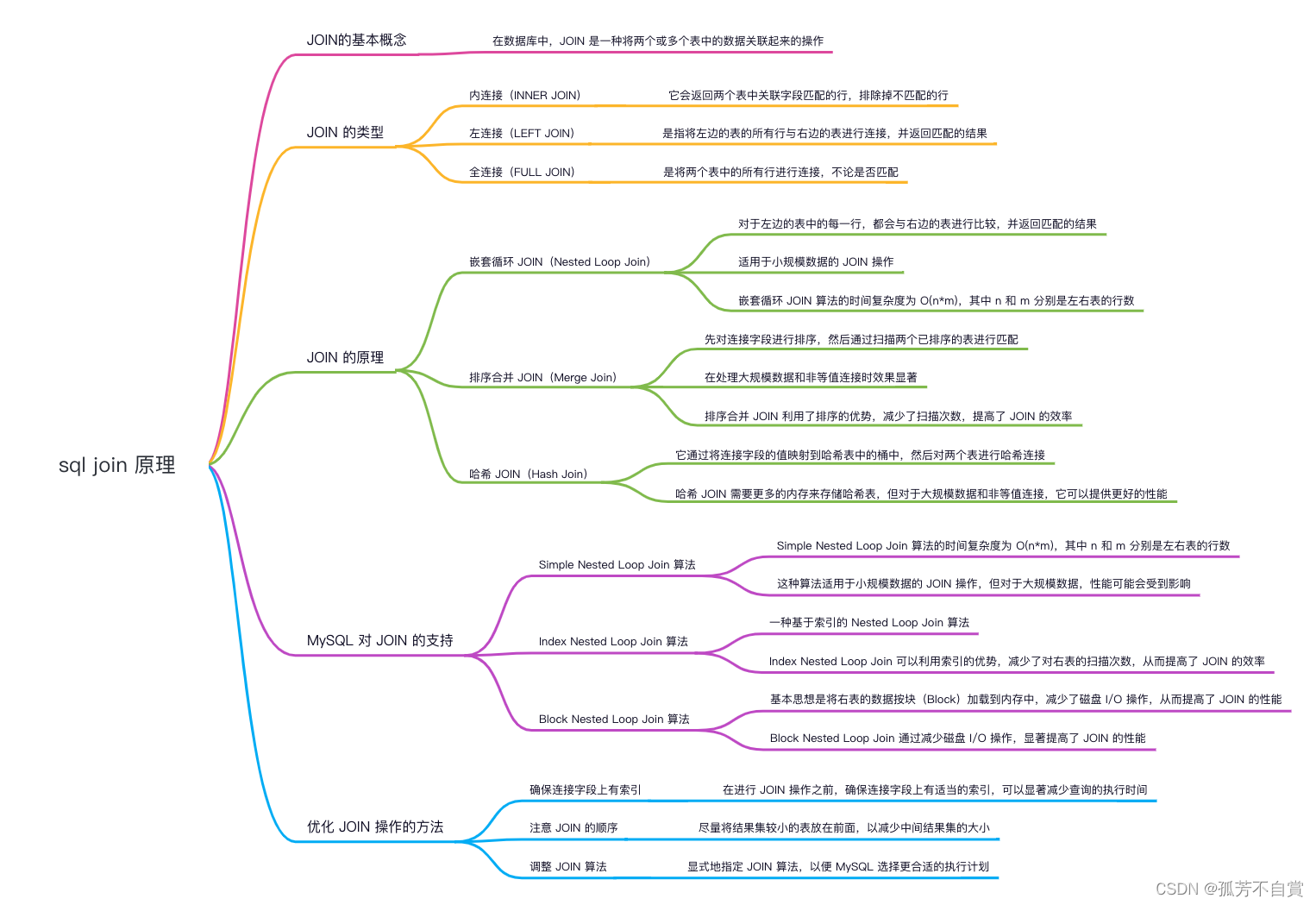
在开始深入探讨 JOIN 的原理之前,我们先来了解一下 JOIN 的基本概念。在数据库中,JOIN 是一种将两个或多个表中的数据关联起来的操作。通过使用 JOIN,我们可以根据两个或多个表之间的关联字段将它们的数据合并在一起,以便进行更复杂的查询和分析。
在 SQL 中,有几种不同类型的 JOIN 可供我们使用。下面我将介绍三种最常见的 JOIN 类型。
内连接
内连接(INNER JOIN)是最基本的 JOIN 类型之一。它会返回两个表中关联字段匹配的行,排除掉不匹配的行。内连接只返回匹配的结果,因此可以过滤掉不相关的数据,提高查询效率。
左连接
左连接(LEFT JOIN)是指将左边的表的所有行与右边的表进行连接,并返回匹配的结果。如果右边的表中没有与左边表匹配的行,则返回 NULL 值。左连接常用于获取左表中的所有数据以及与之相关的右表数据。
全连接
全连接(FULL JOIN)是将两个表中的所有行进行连接,不论是否匹配。如果两个表中的某行在另一个表中没有匹配,那么将使用 NULL 值填充。全连接返回的结果包含了左连接和右连接的所有数据。
接下来,我们将深入探讨 JOIN 的原理,主要包括三种常见的 JOIN 算法:嵌套循环 JOIN、排序合并 JOIN 和哈希 JOIN。
嵌套循环连接
嵌套循环 JOIN(Nested Loop Join)是一种简单但效率较低的 JOIN 算法。它的原理是对于左边的表中的每一行,都会与右边的表进行比较,并返回匹配的结果。这种算法适用于小规模数据的 JOIN 操作,但对于大规模数据,性能可能会受到影响。
嵌套循环 JOIN 的步骤如下:
- 对于左边的表,逐行读取每一行。
- 对于右边的表,逐行扫描,并与左边表的当前行进行比较。
- 如果连接字段的值匹配,则将两个表的匹配行合并,并返回结果。
- 继续对右边的表进行扫描,直到找到所有匹配的行。
- 然后,读取左边表的下一行,重复上述步骤,直到处理完所有行。
嵌套循环 JOIN 算法的时间复杂度为 O(n*m),其中 n 和 m 分别是左右表的行数。
排序合并连接
排序合并 JOIN(Merge Join)是一种更高效的 JOIN 算法。它的原理是先对连接字段进行排序,然后通过扫描两个已排序的表进行匹配。这种算法在处理大规模数据和非等值连接时效果显著。
排序合并 JOIN 的步骤如下:
- 对连接字段在左右两个表上进行排序。
