POI报表的高级应用
掌握基于模板打印的POI报表导出理解自定义工具类的执行流程
熟练使用SXSSFWorkbook完成百万数据报表打印理解基于事件驱动的POI报表导入
模板打印
概述
自定义生成Excel报表文件还是有很多不尽如意的地方,特别是针对复杂报表头,单元格样式,字体等操作。手写这些代码不仅费时费力,有时候效果还不太理想。那怎么样才能更方便的对报表样式,报表头进行处理呢?答案是 使用已经准备好的Excel模板,只需要关注模板中的数据即可。
模板打印的操作步骤
- 制作模版文件(模版文件的路径)
- 导入(加载)模版文件,从而得到一个工作簿
- 读取工作表
- 读取行
- 读取单元格
- 读取单元格样式
- 设置单元格内容
- 其他单元格就可以使用读到的样式了
代码实现
/**
* 采用模板打印的形式完成报表生成
* 模板
* 参数:
* 年月-月(2018-02%)
*
* sxssf对象不支持模板打印
*/
@RequestMapping(value = "/export/{month}", method = RequestMethod.GET)
public void export(@PathVariable String month) throws Exception {
//1.获取报表数据
List<EmployeeReportResult> list = userCompanyPersonalService.findByReport(companyId,month);
//2.加载模板
Resource resource = new ClassPathResource("excel-template/hr-demo.xlsx");
FileInputStream fis = new FileInputStream(resource.getFile());
//3.通过工具类完成下载
// new ExcelExportUtil(EmployeeReportResult.class,2,2).
// export(response,fis,list,month+"人事报表.xlsx");
//3.根据模板创建工作簿
Workbook wb = new XSSFWorkbook(fis);
//4.读取工作表
Sheet sheet = wb.getSheetAt(0);
//5.抽取公共样式
Row row = sheet.getRow(2);
CellStyle styles [] = new CellStyle[row.getLastCellNum()];
for(int i=0;i<row.getLastCellNum();i++) {
Cell cell = row.getCell(i);
styles[i] = cell.getCellStyle();
}
//6.构造单元格
int rowIndex = 2;
Cell cell=null;
for(int i=0;i<10000;i++) {
for (EmployeeReportResult employeeReportResult : list) {
row = sheet.createRow(rowIndex++);
// 编号,
cell = row.createCell(0);
cell.setCellValue(employeeReportResult.getUserId());
cell.setCellStyle(styles[0]);
// 姓名,
cell = row.createCell(1);
cell.setCellValue(employeeReportResult.getUsername());
cell.setCellStyle(styles[1]);
// 手机,
cell = row.createCell(2);
cell.setCellValue(employeeReportResult.getMobile());
cell.setCellStyle(styles[2]);
// 最高学历,
cell = row.createCell(3);
cell.setCellValue(employeeReportResult.getTheHighestDegreeOfEducation());
cell.setCellStyle(styles[3]);
// 国家地区,
cell = row.createCell(4);
cell.setCellValue(employeeReportResult.getNationalArea());
cell.setCellStyle(styles[4]);
// 护照号,
cell = row.createCell(5);
cell.setCellValue(employeeReportResult.getPassportNo());
cell.setCellStyle(styles[5]);
// 籍贯,
cell = row.createCell(6);
cell.setCellValue(employeeReportResult.getNativePlace());
cell.setCellStyle(styles[6]);
// 生日,
cell = row.createCell(7);
cell.setCellValue(employeeReportResult.getBirthday());
cell.setCellStyle(styles[7]);
// 属相,
cell = row.createCell(8);
cell.setCellValue(employeeReportResult.getZodiac());
cell.setCellStyle(styles[8]);
// 入职时间,
cell = row.createCell(9);
cell.setCellValue(employeeReportResult.getTimeOfEntry());
cell.setCellStyle(styles[9]);
// 离职类型,
cell = row.createCell(10);
cell.setCellValue(employeeReportResult.getTypeOfTurnover());
cell.setCellStyle(styles[10]);
// 离职原因,
cell = row.createCell(11);
cell.setCellValue(employeeReportResult.getReasonsForLeaving());
cell.setCellStyle(styles[11]);
// 离职时间
cell = row.createCell(12);
cell.setCellValue(employeeReportResult.getResignationTime());
cell.setCellStyle(styles[12]);
}
}
//7.下载
//3.完成下载
ByteArrayOutputStream os = new ByteArrayOutputStream();
wb.write(os);
new DownloadUtils().download(os,response,month+"人事报表.xlsx");
}骚戴理解:学会了一个小技巧,怎么获取模板数据?
Resource resource = new ClassPathResource("excel-template/hr-demo.xlsx");
FileInputStream fis = new FileInputStream(resource.getFile());
Workbook wb = new XSSFWorkbook(fis);同时这里的 for(int i=0;i<10000;i++) 其实是为了造数据,数据库本来查询到的数据有90多条,然后循环10000次自然就是90多万条,接近百万数据量
自定义工具类
自定义注解ExcelAttribute
package com.ihrm.domain.poi;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.FIELD)
public @interface ExcelAttribute {
/** 对应的列名称 */
String name() default "";
/** 列序号 */
int sort();
/** 字段类型对应的格式 */
String format() default "";
}
导出工具类
package com.ihrm.common.poi.utils;
import com.ihrm.domain.poi.ExcelAttribute;
import lombok.Getter;
import lombok.Setter;
import org.apache.poi.hssf.usermodel.*;
import org.apache.poi.poifs.filesystem.POIFSFileSystem;
import org.apache.poi.ss.formula.functions.T;
import org.apache.poi.ss.usermodel.*;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
import javax.servlet.http.HttpServletResponse;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.lang.reflect.Field;
import java.net.URLEncoder;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.concurrent.atomic.AtomicInteger;
@Getter
@Setter
public class ExcelExportUtil<T> {
private int rowIndex;
private int styleIndex;
private String templatePath;
private Class clazz;
private Field fields[];
public ExcelExportUtil(Class clazz,int rowIndex,int styleIndex) {
this.clazz = clazz;
this.rowIndex = rowIndex;
this.styleIndex = styleIndex;
fields = clazz.getDeclaredFields();
}
/**
* 基于注解导出
*/
public void export(HttpServletResponse response,InputStream is, List<T> objs,String fileName) throws Exception {
XSSFWorkbook workbook = new XSSFWorkbook(is);
Sheet sheet = workbook.getSheetAt(0);
CellStyle[] styles = getTemplateStyles(sheet.getRow(styleIndex));
AtomicInteger datasAi = new AtomicInteger(rowIndex);
for (T t : objs) {
Row row = sheet.createRow(datasAi.getAndIncrement());
for(int i=0;i<styles.length;i++) {
Cell cell = row.createCell(i);
cell.setCellStyle(styles[i]);
for (Field field : fields) {
if(field.isAnnotationPresent(ExcelAttribute.class)){
field.setAccessible(true);
ExcelAttribute ea = field.getAnnotation(ExcelAttribute.class);
if(i == ea.sort()) {
cell.setCellValue(field.get(t).toString());
}
}
