文章目录
- Alloy 核心内容
- sig
- 数据类型
- var
- one
- fact
- pre-condition
- fun
- pred 谓词
- 谓词的构成
- 谓词的结果 / 普通条件约束和 pre-post condition 的区别
- Finite State Machines 有限状态机
- FSM in Alloy
- Check Specification
- 动画(Animation):
- run 关键字
- but 关键字
- Visualization
- 检查断言(Check Assertion):
Alloy 核心内容

sig
- 在 Alloy 中,
sig用于定义一个抽象的、命名的实体或类型。 - 这个实体可以代表一个对象、一个类、一个状态或任何你想要建模的概念。
- 因为在
alloy中一切皆集合,因此通过sig定义的什么其本质都是一个集合。 - 通过定义
sig,你可以指定实体的 名称、属性和关系。这些定义可以用于构建模型,表示系统中的元素以及它们之间的关系。
下面是一个使用 Alloy 中的 sig 定义对象的简单示例:
sig Person {
name: String,
age: Int,
address: String
}
sig Car {
make: String,
model: String,
year: Int
}
- 在上述示例中,我们定义了两个签名:
Person和Car。Person表示一个人,具有名称、年龄和地址属性。Car 表示一辆汽车,具有制造商、型号和年份属性。
通过使用 sig,你可以定义系统中的各种实体类型,并在模型中使用它们来表示对象、类别、状态等。这有助于构建系统的抽象模型,并在模型中描述对象之间的关系和约束。 然后,你可以使用 Alloy 的分析工具来验证模型的属性、执行模型检查和生成实例,以了解系统的行为和性质。
数据类型
在 Alloy 中,有几种基本的数据类型可用于定义模型的属性和关系。以下是一些常见的 Alloy 数据类型:
-
Int:表示整数类型。例如:age: Int。 -
String:表示字符串类型。例如:name: String。 -
Bool:表示布尔类型,只有两个可能的值:true 或 false。例如:isAvailable: Bool。 -
univ:表示一个全域(universe),包含了模型中所有可能的元素。univ 类型可用于定义无约束的关系。例如:allObjects: univ。 -
set:表示集合类型,用于存储多个元素。可以与其他类型结合使用,如 set Int 表示整数集合,set Person 表示 Person 类型的对象集合。 -
seq:表示序列类型,用于存储有序的元素序列。可以与其他类型结合使用,如 seq Int 表示整数序列,seq String 表示字符串序列。 -
one、lone、some:这些是用于限制关系基数的关键字。one表示关系中的元素必须有且仅有一个,lone表示关系中的元素可以有最多一个,而some表示关系中的元素至少有一个。
var
-
var关键字限制当前属性是否为可变的 -
如下:
sig Person { var name: String, var age: Int } -
这个例子中
name,age都是可变属性,即,可在运算过程中发生更改 -
但是如果如下写:
sig Person { name: String, age: Int } -
则默认这两个属性是不可变的,其值在
Person创建的时候被唯一确定
one
one是一个关键字,用于限制relation中元素的基数。one关键字指示关系中的元素必须有且仅有一个。
one 关键字通常与关系声明一起使用,以确保满足特定的基数约束。下面是一个示例:
sig Person {
name: String,
car: one Car
}
sig Car {
make: String,
model: String
}
-
上述代码中,通过在
car关系声明中使用one关键字,我们指示每个Person对象与一个且仅一个Car对象相关联。这就强制了在模型中的每个Person对象都拥有一辆汽车。 -
如果
one加载了sig定义的内容前面,则表示整个sig定义的集合中只有一个元素,例如:one sig Person{} -
则代表在
Person这个集合中最多只有一个实例
基数约束可以帮助确保模型中的关系满足特定的要求,如一对一关系、每个对象至多一个关联对象等。
fact
-
在 Alloy 中,
fact用于定义陈述事实(facts)。陈述事实是模型中的断言或约束条件,用于描述关于模型的静态属性、关系或约束的真实性。 -
通过使用
fact,你可以表达关于模型的一些预期或必须满足的条件,以确保模型的合理性和一致性。 -
以下是一个示例,展示了如何使用
fact关键字:sig Person { name: String, age: Int } fact AgePositive { all p: Person | p.age > 0 } -
这里的意思就是,我们写了一个
AgePositivefact对Person中的age属性做出了限制,也就是对于所有的Person,他们的age都必须> 0。 -
但是我们还可以进行更加严格的规定,因为现在我们还没有考虑
时态(temporal)概念,因为我们现在关注的还是某一个state,如果我们想让程序在任何state都必须满足这个条件,我们就需要使用always在时间概念上加以限制:sig Person { name: String, age: Int } fact AgePositive { always all p: Person | p.age > 0 }
pre-condition
sig URL{}
sig Password{}
sig Username{}
sig Passbook{ var password: Username -> URL -> Password}
fact NoDuplicate{
always all pb: Passbook, usr: Username, url:URL | lone pb.password[usr][url]
}
pred add[pb: Passbook, usr: Username, url: URL, psd: Password]{
pb.password' = pb.password + (usr -> url -> psd)
}
pred update[pb: Passbook, usr: Username, url: URL, psd: Password]{
one pb.password[usr][url]
pb.password' = pb.password ++ (usr -> url -> Password)
}
pred delete[pb:Passbook, usr: Username, url: URL] {
one pb.password[usr][url]
pb.password' = pb.password - (usr -> url -> Password)
}
-
从这个实例中,我们构建了一个
Passbook来存储用户名、url 和密码 -
我们首先使用
fact定义了一个约束NoDuplicate来保证对于任意给定的usrname和url的组合,密码只能是唯一的,或者是个空值 -
在
add中当需要添加一个password到Passbook中的时候,直接添加即可 -
特别需要注意的是
delete和update操作,这里多了一个one pb.password[usr][url]的precondition,也就是说,当进行delete和update的时候,都必须保证当前的username, url对应的password是存在的,要不然就不能够删除和更新。 同样需要注意的是:pre / post condition往往发生在state改变的上下文中,区别于pred中普通的条件约束,这个我们在后面还会详细解读。为什么
pb.password - (usr -> url -> Password) 要使用Password?- 在
