目录
- 理论
- 框架
- text-to-imgae
- decoder
- generation model
- clip的原理
- FID指标:评估图像生成的好坏
- 数学原理
- training
- inference
- 图像生成模型的本质
- 最大似然估计
- 正式推导
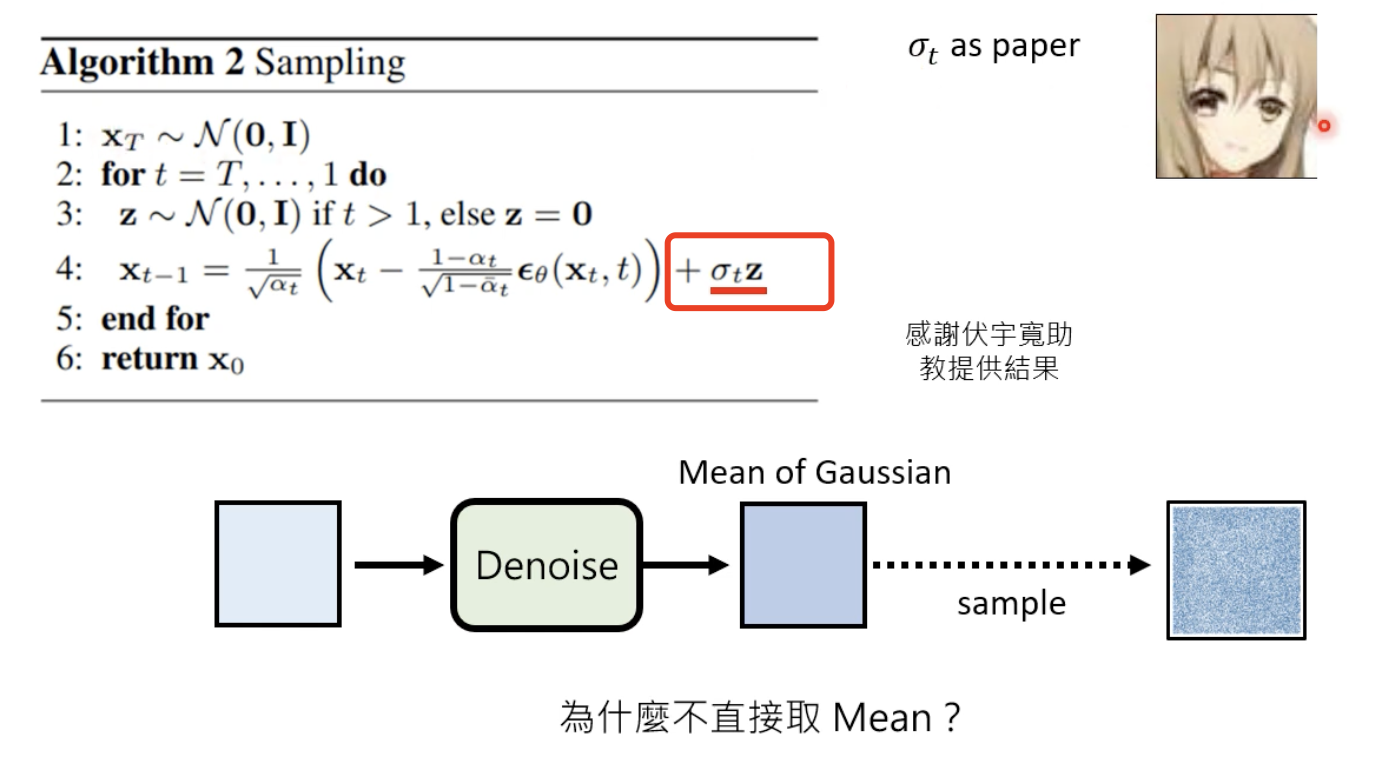
- sample 带来随机性
- 从一次到位到N次到位
理论
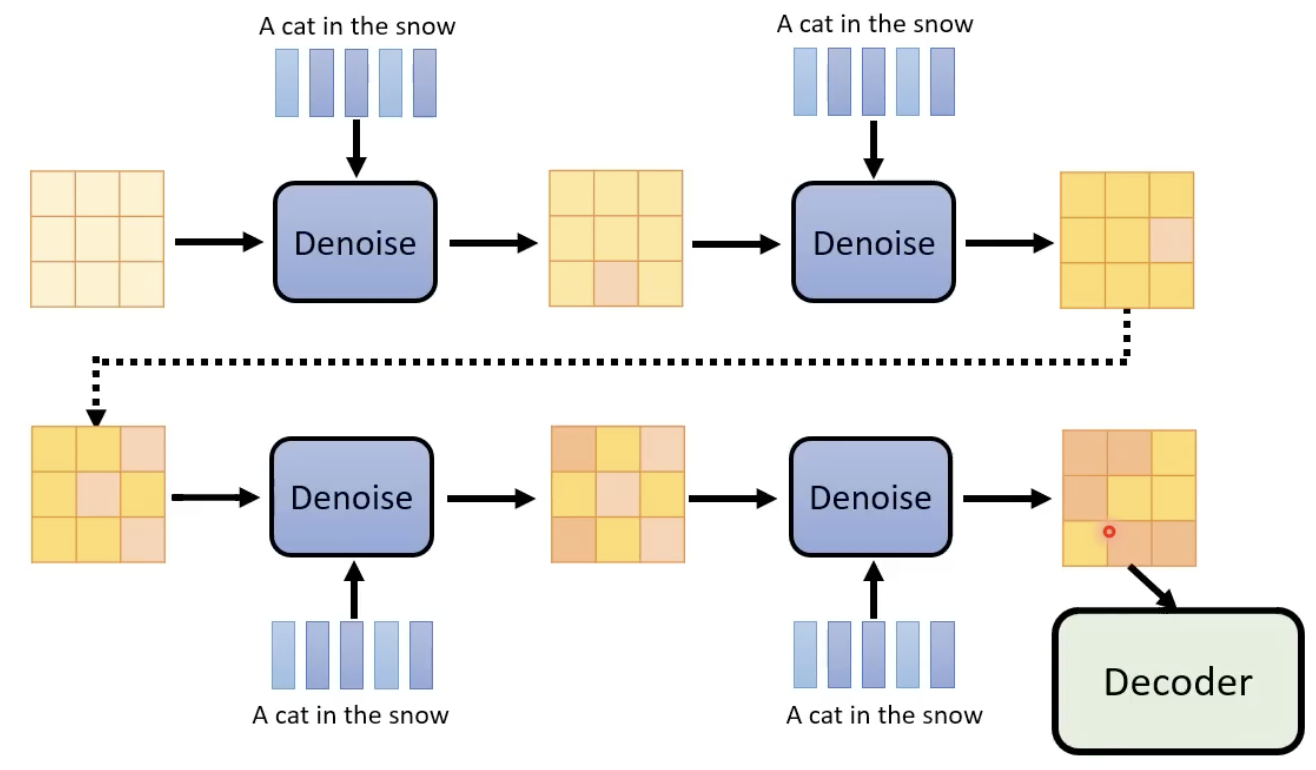
框架
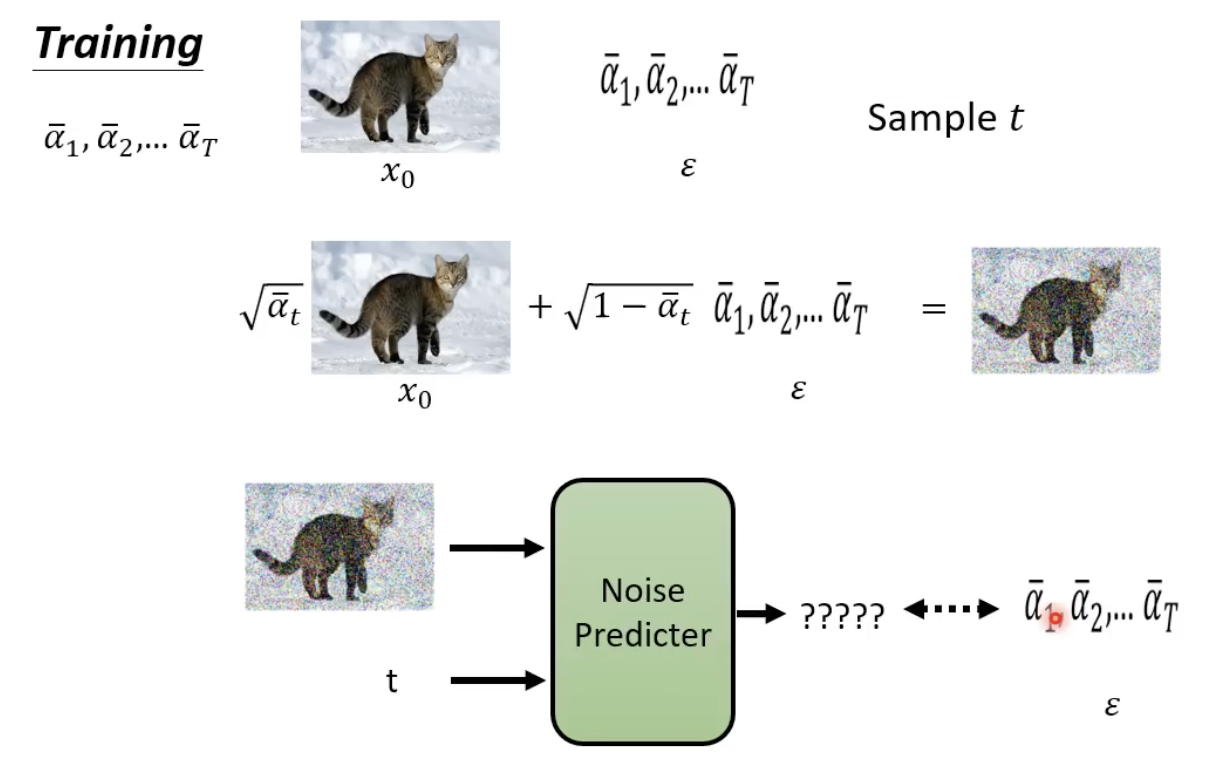
不断的进行去噪,并且在这个过程中,step也作为“去噪模型(其实就是扩散模型)”的输入:
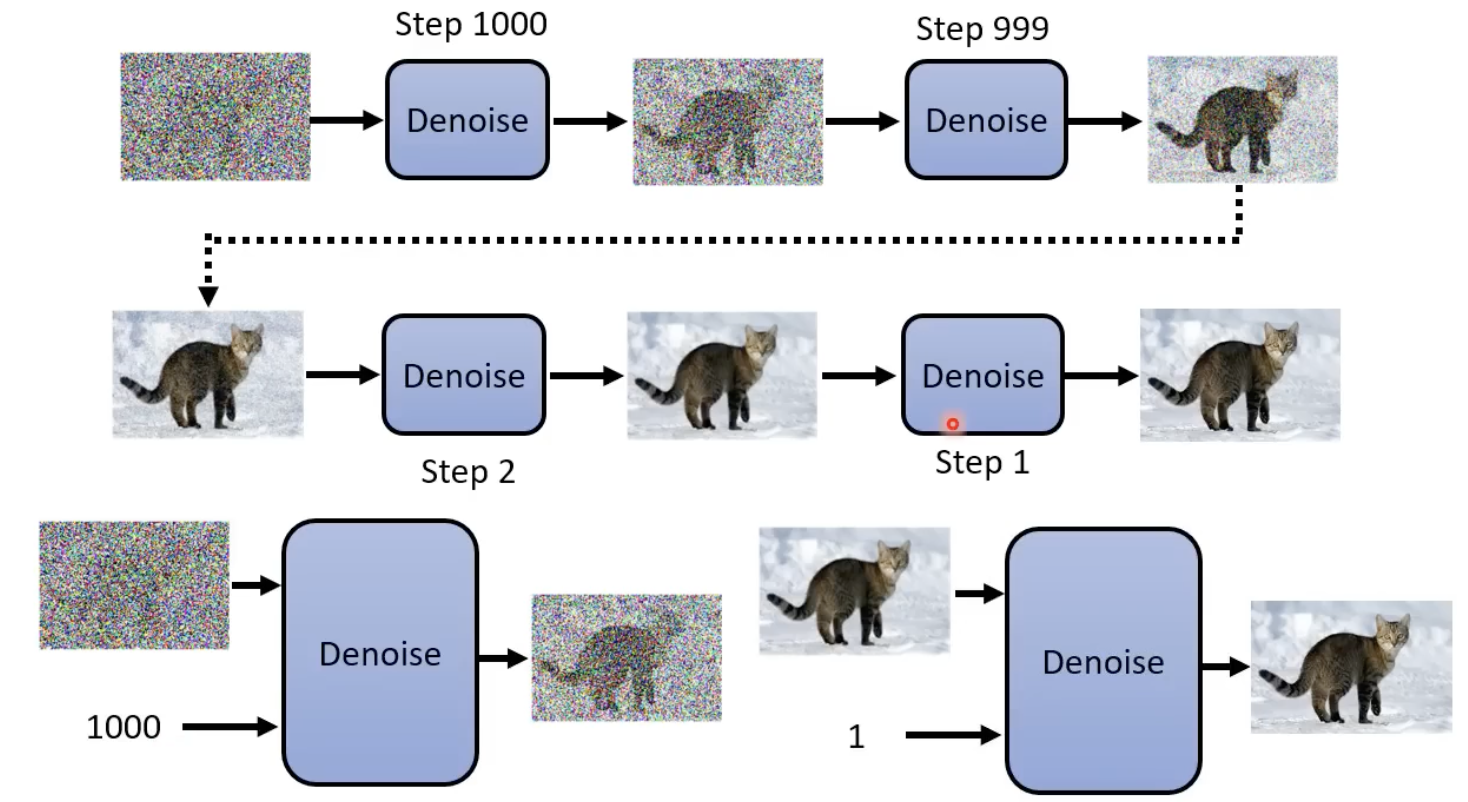
denoise 模型的内部结构长这样下图这样,他能够产生一张噪声,然后原始图像减去这个噪声,就能够得到更清楚的图像(去噪后的图像)了:
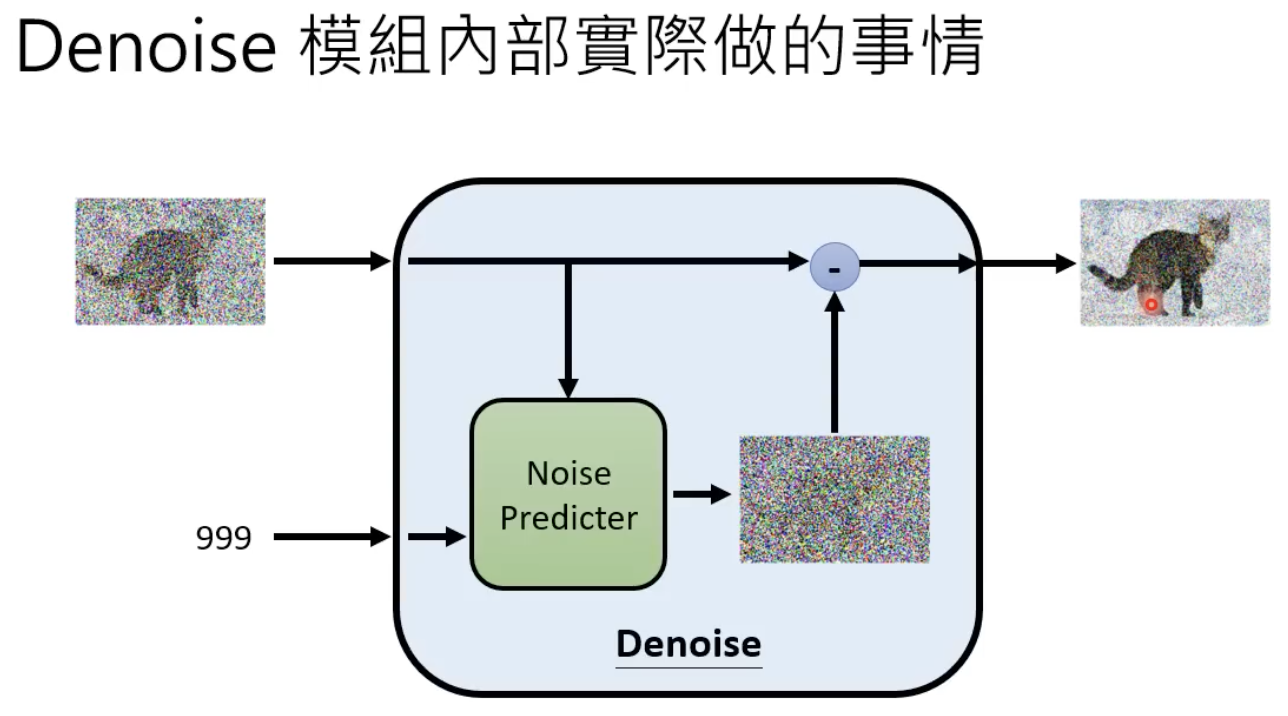
为什么denoise 模型不直接对图片进行去噪,而是其内部的 noise predicator产生一个噪声图片?因为难度不一样,产生一张噪声要容易得多。
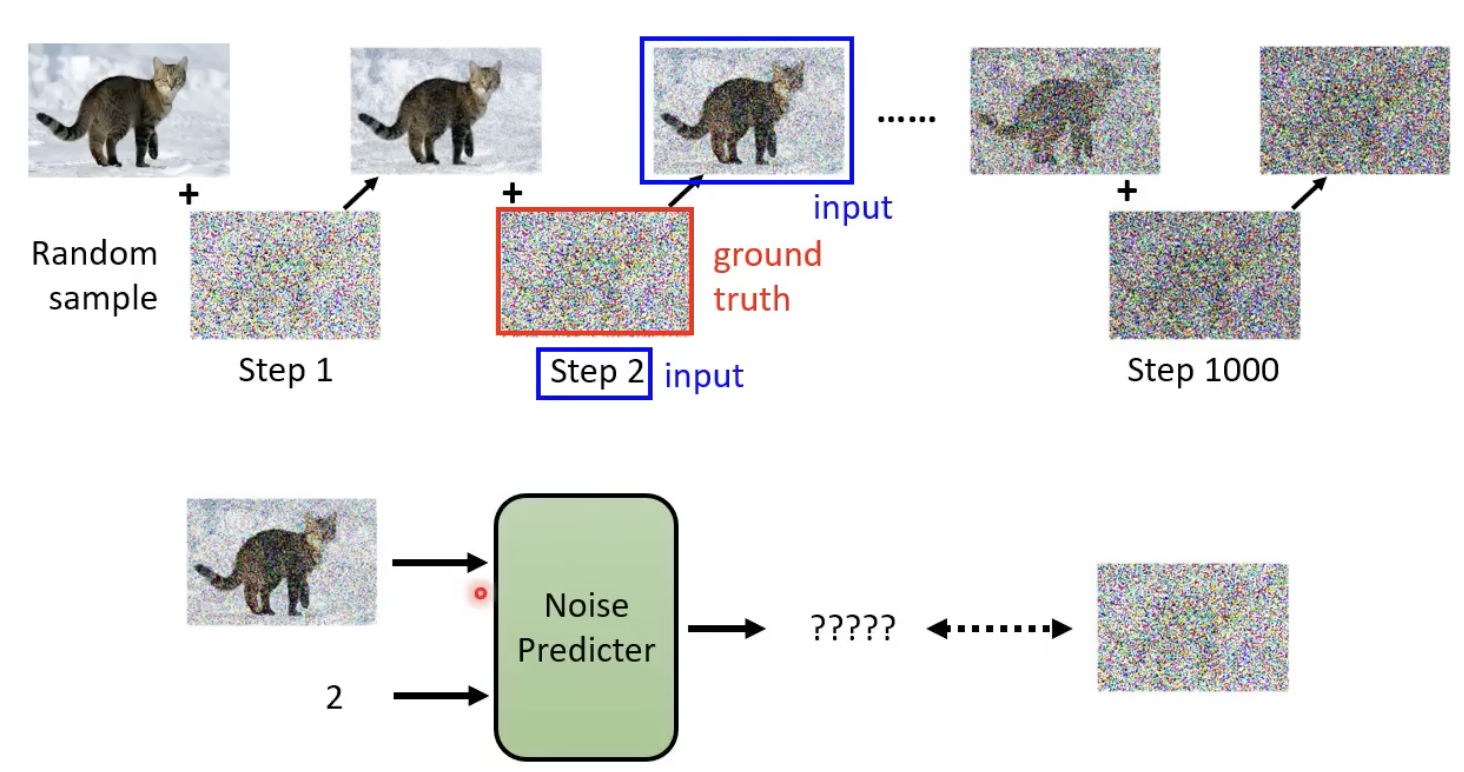
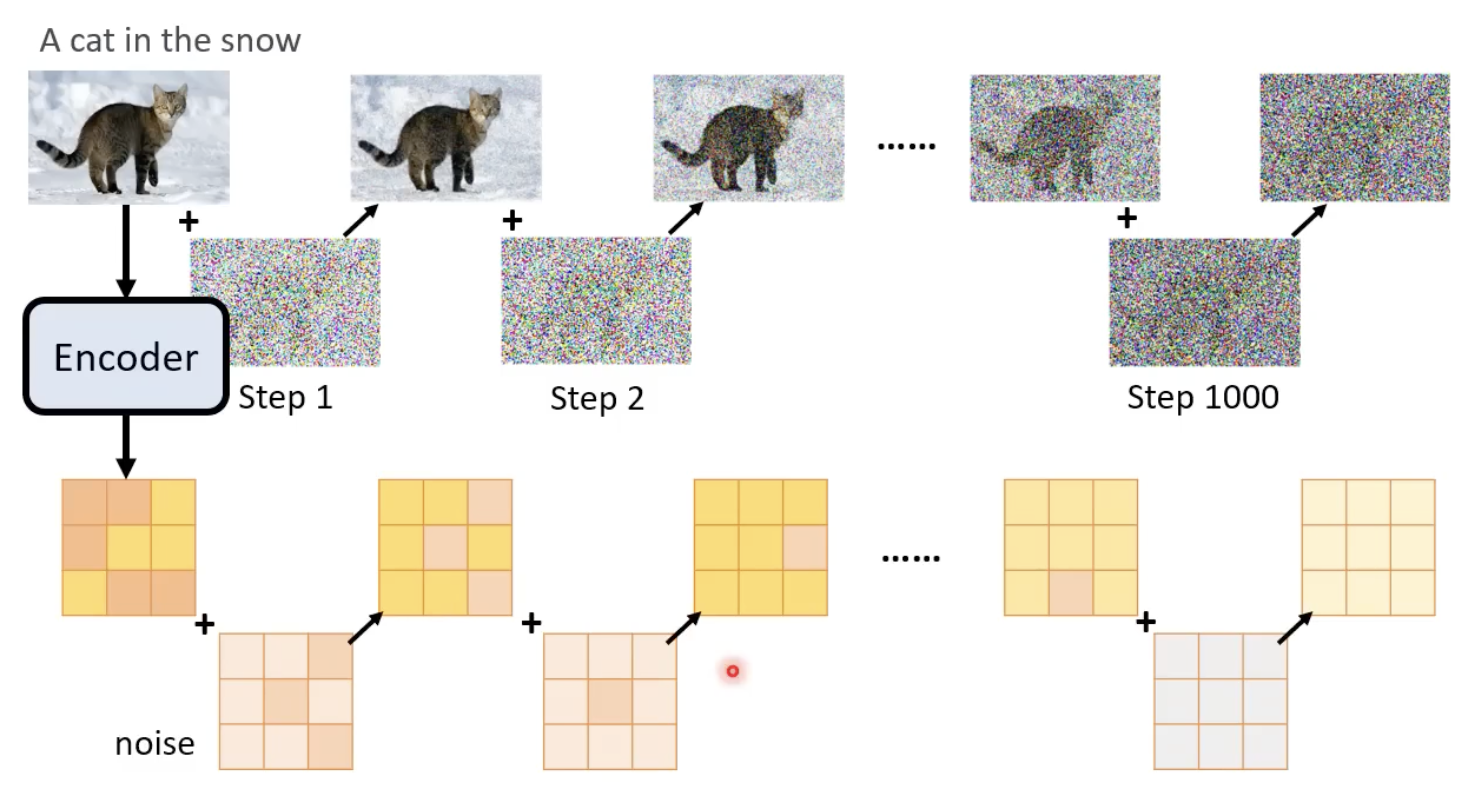
既然要其生成的是一张噪声,那么也需要有ground truth 的噪声,来进行该模型的训练:
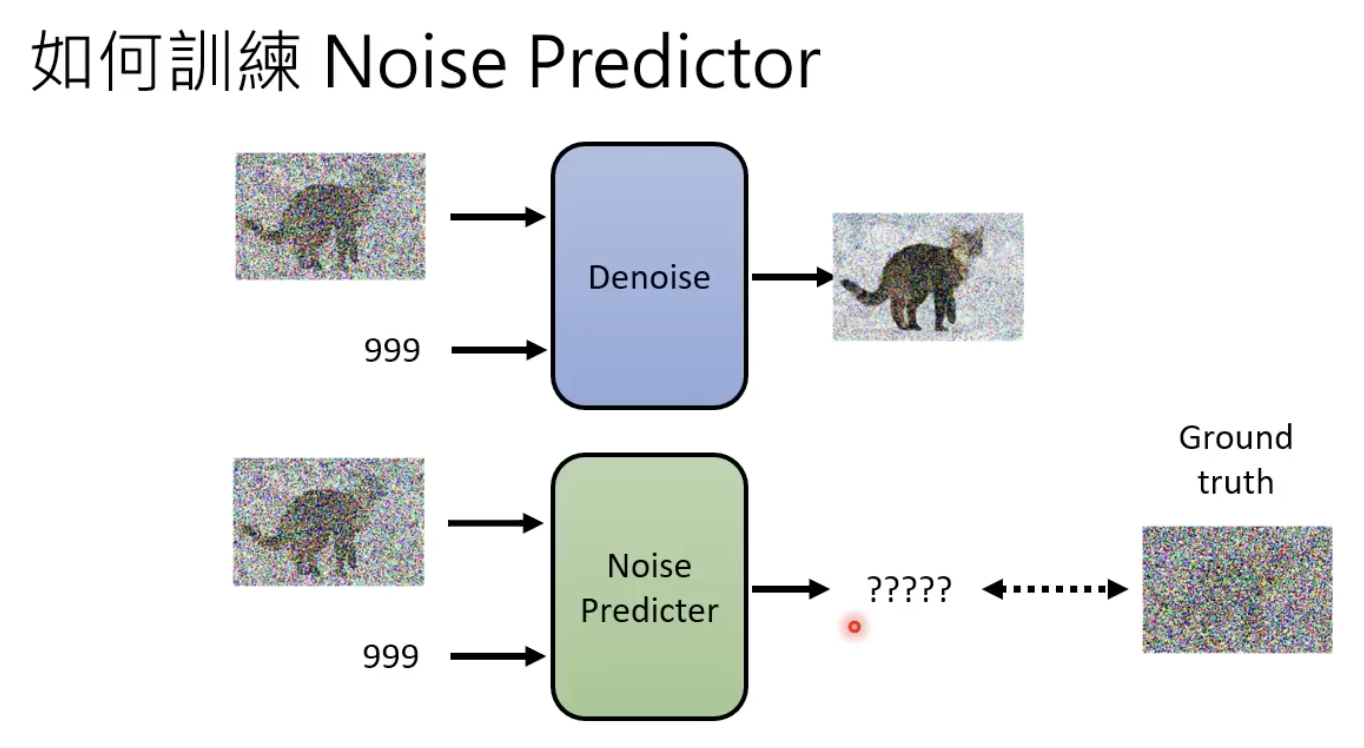
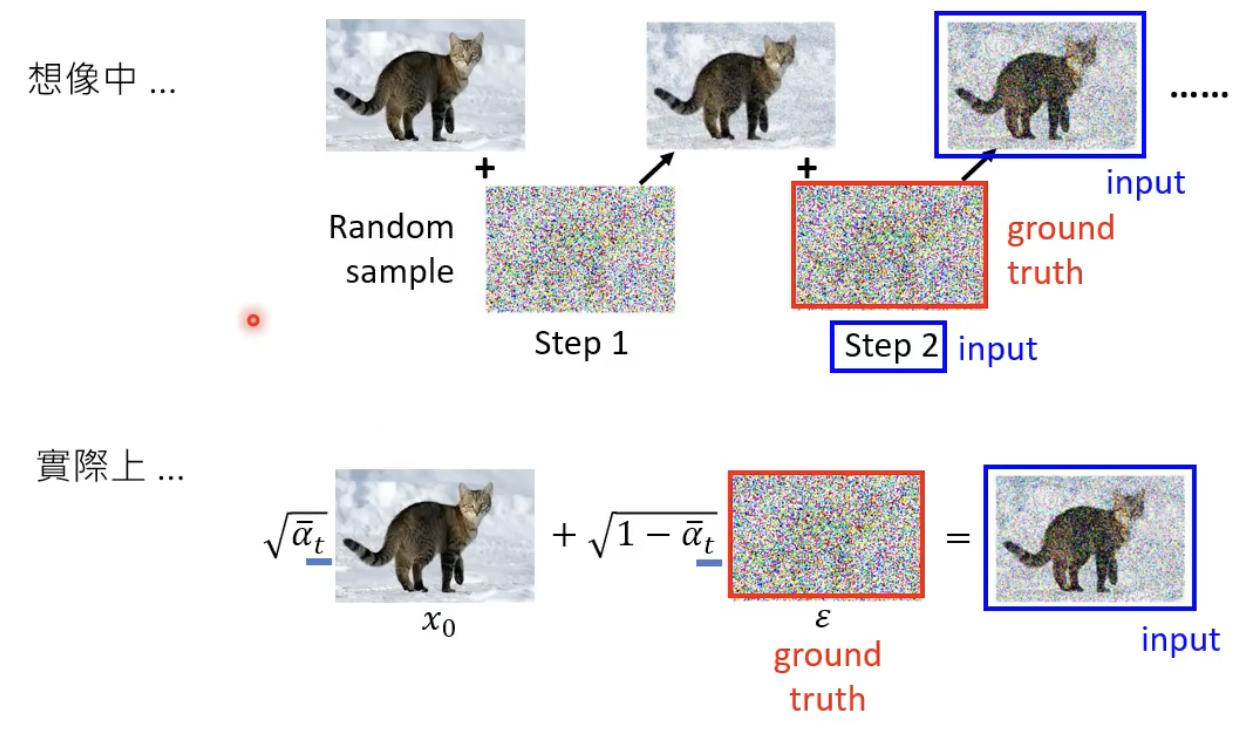
每一步的噪声的 ground truth 怎么来?——先加噪,然后记录下每个step所添加的噪声就是ground truth:
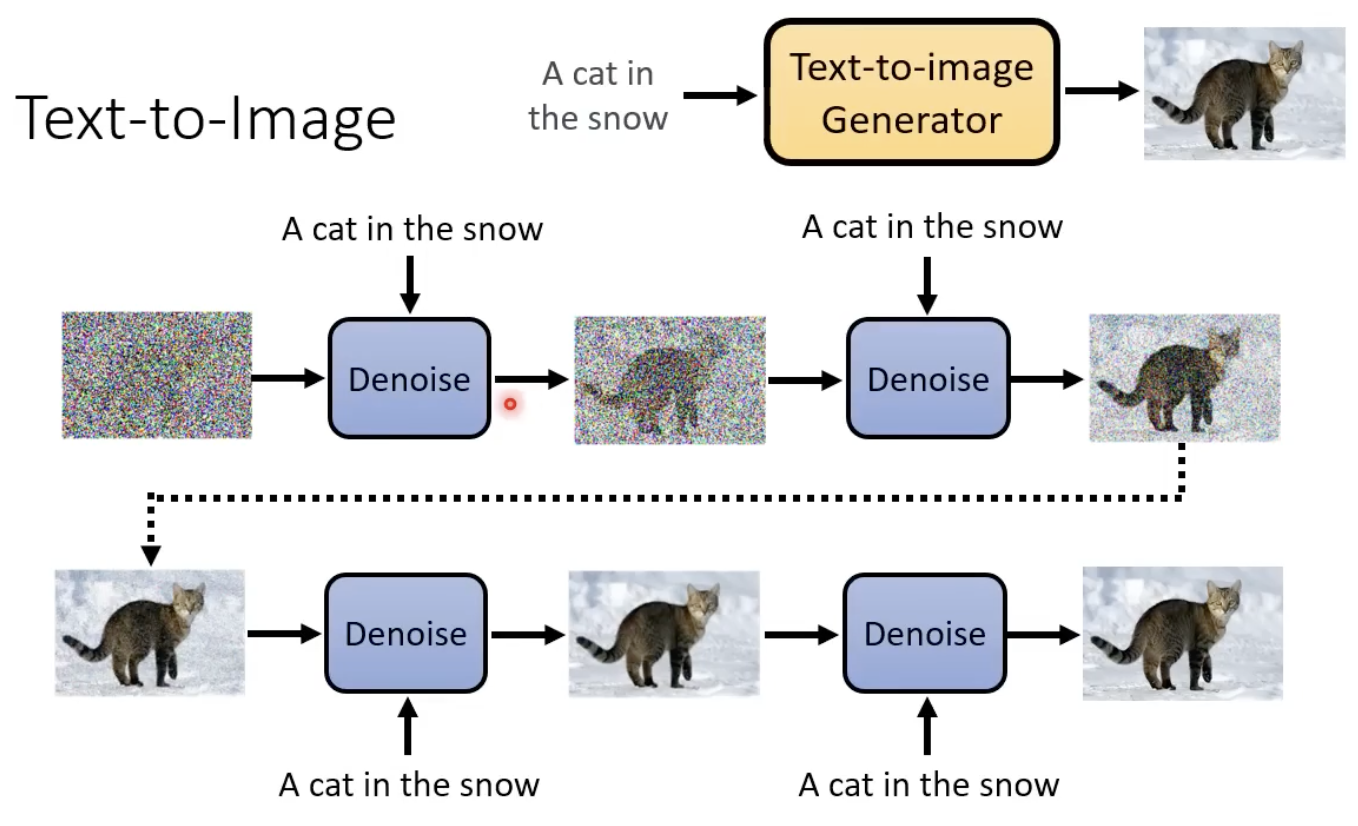
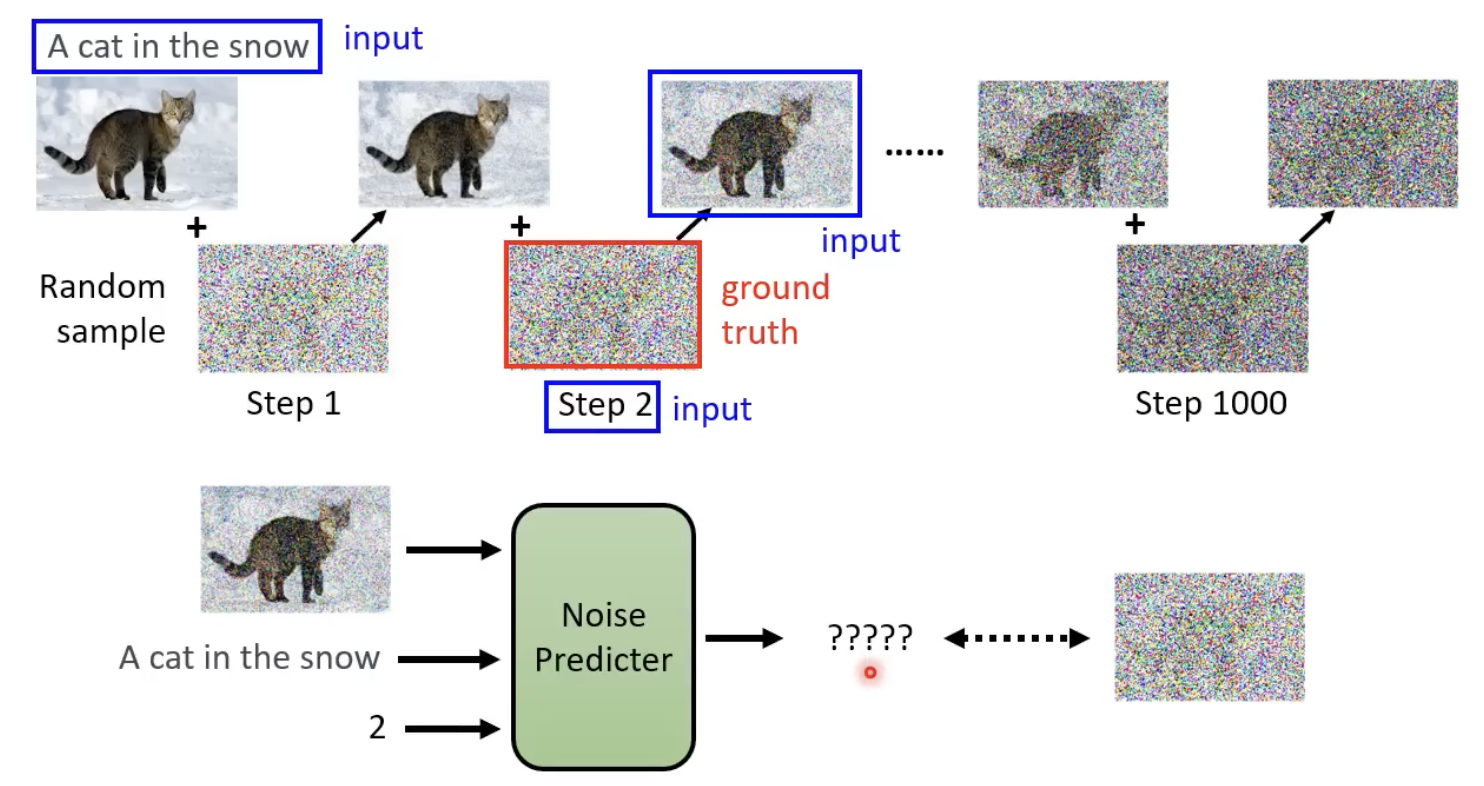
text-to-imgae
如果是这类模型,则每次noise predictor还需要添加一样的文字。
text-image DM模型的整体框架,需要依赖encoder、decoder等:
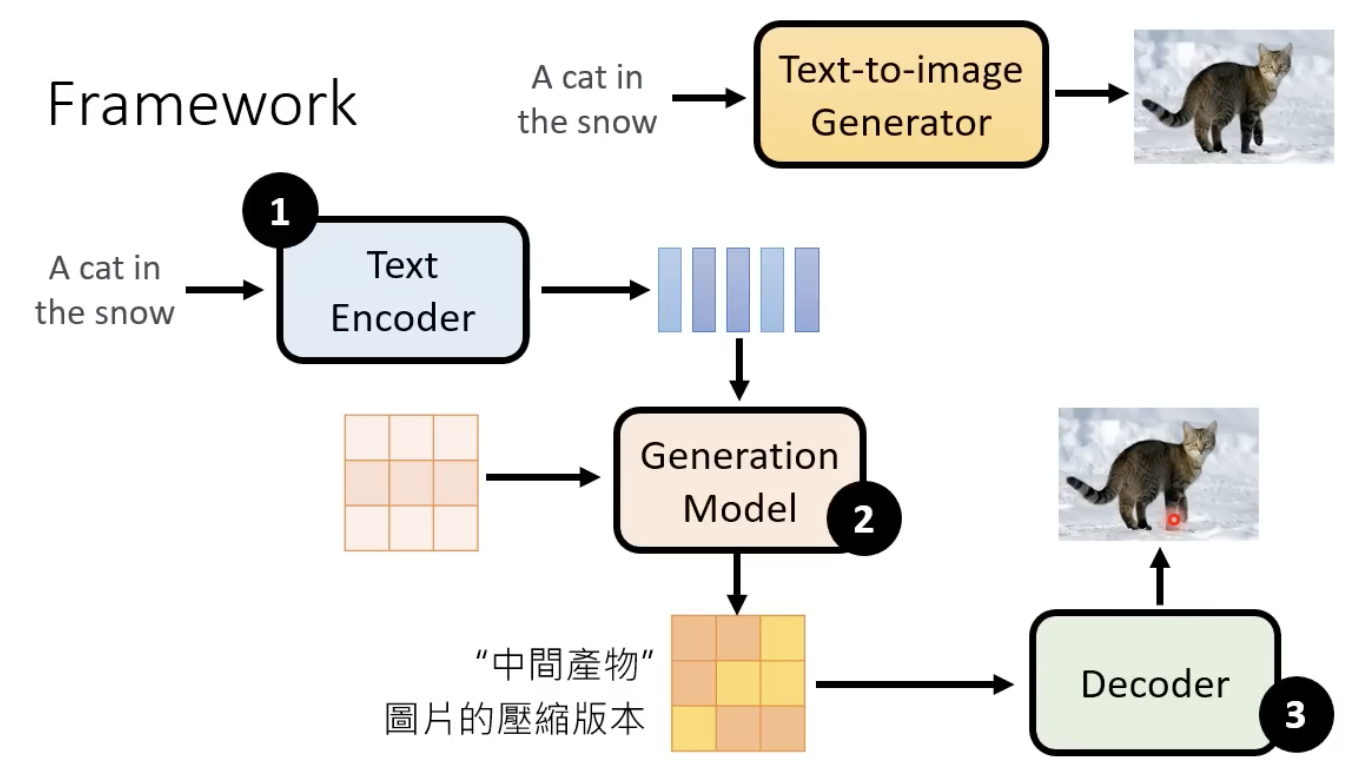
下面介绍encder、generation model、decoder,已经它们分别是怎么训练的。
decoder
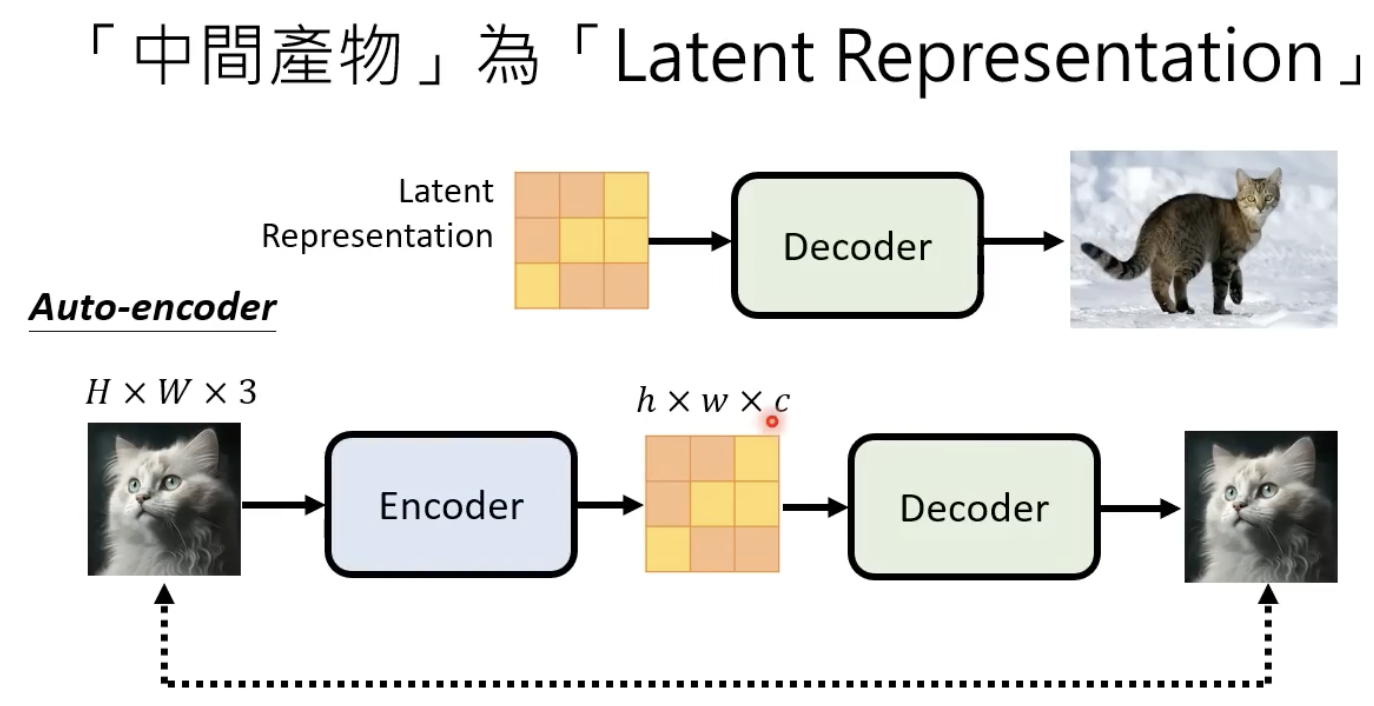
decoder的训练方法比较简单,中间一个缩小后的图片,然后用AE的训练方式即可。
generation model
generation model这里就类似扩散模型。
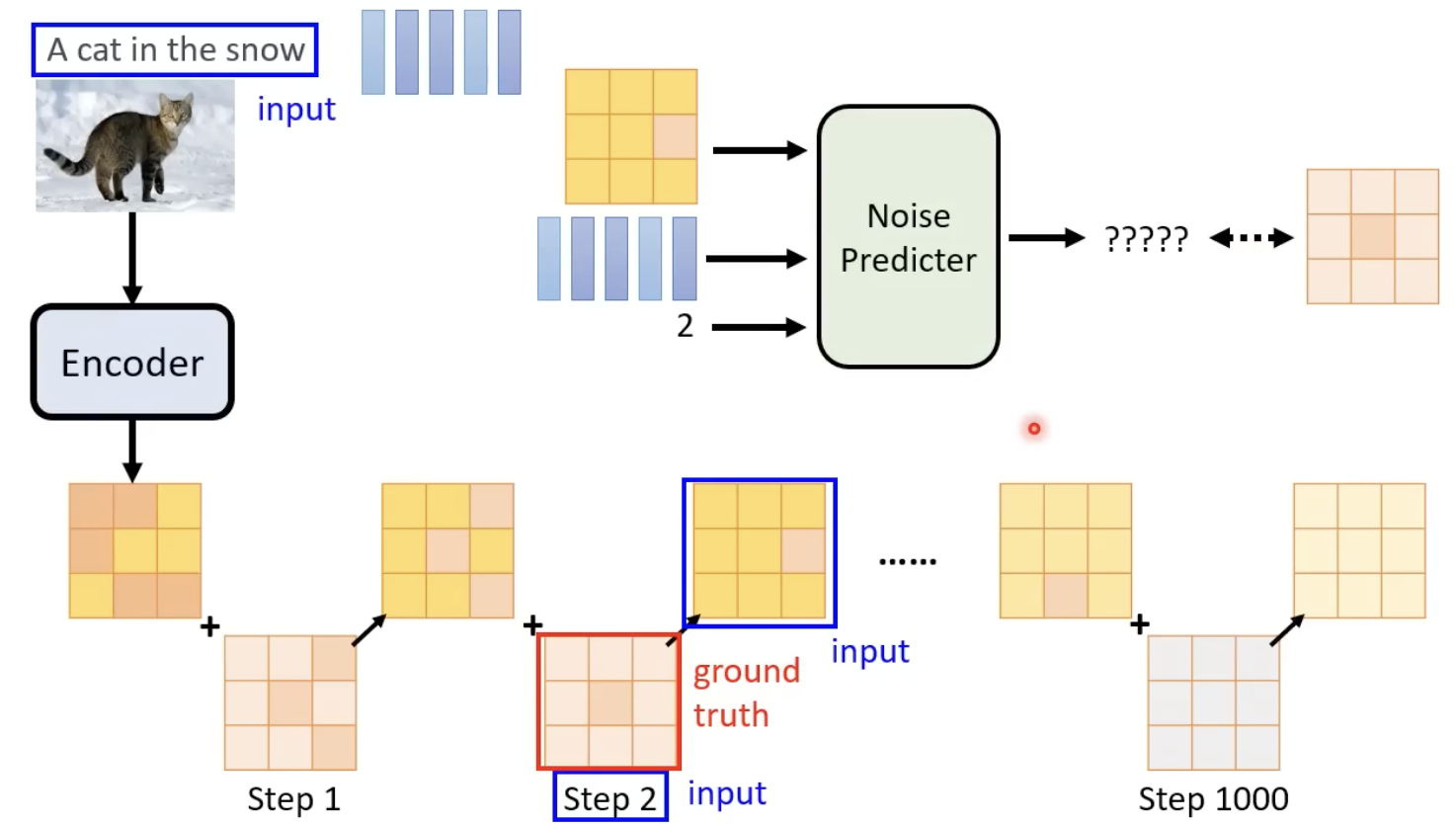