}
}
}
fileName = URLEncoder.encode(fileName, "UTF-8");
response.setContentType("application/octet-stream");
response.setHeader("content-disposition", "attachment;filename=" + new String(fileName.getBytes("ISO8859-1")));
response.setHeader("filename", fileName);
workbook.write(response.getOutputStream());
}
public CellStyle[] getTemplateStyles(Row row) {
CellStyle [] styles = new CellStyle[row.getLastCellNum()];
for(int i=0;i<row.getLastCellNum();i++) {
styles[i] = row.getCell(i).getCellStyle();
}
return styles;
}
}
导入工具类
package com.ihrm.common.poi.utils;
import com.ihrm.domain.poi.ExcelAttribute;
import org.apache.poi.hssf.usermodel.*;
import org.apache.poi.poifs.filesystem.POIFSFileSystem;
import org.apache.poi.ss.format.CellFormat;
import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.DateUtil;
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.ss.usermodel.Sheet;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
import java.io.FileInputStream;
import java.io.InputStream;
import java.lang.reflect.Field;
import java.math.BigDecimal;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
public class ExcelImportUtil<T> {
private Class clazz;
private Field fields[];
public ExcelImportUtil(Class clazz) {
this.clazz = clazz;
fields = clazz.getDeclaredFields();
}
/**
* 基于注解读取excel
*/
public List<T> readExcel(InputStream is, int rowIndex,int cellIndex) {
List<T> list = new ArrayList<T>();
T entity = null;
try {
XSSFWorkbook workbook = new XSSFWorkbook(is);
Sheet sheet = workbook.getSheetAt(0);
// 不准确
int rowLength = sheet.getLastRowNum();
System.out.println(sheet.getLastRowNum());
for (int rowNum = rowIndex; rowNum <= sheet.getLastRowNum(); rowNum++) {
Row row = sheet.getRow(rowNum);
entity = (T) clazz.newInstance();
System.out.println(row.getLastCellNum());
for (int j = cellIndex; j < row.getLastCellNum(); j++) {
Cell cell = row.getCell(j);
for (Field field : fields) {
if(field.isAnnotationPresent(ExcelAttribute.class)){
field.setAccessible(true);
ExcelAttribute ea = field.getAnnotation(ExcelAttribute.class);
if(j == ea.sort()) {
field.set(entity, covertAttrType(field, cell));
}
}
}
}
list.add(entity);
}
} catch (Exception e) {
e.printStackTrace();
}
return list;
}
/**
* 类型转换 将cell 单元格格式转为 字段类型
*/
private Object covertAttrType(Field field, Cell cell) throws Exception {
String fieldType = field.getType().getSimpleName();
if ("String".equals(fieldType)) {
return getValue(cell);
}else if ("Date".equals(fieldType)) {
return new SimpleDateFormat("yyyy-MM-dd hh:mm:ss").parse(getValue(cell)) ;
}else if ("int".equals(fieldType) || "Integer".equals(fieldType)) {
return Integer.parseInt(getValue(cell));
}else if ("double".equals(fieldType) || "Double".equals(fieldType)) {
return Double.parseDouble(getValue(cell));
}else {
return null;
}
}
/**
* 格式转为String
* @param cell
* @return
*/
public String getValue(Cell cell) {
if (cell == null) {
return "";
}
switch (cell.getCellType()) {
case STRING:
return cell.getRichStringCellValue().getString().trim();
case NUMERIC:
if (DateUtil.isCellDateFormatted(cell)) {
Date dt = DateUtil.getJavaDate(cell.getNumericCellValue());
return new SimpleDateFormat("yyyy-MM-dd hh:mm:ss").format(dt);
} else {
// 防止数值变成科学计数法
String strCell = "";
Double num = cell.getNumericCellValue();
BigDecimal bd = new BigDecimal(num.toString());
if (bd != null) {
strCell = bd.toPlainString();
}
// 去除 浮点型 自动加的 .0
if (strCell.endsWith(".0")) {
strCell = strCell.substring(0, strCell.indexOf("."));
}
return strCell;
}
case BOOLEAN:
return String.valueOf(cell.getBooleanCellValue());
default:
return "";
}
}
}工具类完成导入导出
导入数据
给导入的User实体类上面加上自定义注解 @ExcelAttribute
package com.ihrm.domain.system;
import com.fasterxml.jackson.annotation.JsonIgnore;
import com.ihrm.domain.poi.ExcelAttribute;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
import javax.persistence.*;
import java.io.Serializable;
import java.text.DecimalFormat;
import java.util.Date;
import java.util.HashSet;
import java.util.Set;
/**
* 用户实体类
*/
@Entity
@Table(name = "bs_user")
@Getter
@Setter
@NoArgsConstructor
public class User implements Serializable {
private static final long serialVersionUID = 4297464181093070302L;
/**
* ID
*/
@Id
private String id;
/**
* 手机号码
*/
@ExcelAttribute(sort = 2)
private String mobile;
/**
* 用户名称
*/
@ExcelAttribute(sort = 1)
private String username;
/**
* 密码
*/
private String password;
/**
* 启用状态 0为禁用 1为启用
*/
private Integer enableState;
/**
* 创建时间
*/
private Date createTime;
private String companyId;
private String companyName;
/**
* 部门ID
*/
@ExcelAttribute(sort = 6)
private String departmentId;
/**
* 入职时间
*/
@ExcelAttribute(sort = 5)
private Date timeOfEntry;
/**
* 聘用形式
*/
@ExcelAttribute(sort = 4)
private Integer formOfEmployment;
/**
* 工号
*/
@ExcelAttribute(sort = 3)
private String workNumber;
/**
* 管理形式
*/
private String formOfManagement;
/**
* 工作城市
*/
private String workingCity;
/**
* 转正时间
*/
private Date correctionTime;
/**
* 在职状态 1.在职 2.离职
*/
private Integer inServiceStatus;
private String departmentName;
/**
* level
* String
* saasAdmin:saas管理员具备所有权限
* coAdmin:企业管理(创建租户企业的时候添加)
* user:普通用户(需要分配角色)
*/
private String level;
private String staffPhoto; //用户头像
public User(Object [] values) {
//用户名 手机号 工号 聘用 形式 入职 时间 部门编码
this.username = values[1].toString();
this.mobile = values[2].toString();
this.workNumber = new DecimalFormat("#").format(values[3]);