delete谓词中,这个表达式pb.password - (usr -> url -> Password)的含义是,从pb.password这个关系中移除所有满足usr -> url -> ?的映射,这些映射的格式是(usr -> url -> Password)。换句话说,就是删除所有与给定的 usr 和 url 对应的密码。 - 不过这里有一点需要注意,使用
Password作为一个类型而不是一个变量可能会导致一些混淆。在这种情况下,使用Password实际上是指对应的密码类型的所有可能值,这可能并不是你想要的结果。实际上,你可能想要删除与特定用户和特定 URL 对应的特定密码,那么这个Password就应该被替换为一个指定的密码变量。 - 也就是说,如果你想要删除与特定用户和
URL相关联的具体密码,你需要有一个具体的Password参数。然后你可以用类似于pb.password' = pb.password - (usr -> url -> psd)这样的语句来表示删除操作。
- 在
-
让我们来推导一下,其实
usr -> url -> Password这种表示虽然看起来奇怪,但是其实很合理,因为我们可以这么认为,alloy中的所有内容都是集合,因此可以写成{usr} -> {url} -> Password如果我们看一个更加简单的例子A -> B所代表的其实就是{(a1, b1), .... (a_n, b_m)},所以{usr} -> {url} -> Password也就是{(usr, url, pass1), ..., (usr, url, passn)}这个集合。
fun
在 Alloy 中,你可以使用 fun 关键字定义函数。与谓词(pred)不同,函数会返回一个值。返回值的类型是由函数的签名定义的。
函数和谓词在 Alloy 中的主要区别是 函数可以返回值,而谓词则不可以。 函数的返回值可以是任意类型的值,包括简单类型、集合、元组、关系等。
Alloy 中函数的关键知识点包括:
-
返回类型: 在定义函数时,你需要指定函数的返回类型。 返回类型定义了函数返回值的类型。
-
参数列表: 函数可以接受任意数量的参数。参数列表定义了函数接受的参数的数量和类型。
-
函数体: 函数体定义了函数的行为。在函数体中,你可以使用逻辑表达式和关系运算来描述函数的行为。
-
量词: 你可以在函数体中使用量词,例如
all, some, one, lone,和no,来对函数的行为进行更精确的描述。 -
集合运算符: 在函数体中,你可以使用集合运算符,例如
+, -, &,和++,来操作集合和关系。 -
递归函数: 在 Alloy 中,你可以定义递归函数。递归函数是一种在其定义中调用自身的函数。递归函数可以用来解决许多复杂的问题,例如遍历树形数据结构。
-
内置函数: Alloy 提供了一些内置函数,例如
sum,#,和min,可以帮助你更方便地编写模型。
需要注意的是,虽然函数可以返回值,但是 Alloy 中的函数并不具有副作用。也就是说,函数不能修改其参数或者其他全局变量的值。函数只能根据其参数计算并返回一个值。
fun lookup[pb:Passbook, usr: Username, url: URL] :lone Password{
pb.password[usr][url]
}
- 这里我们定义一个函数
loopup,从Passbook中索引对应的password - 我们制定了返回类型是
Password,也制定了返回的数量最多是1个(用lone)
pred 谓词
谓词的构成
在 alloy 中,我们可以从不同的角度去理解谓词,谓词可以有下列内容组成:
-
Preconditions(前置条件): 这些是调用谓词之前必须满足的条件。
-
Postconditions(后置条件): 这些是执行谓词之后必须满足的条件。在某些情况下,后置条件也可以被视为谓词执行的结果。
-
Quantifiers(量词): 这些用于定义对某个集合中所有元素或存在某个元素满足的条件,例如
all(所有的)、some(存在的)、one(恰好一个的)、lone(最多一个的)、no(不存在的)。 -
Relational expressions(关系表达式): 这些表达式用于定义或操作关系,包括关系的并(
+)、差(-)、交(&)、覆盖(++)等。 -
Other logical expressions(其他逻辑表达式): 这些可以包括逻辑运算符(如
and、or、not)、比较运算符(如=、!=)、条件运算符(如=>、<=>)等。
谓词的具体构成会根据它的用途和需要表达的逻辑而有所不同。一个谓词可以只包含前置条件,也可以只包含后置条件,也可以包含更复杂的逻辑表达式。
谓词的结果 / 普通条件约束和 pre-post condition 的区别
-
谓词不像我们之前编码中定义的函数
-
谓词没有返回值,只有
是否执行成功 -
谓词的主要作用是对输入参数提出一系列的约束。当这些约束被满足时,我们说这个谓词的执行结果是 “成功” 或
true;反之,如果约束没有被满足,我们说执行结果是 “失败” 或false。 -
比如上面中代码的例子,如果
add谓词符合了所有的条件,那么Passbook中多了一项,这时候谓词执行成功,谓词的结果为true,但是并没有任何返回值。 -
同样的,我们在这里定义一个新的谓词
samePassword:fun lookup[pb:Passbook, usr: Username, url: URL] :lone Password{ pb.password[usr][url] } pred samePassword[pb:Passbook, usr, otherUsr: Username, url: URL]{ lookup[pb, usr, url] = lookup[pb, otherUsr, url] }- 因为
funlookup会返回一个具体的password,同时在samePassword中我们让这个谓词的 条件 是lookup[pb, usr, url] = lookup[pb, otherUsr, url],如果条件满足,则此pred为真。 - 但是注意这里的
lookup[pb, usr, url] = lookup[pb, otherUsr, url]既不是pre也不是postcondition,只是一个普通的 谓词条件(限制) 前置条件和后置条件主要用在操作或变化的上下文中。前置条件是执行某个操作或变化前需要满足的条件,后置条件是执行操作或变化后需要满足的条件。
- 因为
Finite State Machines 有限状态机
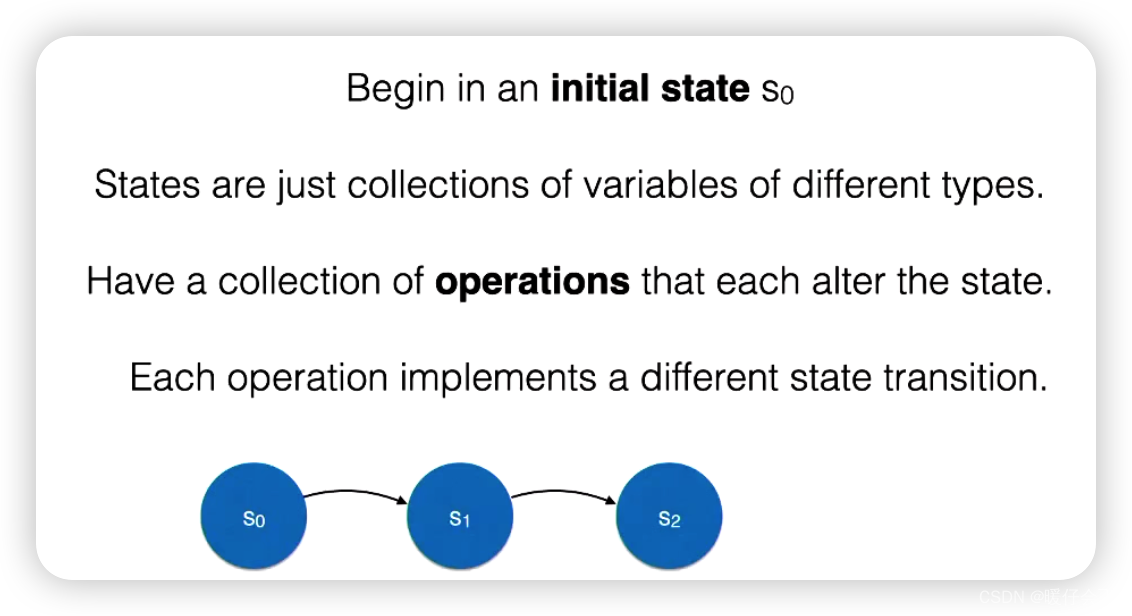
FSM in Alloy

有限状态机(Finite State Machine,FSM)是一个抽象的计算模型,可以描述一个系统的行为。在 FSM 中,系统可以处于一系列的状态,每一个状态都代表了系统的一种特定配置。 系统可以根据一些规则从一个状态转移到另一个状态。
在 Alloy 中,你可以使用 关系和约束 来实现 FSM。下面是一个基本的 FSM 在 Alloy 中的表示方式:
// 定义状态和转移事件
sig State {}
sig Event {}
// 定义有限状态机
sig FSM {
// set 是一个关键字,表示 states 的元素集合可以是任意 States 的子集
states: set State,
init: one State, // 将初始状态设定为一个 State 的实例
trans: states -> Event -> states //将状态转移设置为一组 relation 关系
}
// 约束:初始化状态必须在状态集合中
fact InitInStates {
all fsm: FSM | fsm.init in fsm.states
}
// 约束:转移关系的定义
fact Transitions {
all fsm: FSM, s: fsm.states, e: Event, s': fsm.states |
(s -> e -> s') in fsm.trans implies (s' in fsm.states)
}
// 更多的约束可以根据你的 FSM 的具体需求来添加...