在每一个step中,noise predictor的输入是图像的representation、文字的represenation、当前step。输出得到该step添加的噪声。
经历若干个去噪步骤,再输入到decoder,基本就可以得到生成的大图了。
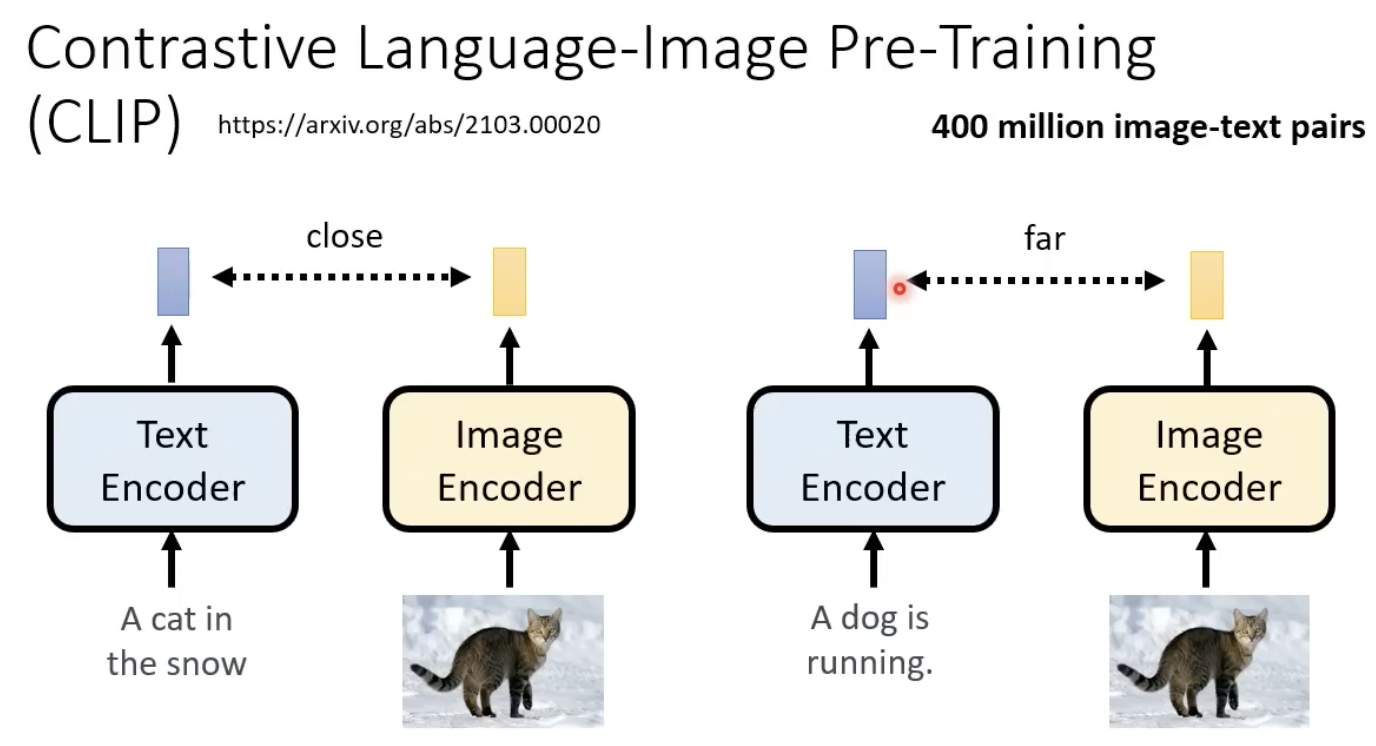
clip的原理
让两个encoder输出的向量相近:
FID指标:评估图像生成的好坏
依赖一个retrain好的CNN模型,输入一个生成的图片,得到representation,然后比较和真实影像的representation的进行比较:
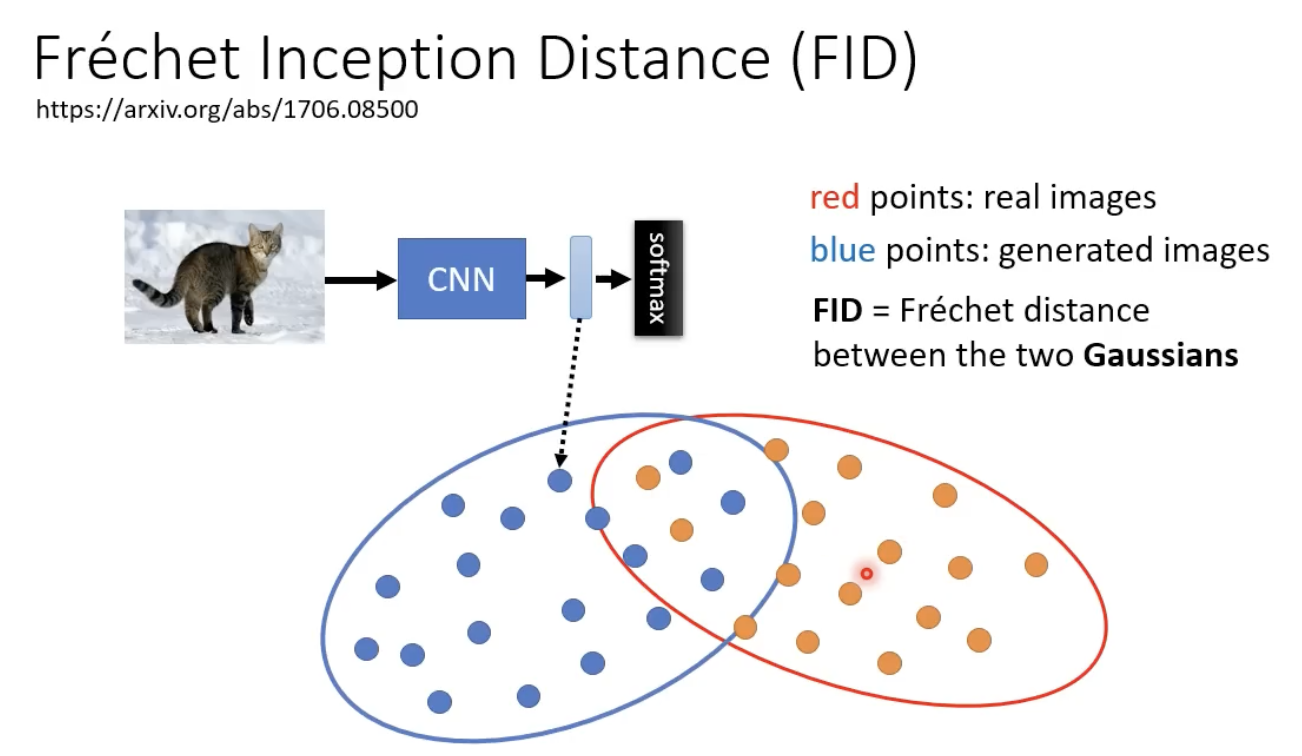
两个分布(假设是高斯分布)越接近越好。
数学原理
先区分下VAE和扩散模型的区别:
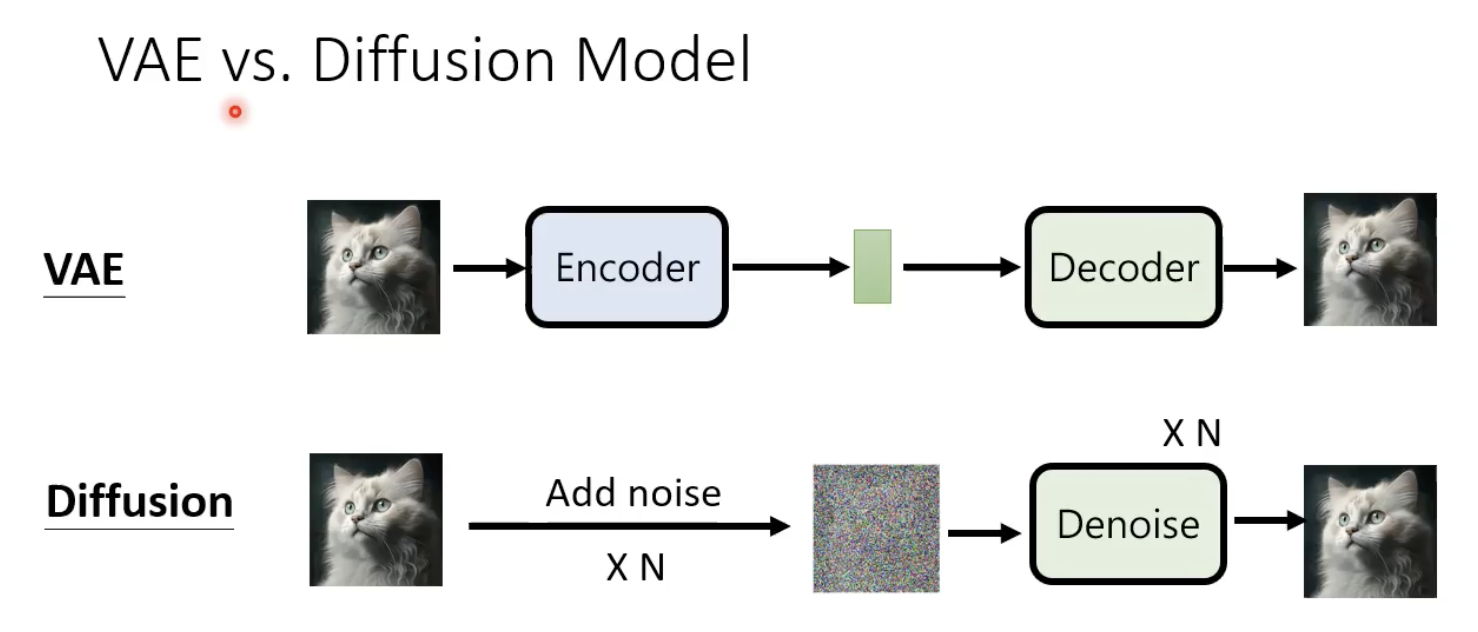