this.formOfEmployment =((Double) values[4]).intValue();
this.timeOfEntry = (Date) values[5];
this.departmentId = values[6].toString(); //部门编码 != 部门id
}
/**
* JsonIgnore
* : 忽略json转化
*/
@JsonIgnore
@ManyToMany
@JoinTable(name="pe_user_role",joinColumns={@JoinColumn(name="user_id",referencedColumnName="id")},
inverseJoinColumns={@JoinColumn(name="role_id",referencedColumnName="id")}
)
private Set<Role> roles = new HashSet<Role>();//用户与角色 多对多
}
- 在UserController中importUser方法用工具类来导入数据
/**
* 导入Excel,添加用户
*/
@RequestMapping(value = "/user/import" , method = RequestMethod.POST)
public Result importUser(@RequestParam(name = "file") MultipartFile file) throws Exception {
List<User> list = new ExcelImportUtil(User.class).readExcel(file.getInputStream(), 1, 1);
//3.批量保存用户
userService.saveAll(list , companyId , companyName);
return new Result(ResultCode.SUCCESS);
}骚戴理解:这里也只要知道怎么用这个工具类即可
- User.class是指的导出实体类的字节码
- file.getInputStream()是指的传入文件的IO输入流
- 第一个1是指从模板的第二行开始读数据
- 第二个1是指从模板的第二列开始读数据

导出数据
给导出的实体类上面加上自定义注解 @ExcelAttribute
package com.ihrm.domain.employee.response;
import com.ihrm.domain.employee.EmployeeResignation;
import com.ihrm.domain.employee.UserCompanyPersonal;
import com.ihrm.domain.poi.ExcelAttribute;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
import lombok.ToString;
import org.springframework.beans.BeanUtils;
@Getter
@Setter
@NoArgsConstructor
@ToString
public class EmployeeReportResult {
@ExcelAttribute(sort = 0)
private String userId;
@ExcelAttribute(sort = 1)
private String username;
private String departmentName;
@ExcelAttribute(sort = 2)
private String mobile;
@ExcelAttribute(sort = 9)
private String timeOfEntry;
private String companyId;
private String sex;
/**
* 出生日期
*/
private String dateOfBirth;
/**
* 最高学历
*/
@ExcelAttribute(sort = 3)
private String theHighestDegreeOfEducation;
/**
* 国家地区
*/
@ExcelAttribute(sort = 4)
private String nationalArea;
/**
* 护照号
*/
@ExcelAttribute(sort = 5)
private String passportNo;
/**
* 身份证号
*/
private String idNumber;
/**
* 身份证照片-正面
*/
private String idCardPhotoPositive;
/**
* 身份证照片-背面
*/
private String idCardPhotoBack;
/**
* 籍贯
*/
@ExcelAttribute(sort = 6)
private String nativePlace;
/**
* 民族
*/
private String nation;
/**
* 英文名
*/
private String englishName;
/**
* 婚姻状况
*/
private String maritalStatus;
/**
* 员工照片
*/
private String staffPhoto;
/**
* 生日
*/
@ExcelAttribute(sort = 7)
private String birthday;
/**
* 属相
*/
@ExcelAttribute(sort = 8)
private String zodiac;
/**
* 年龄
*/
private String age;
/**
* 星座
*/
private String constellation;
/**
* 血型
*/
private String bloodType;
/**
* 户籍所在地
*/
private String domicile;
/**
* 政治面貌
*/
private String politicalOutlook;
/**
* 入党时间
*/
private String timeToJoinTheParty;
/**
* 存档机构
*/
private String archivingOrganization;
/**
* 子女状态
*/
private String stateOfChildren;
/**
* 子女有无商业保险
*/
private String doChildrenHaveCommercialInsurance;
/**
* 有无违法违纪行为
*/
private String isThereAnyViolationOfLawOrDiscipline;
/**
* 有无重大病史
*/
private String areThereAnyMajorMedicalHistories;
/**
* QQ
*/
private String qq;
/**
* 微信
*/
private String wechat;
/**
* 居住证城市
*/
private String residenceCardCity;
/**
* 居住证办理日期
*/
private String dateOfResidencePermit;
/**
* 居住证截止日期
*/
private String residencePermitDeadline;
/**
* 现居住地
*/
private String placeOfResidence;
/**
* 通讯地址
*/
private String postalAddress;
/**
* 联系手机
*/
private String contactTheMobilePhone;
/**
* 个人邮箱
*/
private String personalMailbox;
/**
* 紧急联系人
*/
private String emergencyContact;
/**
* 紧急联系电话
*/
private String emergencyContactNumber;
/**
* 社保电脑号
*/
private String socialSecurityComputerNumber;
/**
* 公积金账号
*/
private String providentFundAccount;
/**
* 银行卡号
*/
private String bankCardNumber;
/**
* 开户行
*/
private String openingBank;
/**
* 学历类型
*/
private String educationalType;
/**
* 毕业学校
*/
private String graduateSchool;
/**
* 入学时间
*/
private String enrolmentTime;
/**
* 毕业时间
*/
private String graduationTime;
/**
* 专业
*/
private String major;
/**
* 毕业证书
*/
private String graduationCertificate;
/**
* 学位证书
*/
private String certificateOfAcademicDegree;
/**
* 上家公司
*/
private String homeCompany;
/**
* 职称
*/
private String title;
/**
* 简历
*/
private String resume;
/**
* 有无竞业限制
*/
private String isThereAnyCompetitionRestriction;
/**
* 前公司离职证明
*/
private String proofOfDepartureOfFormerCompany;
/**
* 备注
*/
private String remarks;
/**
* 离职时间
*/
@ExcelAttribute(sort = 12)
private String resignationTime;
/**
* 离职类型
*/
@ExcelAttribute(sort = 10)
private String typeOfTurnover;
/**
* 申请离职原因
*/
@ExcelAttribute(sort = 11)
private String reasonsForLeaving;
public EmployeeReportResult(UserCompanyPersonal personal, EmployeeResignation resignation) {
BeanUtils.copyProperties(personal,this);
if(resignation != null) {
BeanUtils.copyProperties(resignation,this);
}
}
}
骚戴理解: @ExcelAttribute注解就是用来定义实体类属性在模板中列的位置,例如模板中姓名对应的列号是1,所以 @ExcelAttribute(sort = 1) private String username;里的sort = 1,注意列号是从0开始的

在export方法里使用导入工具类
@RequestMapping(value = "/export/{month}", method = RequestMethod.GET)
public void export(@PathVariable String month) throws Exception {
//1.获取报表数据
List<EmployeeReportResult> list = userCompanyPersonalService.findByReport(companyId,month+"%");
//2.加载模板
Resource resource = new ClassPathResource("excel-template/hr-demo.xlsx");
FileInputStream fis = new FileInputStream(resource.getFile());
//3.通过工具类完成下载
new ExcelExportUtil(EmployeeReportResult.class,2,2).
export(response,fis,list,month+"人事报表.xlsx");
}骚戴理解:下面的工具类会用就行,知道传入的参数是什么就可以了
new ExcelExportUtil(EmployeeReportResult.class,2,2).export(response,fis,list,month+"人事报表.xlsx");- EmployeeReportResult.class是导出的实体类的字节码,也就是从数据库中查询到的数据集合的实体类的字节码
- 第一个2是指的行号,也就是把数据集合中的数据从第几行开始写到Excel表格中,注意这个2是指的把数据从第3行开始写入,因为下标是从0开始的
- 第二个2是指的样式的行号,可以看到我希望所有的数据样式都是如下面的第三行的样式一样,所以这个2是指的第三行的样式
- response其实就是HttpServletResponse
- fis是模板样式的文件输入IO流
FileInputStream fis = new FileInputStream(resource.getFile());- list是需要导出数据库中查询到的所有集合数据
List<EmployeeReportResult> list = userCompanyPersonalService.findByReport(companyId,month+"%");- month+"人事报表.xlsx"是导出文件的名称
百万数据报表概述
概述
我们都知道Excel可以分为早期的Excel2003版本(使用POI的HSSF对象操作)和Excel2007版本(使用POI的XSSF 操作),两者对百万数据的支持如下:
- Excel 2003:在POI中使用HSSF对象时,excel 2003最多只允许存储65536条数据,一般用来处理较少的数据量。这时对于百万级别数据,Excel肯定容纳不了。
- Excel 2007:当POI升级到XSSF对象时,它可以直接支持excel2007以上版本,因为它采用ooxml格式。这时excel可以支持1048576条数据,单个sheet表就支持近百万条数据。但实际运行时还可能存在问题,原因是执 行POI报表所产生的行对象,单元格对象,字体对象,他们都不会销毁,这就导致OOM的风险。
JDK性能监控工具介绍
没有性能监控工具一切推论都只能停留在理论阶段,我们可以使用Java的性能监控工具来监视程序的运行情况,包 括CUP,垃圾回收,内存的分配和使用情况,这让程序的运行阶段变得更加可控,也可以用来证明我们的推测。这里我们使用JDK提供的性能工具Jvisualvm来监控程序运行。
Jvisualvm概述
VisualVM 是Netbeans的profile子项目,已在JDK6.0 update 7 中自带,能够监控线程,内存情况,查看方法的CPU时间和内存中的对 象,已被GC的对象,反向查看分配的堆栈
Jvisualvm的位置
Jvisualvm位于JAVA_HOME/bin目录下,直接双击就可以打开该程序。如果只是监控本地的java进程,是不需要配 置参数的,直接打开就能够进行监控。首先我们需要在本地打开一个Java程序,例如我打开员工微服务进程,这时 在jvisualvm界面就可以看到与IDEA相关的Java进程了:
骚戴理解:我的Jvisualvm默认路径在C:\Program Files\Java\jdk1.8.0_351\bin\jvisualvm.exe
Jvisualvm的使用
Jvisualvm使用起来比较简单,双击点击当前运行的进程即可进入到程序的监控界面
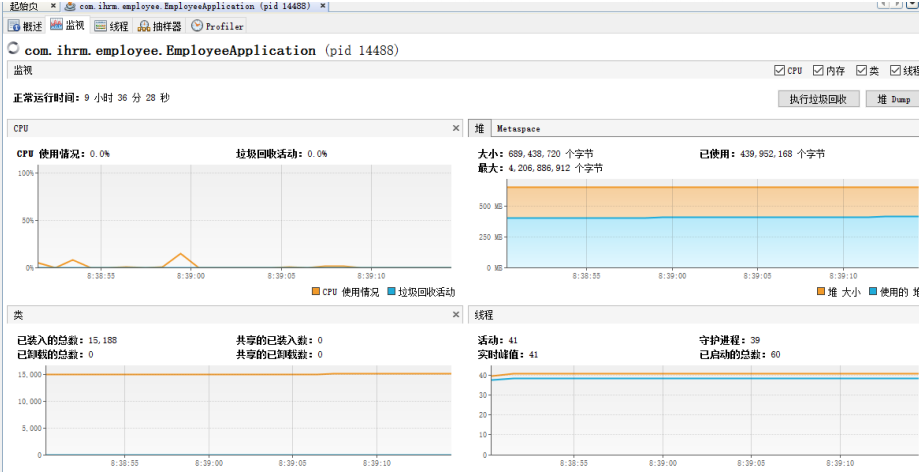
概述:可以看到进程的启动参数。
监视:
- 左上:cpu利用率,gc状态的监控
- 右上:堆利用率,永久内存区的利用率
- 左下:类的监控
- 右下: 线程的监控
线程:能够显示线程的名称和运行的状态,在调试多线程时必不可少,而且可以点进一个线程查看这个线程 的详细运行情况
解决方案分析
对于百万数据量的Excel导入导出,只讨论基于Excel2007的解决方法。在ApachePoi 官方提供了对操作大数据量的导入导出的工具和解决办法,操作Excel2007使用XSSF对象,可以分为三种模式:
- 用户模式:用户模式有许多封装好的方法操作简单,但创建太多的对象,非常耗内存(之前使用的方法)
- 事件模式:基于SAX方式解析XML,SAX全称Simple API for XML,它是一个接口,也是一个软件包。它是一种XML解析的替代方法,不同于DOM解析XML文档时把所有内容一次性加载到内存中的方式,它逐行扫描文 档,一边扫描,一边解析。
- SXSSF对象:是用来生成海量excel数据文件,主要原理是借助临时存储空间生成excel
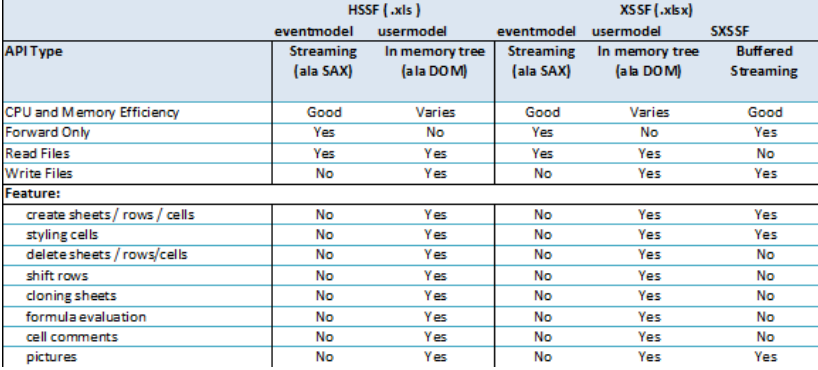
这是一张Apache POI官方提供的图片,描述了基于用户模式,事件模式,以及使用SXSSF三种方式操作Excel的特性以及CUP和内存占用情况。
骚戴理解:用户模式就是之前写的那种代码就是用户模式,如下所示就是用户模式
/**
* 采用模板打印的形式完成报表生成
* 模板
* 参数:
* 年月-月(2018-02%)
*
* sxssf对象不支持模板打印
*/
@RequestMapping(value = "/export/{month}", method = RequestMethod.GET)
public void export(@PathVariable String month) throws Exception {
//1.获取报表数据
List<EmployeeReportResult> list = userCompanyPersonalService.findByReport(companyId,month);
//2.加载模板
Resource resource = new ClassPathResource("excel-template/hr-demo.xlsx");
FileInputStream fis = new FileInputStream(resource.getFile());
//3.通过工具类完成下载
// new ExcelExportUtil(EmployeeReportResult.class,2,2).