-
在上述代码中,
State代表FSM的状态,Event代表可能导致状态转换的事件。FSM是有限状态机的定义,包含一组状态、一个初始状态和一个转换关系。 -
InitInStates是一个约束,它要求初始状态必须在状态集合中。Transitions是另一个约束,它定义了转移关系的语义:如果有一个转移关系从状态s通过事件e到达状态s',那么s'必须是状态集合中的一个状态。
Check Specification
- 如何建议一个 specification 是否满足我们的预期呢?在 alloy 中我们通过
animation和check assertion来完成这个任务
动画(Animation):
动画是 Alloy 分析器的另一种功能,它允许你以图形化的方式探索你的模型的可能状态。 你可以使用 run 命令来生成一个实例,然后使用 Alloy 分析器的可视化工具来查看和探索这个实例。你可以使用动画功能来理解你的模型的行为,找出模型的潜在问题,或者测试你的模型是否满足你的需求。
总的来说,检查断言和动画都是 Alloy 提供的工具,可以帮助你理解和验证你的模型。通过使用这些工具,你可以更好地理解你的模型的行为,发现模型中的问题,以及验证模型是否满足你的需求。
run 关键字
在 Alloy 中,run 命令用于生成满足给定条件的实例,这些条件通常在谓词中定义。 一旦找到了这样的实例,可以使用 Alloy 分析器的可视化工具来查看和理解这些实例。
下面是一个简单的例子:
sig A {}
sig B {
a: set A
}
pred P {
some b: B | some b.a
}
run P
-
在这个例子中,首先定义了两个
sigA和B,其中B有一个字段a,其值是A的实例的一个集合。然后定义了一个谓词P,表示存在一个B,其a字段包含至少一个A。 -
最后,
run P命令会让 Alloy 分析器找到一个实例,使得谓词 P 成立。 换句话说,分析器会找到一个B,其a字段包含至少一个A。 -
如果存在满足这个条件的实例,Alloy 分析器会生成一个或多个这样的实例,并可以使用分析器的可视化工具查看它们。如果不存在满足这个条件的实例,Alloy 分析器会报告找不到这样的实例。
-
需要注意的是,
run命令 默认只找一个满足条件的实例。 -
注意:如果
run P for n,那么代表对于这个pred中的所有sig他们自个的实例数都不能超过n,如果我按照下面的方式去写,则会报冲突错误:sig A {} sig B { a: set A } pred P { some b: B | #b.a > 5 } run P for 5- 这里我定义了
P要符合的条件是每个B中包含A类的实例数至少是6个,但是我在run命令中for 5代表在整个 alloy 探索的过程中,不能探索超过5个A实例,那么根本就无法验证我的P
- 这里我定义了
-
再次强调:
run P for 5命令告诉 Alloy 分析器在最多有5 个 A 和 B的情况下 找到一个 满足谓词P的实例。
but 关键字
- 同样的
run P for n我们依然可以扩展,因为这个语句的意思是所有sig的实例数都不能超过n,但是如果我想让某一个sig的实例数有单独的限制,就可以使用but; run P for 20 but 6 A代表的就是在最大实例数不超过20的条件下,A的实例数应该保证 最多是6个,而非刚好限制为6个
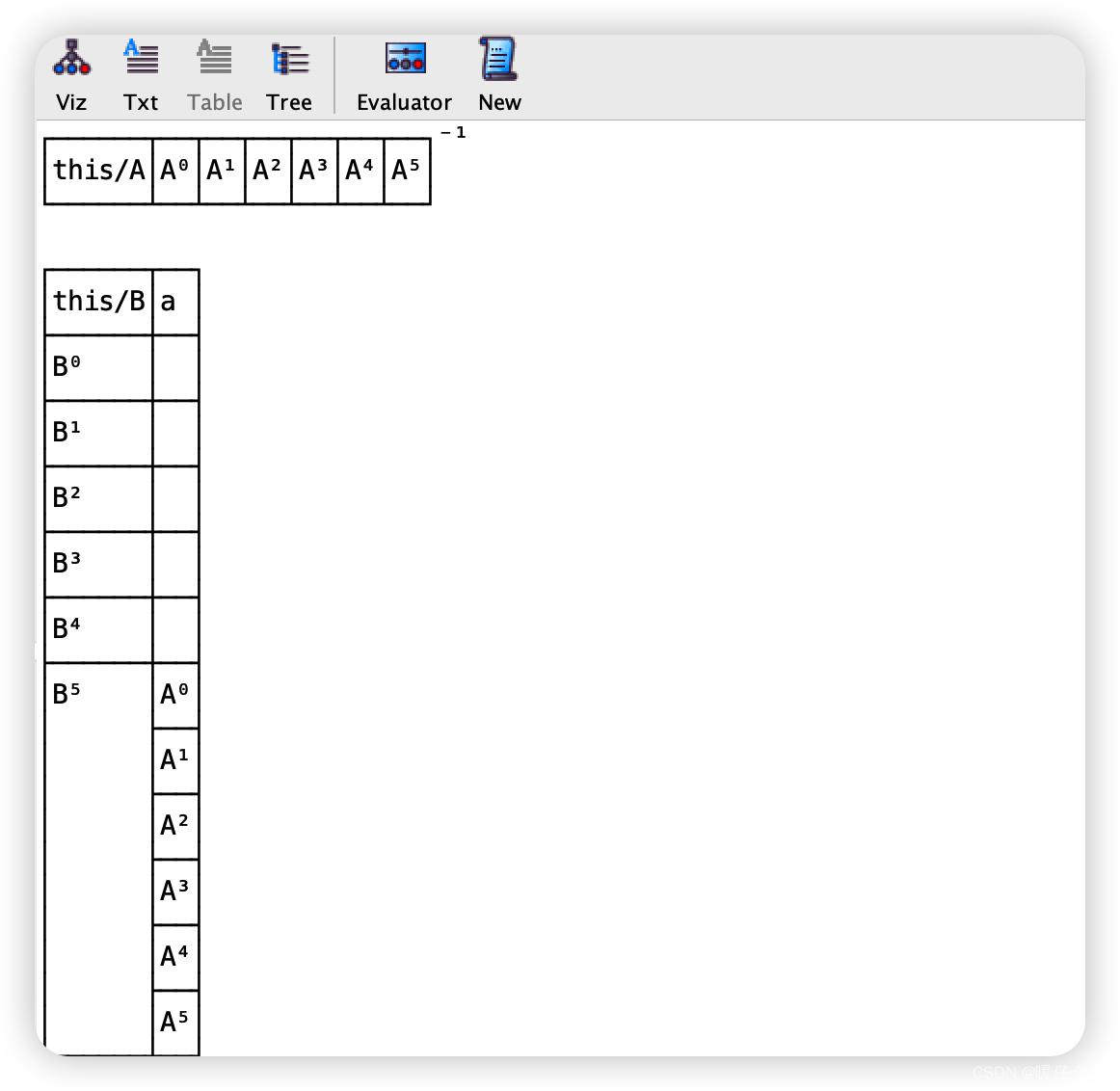
- 从图中也可以看出,
A的实例数刚好为6个
Visualization
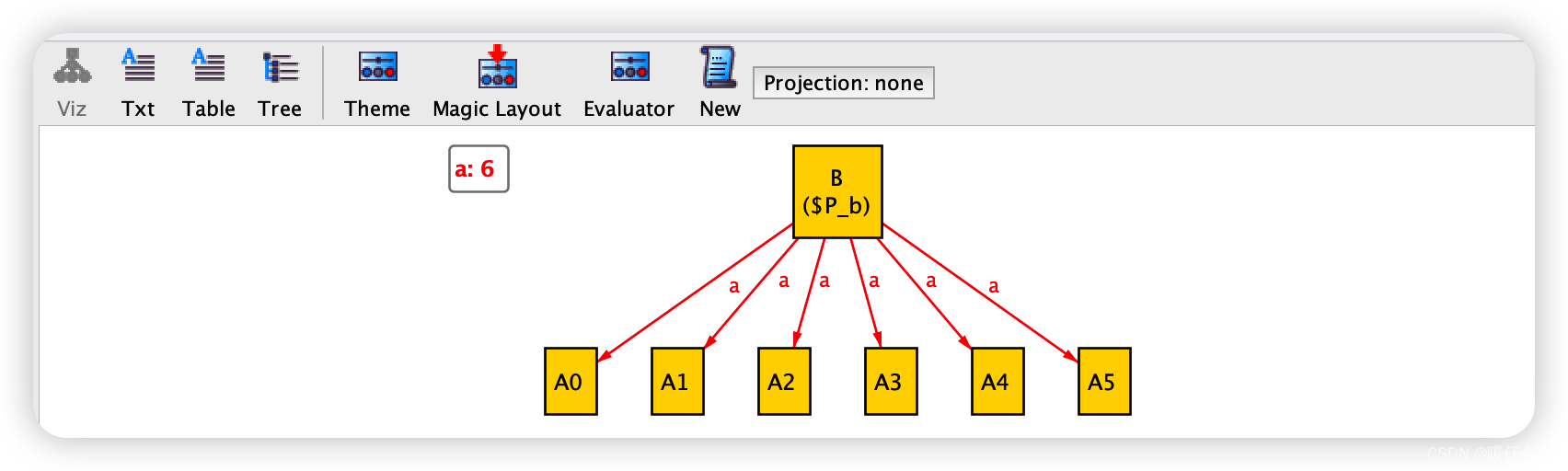
sig A {}
sig B {
a: set A
}
pred P {
some b: B | #b.a > 5
}
run P for 5
- 在这段代码中,由于我们只存在
pred而不存在 不同state之间的转变,也就不存在时态概念上的多个states, 因此这里只有一个图(多个图的情况我们后面讲解)
sig URL{}
sig Password{}
sig Username{}
sig Passbook{ var password: Username -> URL -> Password}
fact NoDuplicate{
always all pb: Passbook, usr: Username, url:URL | lone pb.password[usr][url]
}
pred add[pb: Passbook, usr: Username, url: URL, psd: Password]{
pb.password' = pb.password + (usr -> url -> psd)
}
pred update[pb: Passbook, usr: Username, url: URL, psd: Password]{
one pb.password[usr][url]
pb.password' = pb.password ++ (usr -> url -> Password)
}
pred delete[pb:Passbook, usr: Username, url: URL] {
one pb.password[usr][url]
