目录
一、使用IDEA开发WordCount程序... 3
二、实验目的... 3
三、实验要求... 3
四、实验环境... 3
五、实验步骤... 3
4.1.1启动IDEA并创建一个新项目WordCount 3
4.1.2为WordCount项目添加Scala框架支持... 7
4.1.3数据准备... 8
4.1.4设置项目目录... 9
4.1.5新建Scala代码文件... 10
4.1.6配置pom.xml文件... 12
4.1.7更新Maven的依赖文件... 12
4.1.8运行WordCount程序... 13
4.1.9打包WordCount程序生成JAR包... 14
4.10提交到Spark中运行... 17
六、使用IDEA开发读写MySQL数据库程序... 18
七、实验目的... 18
八、实验要求... 18
九、实验环境... 19
十、实验步骤... 19
4.1.1创建MySQL数据库... 19
4.1.2在spark-shell交互式环境中读写MySQL数据库... 20
4.1.3编写独立应用程序读写MySQL数据库... 23
4.1.4新建项目... 23
4.1.5设置依赖包... 24
4.1.6新建Scala代码文件... 25
4.1.8配置pom.xml文件... 25
4.1.9编译运行程序... 27
4.2.0生成应用程序JAR包... 27
十一、出现问题及解决办法... 29
一、使用IDEA开发WordCount程序
二、实验目的
掌握使用IntelliJ IDEA开发Spark应用程序。
三、实验要求
使用IntelliJ IDEA开发本地Spark应用程序。
部署分布式Spark应用程序。
四、实验环境
x86_64 ubuntu 16.04
JDK1.8
Spark-2.1.0
Hadoop-2.7.1
IntelliJ IDEA-3.7
scala-2.11.8
五、实验步骤
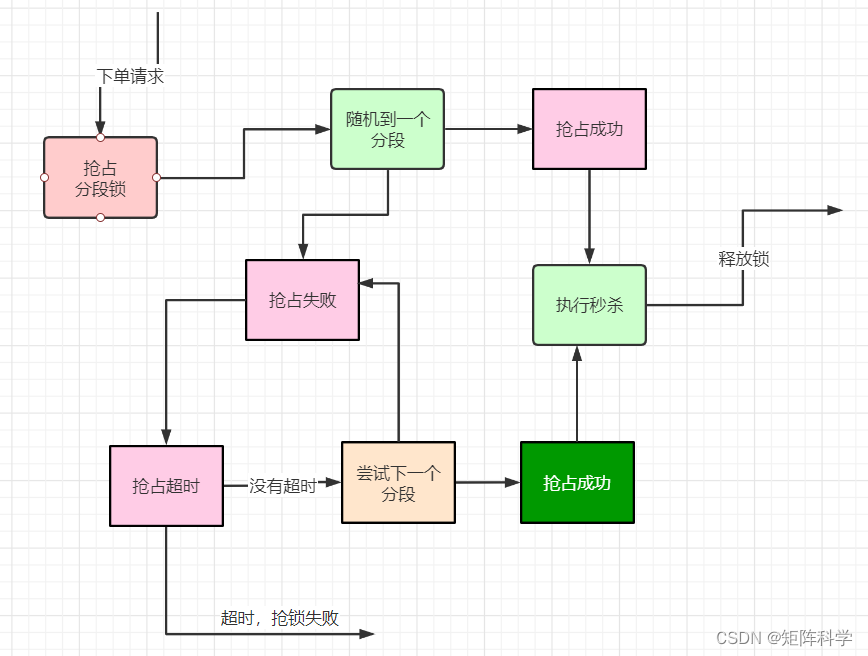
4.1.1启动IDEA并创建一个新项目WordCount
启动IntelliJ IDEA
cd /usr/local/idea
./bin/idea.sh

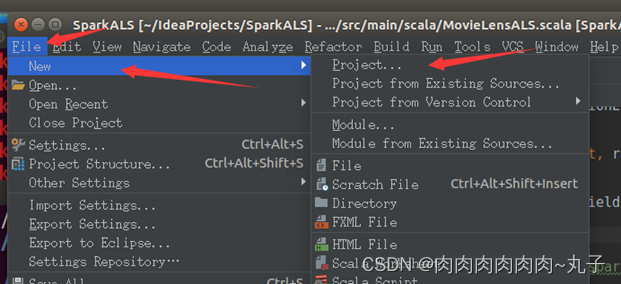
通过菜单“File-->New-->Project”打开一个新建项目对话框
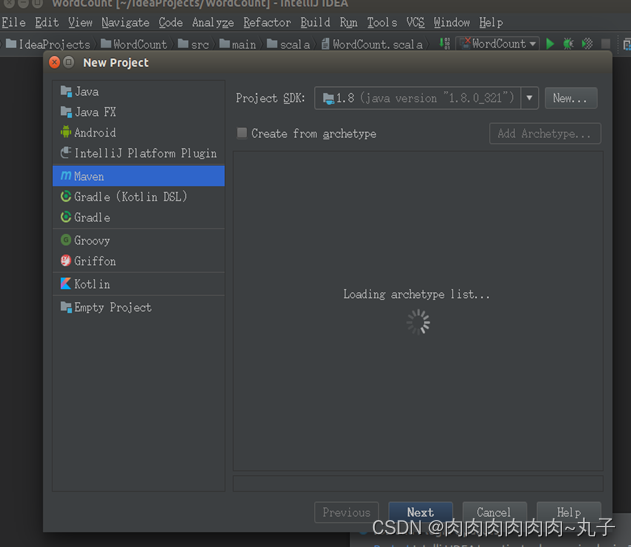
单击左侧的“Maven”项,右侧将出现“Create from_archetype”复选框,不要选择,直接单击窗口底部的“Next”按钮
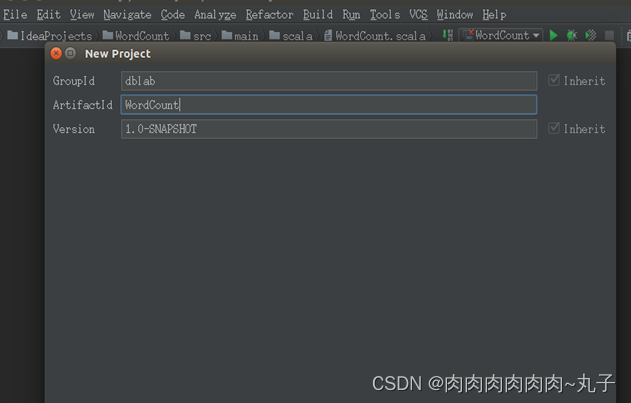
在弹出的窗口中,在“GroupId”对话框中填入“dblab”,在“ArtifactId”对话框中填入“WordCount”,然后,单击“Next”按钮

