论文笔记--Evaluating Large Language Models Trained on Code
- 1. 文章简介
- 2. 文章概括
- 3 文章重点技术
- 3.1 评估
- 3.2 模型训练--Codex
- 3.3 微调模型--Codex-S
- 3.4 微调模型--Codex-D
- 4. 文章亮点
- 5. 原文传送门
- 6. References
1. 文章简介
- 标题:Evaluating Large Language Models Trained on Code
- 作者:Chen, Mark, et al.
- 日期:2021
- 期刊:arxiv preprint
2. 文章概括
现存的GPT系列语言模型在自然语言中取得了不俗的表现,但实验表明其在代码方面的生成能力十分有限。本文提出了Codex,Codex-S和Codex-D三个大语言模型,在多个代码生成任务上表现远超GPT-3[1]。
3 文章重点技术
3.1 评估
评估代码性能的方法大致分为两种:基于匹配的方法和函数正确率方法。比如BLEU就是一种基于匹配的方法,但文章数值实验证明,BLEU不能总是捕捉到函数的功能正确:分数很高的代码可能不正确。为此文章选择用函数正确率方法
一种常用的评估函数正确率的指标叫pass@k指标,即模型随机生成k个回答(代码块),通过unit test(单元测试)的回答个数。但这样计算的指标方差很高,故文章每次生成
n
≥
k
n\ge k
n≥k个回答,其中通过测试的回答个数为
c
c
c,我们计算
p
a
s
s
@
k
=
E
p
r
o
b
l
e
m
[
1
−
(
n
−
c
k
)
(
n
k
)
]
pass@k = \mathbb{E}_{problem} \left[1 - \frac {\binom {n-c}k}{\binom nk}\right]
pass@k=Eproblem[1−(kn)(kn−c)]
为了自动评估代码性能,文章手动构建了164个手写的编程问题,称为HumanEval数据集。每个问题都包含一个签名(返回)、说明、主题和几个单元测试。文章选择手动构建的原因是不希望训练语料库中包含HumanEval中的问题。
下面给出了HumanEval中的三个问题示例,全部数据可在网址https://www.github.com/openai/human-eval 查看使用。
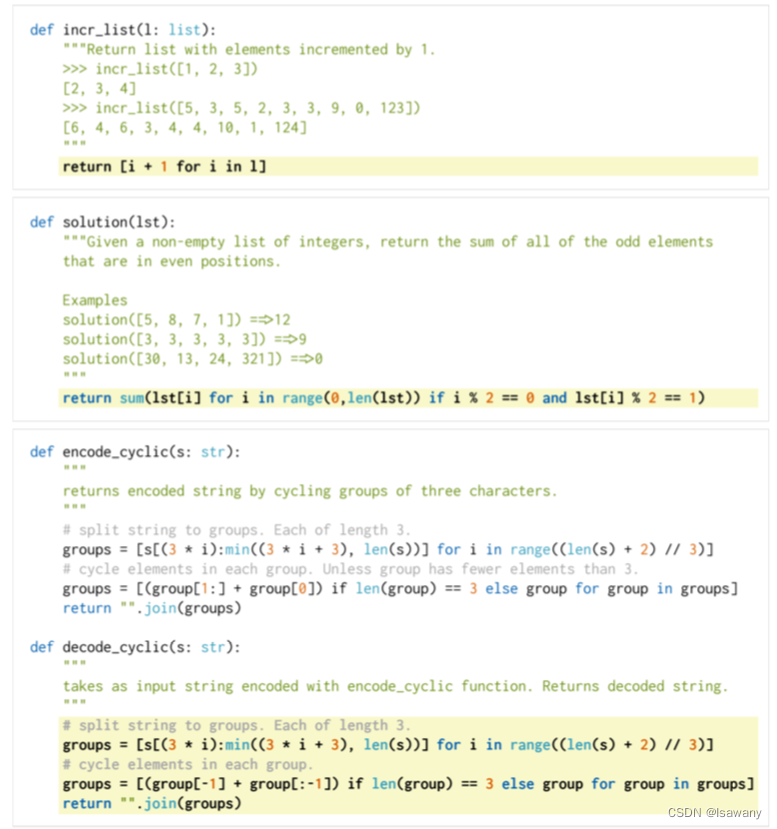
评估时,只需要将上述问题转化成一个包含header、signature、docstring的prompt即可。
3.2 模型训练–Codex