pb.password' = pb.password - (usr -> url -> Password)
}
run add for 2 but 1 Passbook
-
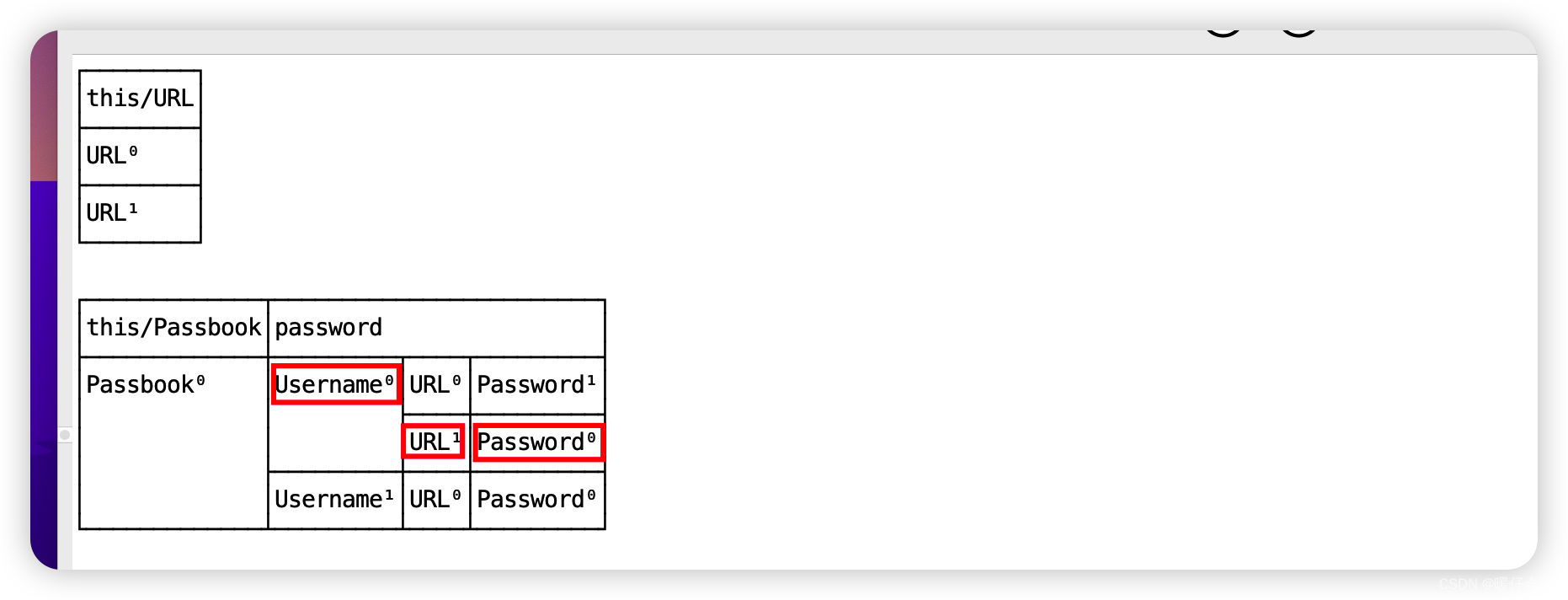
当我们回到这段代码, 我们执行
add命令,命令的意思是:每个sig最多有两个实例,对于Passbook则最多一个实例,最终我们得到了下表:
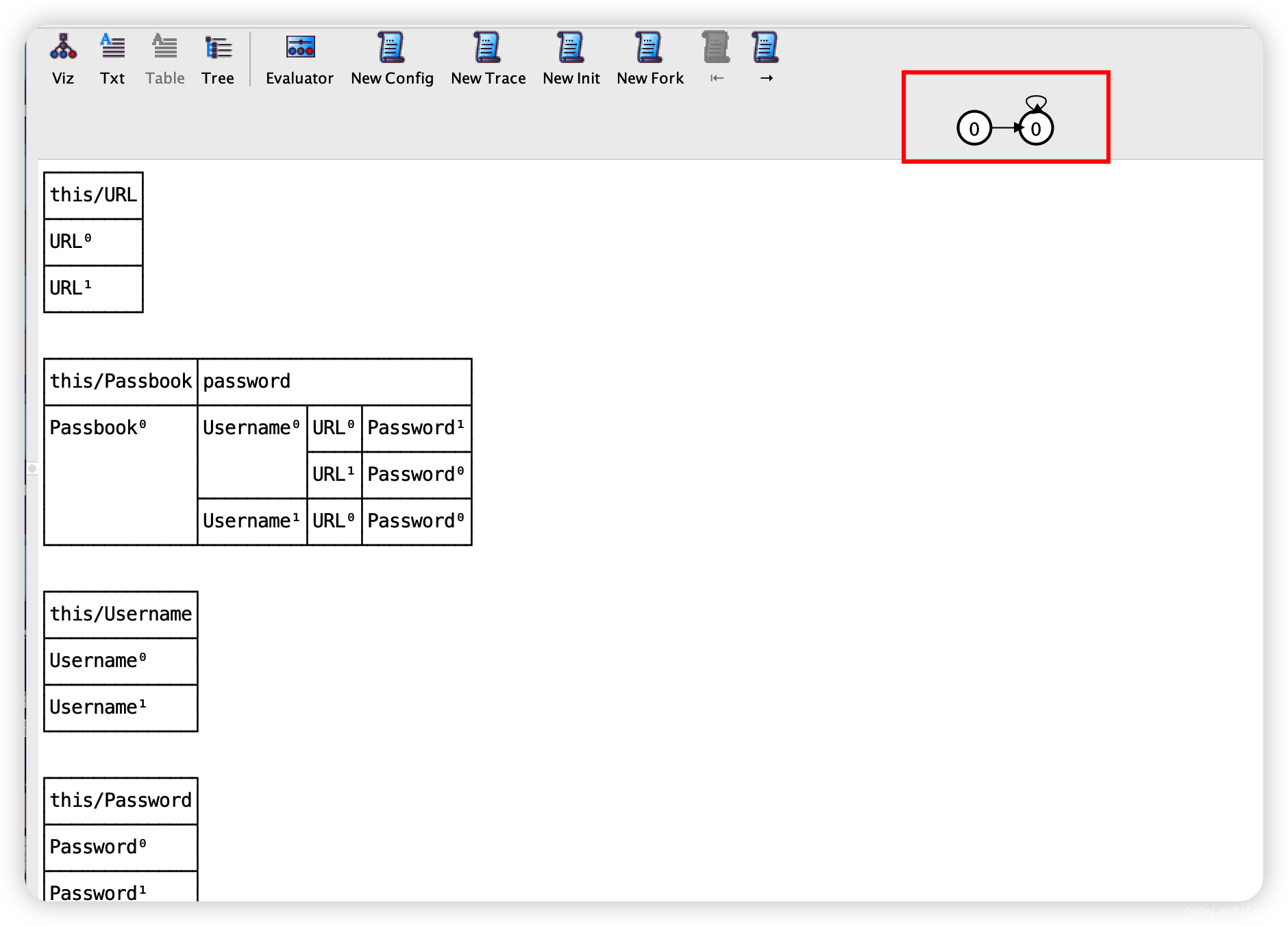
-
从表格的信息可以看到
Passbook只有一个实例,Username有两个实例,Password有两个实例,URL有两个实例。 -
同样的,右上角出现了一个有限状态机的图标,这代表在我们的
add执行过程中存在不同的state之间的转换 -
接着我们解析一下下面的图:
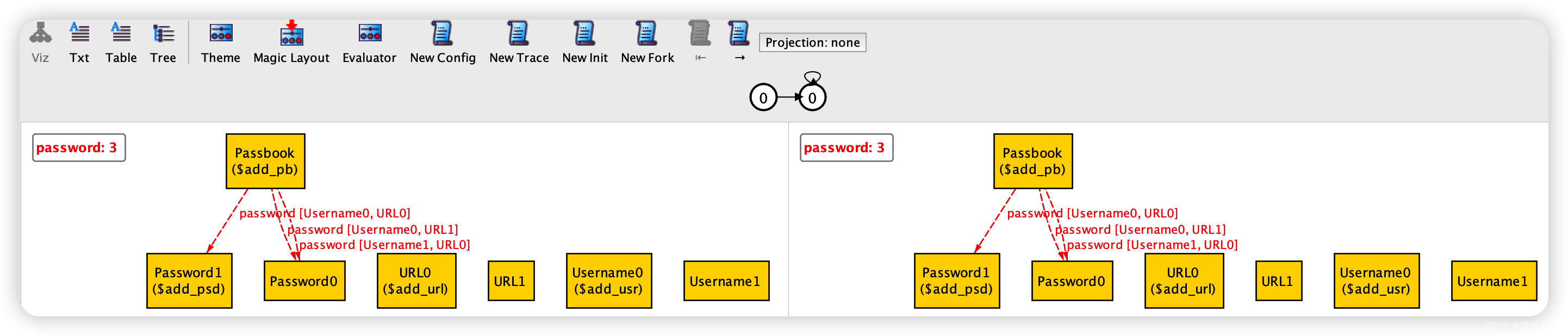
-
图的左侧代表
add操作发生前,右侧代表add操作发生后 -
图中的每个黄色框代表不同的
item -
图中红色的虚线,代表不同的
relations(当我把鼠标停留着某个虚线上,就显示这个relation,例如下图中的relation就是Username0 -> URL1 -> Password0,在 table 中可以找到这个项,刚好 Table 表格中一共 3 项,然后这个图里也刚好 3 根红色的虚线,他们之间是一一对应的关系)
-
再看图中的这个部分:
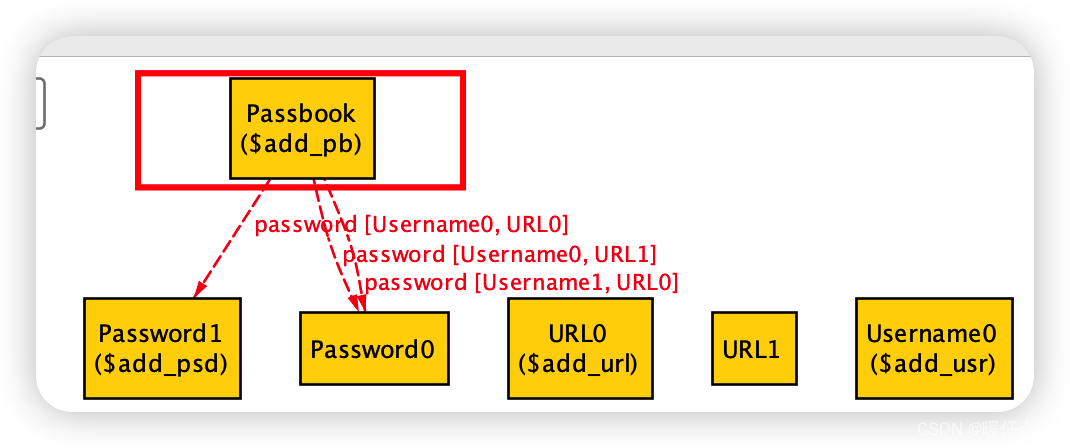
- 其中
$add表示的就是add的操作,_pb刚好与Passbook对应,代表add操作的pb参数就是这个Passbook,以此类推,这些带$add标记的就是参与add行为的那些实例们 - 在上图中,当执行
add的时候,Username0, URL0, Password1, Passbook这四个实例参与了add行为,并作为参数
- 其中
-
从整体上看一下左右两个
state的结果,会发现,图竟然是一样的:

-
其原因是,我们在左图中通过
add增加的这个项目,原本已经存在,即:原本在执行add之前的初始化阶段Username0 -> URL0 -> Password1就已经存在于集合Passbook中了,那么这时候即使add了,从图中看起来也没变化 -
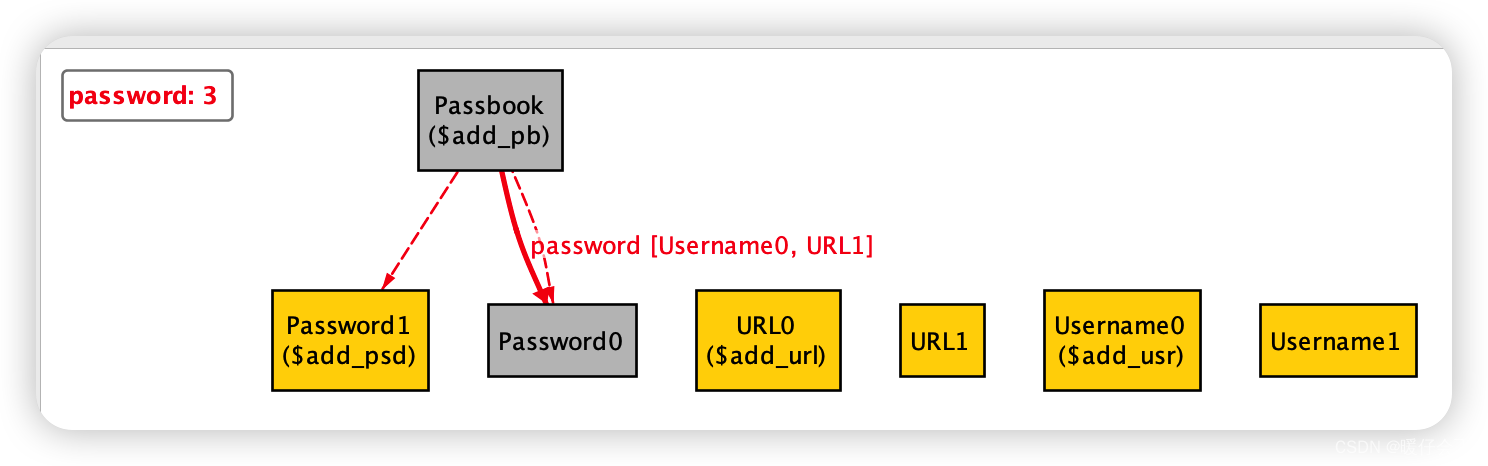
让我们来操作一下,将