扩散模型加噪的过程中,不需要训练一个encoder。
算法如下:

training
先来看看第一个算法是什么意思,红色框框做的是把原始图像和噪声进行加权相加,
α
t
ˉ
\bar{\alpha_{t}}
αtˉ 越小代表加的的噪声越大,t越大,和原图相比的噪声越大。noise predictor所需要的输入是添加了噪声的图片(红色框框里面的内容)和step t,并且
α
t
ˉ
\bar{\alpha_{t}}
αtˉ 随着t的增大时越来也小的。注意这里是对 noise predictor (即
ϵ
θ
(
a
,
b
)
\epsilon_{\theta}(a,b)
ϵθ(a,b))做优化,让其根据两个输入,得到一个指定的噪声作为输出。

具体的训练流程如下图,给定一个添加噪声后的图,noise predictor 需要预测添加了那些噪声:
配合前面讲的理解
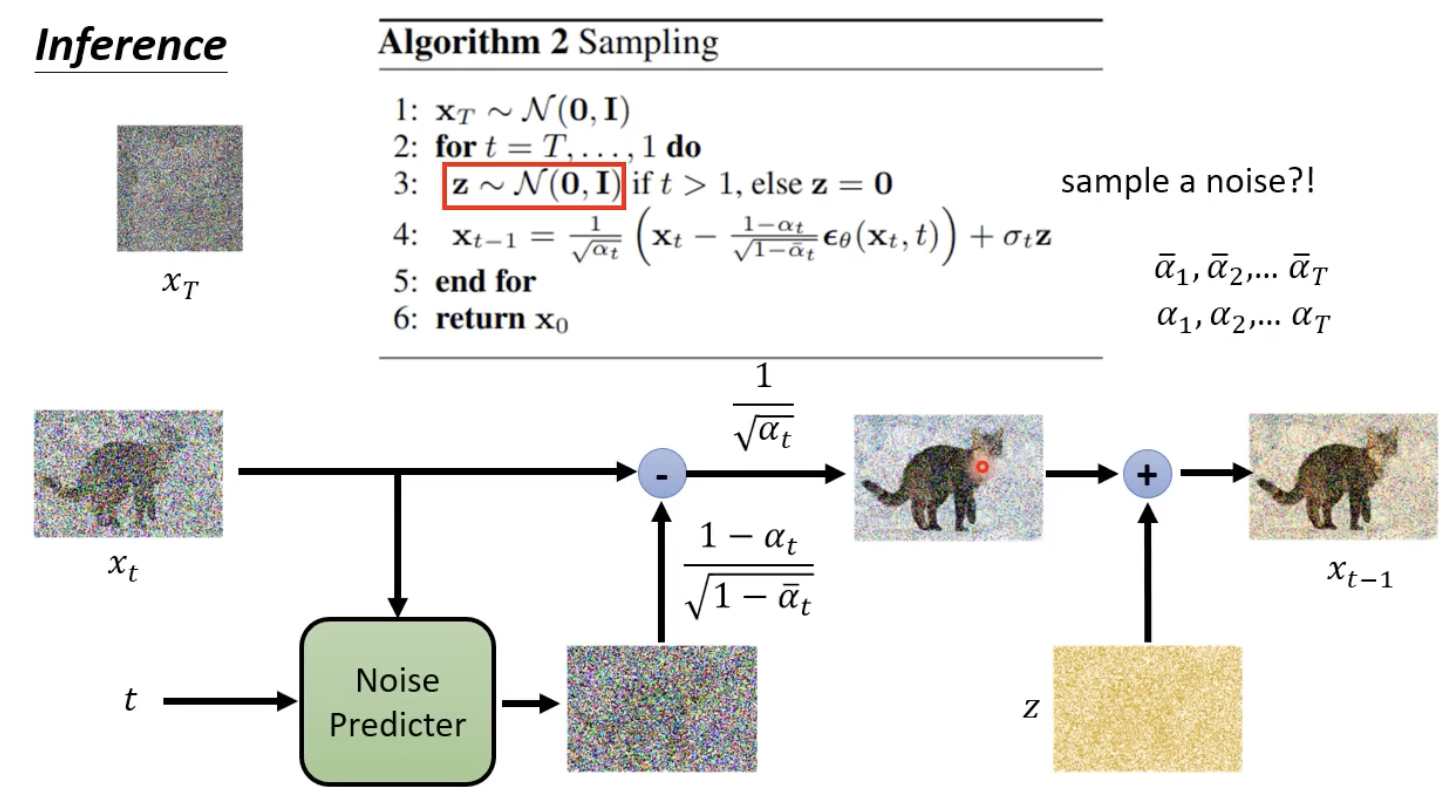