// export(response,fis,list,month+"人事报表.xlsx");
//3.根据模板创建工作簿
Workbook wb = new XSSFWorkbook(fis);
//4.读取工作表
Sheet sheet = wb.getSheetAt(0);
//5.抽取公共样式
Row row = sheet.getRow(2);
CellStyle styles [] = new CellStyle[row.getLastCellNum()];
for(int i=0;i<row.getLastCellNum();i++) {
Cell cell = row.getCell(i);
styles[i] = cell.getCellStyle();
}
//6.构造单元格
int rowIndex = 2;
Cell cell=null;
for(int i=0;i<10000;i++) {
for (EmployeeReportResult employeeReportResult : list) {
row = sheet.createRow(rowIndex++);
// 编号,
cell = row.createCell(0);
cell.setCellValue(employeeReportResult.getUserId());
cell.setCellStyle(styles[0]);
// 姓名,
cell = row.createCell(1);
cell.setCellValue(employeeReportResult.getUsername());
cell.setCellStyle(styles[1]);
// 手机,
cell = row.createCell(2);
cell.setCellValue(employeeReportResult.getMobile());
cell.setCellStyle(styles[2]);
// 最高学历,
cell = row.createCell(3);
cell.setCellValue(employeeReportResult.getTheHighestDegreeOfEducation());
cell.setCellStyle(styles[3]);
// 国家地区,
cell = row.createCell(4);
cell.setCellValue(employeeReportResult.getNationalArea());
cell.setCellStyle(styles[4]);
// 护照号,
cell = row.createCell(5);
cell.setCellValue(employeeReportResult.getPassportNo());
cell.setCellStyle(styles[5]);
// 籍贯,
cell = row.createCell(6);
cell.setCellValue(employeeReportResult.getNativePlace());
cell.setCellStyle(styles[6]);
// 生日,
cell = row.createCell(7);
cell.setCellValue(employeeReportResult.getBirthday());
cell.setCellStyle(styles[7]);
// 属相,
cell = row.createCell(8);
cell.setCellValue(employeeReportResult.getZodiac());
cell.setCellStyle(styles[8]);
// 入职时间,
cell = row.createCell(9);
cell.setCellValue(employeeReportResult.getTimeOfEntry());
cell.setCellStyle(styles[9]);
// 离职类型,
cell = row.createCell(10);
cell.setCellValue(employeeReportResult.getTypeOfTurnover());
cell.setCellStyle(styles[10]);
// 离职原因,
cell = row.createCell(11);
cell.setCellValue(employeeReportResult.getReasonsForLeaving());
cell.setCellStyle(styles[11]);
// 离职时间
cell = row.createCell(12);
cell.setCellValue(employeeReportResult.getResignationTime());
cell.setCellStyle(styles[12]);
}
}
//7.下载
//3.完成下载
ByteArrayOutputStream os = new ByteArrayOutputStream();
wb.write(os);
new DownloadUtils().download(os,response,month+"人事报表.xlsx");
}事件模式适用于大数据量的导入操作,SXSSF对象适用于大数据量的导出操作
百万数据报表导出
需求分析
使用Apache POI完成百万数据量的Excel报表导出
解决方案
思路分析
基于XSSFWork导出Excel报表,是通过将所有单元格对象保存到内存中,当所有的Excel单元格全部创建完成之后 一次性写入到Excel并导出。当百万数据级别的Excel导出时,随着表格的不断创建,内存中对象越来越多,直至内 存溢出。Apache Poi提供了SXSSFWork对象,专门用于处理大数据量Excel报表导出。
原理分析
在实例化SXSSFWork这个对象时,可以指定在内存中所产生的POI导出相关对象的数量(默认100),一旦内存中的对象的个数达到这个指定值时,就将内存中的这些对象的内容写入到磁盘中(XML的临时文件格式),就可以将这些对象从内存中销毁,以后只要达到这个值,就会以类似的处理方式处理,直至Excel导出完成。
代码实现
在原有代码的基础上替换之前的XSSFWorkbook,使用SXSSFWorkbook完成创建过程即可
/**
* 采用模板打印的形式完成报表生成
* 模板
* 参数:
* 年月-月(2018-02%)
*
* sxssf对象不支持模板打印
*/
@RequestMapping(value = "/export/{month}", method = RequestMethod.GET)
public void export(@PathVariable String month) throws Exception {
//1.获取报表数据
List<EmployeeReportResult> list = userCompanyPersonalService.findByReport(companyId,month);
//2.加载模板
Resource resource = new ClassPathResource("excel-template/hr-demo.xlsx");
FileInputStream fis = new FileInputStream(resource.getFile());
//3.通过工具类完成下载
// new ExcelExportUtil(EmployeeReportResult.class,2,2).