文章选择从GPT-3上微调得到代码模型,这样做虽然没有显著提升模型表现,但是加快了模型的收敛。文章从Github中收集了54million的公共库,包含1MB以下的Python文件共计179GB。为了保证训练集的质量,文章过滤了自动生成的文件、平均行数大于100的文件或仅包含一小部分字符数字的文件,过滤后的文件总计159GB。微调后的模型记作Codex模型(其中最大的模型为Codex-12B)。
自动评估阶段,我们每次生成k个样例,然后评估其中通过单元测试的样例个数,得到pass@k;实际应用时,我们每次生成k个样例,选择其中mean token log-proba最大的输出即可。
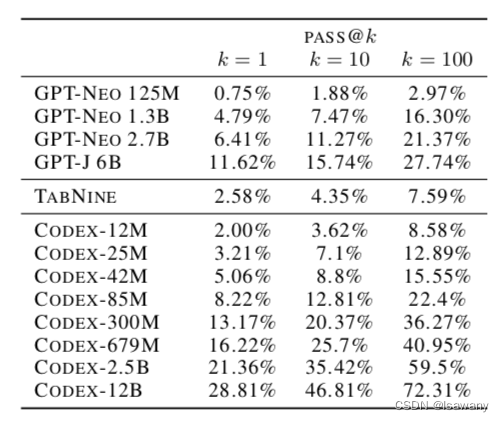
实验表明,Codex系列模型效果远超GPT-3。300M以上的Codex模型效果已经优于GPT-J 6B:
3.3 微调模型–Codex-S
文章发现Github上很多代码包含很多类、说明等,会造成数据集不纯粹。为此,我们构建了一个训练数据集并使用它对Codex模型进行微调。
训练数据集来自编程竞赛、面试准备网站和PyPI中的持续集成问题。为了过滤其中模糊的、太复杂的问题,我们首先用Codex-12B对上述问题进行回答,每个问题生成100个答案,如果没有一个答案通过单元测试,则认为该问题太难或太模糊,将其从微调数据集中移除。
最后我们在上述数据集上微调Codex模型:将上述问题转化成标准代码格式,将prompt中的token掩码,最小化参考答案的负对数似然。
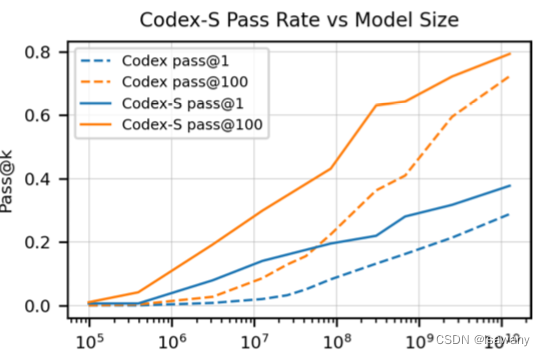
评估结果显示Codex-S的性能超过Codex,且Codex-S的pass@1,即通过最大似然筛选出来的单个样例准确率高于Codex的pass@100。
3.4 微调模型–Codex-D
另一方面,文章探索了从代码生成文本说明的反向过程。类似上一节中的微调方法,我们修改训练目标为“掩码代码(包括signature、header、body)部分,最小化说明(docstring)的负对数似然。得到的模型称为Codex-D。
4. 文章亮点
文章给出了代码大语言模型Codex,Codex-S和Codex-D,可帮助开发者,尤其是初学者自动生成代码。但文章论证了Codex系列模型的局限性,现有模型还存在一些不正确的结论和misalianment(即模型有这个能力但是没回答)现象,同时模型可能存在一些敏感话题风险,后续可通过指令微调进行控制。
5. 原文传送门
Evaluating Large Language Models Trained on Code
HumanEval数据集
6. References
[1] 论文笔记–Language Models are Few-Shot Learners