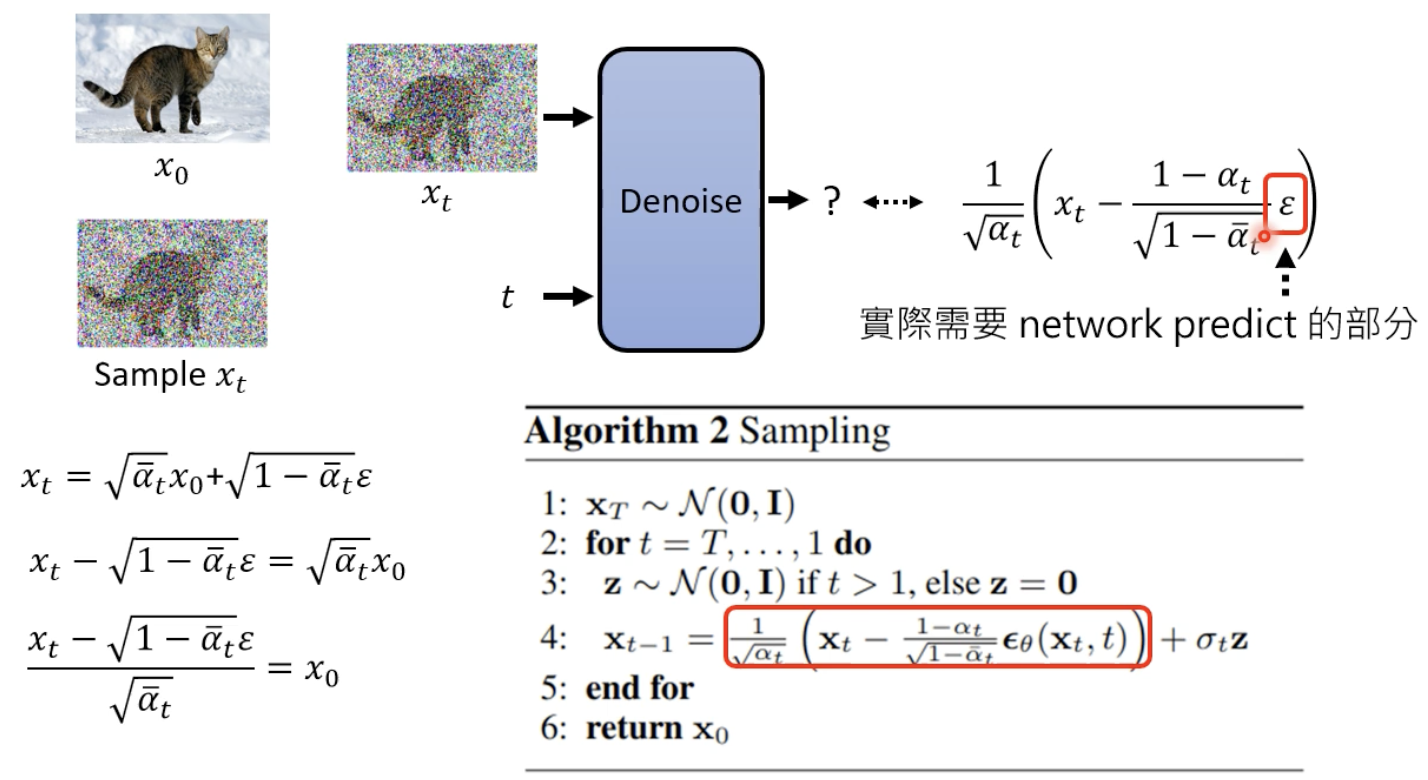
inference
流程如下,注意区分
α
t
ˉ
\bar{\alpha_{t}}
αtˉ 和
α
t
\alpha_{t}
αt 的区别,后者是新出现的一个变量:
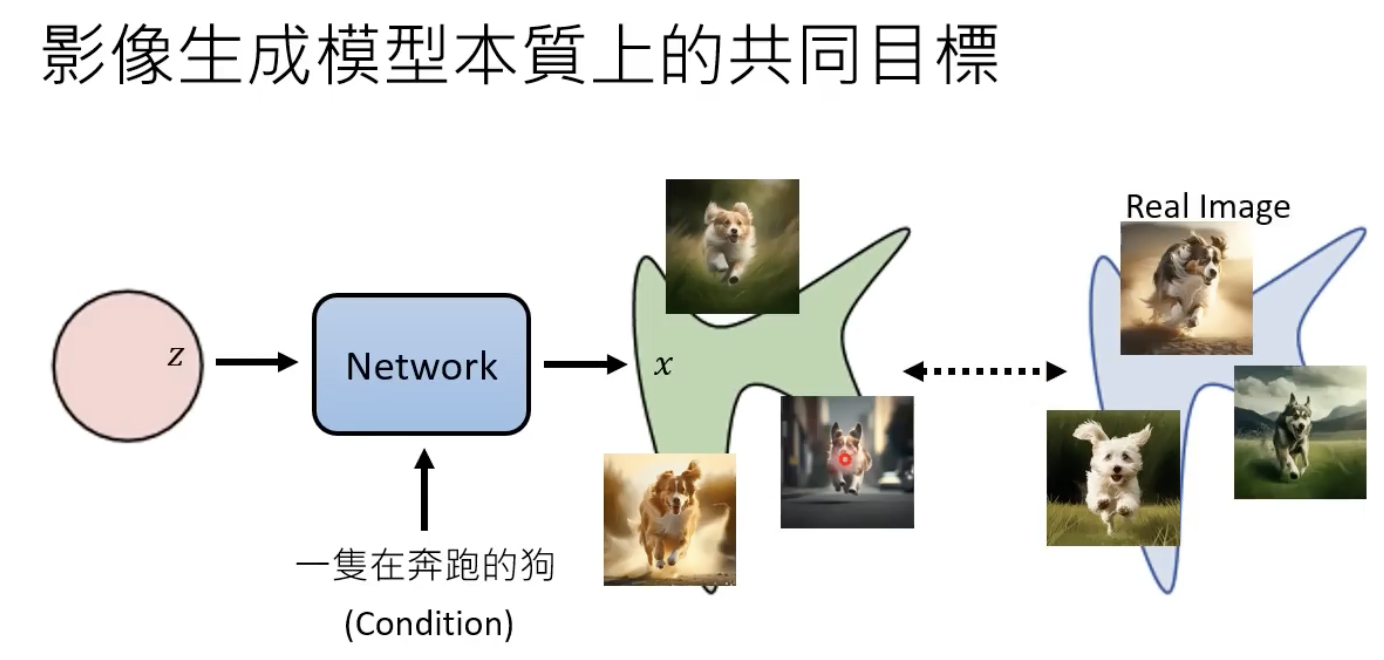
图像生成模型的本质
凭空生成
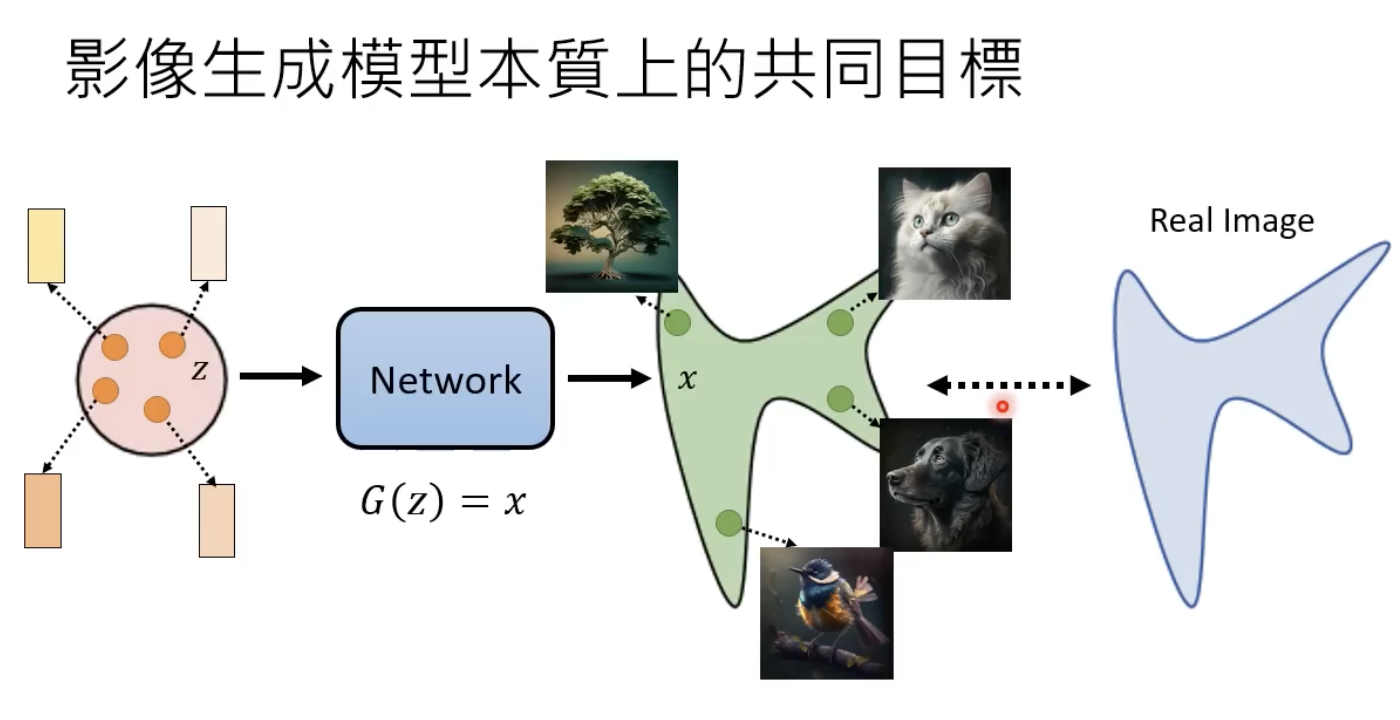
文字生成图片
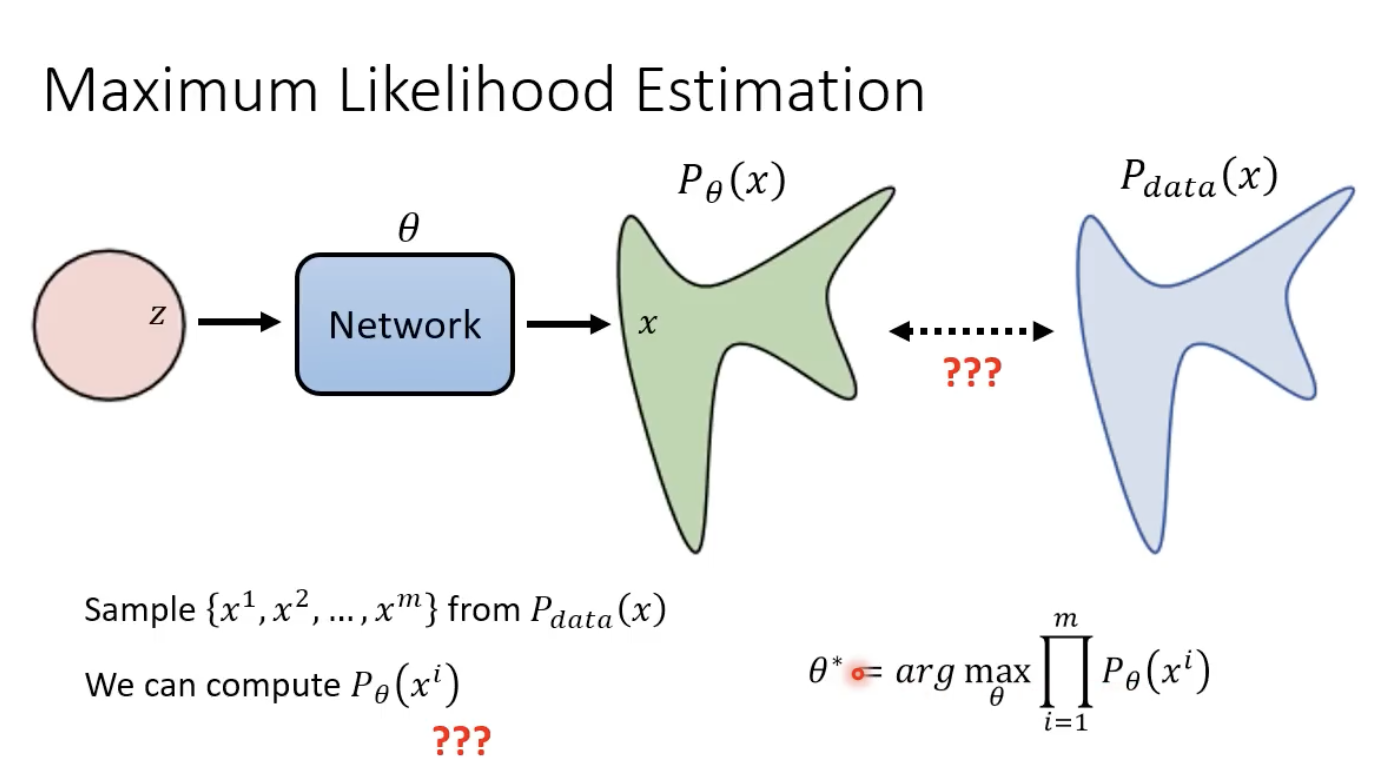
最大似然估计
x
i
x^i
xi为模型生成样本空间的一张图,
P
θ
(
x
i
)
P_{\theta}(x^i)
Pθ(xi)指的是模型生成
x
i
x^i
xi 的几率。最大似然估计就是要找到最优的
θ
∗
\theta^*
θ∗,使得模型输出的空间分布
P
θ
(
x
)
P_{\theta}(x)
Pθ(x) 能够和 真实数据(也就是训练数据)的分布
