目录
- 1.Redis缓存和MySQL数据一致性如何保证?
- 2.你使用缓存,在高并发的情况下,如果多个缓存同时过期了怎么办?
- 3.消息队列积压了怎么办?
- 4.jdk1.8之后Java内存模型分别哪几个部分?每个部分用一句话概括一下?
- 5.哪几个部分是线程私有的?哪几个是线程共有的?
- 6.哪些部分会造成OOM问题?
- 7.讲一下Java异常的体系结构?
- 8.项目中有自定义异常吗?
- 9.线程调用start()之后再次调用start()会抛异常还是没反应吗?
- 10.说一下TCP三次握手?
- 11.线程和进程的区别?
- 12.常用的进程的通信方式有哪些?
1.Redis缓存和MySQL数据一致性如何保证?
如果不熟悉可以看这篇
深入理解redis_缓存双写一致性之更新策略探讨
考点:redis和数据库双写一致性问题
跟着这三点去答
先更新数据库,再更新缓存
先删除缓存,再更新数据库
先更新数据库,再删除缓存
先更新数据库,再更新缓存
- 先更新mysql的某商品的库存,当前商品的库存是100,更新为99个。
先更新mysql修改为99成功,然后更新redis。
此时假设异常出现,更新redis失败了,这导致mysql里面的库存是99而redis里面的还是100 。
上述发生,会让数据库里面和缓存redis里面数据不一致,读到脏数据 - 举个例子:如果数据库1小时内更新了1000次,那么缓存也要更新1000次,但是这个缓存可能在1小时内只被读取了1次,那么这1000次的更新有必要吗?
反过来,如果是删除的话,就算数据库更新了1000次,那么也只是做了1次缓存删除,只有当缓存真正被读取的时候才去数据库加载。
先删除缓存,再更新数据库
如果数据库更新失败,导致B线程请求再次访问缓存时,发现redis里面没数据,缓存缺失,再去读取mysql时,从数据库中读取到旧值
解决方式:采用延时双删策略
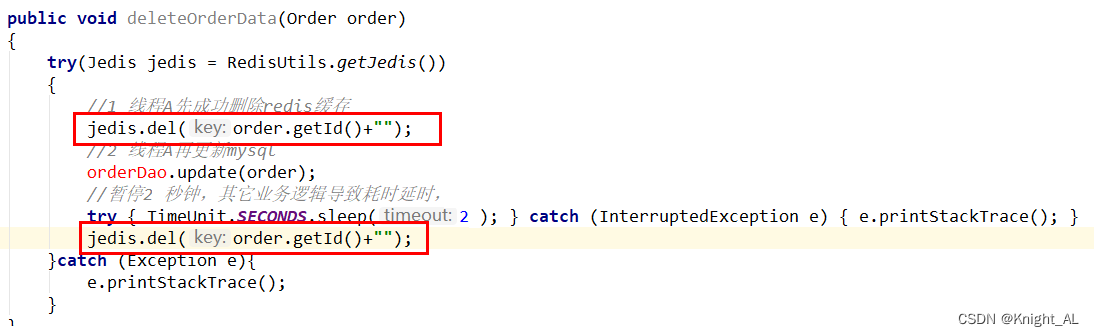

先更新数据库,再删除缓存
假如缓存删除失败或者来不及,导致请求再次访问redis时缓存命中,读取到的是缓存旧值。
解决方案:canal
方案2和方案3用那个?
个人建议是,优先使用先更新数据库,再删除缓存的方案。理由如下:
1 先删除缓存值再更新数据库,有可能导致请求因缓存缺失而访问数据库,给数据库带来压力,严重导致打满mysql。
2 如果业务应用中读取数据库和写缓存的时间不好估算,那么,延迟双删中的等待时间就不好设置。
2.你使用缓存,在高并发的情况下,如果多个缓存同时过期了怎么办?
大量的请求同时查询一个 key 时,此时这个key正好失效了,就会导致大量的请求都打到数据库上面去
简单说就是热点key突然失效了,暴打mysql

方案1:对于访问频繁的热点key,干脆就不设置过期时间
互斥独占锁防止击穿
方案2:互斥独占锁防止击穿
多个线程同时去查询数据库的这条数据,那么我们可以在第一个查询数据的请求上使用一个 互斥锁来锁住它。
其他的线程走到这一步拿不到锁就等着,等第一个线程查询到了数据,然后做缓存。后面的线程进来发现已经有缓存了,就直接走缓存。
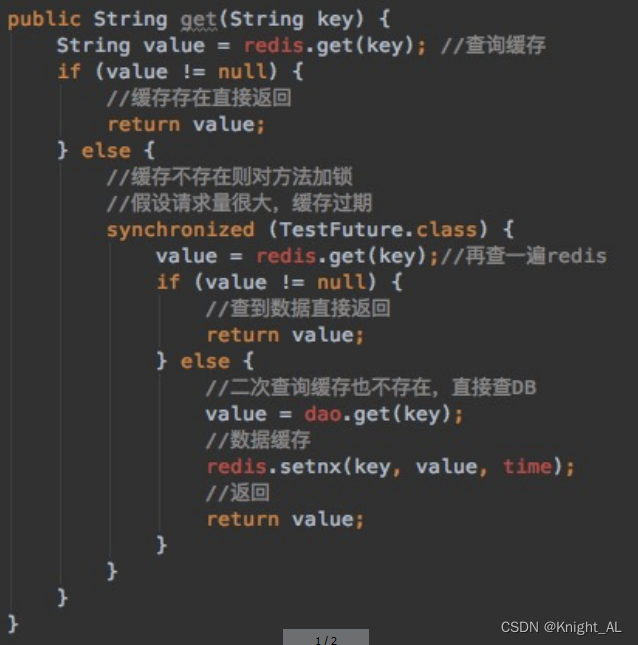
方案3:定时轮询,互斥更新,差异失效时间
举一个案例例子
QPS上1000后导致可怕的缓存击穿
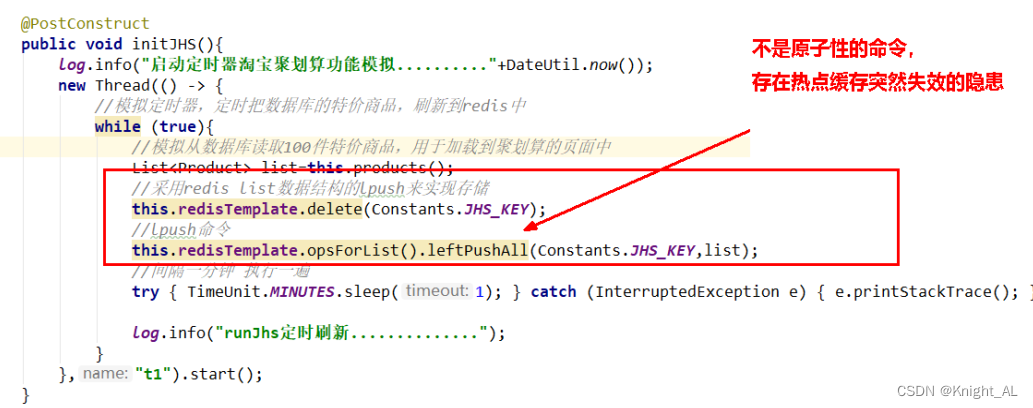
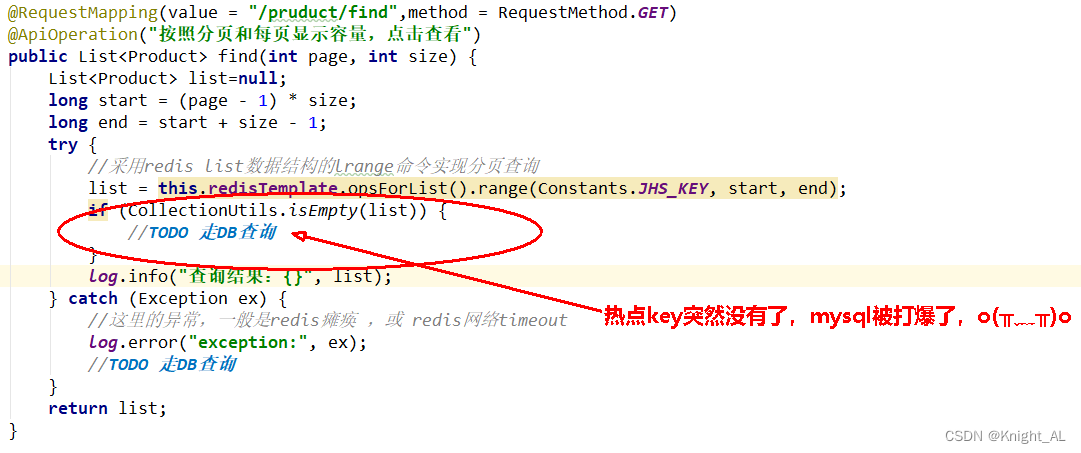
解决方法
定时轮询,互斥更新,差异失效时间

相当于B穿了一件防弹衣
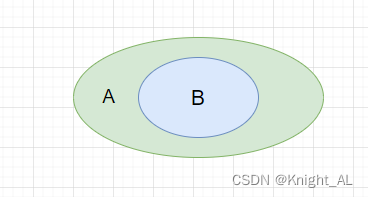
我们先缓存B,然后在缓存A,设置B的过期时间要比A的长

我们先查询A,如果A为空,我们再查询B

3.消息队列积压了怎么办?
