一、 ImagesPipeline是啥
ImagesPipeline是scrapy自带的类,用来处理图片(爬取时将图片下载到本地)。
二、ImagesPipeline优势:
- 将下载图片转换成通用的jpg和rgb格式
- 避免重复下载
- 缩略图生成
- 图片大小过滤
- 异步下载
三、ImagesPipeline工作流程
- 爬取一个item,将图片的urls放入image_urls字段
- 从spider返回的item,传递到item pipeline
- 当item传递到imagepipeline,将调用scrapy 调度器和下载器完成image_urls中的url的调度和下载。
- 图片下载成功结束后,图片下载路径、url和校验和等信息会被填充到images字段中。
四、使用ImagesPipeline下载美女整页的图片
(1) 网页分析

详情页的信息

(2) 创建项目
scrapy startproject Uis
cd Uis
scrapy genspider -t crawl ai_img xx.com
(3) 修改setting.py文件
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 1
(4) 编写spider的文件ai_img.py
首先 查看ImagesPipeline源文件

import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from ..items import *
class AiImgSpider(CrawlSpider):
name = "ai_img"
allowed_domains = ["netbian.com"]
start_urls = ["http://www.netbian.com/mei/index.htm"] # 起始url
rules = (
Rule(LinkExtractor(allow=r"^http://www.netbian.com/desk/(.*?)$"), #详情页的路径
callback="parse_item", follow=False),)
def parse_item(self, response):
#创建item对象
item =UisItem()
# 图片url ->保存到管道中 是字符串类型
url_=response.xpath('//div[@class="pic"]//p/a/img/@src').get()
#图片名称
title_=response.xpath('//h1/text()').get()
# 注意:必须是列表的形式
item['image_urls']=[url_]
item['title_']=title_
return item(5) 编写item.py文件
class UisItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
#默认字段image_urls,查看源码
image_urls=scrapy.Field()
title_=scrapy.Field()
pass
(6)编写管道pipelines.py
首先 查看ImagesPipeline源文件
1) 默认保存的文件夹

2)获取Item对象

# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
import hashlib
from itemadapter import ItemAdapter
from scrapy import Request
from scrapy.pipelines.images import ImagesPipeline
from scrapy.utils.python import to_bytes
#继承ImagesPipeline
class UisPipeline(ImagesPipeline):
# 重写1:直接修改默认路径
# def file_path(self, request, response=None, info=None, *, item=None):
# image_guid = hashlib.sha1(to_bytes(request.url)).hexdigest()
# # 修改默认文件夹路径
# return f"desk/{image_guid}.jpg"
#重写2:需要修改文件夹和文件名
def file_path(self, request, response=None, info=None, *, item=None):
#获取item对象
item_=request.meta.get('db')
#获取图片名称
image_guid = item_['title_'].replace(' ','').replace(',','')
print(image_guid)
# 修改默认文件夹路径
return f"my/{image_guid}.jpg"
# 重写-item对象的图片名称数据
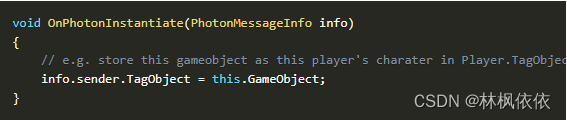
def get_media_requests(self, item, info):
urls = ItemAdapter(item).get(self.images_urls_field, [])
# 传递item对象
return [Request(u, meta={'db':item}) for u in urls](7)设置settings.py ,开启图片管道
ITEM_PIPELINES = {
#普通管道
# "Uis.pipelines.UisPipeline": 300,
# "scrapy.pipelines.images.ImagesPipeline": 301, #图片的管道开启
"Uis.pipelines.UisPipeline": 302, #自定义图片的管道开启
}
# 保存下载图片的路径
IMAGES_STORE='./'(8) 运行: scrapy crawl ia_img

(9)成果展示