// export(response,fis,list,month+"人事报表.xlsx");
//3.根据模板创建工作簿
SXSSFWorkbook wb = new SXSSFWorkbook(fis);
//4.读取工作表
Sheet sheet = wb.getSheetAt(0);
//5.抽取公共样式
Row row = sheet.getRow(2);
CellStyle styles [] = new CellStyle[row.getLastCellNum()];
for(int i=0;i<row.getLastCellNum();i++) {
Cell cell = row.getCell(i);
styles[i] = cell.getCellStyle();
}
//6.构造单元格
int rowIndex = 2;
Cell cell=null;
for(int i=0;i<10000;i++) {
for (EmployeeReportResult employeeReportResult : list) {
row = sheet.createRow(rowIndex++);
// 编号,
cell = row.createCell(0);
cell.setCellValue(employeeReportResult.getUserId());
cell.setCellStyle(styles[0]);
// 姓名,
cell = row.createCell(1);
cell.setCellValue(employeeReportResult.getUsername());
cell.setCellStyle(styles[1]);
// 手机,
cell = row.createCell(2);
cell.setCellValue(employeeReportResult.getMobile());
cell.setCellStyle(styles[2]);
// 最高学历,
cell = row.createCell(3);
cell.setCellValue(employeeReportResult.getTheHighestDegreeOfEducation());
cell.setCellStyle(styles[3]);
// 国家地区,
cell = row.createCell(4);
cell.setCellValue(employeeReportResult.getNationalArea());
cell.setCellStyle(styles[4]);
// 护照号,
cell = row.createCell(5);
cell.setCellValue(employeeReportResult.getPassportNo());
cell.setCellStyle(styles[5]);
// 籍贯,
cell = row.createCell(6);
cell.setCellValue(employeeReportResult.getNativePlace());
cell.setCellStyle(styles[6]);
// 生日,
cell = row.createCell(7);
cell.setCellValue(employeeReportResult.getBirthday());
cell.setCellStyle(styles[7]);
// 属相,
cell = row.createCell(8);
cell.setCellValue(employeeReportResult.getZodiac());
cell.setCellStyle(styles[8]);
// 入职时间,
cell = row.createCell(9);
cell.setCellValue(employeeReportResult.getTimeOfEntry());
cell.setCellStyle(styles[9]);
// 离职类型,
cell = row.createCell(10);
cell.setCellValue(employeeReportResult.getTypeOfTurnover());
cell.setCellStyle(styles[10]);
// 离职原因,
cell = row.createCell(11);
cell.setCellValue(employeeReportResult.getReasonsForLeaving());
cell.setCellStyle(styles[11]);
// 离职时间
cell = row.createCell(12);
cell.setCellValue(employeeReportResult.getResignationTime());
cell.setCellStyle(styles[12]);
}
}
//7.下载
//3.完成下载
ByteArrayOutputStream os = new ByteArrayOutputStream();
wb.write(os);
new DownloadUtils().download(os,response,month+"人事报表.xlsx");
}对比测试
- XSSFWorkbook生成百万数据报表
使用XSSFWorkbook生成Excel报表,时间较长,随着时间推移,内存占用原来越多,直至内存溢出
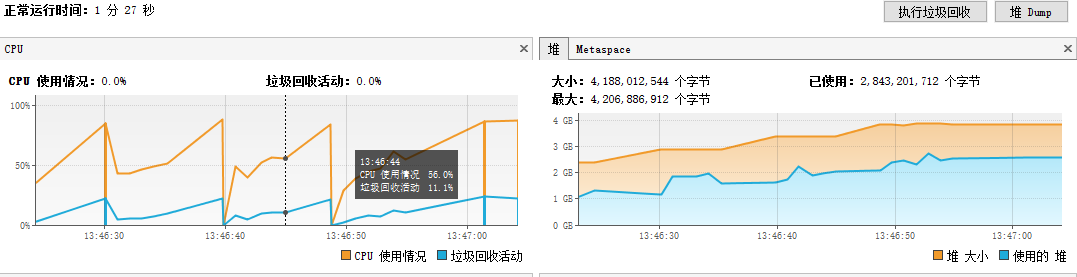
- SXSSFWorkbook生成百万数据报表
使用SXSSFWorkbook生成Excel报表,内存占用比较平缓
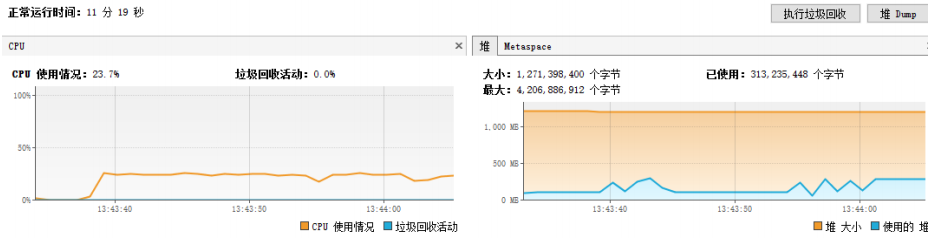
骚戴理解:可以看到SXSSFWorkbook的堆内存变化,即蓝色的曲线图,可以看出它是一个个的山峰一样的图形,上升后会下降,下降的原因是因为对象达到了SXSSFWorkbook设置的阈值,默认是100,也就是达到了100个对象后就会把对象写到临时的xml文件里面,然后销毁掉内存中的这部分对象,所以才会下降,这样的确可以实现百万数据量的导出,但是也是有一些问题的,由于内存速度速度和磁盘速度是不一样的,首先主线程会把所有的对象创建好放到内存里,然后达到阈值才会写入xml临时文件,这是两个过程,然后通常内存写入的速度远远快于磁盘写入xml临时文件的速度,所以如果数据量是很多,例如千万级别的数据量的时候还是会把内存给挤爆,然后报错OOM内存溢出!
百万数据报表读取
需求分析
使用POI基于事件模式解析案例提供的Excel文件
解决方案
思路分析
用户模式:加载并读取Excel时,是通过一次性的将所有数据加载到内存中再去解析每个单元格内容。当Excel 数据量较大时,由于不同的运行环境可能会造成内存不足甚至OOM异常。
事件模式:它逐行扫描文档,一边扫描一边解析。由于应用程序只是在读取数据时检查数据,因此不需要将数据完全存储在内存中,这对于大型文档的解析是个巨大优势。
步骤分析
- 设置POI的事件模式
- 根据Excel获取文件流
- 根据文件流创建OPCPackage
- 创建XSSFReader对象
- Sax解析
- 自定义Sheet处理器
- 创建Sax的XmlReader对象
- 设置Sheet的事件处理器
- 逐行读取
原理分析
我们都知道对于Excel2007的实质是一种特殊的XML存储数据,那就可以使用基于SAX的方式解析XML完成Excel的读取。SAX提供了一种从XML文档中读取数据的机制。它逐行扫描文档,一边扫描一边解析。由于应用程序只是在读取数据时检查数据,因此不需要将数据完全存储在内存中,这对于大型文档的解析是个巨大优势

骚戴理解:事件驱动就是一边解析一边用,所以数据不完全放内存里,即拿即用,用完就删,所以对内存的占用很少,但是只能解析一次,因为数据会被删掉,不可逆!