当 RabbitMQ 消息队列积压时,可以采取以下措施:
-
增加消费者:增加消费者可以加快消息的消费速度从而减少队列中的积情况。
-
增加队列容量:增加队列容量可以使队列能够存储更多的消息,从而减少消息被丢弃的情况。
-
优化消费者代码:优化消费者代码可以使消费者快地处理消息,从而减少队列中的压情况。
-
优化生产者代码:优化生产者代码可以使生产更快地发送消息,从而减少队列中的积压情况。
-
使用 TTL:使用 TTL(Time To Live)可以设置消息的过期时间,从而减少队列中的积压情况。
-
使用死信队列:使用信队列可以将无法被消费的消息转移到另一个队列中,从而减少队列中的积压情况。
4.jdk1.8之后Java内存模型分别哪几个部分?每个部分用一句话概括一下?
在 JDK1.8 之后,Java 内存模型分为以下几个部分:
-
堆:用于存储对象实例,是 Java 程序中最大的一块存区域。
-
虚拟机栈:用于存储方法调用时的局部变量、方法参数和返回值等数据,是线程私有的。
-
方法区:用于存储类的信息、常量、静态变量、即时编译器编译后的代码等数据,是线程共享的。
-
本地方法栈:与虚拟机栈类似,不过只能执行native修饰的方法。
-
程序计数器:用于记录线程执行的位置,是线程私有的。
5.哪几个部分是线程私有的?哪几个是线程共有的?
共有:堆,方法区
私有:栈,本地方法栈,虚拟机栈
6.哪些部分会造成OOM问题?
除了程序计数器不会发生OOM,其他都要发生OOM
堆内存
如果在堆中没有内存完成对象实例的分配,并且堆无法再扩展时,将抛出OutOfMemoryError异常,抛出的错误信息是“java.lang.OutOfMemoryError:Java heap space”。
当前主流的JVM可以通过-Xmx和-Xms来控制堆内存的大小,发生堆上OOM的可能是存在内存泄露,也可能是堆大小分配不合理。
虚拟机栈和本地方法栈
这两个区域的区别不过是虚拟机栈为虚拟机执行Java方法服务,而本地方法栈则为虚拟机使用到的Native方法服务,在内存分配异常上是相同的。
在JVM规范中,对Java虚拟机栈规定了两种异常:
a. 如果线程请求的栈大于所分配的栈大小,则抛出StackOverFlowError错误,比如进行了一个不会停止的递归调用;
b. 如果虚拟机栈是可以动态拓展的,拓展时无法申请到足够的内存,则抛出OutOfMemoryError错误。
方法区
方法区用于存储的信息、常量、静态变量、即时编译器编译后的代码等数据。如果程序中使用了大量的类或者字符串常量,就会导致方法区溢出。
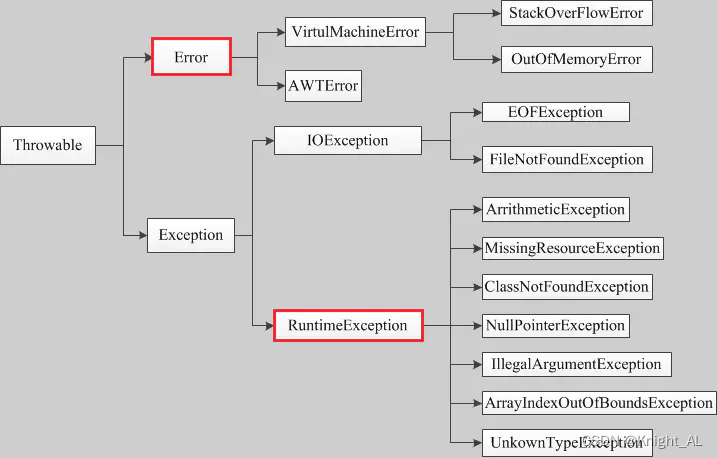
7.讲一下Java异常的体系结构?