- 同时扫描两个表,比较连接字段的值。
- 如果连接字段的值相等,则将两个表的匹配行合并,并返回结果。
- 继续扫描,直到找到所有匹配的行。
- 如果连接字段的值不相等,则根据排序顺序继续扫描。
排序合并 JOIN 利用了排序的优势,减少了扫描次数,提高了 JOIN 的效率。
哈希连接
哈希 JOIN(Hash Join)是一种基于哈希表的 JOIN 算法。它通过将连接字段的值映射到哈希表中的桶中,然后对两个表进行哈希连接。哈希 JOIN 需要更多的内存,但对于大规模数据和非等值连接,它可以提供更好的性能。
哈希 JOIN 的步骤如下:
- 对于左边的表,将连接字段的值进行哈希计算,并将每个值存储到哈希表的相应桶中。
- 对于右边的表,逐行扫描并计算连接字段的哈希值。
- 在哈希表中查找匹配的哈希值,找到对应的桶。
- 将匹配的行合并,并返回结果。
- 继续扫描右边的表,直到找到所有匹配的行。
哈希 JOIN 需要更多的内存来存储哈希表,但对于大规模数据和非等值连接,它可以提供更好的性能。
MySQL对JOIN的支持
相对于其他数据库管理系统,MySQL 在 JOIN 操作中的支持相对较少。它主要采用嵌套循环 JOIN 算法,而不支持哈希连接和排序合并连接。不过,在 MySQL 中有一些变种算法,可以帮助 MySQL 提高 JOIN 的执行效率。
Simple NLJ算法
Simple Nested Loop Join 是 MySQL 中的一种变种算法。其基本原理如下:
- 对于左边的表,逐行读取每一行。
- 对于右边的表,逐行扫描,并与左边表的当前行进行比较。
- 如果连接字段的值匹配,则将两个表的匹配行合并,并返回结果。
- 继续对右边的表进行扫描,直到找到所有匹配的行。
- 然后,读取左边表的下一行,重复上述步骤,直到处理完所有行。
Simple Nested Loop Join 算法的时间复杂度为 O(n*m),其中 n 和 m 分别是左右表的行数。这种算法适用于小规模数据的 JOIN 操作,但对于大规模数据,性能可能会受到影响。
Index NLJ算法
Index Nested Loop Join 是一种基于索引的 Nested Loop Join 算法。它使用索引来加速 JOIN 操作,尤其在连接字段上有索引的情况下,可以显著提高性能。
Index Nested Loop Join 的原理如下:
- 对于左边的表,逐行读取每一行。
- 对于右边的表,使用连接字段上的索引进行快速查找匹配的行。