代码实现
自定义处理器
package cn.itcast.poi.entity.cn.itcast.poi.handler;
import cn.itcast.poi.entity.PoiEntity;
import org.apache.poi.xssf.eventusermodel.XSSFSheetXMLHandler;
import org.apache.poi.xssf.usermodel.XSSFComment;
/**
* 自定义的事件处理器
* 处理每一行数据读取
* 实现接口
*/
public class SheetHandler implements XSSFSheetXMLHandler.SheetContentsHandler {
private PoiEntity entity;
/**
* 当开始解析某一行的时候触发
* i:行索引
*/
@Override
public void startRow(int i) {
//实例化对象
if(i>0) {
entity = new PoiEntity();
}
}
/**
* 当结束解析某一行的时候触发
* i:行索引
*/
@Override
public void endRow(int i) {
//使用对象进行业务操作
System.out.println(entity);
}
/**
* 对行中的每一个表格进行处理
* cellReference: 单元格名称
* value:数据
* xssfComment:批注
*/
@Override
public void cell(String cellReference, String value, XSSFComment xssfComment) {
//对对象属性赋值
if(entity != null) {
String pix = cellReference.substring(0,1);
switch (pix) {
case "A":
entity.setId(value);
break;
case "B":
entity.setBreast(value);
break;
case "C":
entity.setAdipocytes(value);
break;
case "D":
entity.setNegative(value);
break;
case "E":
entity.setStaining(value);
break;
case "F":
entity.setSupportive(value);
break;
default:
break;
}
}
}
}
骚戴理解:String pix = cellReference.substring(0,1);是获取单元格名称的第一个字符,也就是标识列名的字母。在Excel中,单元格名称通常由列名字母和行号组成(例如A1、B2等),这里使用substring方法截取单元格名称的第一个字符来标识列名从而确定对应属性进行赋值操作。

自定义解析
package cn.itcast.poi.test;
import cn.itcast.poi.entity.cn.itcast.poi.handler.SheetHandler;
import org.apache.poi.openxml4j.exceptions.InvalidFormatException;
import org.apache.poi.openxml4j.opc.OPCPackage;
import org.apache.poi.openxml4j.opc.PackageAccess;
import org.apache.poi.xssf.eventusermodel.XSSFReader;
import org.apache.poi.xssf.eventusermodel.XSSFSheetXMLHandler;
import org.apache.poi.xssf.model.SharedStringsTable;
import org.apache.poi.xssf.model.StylesTable;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
import org.xml.sax.InputSource;
import org.xml.sax.XMLReader;
import org.xml.sax.helpers.XMLReaderFactory;
import java.io.InputStream;
import java.util.Iterator;
/**
* 使用事件模型解析百万数据excel报表
*/
public class PoiTest06 {
public static void main(String[] args) throws Exception {
String path = "C:\\Users\\ThinkPad\\Desktop\\ihrm\\day8\\资源\\百万数据报表\\demo.xlsx";
//1.根据excel报表获取OPCPackage
OPCPackage opcPackage = OPCPackage.open(path, PackageAccess.READ);
//2.创建XSSFReader
XSSFReader reader = new XSSFReader(opcPackage);
//3.获取SharedStringTable对象
SharedStringsTable table = reader.getSharedStringsTable();
//4.获取styleTable对象
StylesTable stylesTable = reader.getStylesTable();
//5.创建Sax的xmlReader对象
XMLReader xmlReader = XMLReaderFactory.createXMLReader();
//6.注册事件处理器
XSSFSheetXMLHandler xmlHandler = new XSSFSheetXMLHandler(stylesTable,table,new SheetHandler(),false);
xmlReader.setContentHandler(xmlHandler);
//7.逐行读取
XSSFReader.SheetIterator sheetIterator = (XSSFReader.SheetIterator) reader.getSheetsData();
while (sheetIterator.hasNext()) {
InputStream stream = sheetIterator.next(); //每一个sheet的流数据
InputSource is = new InputSource(stream);
xmlReader.parse(is);
}
}
}
骚戴理解:
- OPCPackage opcPackage = OPCPackage.open(path, PackageAccess.READ);这行代码的作用是打开并读取一个指定路径的Office Open XML (OOXML)包文件,该文件通常是.xlsx或.xlsm格式的Excel文件。具体来说,OPCPackage类可以从本地文件系统、InputStream或URL中打开OOXML包,并提供了读取、修改和创建OOXML文档的方法。其中,path参数表示要打开的OOXML包文件的路径;PackageAccess.READ表示采用仅读取模式的方式打开该文件。通过OPCPackage对象的实例,Java程序可以访问包中的各种元素,如workbook、sharedStrings等,以及它们的内容,继而进行相应的处理操作。
- XSSFReader reader = new XSSFReader(opcPackage);这行代码的作用是基于已打开的OOXML包文件,创建一个XSSFReader对象。在Apache POI中,XSSFReader类是用于读取Excel2007及以上版本文件(即.xlsx格式)的类,提供了对工作簿、工作表和单元格等元素的读取操作。reader变量是一个XSSFReader对象的引用,可以通过它访问某个.xlsx文件的所有部件(Parts)并读取其中的数据内容,如工作簿、电子表格、样式集等。具体来说,该代码中的opcPackage参数表示已经打开的.xlsx文件所对应的OPCPackage对象。通过该对象创建XSSFReader对象之后,程序就可以通过调用XSSFReader对象的相应方法,完成Excel文件的解析和读取工作。