8.项目中有自定义异常吗?
在service_utils中创建com.donglin.yygh.common.handler包,建统一异常处理类GlobalExceptionHandler.java:
import com.donglin.yygh.common.result.R;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.web.bind.annotation.RestControllerAdvice;
//凡是由@ControllerAdvice 标记的类都表示全局异常类
@RestControllerAdvice //@ControllerAdvice+@RequestBody=@RestControllerAdvice
public class GlobalExceptionHandler {
@ExceptionHandler(value = Exception.class) //粒度有点大
public R handleException(Exception ex){
ex.printStackTrace();
return R.error().message(ex.getMessage());
}
}
JAVA异常getMessage(),printStackTrace()方法的区别https://donglin.blog.csdn.net/article/details/125471865
添加异常处理方法
GlobalExceptionHandler.java中添加
@ExceptionHandler(value = SQLException.class)
public R handleException(SQLException ex){
ex.printStackTrace();
return R.error().message("Sql异常");
}
@ExceptionHandler(value = ArithmeticException.class)
public R handleException(ArithmeticException ex){
ex.printStackTrace();
return R.error().message("数学异常");
}
9.线程调用start()之后再次调用start()会抛异常还是没反应吗?
抛出异常
如果不熟悉可以看这篇
Thread启动线程的start方法能执行多次吗?
start()方法源码:
public synchronized void start() {
// 如果线程不是"NEW状态",则抛出异常!
if (threadStatus != 0)
throw new IllegalThreadStateException();
// 将线程添加到ThreadGroup中
group.add(this);
boolean started = false;
try {
// 通过start0()启动线程,新线程会调用run()方法
start0();
// 设置started标记=true
started = true;
} finally {
try {
if (!started) {