- 将两个表的匹配行合并,并返回结果。
- 继续对左边表的下一行进行处理,重复上述步骤,直到处理完所有行。
Index Nested Loop Join 可以利用索引的优势,减少了对右表的扫描次数,从而提高了 JOIN 的效率。
Block NLJ算法
Block Nested Loop Join 是一种优化的 Nested Loop Join 算法。其基本思想是将右表的数据按块(Block)加载到内存中,减少了磁盘 I/O 操作,从而提高了 JOIN 的性能。
Block Nested Loop Join 的步骤如下:
- 对于左边的表,逐行读取每一行。
- 从右表中按块加载数据到内存中。
- 对于每个块,与左边表的当前行进行比较并找到匹配的行。
- 将匹配的行合并,并返回结果。
- 继续对左边表的下一行进行处理,重复上述步骤,直到处理完所有行。
Block Nested Loop Join 通过减少磁盘 I/O 操作,显著提高了 JOIN 的性能。
优化 JOIN 操作的方法
除了选择合适的 JOIN 算法外,我们还可以采取一些优化方法来提高 JOIN 的执行效率。
- 确保连接字段上有索引:索引是加快 JOIN 操作的关键。在进行 JOIN 操作之前,确保连接字段上有适当的索引,可以显著减少查询的执行时间。
- 注意 JOIN 的顺序:JOIN 的顺序对性能有重要影响。尽量将结果集较小的表放在前面,以减少中间结果集的大小。此外,根据查询条件和表之间的关系,选择合适的 JOIN 类型和顺序也是优化的关键。
- 调整 JOIN 算法:在某些情况下,我们可以显式地指定 JOIN 算法,以便 MySQL 选择更合适的执行计划。通过分析查询的特性和数据的分布,选择合适的 JOIN 算法,可以进一步提高查询性能。
总结
通过本文的介绍,我们了解了 JOIN 的基本概念和常见的 JOIN 类型。同时,深入探讨了嵌套循环 JOIN、排序合并 JOIN 和哈希 JOIN 这三种常见的 JOIN 算法及其优化。此外,我们还了解到 MySQL 对 JOIN 的支持较少,但可以通过一些变种算法来提高 JOIN 的执行效率。最后,我们介绍了一些优化 JOIN 操作的方法,包括索引的使用、JOIN 顺序的调整以及选择合适的 JOIN 算法。
END
希望通过本文的介绍,你对 SQL JOIN 的原理有了更深入的了解,并且能够在实际应用中优化 JOIN 操作,提高数据库的性能。如果你对此还有任何疑问或需要进一步了解,请随时留言交流。感谢大家的阅读!