- SharedStringsTable table = reader.getSharedStringsTable();这行代码的作用是通过XSSFReader对象获取Excel文件中的共享字符串表(SharedStringsTable)对象。在Excel2007及以上版本中,相比于早期的.xls格式,.xlsx格式的文件更加节省空间,其中一个原因是采用了共享字符串表来存储重复的字符串值,而非直接将它们写入每个单元格。共享字符串表主要用于存储文本型数据类型,包括文字和数字等。因此,在解析.xlsx格式的文件时,需要先将其包含的共享字符串表加载到内存中,才能通过索引查找对应字符串并读取单元格的值。该代码中的reader参数表示已经创建的XSSFReader对象,程序通过调用其getSharedStringsTable()方法,可以获取Excel文件中的共享字符串表对象,从而实现读取其中存储的字符串值及其索引的功能。得到共享字符串表对象之后,程序可以根据需要使用它的API进行相关的字符串操作,如添加、删除、修改、查询等。
- StylesTable stylesTable = reader.getStylesTable();这行代码的作用是通过XSSFReader对象获取Excel2007及以上版本文件中的样式表(StylesTable)对象。在Excel文件中,单元格的样式是由一系列属性和特征组成的。通常情况下,如果多个单元格具有相同的样式属性,则可以将它们定义为一个公共的样式引用,并在样式表中记录它们所包含的所有属性信息。样式表主要用于描述单元格、字体、背景色、边框、对齐方式等样式的各种属性和特征。该代码中的reader参数表示已经创建的XSSFReader对象,程序通过调用其getStylesTable()方法,可以获取Excel文件中的样式表对象,从而实现读取其中存储的样式信息的功能。得到样式表对象之后,程序可以根据需要使用它的API对样式进行相关的操作,如添加、修改、删除、查询等。获取样式表对象也是解析Excel2007及以上版本文件的关键步骤之一,因为对单元格的格式化和样式设置直接依赖于样式表。
- XMLReader xmlReader = XMLReaderFactory.createXMLReader();这行代码的作用是创建一个基于SAX(Simple API for XML)实现的XML解析器对象,该解析器由Java自带的XMLReaderFactory工厂类生成。在Java中,处理XML文档通常有两种方式:DOM和SAX。其中,DOM是一种基于树形结构的解析方式,可以将整个XML文档加载到内存中,并以树形结构表示出来;而SAX则是一种基于事件驱动的解析方式,它会在XML文件解析时产生一系列的事件,我们可以注册回调方法来获取并处理这些事件。由于SAX不需要将XML文档完全加载到内存中,所以对于大型XML文件的处理更加高效和灵活。该代码中使用了Java标准库提供的XMLReaderFactory类生成一个默认配置的SAX解析器对象xmlReader,程序可以通过该对象的相关API实现读取和解析Excel2007及以上版本的xlsx文件。通常情况下,在通过XSSFReader对象获取Excel文件各个部分数据之前,需要先通过该解析器对象将对应部分的XML内容解析为可读格式,再调用相应API进行访问和操作。
XSSFSheetXMLHandler xmlHandler = new XSSFSheetXMLHandler(stylesTable,table,new SheetHandler(),false);
xmlReader.setContentHandler(xmlHandler);- 这两行代码的作用是将读取到的Excel表格数据与对应的样式信息进行关联,并设置XMLReader对象的内容处理器为XSSFSheetXMLHandler对象,进而实现解析.xlsx文件中单个sheet页数据及其样式的功能。其中,参数stylesTable表示Excel文件的样式表对象(StylesTable),参数table表示Excel文件的 共享字符串表对象(SharedStringsTable)。这两个对象是在之前获取Excel数据(包括字符串和样式)时得到的。参数new SheetHandler()表示自定义的SheetHandler对象,该对象继承自DefaultHandler类,实现了XML文档解析时产生的各种事件的回调方法,以便程序能够相应地读取和处理表格中的数据。参数false表示XSSFSheetXMLHandler对象的构造函数不需要启用日期格式化功能,默认为关闭状态。接着,通过xmlReader.setContentHandler(xmlHandler)方法将XSSFSheetXMLHandler对象设置为XMLReader对象的内容处理器。当程序开始解析Excel文件时,XPath表达式会逐一匹配XML文档中的各个节点,当遇到符合条件的节点时,会触发XMLReader对象相应的解析事件,调用XSSFSheetXMLHandler对象对应的回调方法来进行解析、读取和处理。从而实现读取并解析Excel文件中单个表格页数据及其样式的操作。
XSSFReader.SheetIterator sheetIterator = (XSSFReader.SheetIterator) reader.getSheetsData();
while (sheetIterator.hasNext()) {
InputStream stream = sheetIterator.next(); //每一个sheet的流数据
InputSource is = new InputSource(stream);
xmlReader.parse(is);
}- 这行代码的作用是使用XSSFReader对象获取Excel文件中所有sheet页数据流信息,并封装成SheetIterator迭代器对象,以便程序可以遍历和访问其中的每个sheet页。在Excel文件中,一个.xlsx格式的文件通常包含多个sheet页,每个sheet页由若干行和列构成,其中存储着实际的数据内容。为了读取和处理这些数据内容,需要将各个sheet页数据流信息分别提取出来,并进行相应的解析和操作。该代码中,通过调用reader.getSheetsData()方法得到的SheetIterator对象,可以对sheet页数据流进行逐一迭代,并返回每个sheet页数据的相关信息,如名称、ID、XML路径等。程序可以通过该对象的hasNext()方法检查是否还有下一个sheet页待读取,然后再调用next()方法获取当前sheet页的输入流(InputStream),并对其进行相应的数据读取和解析。在while循环中,每次从迭代器中获取当前sheet页的输入流,并创建一个InputSource对象,以帮助XMLReader对象解析该输入流。然后调用xmlReader.parse(is)方法启动XMLReader对象解析输入流并触发各种回调事件,程序根据解析得到的事件来读取相应的表格数据和样式信息。由于Excel2007及以上版本采用了基于XML标准的文件格式,故在解析时需要借助SAX解析器进行读取。因此,在解析每个sheet页的XML数据之前,需要通过XSSFSheetXMLHandler对象将各个单元格的值与样式进行匹配。
对比测试
用户模式下读取测试Excel文件直接内存溢出,测试Excel文件映射到内存中还是占用了不少内存;事件模式下可以 流畅的运行。
- 使用用户模型解析
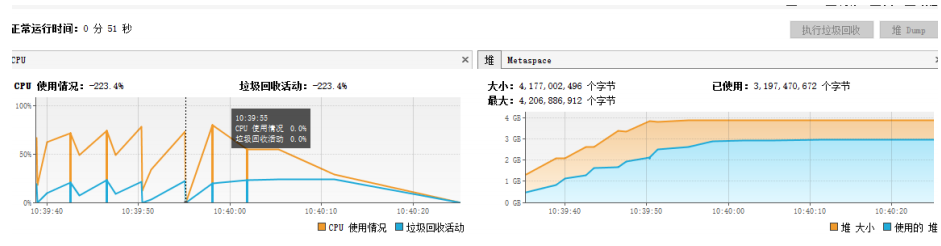
- 使用事件模型解析

总结
通过简单的分析以及运行两种模式进行比较,可以看到用户模式下使用更简单的代码实现了Excel读取,但是在读 取大文件时CPU和内存都不理想;而事件模式虽然代码写起来比较繁琐,但是在读取大文件时CPU和内存更加占优。