group.threadStartFailed(this);
}
} catch (Throwable ignore) {
}
}
}
run方法源码:
public void run() {
if (target != null) {
target.run();
}
}
10.说一下TCP三次握手?
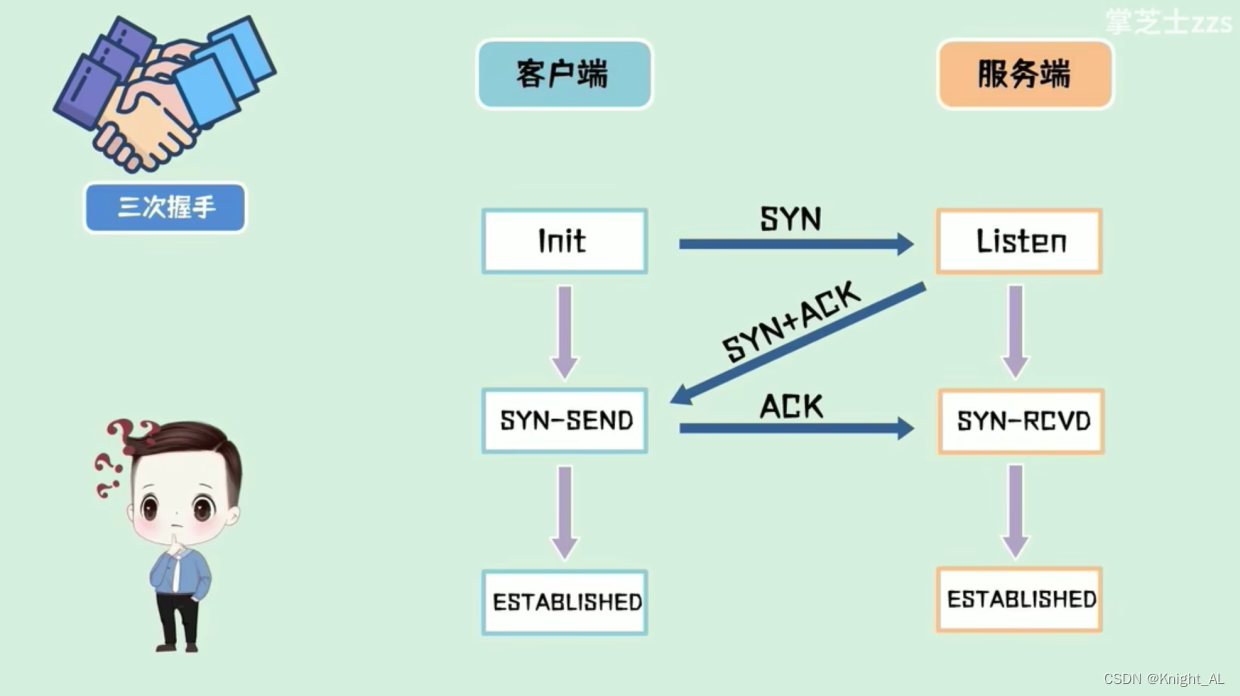
三次握手是建立连接的过程,当客户端向服务端发起连接时,会先发一包连接请求数据,过去询问一下,能否与你建立连接,这包数据我们称之为SYN包。如果对端同意连接,则回复一包SYN+ACK包,客户端收到之后回复一包ACK包连接建立。
因为这个过程中互相发送了三包数据,所以称之为三次握手。
Q:为什么要三次握手,而不是两次握手,服务端回复完SYN+ACK包之后就建立连接
A:这是为了防止因为已失效的请求报文突然又传到服务器引起错误。解决网络信道不可靠的问题
如果没有第三次握手告诉服务器端客户端收的到服务器端传输的数据的话,服务器端是不知道客户端有没有接收到服务器端返回的信息的。服务端就认为这个连接是可用的,端口就一直开着,等到客户端因超时重新发出请求时,服务器就会重新开启一个端口连接。
这样一来,就会有很多无效的连接端口白白地开着,导致资源的浪费。
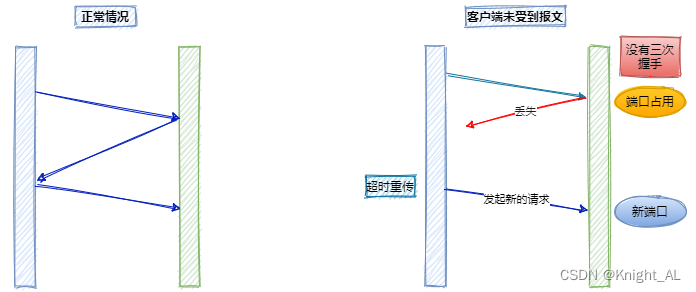
还有一种情况是已经失效的客户端发出的请求信息,由于某种原因传输到了服务器端,服务器端以为是客户端发出的有效请求,接收后产生错误。
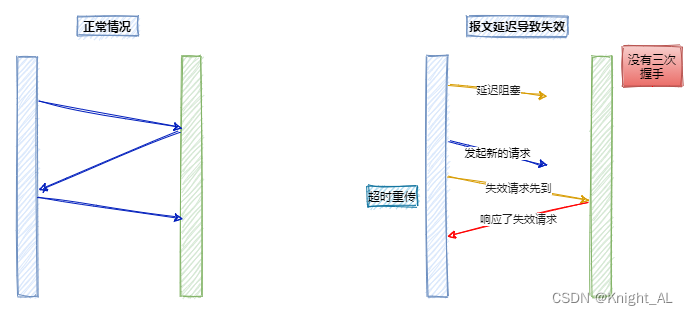
Q:为什么不是四次握手?
A:因为通信不可能100%可靠,而上面的三次握手已经做好了通信的准备工作,再四次握手,并不能显著提高可靠性,而且也没有必要。
11.线程和进程的区别?
进程
是一个具有一定独立功能的程序关于某个数据集合的一次运行活动,是系统进行『资源分配和调度』的一个独立单位。
线程
进行运算调度的最小单位,其实是进程中的一个执行任务(控制单元),负责当前进程中程序的执行
两者之间的区别
- 「本质区别」:进程是操作系统资源分配的基本单位,而线程是任务调度和执行的基本单位
- 「在开销方面」:每个进程都有独立的代码和数据空间(程序上下文),程序之间的切换会有较大的开销;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开销小
- 「所处环境」:在操作系统中能同时运行多个进程(程序);而在同一个进程(程序)中有多个线程同时执行(通过CPU调度,在每个时间片中只有一个线程执行)
- 「内存分配方面」:系统在运行的时候会为每个进程分配不同的内存空间;而对线程而言,除了CPU外,系统不会为线程分配内存(线程所使用的资源来自其所属进程的资源),线程组之间只能共享资源
- 「包含关系」:没有线程的进程可以看做是单线程的,如果一个进程内有多个线程,则执行过程不是一条线的,而是多条线(线程)共同完成的;线程是进程的一部分,所以线程也被称为轻权进程或者轻量级进程
12.常用的进程的通信方式有哪些?
如果不熟悉可以看这篇
进程的通信方式有哪些?
- 管道
- 消息队列
- 共享内存
- 信号量
- 信号
- 套接字