出现提示框需要单击底部的“Maven projects need to be imported”区域的“Enable Auto-Import”。这样,IDEA就可以自动连接网络下载Maven相关的依赖文件,以后每次修改项目中的pom.xml内容时,IDEA都会自动连接网络下载相关的依赖文件。
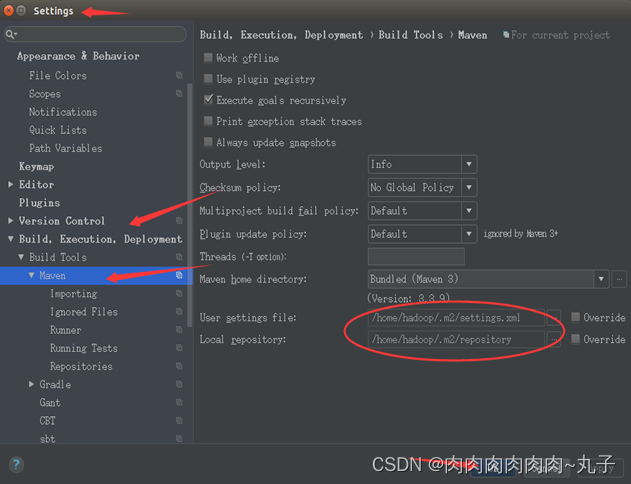
选中如下Maven的配置文件
4.1.2为WordCount项目添加Scala框架支持
Spark程序开发和运行,需要依赖Spark相关的jar包。按下图中所示依次选择,手动导入spark的jar包到项目中。

4.1.3数据准备
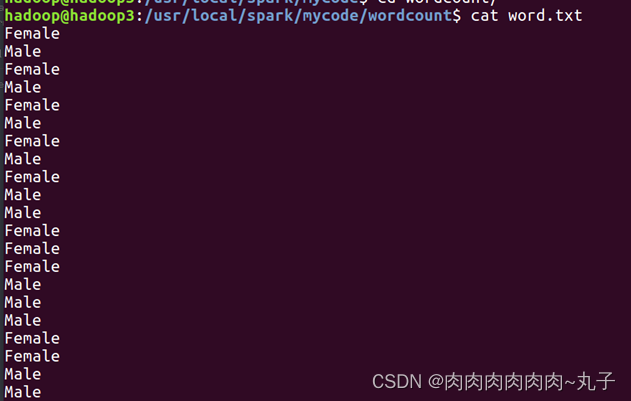
打开终端,在/usr/local/spark/mycode/目录下创建文件word.txt
cd /usr/local/spark/mycode/wordcount/
sudo vi word.txt

4.1.4设置项目目录
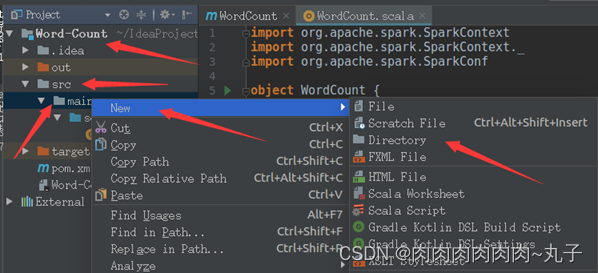
在界面左侧的项目栏中,在“src”目录的“main”子目录上,单击鼠标右键,在弹出的菜单中选择“New”菜单项,然后,子菜单中选择“Directory”菜单项,创建一个新目录。
在弹出的对话框中,输入目录名称“Scala”,单击“OK”按钮
在scala子目录上,单击鼠标右键,在弹出的菜单中选择“Mark Directory as”菜单项,再在子菜单中选择“Sources Root”菜单项,把“scala”目录设置为源代码目录。

在“java”子目录上,单击鼠标右键,在弹出的菜单中单击“Delete...”菜单项,删除这个目录
4.1.5新建Scala代码文件
在scala目录上单击鼠标右键,在弹出的菜单中单击“New”,然后在子菜单中选择“Scala Class”菜单项,新建一个Scala代码文件。
在弹出的窗口中,在“Name”对话框中输入“WordCount”,在“Kind”的下拉选项框中选择“Object”,单击“OK”按钮
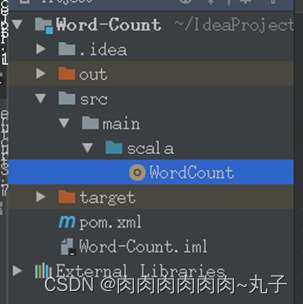
4.1.6配置pom.xml文件
具体详情请点击以下链接查看文档:
https://download.csdn.net/download/qq_53142796/87866506![]() https://download.csdn.net/download/qq_53142796/87866506
https://download.csdn.net/download/qq_53142796/87866506