P
d
a
t
a
(
x
)
P_{data}(x)
Pdata(x)最接近:
 具体的计算方式如下:
具体的计算方式如下:
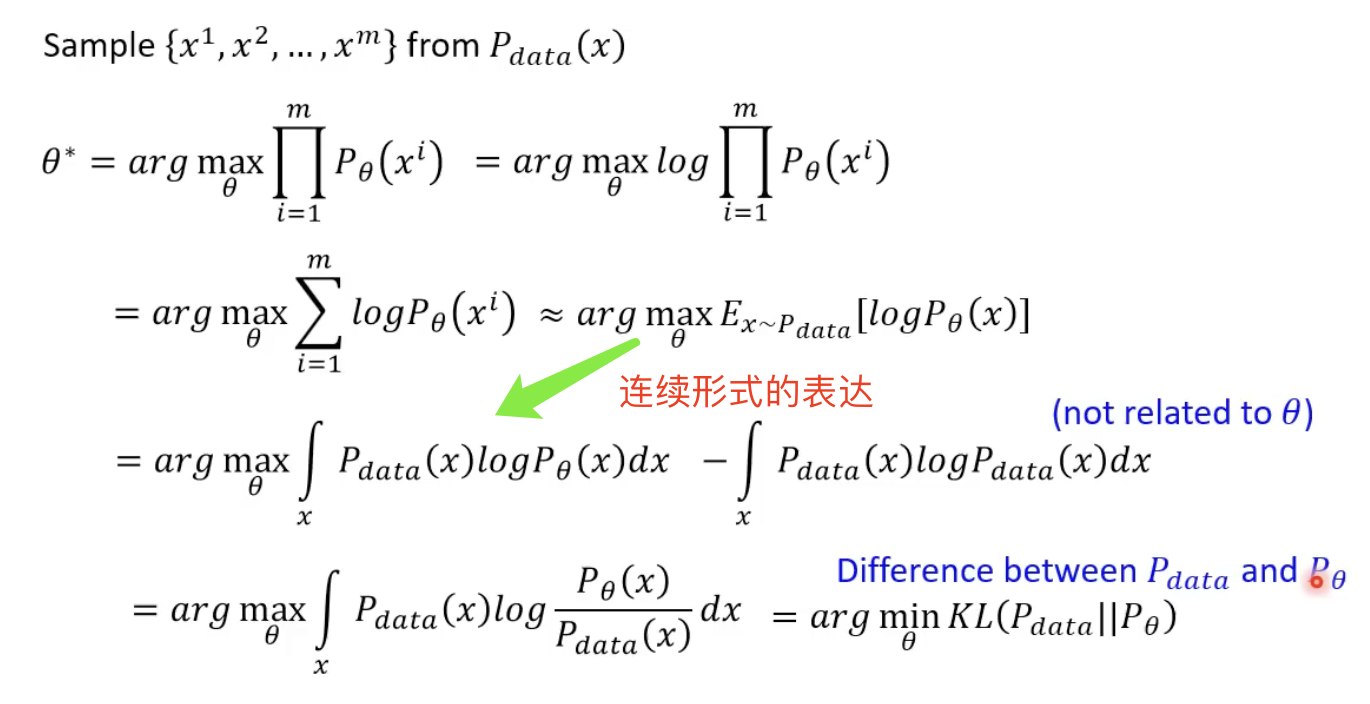
VAE中的推导:
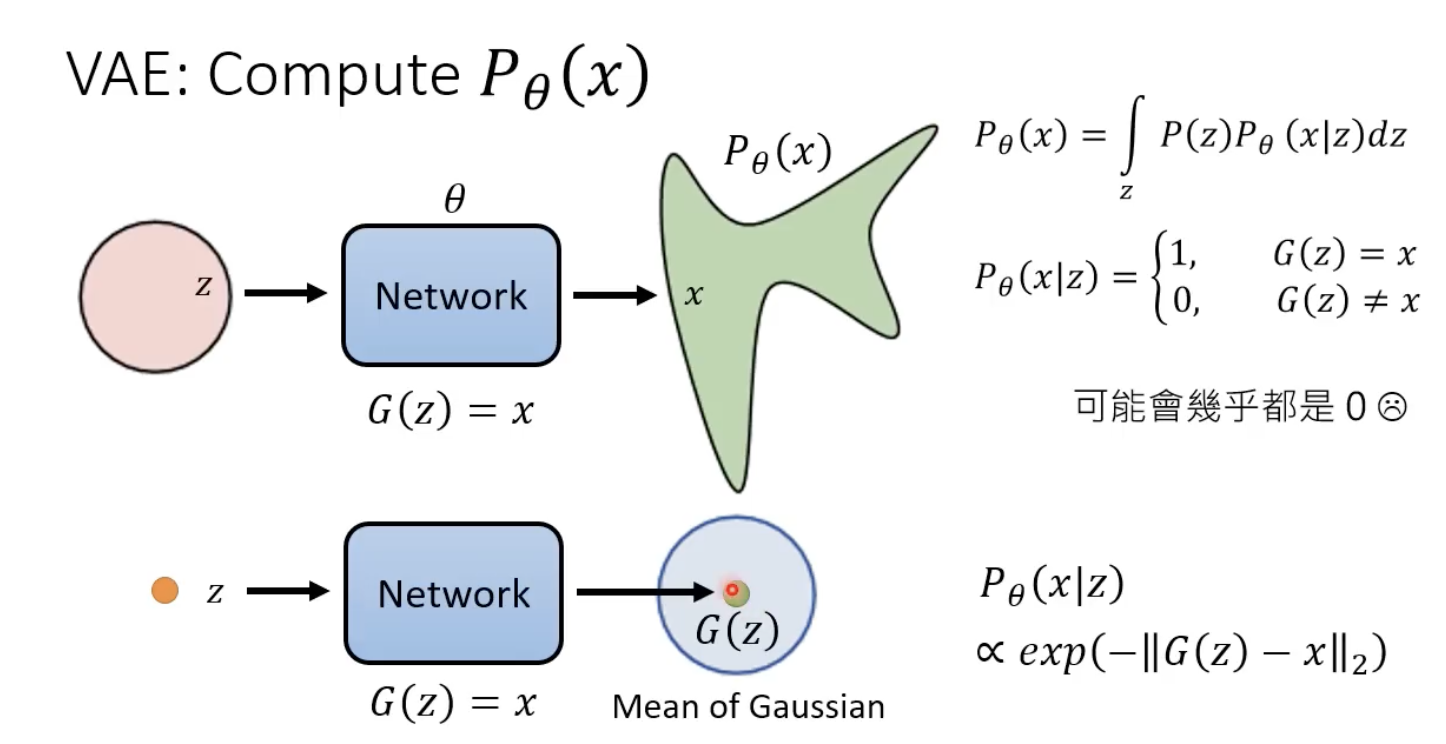
拓展到扩散模型:
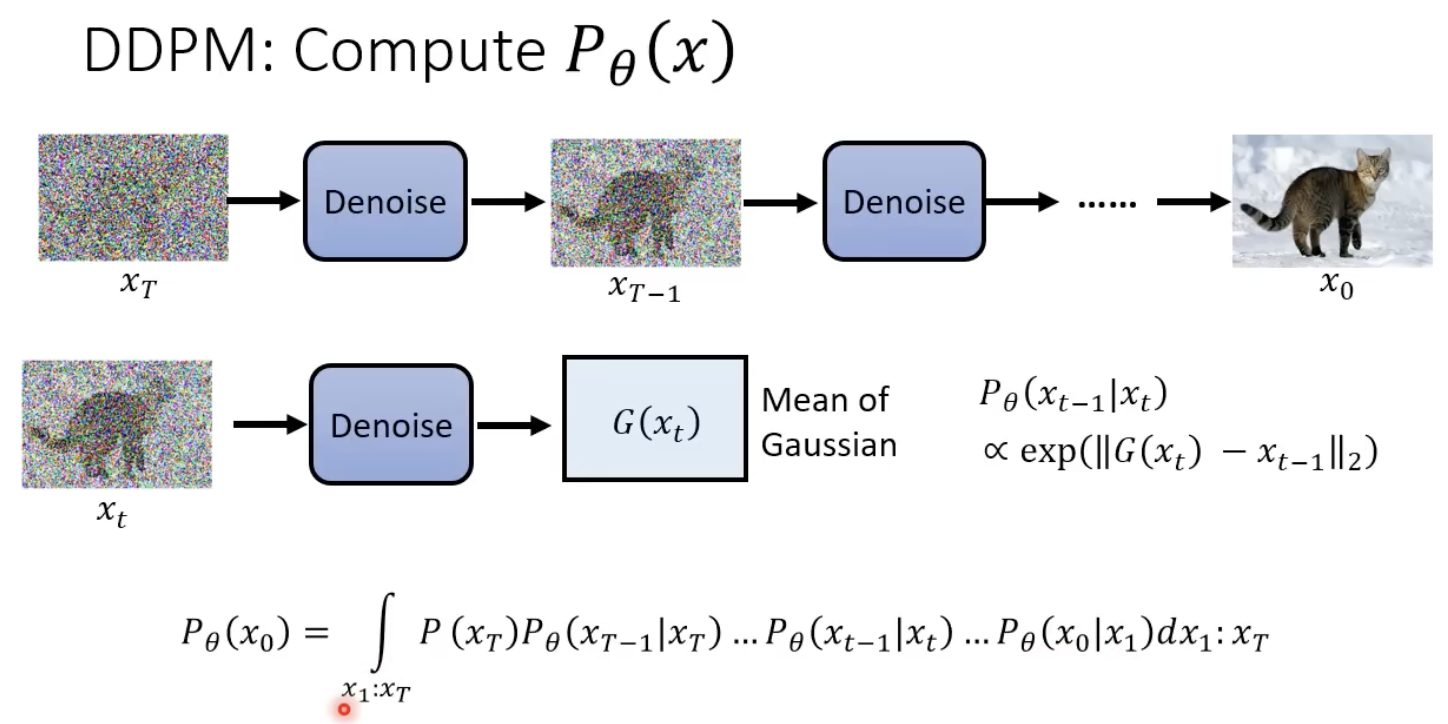

正式推导
参数 β \beta β,和前面 α \alpha α 相关的表达式有所不同:

先看一下展开是咋样的:
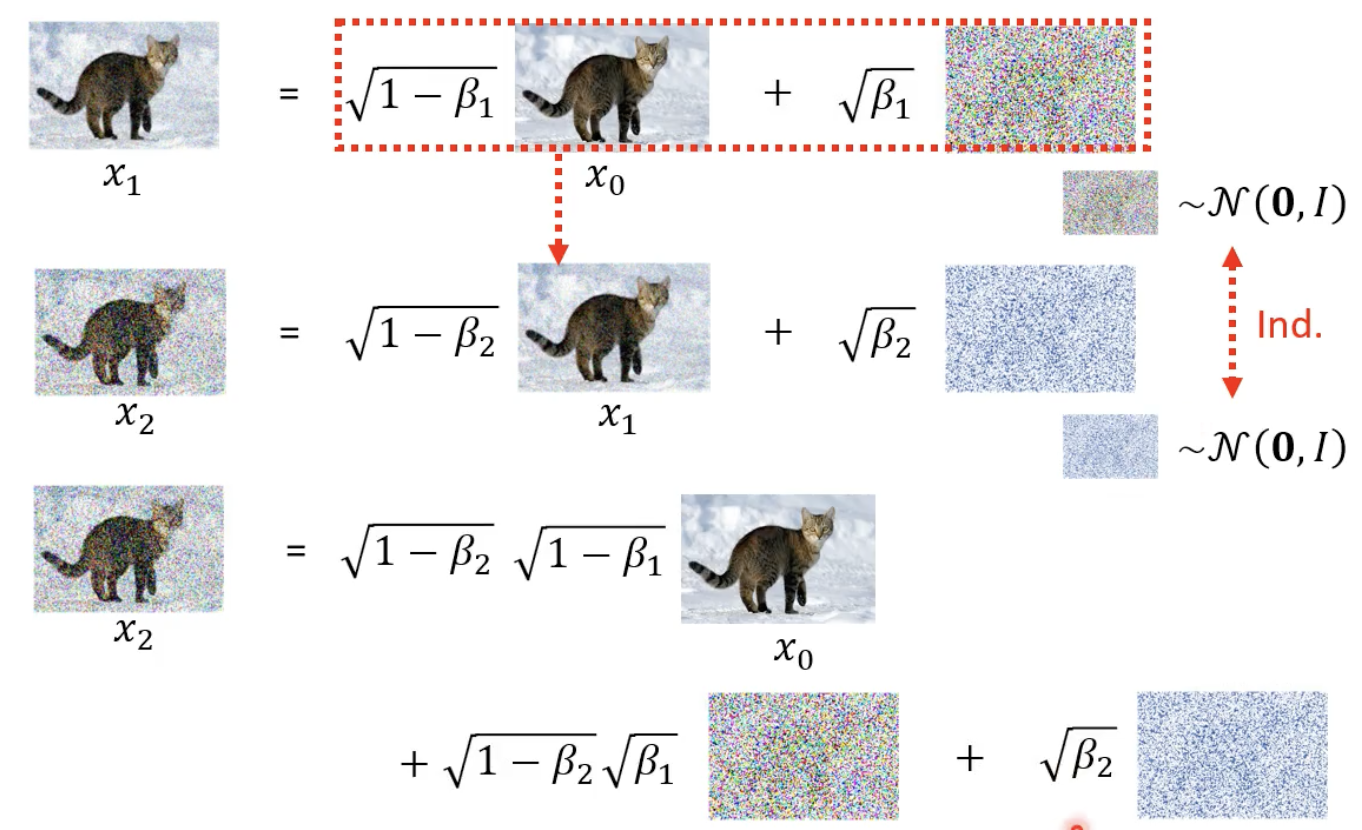
两个高斯噪声可以这样化简(别问原因):

以此类推,并使用 α \alpha α 来替换 β \beta β :

所以说做一次sample就可以得到
x
T
x_{T}
xT 了,不需要经过多个 step 得到,这样可以用来减少 sample 的时间。