init这个pred加入到add中,也就是让我们执行add操作之前先把passbook清空,这样就能看到变化了(run 的代码保持不变):pred init[pb: Passbook]{ no pb.password } pred add[pb: Passbook, usr: Username, url: URL, psd: Password]{ init[pb] pb.password' = pb.password + (usr -> url -> psd) } -
图结果:
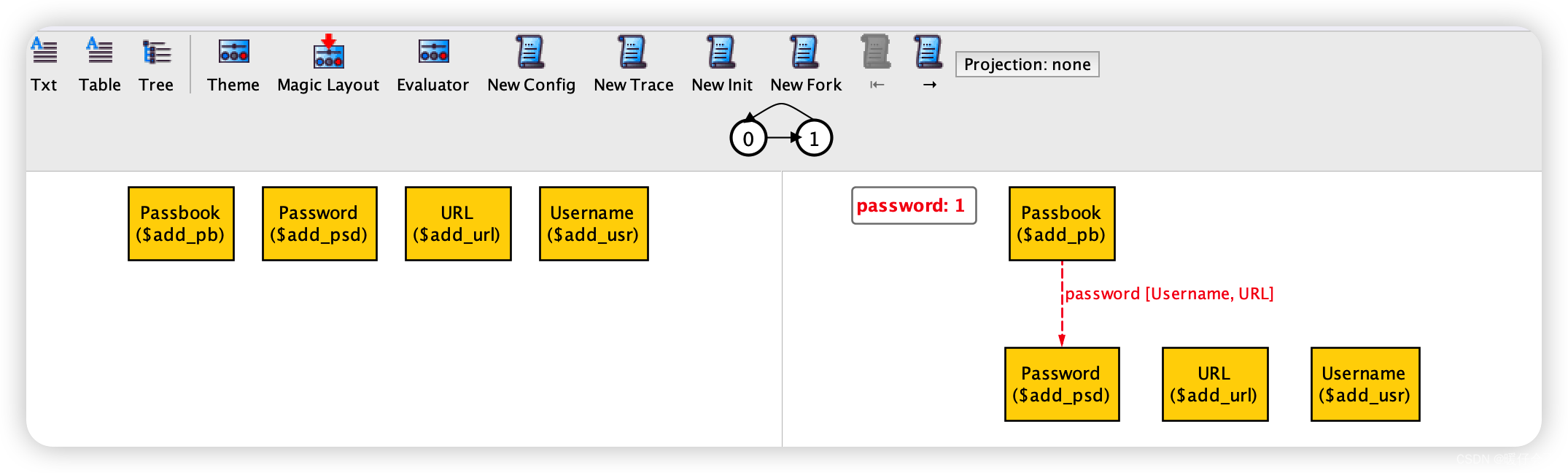
-
可以清楚看到,左边是执行
add之前的state,也就是执行init之后的结果,而右边则是执行了add之后的state,明显我们password:1代表了Passbook中被加入了1个 passwordrelation,而这个relation是Username -> URL -> Password -
同样需要注意的事,之所以在上面的状态机图中
0和1状态之间是闭环的,是因为每次我们进行add操作之前都执行init,而init就会回到空状态 -
我们再看看 table:
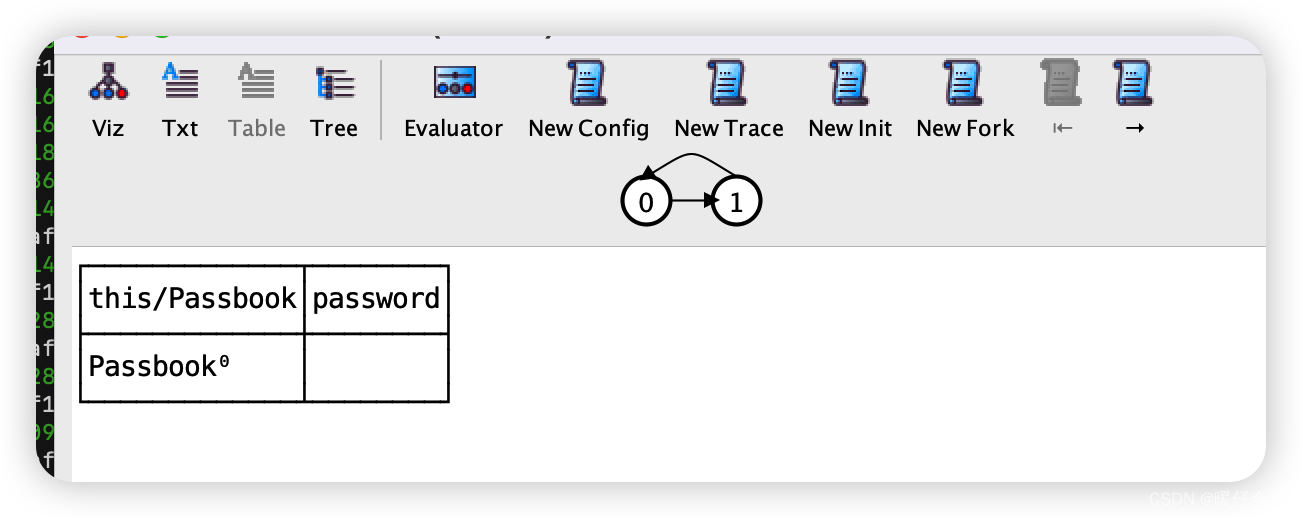
-
开始啥也没有,当我点击
1,则变成如下:
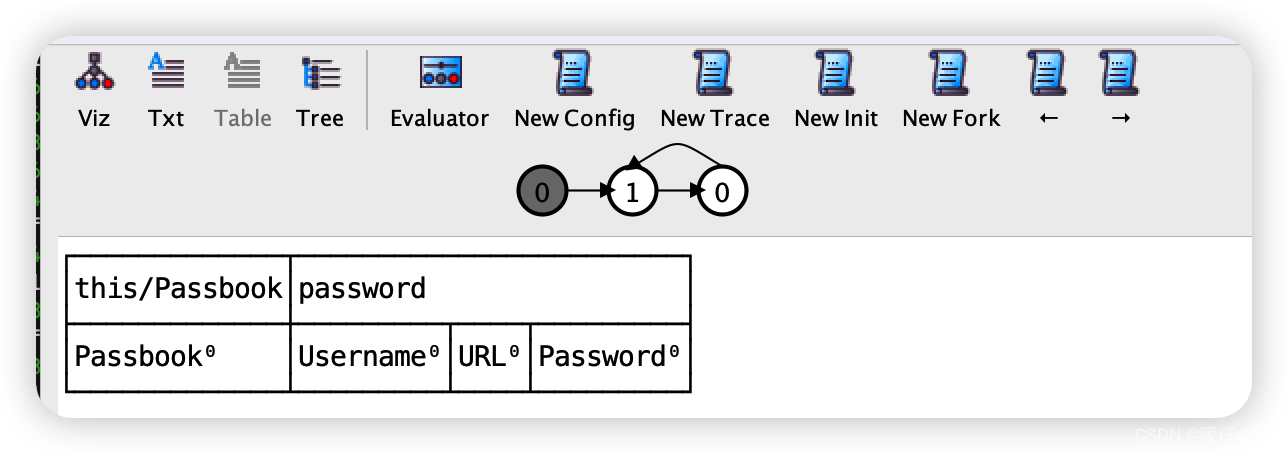
-
即将内容加入了
Passbook
检查断言(Check Assertion):
检查断言是 Alloy 分析器的一种功能,它允许你检查你的模型中的某个断言(assertion)是否总是成立。你可以使用 assert 关键字来定义一个断言,然后使用 check 命令来检查这个断言。如果断言是正确的,Alloy 分析器将找不到反例;如果断言是错误的,Alloy 分析器将找到一个反例,说明在某种情况下断言是不成立的。 通过检查断言,你可以验证你的模型是否满足你期望的属性。
sig URL{}
sig Password{}
sig Username{}
sig Passbook{ var password: Username -> URL -> Password}
fact NoDuplicate{
always all pb: Passbook, usr: Username, url:URL | lone pb.password[usr][url]
}
pred init[pb: Passbook]{
no pb.password
}
pred add[pb: Passbook, usr: Username, url: URL, psd: Password]{
pb.password' = pb.password + (usr -> url -> psd)
}
pred update[pb: Passbook, usr: Username, url: URL, psd: Password]{
one pb.password[usr][url]
pb.password' = pb.password ++ (usr -> url -> Password)
}
pred delete[pb:Passbook, usr: Username, url: URL] {
one pb.password[usr][url]
pb.password' = pb.password - (usr -> url -> Password)
}
fun lookup[pb:Passbook, usr: Username, url: URL] :lone Password{
pb.password[usr][url]
}
pred samePassword[pb:Passbook, usr, otherUsr: Username, url: URL]{
lookup[pb, usr, url] = lookup[pb, otherUsr, url]
}
assert checkAddDelete{
all pb: Passbook, url: URL, usr:Username, psd:Password |
(add[pb, usr, url, psd]; delete[pb, usr, url]) => pb.password=pb.password''
}
check checkAddDelete for 1
-
这个例子中,我们构建了一个
checkAddDeleteassertion 来帮忙检查我们的add和delete行为完成后是否符合预期,在checkAddDelete中我们定义了,当add和delete按照顺序做完之后,pb.password的状态应该和add和delete发生之前完全一样 -
当我们运行的时候:
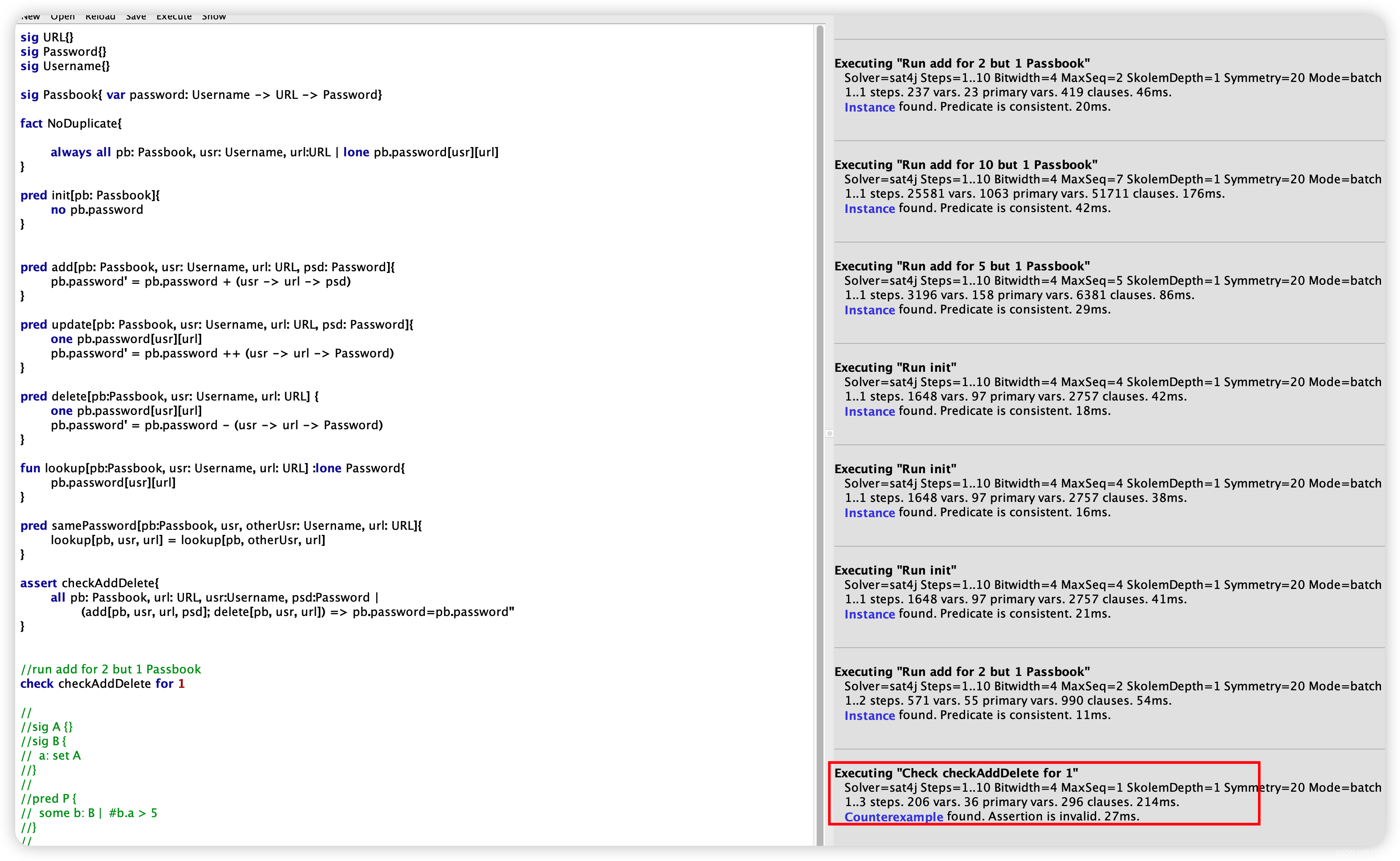
-
系统发现了
Counterexample,这个意思就是,assert找出了反例,我们的设计存在漏洞 -
我们看一下状态图:
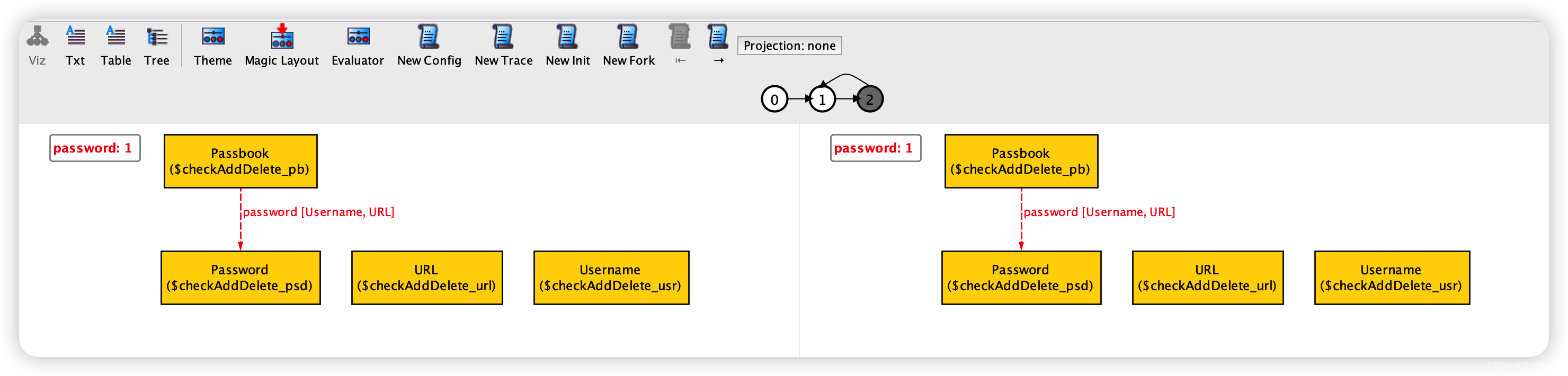
- 左边的是没有执行的情况,右边是执行了
add的情况 - 再点一下状态机进入下一个状态:

- 这时候右边的状态是
delete之后的状态。 - 很明显,左边的
s0和右边的s2状态明显不同,所以产生了counterexample
- 左边的是没有执行的情况,右边是执行了
-
这里的问题其实我们之前探讨过,因为没有
init所以导致一开始s0里面的pb.password就有内容,如果我们把init或者no pb.password[usr][url]放在add最开始,就不会有问题了:sig URL{} sig Password{} sig Username{} sig Passbook{ var password: Username -> URL -> Password} fact NoDuplicate{ always all pb: Passbook, usr: Username, url:URL | lone pb.password[usr][url] } pred init[pb: Passbook]{ no pb.password } pred add[pb: Passbook, usr: Username, url: URL, psd: Password]{ //init[pb] no pb.password[usr][url] pb.password' = pb.password + (usr -> url -> psd) } pred update[pb: Passbook, usr: Username, url: URL, psd: Password]{ one pb.password[usr][url] pb.password' = pb.password ++ (usr -> url -> Password) } pred delete[pb:Passbook, usr: Username, url: URL] { one pb.password[usr][url] pb.password' = pb.password - (usr -> url -> Password) } fun lookup[pb:Passbook, usr: Username, url: URL] :lone Password{ pb.password[usr][url] } pred samePassword[pb:Passbook, usr, otherUsr: Username, url: URL]{ lookup[pb, usr, url] = lookup[pb, otherUsr, url] } assert checkAddDelete{ all pb: Passbook, url: URL, usr:Username, psd:Password | (add[pb, usr, url, psd]; delete[pb, usr, url]) => pb.password=pb.password'' } check checkAddDelete for 1 but 1 Passbook
-
可以看到
Counterexample不存在了