前言
roofline 分析是一种简单评估当前计算任务对当前平台计算/访存能力的利用情况的方法,可以帮助分析算子的优化方向和优化潜力。mperf 实现了安卓 mali/adreno 两种 gpu 平台的 roofline 分析能力,下面以 mali 平台为例,简单介绍一下操作步骤。
编译和集成
下载 repo 代码
git clone https://github.com/MegEngine/mperf.gitgit submodule update --init --recursive编译安装
./android_build.sh -g malicmake --build <mperf_build_dir> --target install项目集成
set(mperf_DIR /path/to/your/installed/mperfConfig.cmake)find_package(mperf REQUIRED)target_link_libraries(your_target mperf::mperf)关于编译和集成部分,详见 mperf readme (https://github.com/MegEngine/mperf#readme)
获取 roofline 数据
获取 opencl 算子执行过程的 GFLOPs 和 GBPs
// define the measurement setmperf::GpuCounterSet gpu_set = { mperf::GpuCounter::GFLOPs, mperf::GpuCounter::GBPs,};mperf::XPMU xpmu(gpu_set);xpmu.run();... // add your opencl kernel calls详细测试样例,参见 mali_gpu_pmu_test (https://github.com/MegEngine/mperf/blob/master/apps/gpu_mali_pmu_test.cpp)
获取当前 gpu 平台的峰值计算能力和访存带宽
将编译阶段得到的 build_dir/apps 目录下的 gpu_inst_gflops_latency 和 gpu_spec_dram_bw 拷贝到手机上执行,即可拿到 gpu 的实际峰值算力和峰值带宽。
峰值性能测试的详细逻辑,参见 gpu_inst_gflops_latency(https://github.com/MegEngine/mperf/blob/master/apps/gpu_inst_gflops_latency.cpp) 和 gpu_spec_dram_bw(https://github.com/MegEngine/mperf/blob/master/apps/gpu_spec_dram_bw.cpp)
绘制 roofline
上一步拿到了 opencl 算子执行过程的 GFLOPs 和 GBPs 和 gpu 的实测峰值算力和峰值带宽,现在可以借助 mperf plot_roofline (https://github.com/MegEngine/mperf/blob/master/apps/scripts/roofline/plot_roofline.py)脚本绘制 roofline 曲线:
编辑 roofline_data.txt:
# params for plotting roofs, gpu peak calculation and memory ability
memroofs 26.3
mem_roof_names 'DRAM'
comproofs 1159
comp_roof_names 'FMA'
# omit the following if only plotting roofs
# the measured data for your opencl kernel call, AI is measured_GFLOPs/measrured_GBPs
AI 15.5
FLOPS 261
labels 'FMA, DRAM'-
执行 python 脚本:
python3 plot_roofline.py ./roofline_data.txt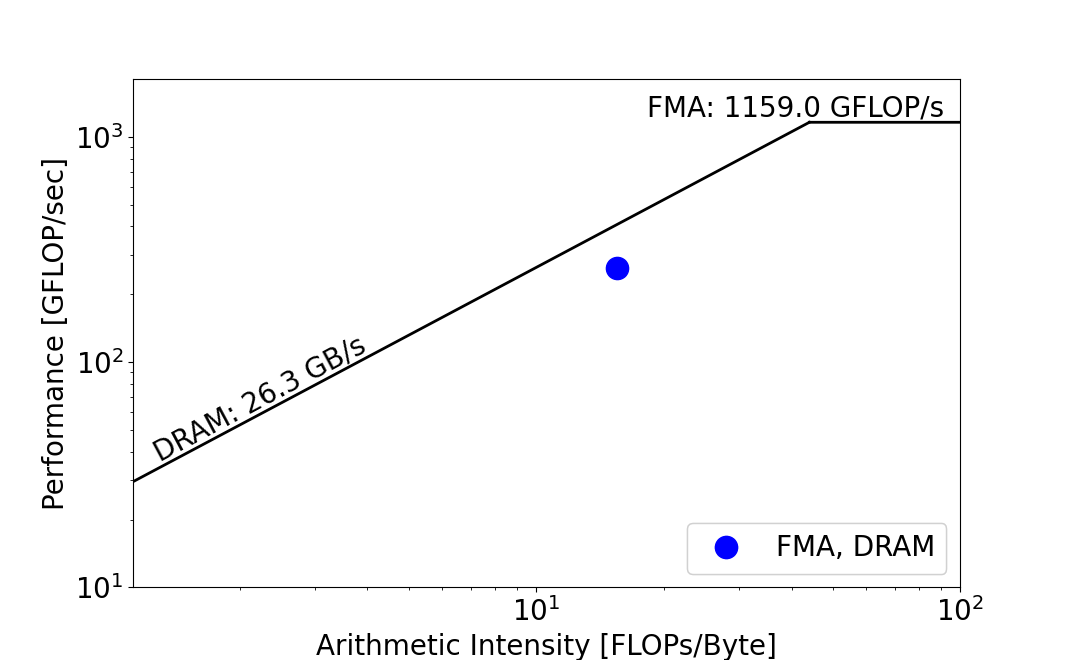
-
-
比如上面得到的 roofline 曲线中,算子的计算访存比小于机器平衡点(通常将屋檐和屋顶转折点的横坐标称为机器平衡点),所以可以初步判断该算子在该平台上主要 bound 在访存部分,平台的算力资源对于该算子来说还是有富裕的。并且可以根据算子的实际带宽跟机器的峰值带宽的比值,来评估后续访存优化的空间有多大。
同时提醒一点,在获取算子 GBPs 的时候,我们是拿到了算子实际发生的 ddr 访存量的,这个访存量可以跟算子输入输出变量总的内存占用大小做一个比较,从而衡量出算子有多少重复访存没有被 cache 和寄存器 cover 住,而产生的对 ddr 的重复访问。如果观察到 ddr 访存量显著大于输入输出总的内存占用,那么我们就需要去审视算子的访存逻辑是不是不够 cache 友好,是不是有些重复访存可以通过加一些缓存逻辑来避免等等。
-
拓展思考
通过上面的步骤,我们获取了 roofline 数据,这可以帮助我们判断当前算子在当前平台是计算 bound 还是访存 bound,以及相对峰值算力和峰值带宽的 gap 大小。但是,单单依靠 roofline 分析又很难进一步具化瓶颈的位置和缓解的对策,比如访存 bound 的原因是因为哪一级存储的访存效率低下?计算 bound 是因为指令依赖还是某一类 alu 硬件资源紧张?
为了解决这些问题,mperf 还做了一些硬件参数探测、PMU 数据加工分析、opencl kernel 的动静态代码分析(动静态代码分析的功能,还在内部迭代开发中,尚未推到开源 repo 中)等尝试,尽可能让算子性能分析和优化更加有迹可循,或者说心智负担更低。
附:更多 MegEngine 信息获取,您可以:查看GitHub 项目(https://github.com/MegEngine),或加入 MegEngine 用户交流 QQ 群:1029741705。欢迎参与 MegEngine 社区贡献,成为 Awesome MegEngineer,荣誉证书、定制礼品享不停。