总之,前面提到的优化目标可以这样化简:
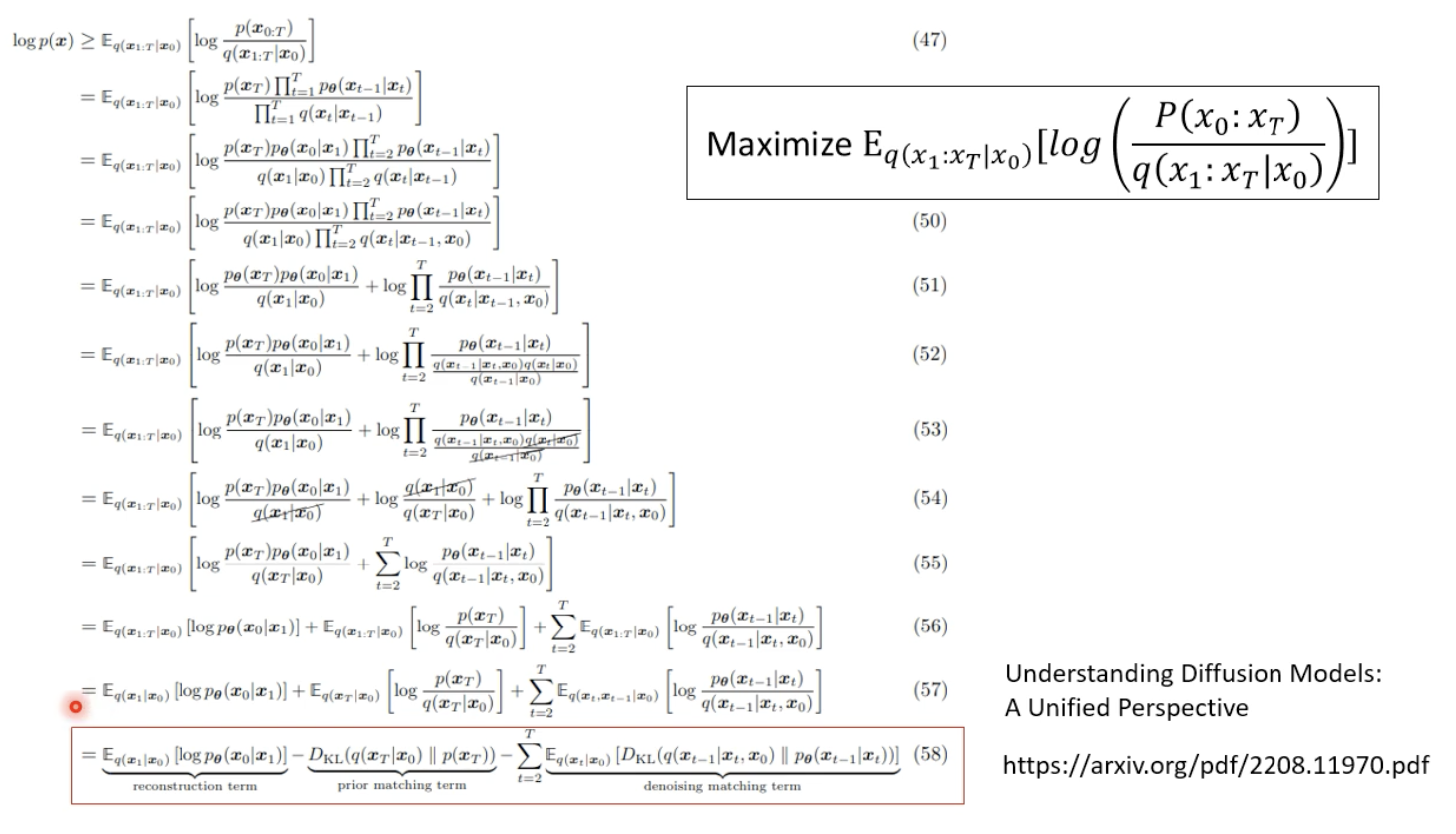
经过一些列化简后。。。。,得到如下公式,其他变量(
α
\alpha
α 是根据提前制定的schedule决定的)都是已知的除了
ϵ
\epsilon
ϵ ,所以noise predictor 只需要求这个变量就行了。
sample 带来随机性
由于 扩散模型是从 随机噪声中采样,然后经过一步步降噪生成的,所以怎么sample都影响模型最后的输出,这样就具有随机性,以往我们认为取输出概率最大的比较好,就像下图这样:
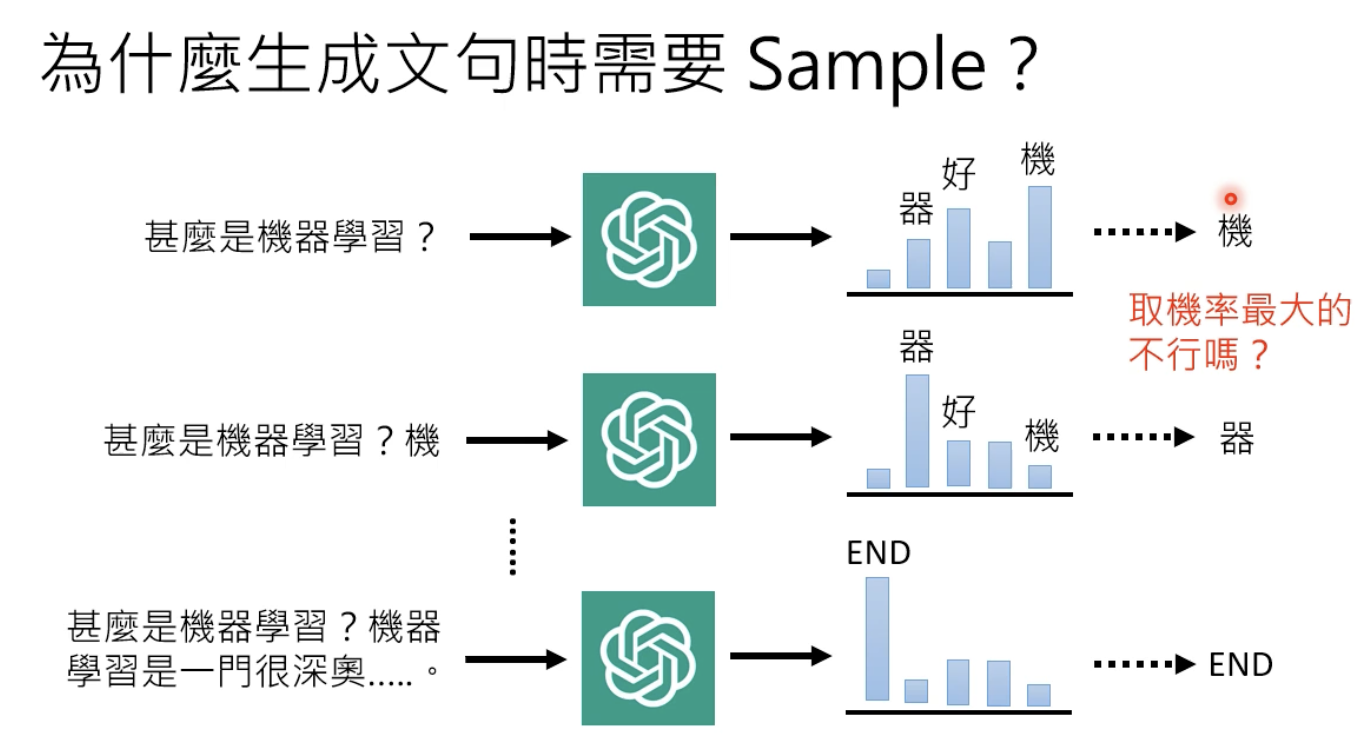
但是后来研究发现,这样做容易跳帧,因为人写的文章,写的时候也不是考虑几率最大的那个词汇,所以采用sample这样的随机性生成会有更好的效果。
从一次到位到N次到位
所以在每一步加一点随机性,效果会更好: