文章目录
- 一、背景
- 二、方法
- 2.1 Contrastive DeNoising Training
- 2.3 Mixed Query Selection
- 2.4 Look Forward Twice
- 三、效果
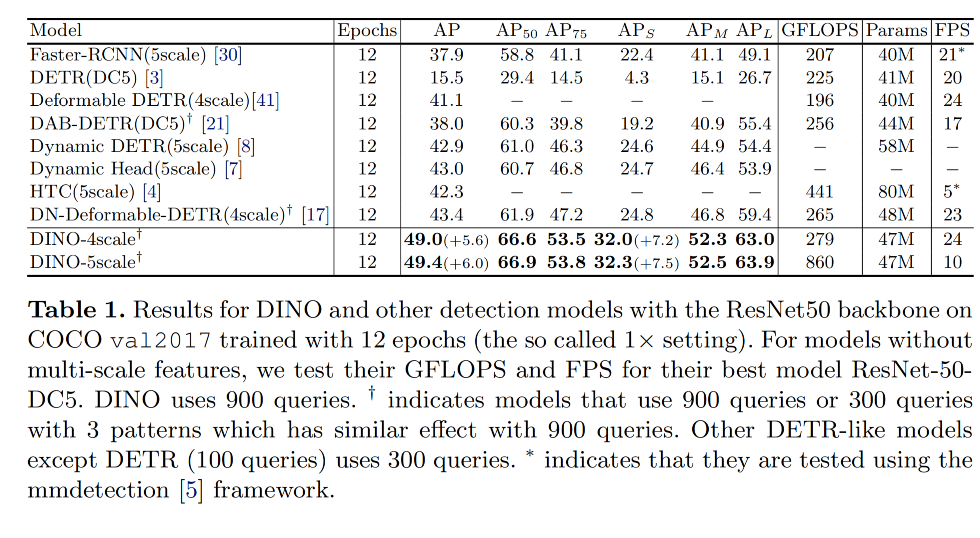
论文:DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
代码:https://github.com/IDEACVR/DINO
出处:香港大学 | 清华大学
时间:2022.07
一、背景
DINO:Detr with Improved deNoising anchOr boxes
DINO 是一个基于 DETR 结构的端到端目标检测器,通过对去噪训练使用对比学习的方式来提高了 DETR-like models 的性能和效果
DINO 的结构:
- backbone
- multi-layer Transformer encoder
- multi-layer Transformer decoder
- multiple prediction heads
- 参考 DAB-DETR,作者在 decoder 中构建了 queries 作为 dynamic anchor box,并且通过 decoder layers 一步步对其进行 refine
- 参考 DN-DETR,作者在 Transformer decoder layer 中的 ground truth label 和 box 添加了噪声,帮助模型在训练中实现更稳定的双边匹配
- 作者还使用了 deformable attention 来提高计算效率
DINO 提出的三个新方式:
-
contrastive denoising training:
为了提升 one-to-one matching 的效果,将一个 gt 对应的所有正负样本都加起来来实现,给一个 gt box 添加两个不同的噪声后,将噪声较小的 box 标记为 positive,另外一个标记为 negative
能够帮助模型过滤掉同一目标的多个冗余输出
-
mixed query selection:
改善 query 初始化
-
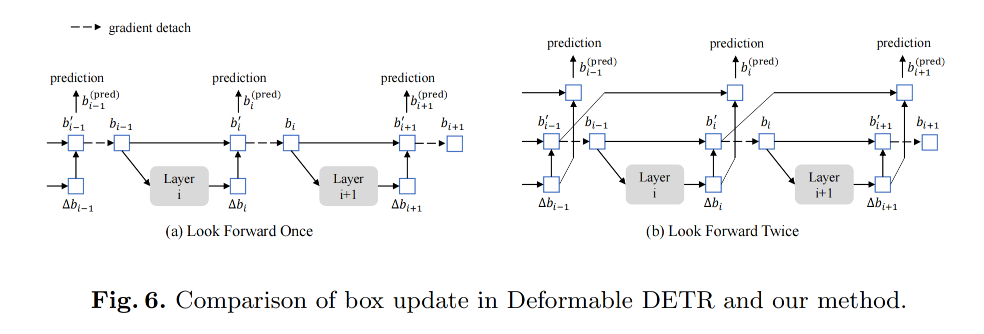
look forward twice:
为了使用后面的层的 refine box information 来帮助前面层进行优化
二、方法
DINO: DETR with Improved DeNoising Anchor Boxes
DETR 是由两部分构成的:
- positional part:作为 positional queries
- content part:作为 content queries
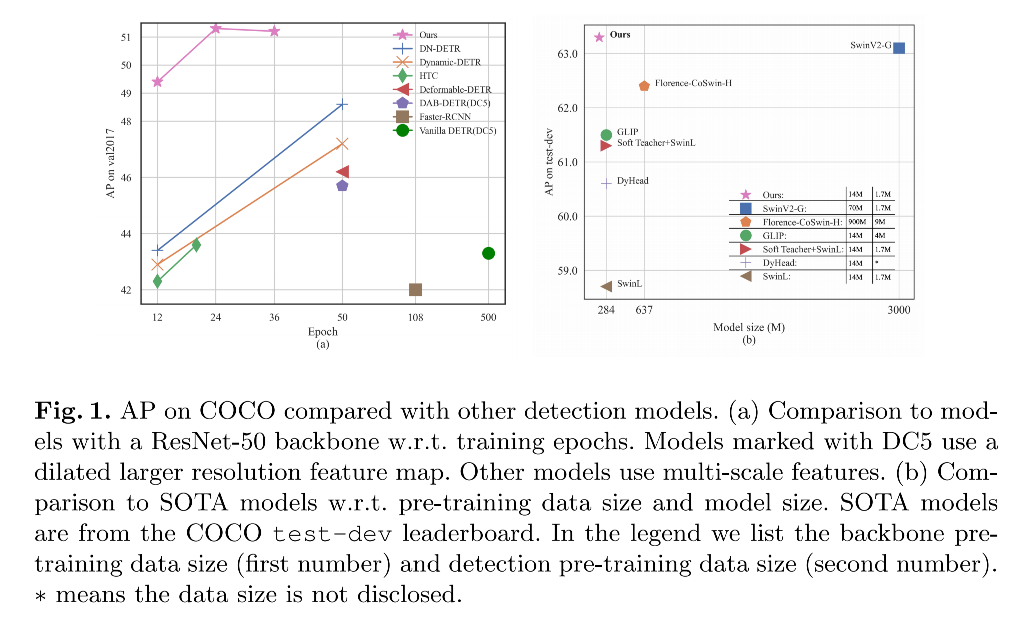
DINO 的框架结构如图 2 所示:给定一个输入图像
- 首先,使用 ResNet 或 Swin transformer 作为 backbone 来进行特征提取
- 其次,将提取到的特征输入 Transformer encoder,并且加上 position embedding,进行 feature enhancement
- 接着,使用 new mixed query selection 来初始化 anchor 作为 decoder 的 positional queries。对 content queries 不进行初始化,让其可以自己学习
- 然后,使用 deformable attention [41] 来对 encoder 输出特征进行结合,并且逐层更新 queries
- 最后,最终的输出是 refined anchor box 和 class result
- 此外,类似于 DN-DETR,DINO 中也使用了 DN branch,来进行 denoising training,且在基础 DN 方法之外,还考虑的 hard negative samples
2.1 Contrastive DeNoising Training
DN-DETR 在稳定训练和加速收敛上表现很好,能够基于和 gt box 离得近的 anchor 来进行预测。
但是,DN-DETR 对附近没有 object 的 anchor 预测 “no object” 的能力较差
所以本文提出了 Contrastive DeNoising(CDN) 来剔除没用的 anchor
DN-DETR 中有一个超参 λ \lambda λ 来控制噪声尺度,生成的早上不会大于 λ \lambda λ,因为 DN-DETR 想要模型学习在适度的 noised queries 中重建 gt
DINO 中,提出了两个超参 λ 1 \lambda_1 λ1 和 λ 2 \lambda_2 λ2,且 λ 1 < λ 2 \lambda_1 < \lambda_2 λ1<λ2,如图 3 所示,生成两种 CDN queries:
- positive queries:noise scale 小于 λ 1 \lambda_1 λ1,用于重建 gt box
- negative queries:noise scale 大于 λ 1 \lambda_1 λ1 小于 λ 2 \lambda_2 λ2,用于预测 “no object”
如图 3 所示,每个 CDN group 有一系列 positive queries 和 negative queries,如果一个图像有 n 个 GT box,CDN group 会有 2n 哥 queries,因为每个 GT box 生成一个 positive 和一个 negative queries
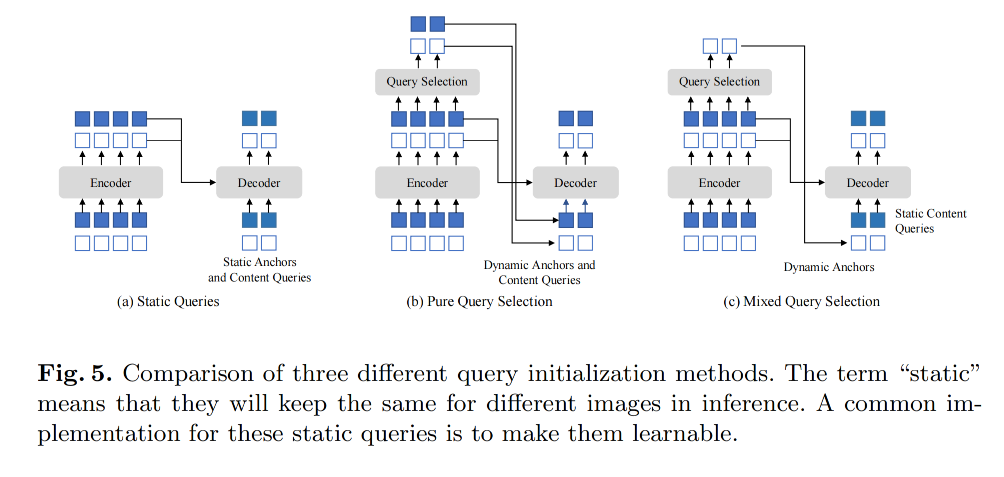
2.3 Mixed Query Selection
如图 5c,DINO 只使用 position information 和 selected top-K features 来初始化 anchor box,保持 content queries
2.4 Look Forward Twice
三、效果